Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Deep Learning JP
PDF, PPTX
3,085 views
[DL Hacks]FPGA入門
2018/06/25 Deep Learning JP: http://deeplearning.jp/hacks/
Technology
◦
Related topics:
Deep Learning
•
Read more
7
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 20
2
/ 20
Most read
3
/ 20
4
/ 20
5
/ 20
6
/ 20
7
/ 20
Most read
8
/ 20
9
/ 20
10
/ 20
11
/ 20
12
/ 20
13
/ 20
14
/ 20
15
/ 20
16
/ 20
17
/ 20
18
/ 20
19
/ 20
20
/ 20
More Related Content
PDF
CUDA 6の話@関西GPGPU勉強会#5
by
Yosuke Onoue
PDF
Magnum IO GPUDirect Storage 最新情報
by
NVIDIA Japan
PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
PDF
10分でわかる Cilium と XDP / BPF
by
Shuji Yamada
PDF
OpenStack超入門シリーズ Novaのディスク周りあれこれ
by
Toru Makabe
PDF
普通の人でもわかる Paxos
by
tyonekura
PDF
ログ解析基盤におけるストリーム処理パイプラインについて
by
cyberagent
PDF
大規模サービスを支えるネットワークインフラの全貌
by
LINE Corporation
CUDA 6の話@関西GPGPU勉強会#5
by
Yosuke Onoue
Magnum IO GPUDirect Storage 最新情報
by
NVIDIA Japan
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
10分でわかる Cilium と XDP / BPF
by
Shuji Yamada
OpenStack超入門シリーズ Novaのディスク周りあれこれ
by
Toru Makabe
普通の人でもわかる Paxos
by
tyonekura
ログ解析基盤におけるストリーム処理パイプラインについて
by
cyberagent
大規模サービスを支えるネットワークインフラの全貌
by
LINE Corporation
What's hot
PDF
Hadoop/Spark を使うなら Bigtop を使い熟そう! ~並列分散処理基盤のいま、から Bigtop の最近の取り組みまで一挙ご紹介~(Ope...
by
NTT DATA Technology & Innovation
PDF
UnboundとNSDの紹介 BIND9との比較編
by
hdais
PDF
L3HA-VRRP-20141201
by
Manabu Ori
PDF
AS45679 on FreeBSD
by
Tomocha Potter
PDF
DSIRNLP #3 LZ4 の速さの秘密に迫ってみる
by
Atsushi KOMIYA
PDF
20230105_TITECH_lecture_ishizaki_public.pdf
by
Kazuaki Ishizaki
PDF
第9回ACRiウェビナー_日立/島田様ご講演資料
by
直久 住川
PDF
ACRi HLSチャレンジ 高速化テクニック紹介
by
Jun Ando
PDF
ネットワークエンジニアはどこでウデマエをみがくのか?
by
Yuya Rin
PPTX
フロー技術によるネットワーク管理
by
Motonori Shindo
PPTX
OVN 設定サンプル | OVN config example 2015/12/27
by
Kentaro Ebisawa
PDF
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
PPTX
Deep Learningのための専用プロセッサ「MN-Core」の開発と活用(2022/10/19東大大学院「 融合情報学特別講義Ⅲ」)
by
Preferred Networks
PDF
CUDAプログラミング入門
by
NVIDIA Japan
PDF
Vivado hls勉強会1(基礎編)
by
marsee101
PDF
TiDBのトランザクション
by
Akio Mitobe
PDF
Cloud runのオートスケールを検証してみる
by
虎の穴 開発室
PPTX
え、まって。その並列分散処理、Kafkaのしくみでもできるの? Apache Kafkaの機能を利用した大規模ストリームデータの並列分散処理
by
NTT DATA Technology & Innovation
PDF
PostgreSQLをKubernetes上で活用するためのOperator紹介!(Cloud Native Database Meetup #3 発表資料)
by
NTT DATA Technology & Innovation
PPTX
競プロでGo!
by
鈴木 セシル
Hadoop/Spark を使うなら Bigtop を使い熟そう! ~並列分散処理基盤のいま、から Bigtop の最近の取り組みまで一挙ご紹介~(Ope...
by
NTT DATA Technology & Innovation
UnboundとNSDの紹介 BIND9との比較編
by
hdais
L3HA-VRRP-20141201
by
Manabu Ori
AS45679 on FreeBSD
by
Tomocha Potter
DSIRNLP #3 LZ4 の速さの秘密に迫ってみる
by
Atsushi KOMIYA
20230105_TITECH_lecture_ishizaki_public.pdf
by
Kazuaki Ishizaki
第9回ACRiウェビナー_日立/島田様ご講演資料
by
直久 住川
ACRi HLSチャレンジ 高速化テクニック紹介
by
Jun Ando
ネットワークエンジニアはどこでウデマエをみがくのか?
by
Yuya Rin
フロー技術によるネットワーク管理
by
Motonori Shindo
OVN 設定サンプル | OVN config example 2015/12/27
by
Kentaro Ebisawa
Transformerを多層にする際の勾配消失問題と解決法について
by
Sho Takase
Deep Learningのための専用プロセッサ「MN-Core」の開発と活用(2022/10/19東大大学院「 融合情報学特別講義Ⅲ」)
by
Preferred Networks
CUDAプログラミング入門
by
NVIDIA Japan
Vivado hls勉強会1(基礎編)
by
marsee101
TiDBのトランザクション
by
Akio Mitobe
Cloud runのオートスケールを検証してみる
by
虎の穴 開発室
え、まって。その並列分散処理、Kafkaのしくみでもできるの? Apache Kafkaの機能を利用した大規模ストリームデータの並列分散処理
by
NTT DATA Technology & Innovation
PostgreSQLをKubernetes上で活用するためのOperator紹介!(Cloud Native Database Meetup #3 発表資料)
by
NTT DATA Technology & Innovation
競プロでGo!
by
鈴木 セシル
Similar to [DL Hacks]FPGA入門
PDF
ICD/CPSY 201412
by
Takefumi MIYOSHI
PPTX
研究者のための Python による FPGA 入門
by
ryos36
PPTX
FPGAって、何?
by
Toyohiko Komatsu
PDF
ソフトウェア技術者はFPGAをどのように使うか
by
なおき きしだ
PDF
Halide, Darkroom - 並列化のためのソフトウェア・研究
by
Yuichi Yoshida
PDF
ACRi_webinar_20220118_miyo
by
Takefumi MIYOSHI
PPTX
Myoshimi extreme
by
Masato Yoshimi
PDF
FPGA startup 第一回 LT
by
Yamato Kazuhiro
PPTX
FPGAことはじめ
by
Takahiro Nakayama
PDF
FPGAのトレンドをまとめてみた
by
Takefumi MIYOSHI
PPTX
動き検出勉強会リメイク。過去の発表のリメイク版です。動き検出のアルゴリズムとOpencvのオプションについてまとめました
by
natsutan0
PDF
FPGAを用いた世界最速のソーティングハードウェアの実現に向けた試み
by
Ryohei Kobayashi
PDF
「FPGA 開発入門:FPGA を用いたエッジ AI の高速化手法を学ぶ」
by
直久 住川
PDF
2値ディープニューラルネットワークと組込み機器への応用: 開発中のツール紹介
by
Hiroki Nakahara
PDF
Sw技術者に送るfpga入門
by
直久 住川
PPTX
Fpga programming introduction
by
YukiFukuda3
PDF
Zenkoku78
by
Takuma Usui
PDF
Python physicalcomputing
by
Noboru Irieda
PPT
20140310 fpgax
by
funadasatoshi
PPTX
Abstracts of FPGA2017 papers (Temporary Version)
by
Takefumi MIYOSHI
ICD/CPSY 201412
by
Takefumi MIYOSHI
研究者のための Python による FPGA 入門
by
ryos36
FPGAって、何?
by
Toyohiko Komatsu
ソフトウェア技術者はFPGAをどのように使うか
by
なおき きしだ
Halide, Darkroom - 並列化のためのソフトウェア・研究
by
Yuichi Yoshida
ACRi_webinar_20220118_miyo
by
Takefumi MIYOSHI
Myoshimi extreme
by
Masato Yoshimi
FPGA startup 第一回 LT
by
Yamato Kazuhiro
FPGAことはじめ
by
Takahiro Nakayama
FPGAのトレンドをまとめてみた
by
Takefumi MIYOSHI
動き検出勉強会リメイク。過去の発表のリメイク版です。動き検出のアルゴリズムとOpencvのオプションについてまとめました
by
natsutan0
FPGAを用いた世界最速のソーティングハードウェアの実現に向けた試み
by
Ryohei Kobayashi
「FPGA 開発入門:FPGA を用いたエッジ AI の高速化手法を学ぶ」
by
直久 住川
2値ディープニューラルネットワークと組込み機器への応用: 開発中のツール紹介
by
Hiroki Nakahara
Sw技術者に送るfpga入門
by
直久 住川
Fpga programming introduction
by
YukiFukuda3
Zenkoku78
by
Takuma Usui
Python physicalcomputing
by
Noboru Irieda
20140310 fpgax
by
funadasatoshi
Abstracts of FPGA2017 papers (Temporary Version)
by
Takefumi MIYOSHI
More from Deep Learning JP
PPTX
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
PPTX
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
PPTX
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
PPTX
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
PPTX
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
PPTX
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
PDF
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
PPTX
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
PDF
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PPTX
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
PDF
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
PDF
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
PPTX
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
PPTX
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
PDF
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
PPTX
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
PDF
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
PDF
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
PPTX
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
【DL輪読会】AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
by
Deep Learning JP
【DL輪読会】事前学習用データセットについて
by
Deep Learning JP
【DL輪読会】 "Learning to render novel views from wide-baseline stereo pairs." CVP...
by
Deep Learning JP
【DL輪読会】Zero-Shot Dual-Lens Super-Resolution
by
Deep Learning JP
【DL輪読会】BloombergGPT: A Large Language Model for Finance arxiv
by
Deep Learning JP
【DL輪読会】マルチモーダル LLM
by
Deep Learning JP
【 DL輪読会】ToolLLM: Facilitating Large Language Models to Master 16000+ Real-wo...
by
Deep Learning JP
【DL輪読会】AnyLoc: Towards Universal Visual Place Recognition
by
Deep Learning JP
【DL輪読会】Can Neural Network Memorization Be Localized?
by
Deep Learning JP
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
【DL輪読会】SimPer: Simple self-supervised learning of periodic targets( ICLR 2023 )
by
Deep Learning JP
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
【DL輪読会】"Language Instructed Reinforcement Learning for Human-AI Coordination "
by
Deep Learning JP
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
【DL輪読会】"Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware"
by
Deep Learning JP
【DL輪読会】Parameter is Not All You Need:Starting from Non-Parametric Networks fo...
by
Deep Learning JP
【DL輪読会】Drag Your GAN: Interactive Point-based Manipulation on the Generative ...
by
Deep Learning JP
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
【DL輪読会】Towards Understanding Ensemble, Knowledge Distillation and Self-Distil...
by
Deep Learning JP
[DL Hacks]FPGA入門
1.
FPGA入門 システム情報学専攻 修士2年 上野 洋典
2.
FPGAとは • Field Programmable
Gate Array • 動作を書き換えられるデジタル回路の集合体 • 大雑把に言うとANDとかORとかが数万個~数百万個詰まってる • 並列計算が得意 • 自分だけの高速並列計算機が作れる • 機械学習と相性良し ◯ × CPU ソフト開発者たくさん。クロック最速(数GHz) 汎用品の限界。ノイマンボトルネック。ク ロックもう伸びない GPU 大量の数値演算なら最強。ソフト開発者が扱える。クロック速い(1GHz位) 汎用品の限界。電力食い過ぎ(200W) ASIC 自由に専用設計できる。低消費電力(uW~W) 修正できないので開発が大がかり。1~2年+ 数億円かかる。コストの8割が検証作業 FPGA 自由に専用設計できる。低消費電力(mW~W)。いつでも仕様変更・バグ修 正できる。1万円で試せる手軽さ ソフト開発者には難しい。クロック遅い(数 100MHz)。集積度低い https://qiita.com/kazunori279/items/a9e97a4463cab7dda8b9
3.
FPGAのインパクト • 2015年,IntelがFPGA大手のAlteraを2兆円で買収 • MicrosoftのBing検索がFPGAによって2倍高速化 •
杉山研佐藤先生の成果もFPGA
4.
今回使うボード • Xilinx Zynq-7000
ZC702 • ARM Cortex-A9 周波数: ~1GHz • 1GB DDR3 memory • 28mm programmable Logic • Configurable Logic Block • 36Kb RAM • Digital signal processor (乗算器等) • etc • ツール込みで900ドルくらい
5.
なぜ早い? CPU 数GHz FPGA y[0] = x[0]
* x[0]; y[1] = x[1] * x[1]; ・・・ y[999] = x[999] * x[999]; x[0] * y[0] x[1] * y[1] x[999] * y[999] ・・・
6.
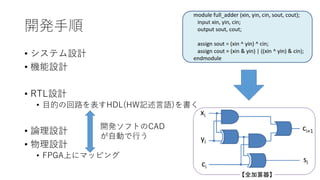
開発手順 • システム設計 • 機能設計 •
RTL設計 • 目的の回路を表すHDL(HW記述言語)を書く • 論理設計 • 物理設計 • FPGA上にマッピング 開発ソフトのCAD が自動で行う
7.
HDLによる開発 • 考えること • データパス •
スケジューリング • 状態遷移 • etc… 2値化CNNなDQNをFPGAで動かしてみた 中原啓貴 https://www.slideshare.net/HirokiNakahara1/tensor-flow-usergroup-2016
8.
高位合成 • C/C++等の高級言語からHDLを生 成する技術 • コンパイルには時間がかかる •
関数単位で行う • アプリケーションの内,一部はCPU で,一部はPLで実行 • FPGA化する関数は色々な制約あり • ダブルポインタ使えない • グローバル変数使えない • 引数の配列サイズの明示 など FPGA化
9.
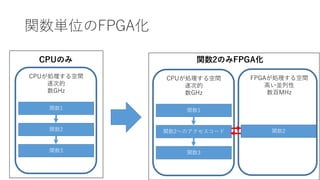
関数単位のFPGA化 CPUのみ 関数2のみFPGA化 関数1 関数2 関数3 CPUが処理する空間 逐次的 数GHz 関数1 関数2へのアクセスコード 関数3 CPUが処理する空間 逐次的 数GHz 関数2 FPGAが処理する空間 高い並列性 数百MHz
10.
実装 • 右の書籍に沿って行う • 3層CNNをC言語で実装しFPGA化 •
犬猫の2クラス分類 • Train: 100枚, Test: 20枚 関数構成 main() ├ ReadBMP() ├ CNN() │ ├ CNNLayer() │ │ ├ Convolution() │ │ │ └ CalcConvolution() │ │ └ Pooling() │ │ └ MaxPooling() │ └Perceptron() ├ HiddenLearning() └ OutLearning() ソースコード https://github.com/aquaxis/CNNFPGA
11.
実行時間: CPUのみで実行 • CPU(Zynq上のARM)のみで実行した場合 •
40ms / dataの実行時間 • FPGA化によってこれを処理時間を 早くしたい 関数構成 main() ├ ReadBMP() ├ CNN() │ ├ CNNLayer() │ │ ├ Convolution() │ │ │ └ CalcConvolution() │ │ └ Pooling() │ │ └ MaxPooling() │ └Perceptron() ├ HiddenLearning() └ OutLearning()
12.
CalcConvolution()のみをFPGA化 • 「何も考えずに」Calc~()をFPGA化 • 2130ms
/ data • 50倍遅い! • メモリ転送がネックになっている • 周波数が遅い分より効いている 関数構成 main() ├ ReadBMP() ├ CNN() │ ├ CNNLayer() │ │ ├ Convolution() │ │ │ └ CalcConvolution() │ │ └ Pooling() │ │ └ MaxPooling() │ └Perceptron() ├ HiddenLearning() └ OutLearning() filter[0] filter[1] filter[2] filter[3]・・・ FPGAによる 処理実行時間 メモリ
13.
CalcConvolution()のみをFPGA化 • 「少し考えて」Calc~()をFPGA化 • 243ms
/ data • さっきよりマシだがまだ遅い • 配列をまとめて転送 • #pragma SDS data access_pattern(filter:SEQUENTIAL) 関数構成 main() ├ ReadBMP() ├ CNN() │ ├ CNNLayer() │ │ ├ Convolution() │ │ │ └ CalcConvolution() │ │ └ Pooling() │ │ └ MaxPooling() │ └Perceptron() ├ HiddenLearning() └ OutLearning() filter[0] filter[1] filter[2] filter[3]・・・ FPGAによる 処理実行時間 メモリ
14.
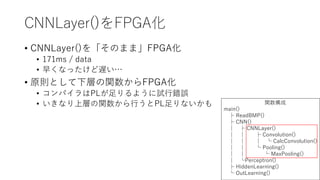
CNNLayer()をFPGA化 • CNNLayer()を「そのまま」FPGA化 • 171ms
/ data • 早くなったけど遅い… • 原則として下層の関数からFPGA化 • コンパイラはPLが足りるように試行錯誤 • いきなり上層の関数から行うとPL足りないかも 関数構成 main() ├ ReadBMP() ├ CNN() │ ├ CNNLayer() │ │ ├ Convolution() │ │ │ └ CalcConvolution() │ │ └ Pooling() │ │ └ MaxPooling() │ └Perceptron() ├ HiddenLearning() └ OutLearning()
15.
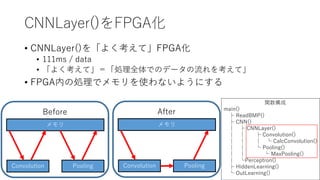
CNNLayer()をFPGA化 • CNNLayer()を「よく考えて」FPGA化 • 111ms
/ data • 「よく考えて」=「処理全体でのデータの流れを考えて」 • FPGA内の処理でメモリを使わないようにする 関数構成 main() ├ ReadBMP() ├ CNN() │ ├ CNNLayer() │ │ ├ Convolution() │ │ │ └ CalcConvolution() │ │ └ Pooling() │ │ └ MaxPooling() │ └Perceptron() ├ HiddenLearning() └ OutLearning() メモリ Convolution Pooling Before メモリ Convolution Pooling After
16.
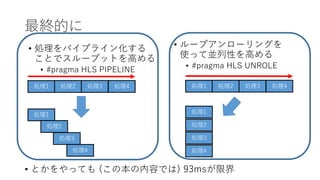
最終的に • とかをやっても (この本の内容では)
93msが限界 • ループアンローリングを 使って並列性を高める • #pragma HLS UNROLE 処理1 処理2 処理3 処理4 処理1 処理2 処理3 処理4 処理1 処理2 処理3 処理4 処理1 処理2 処理3 処理4 • 処理をパイプライン化する ことでスループットを高める • #pragma HLS PIPELINE
17.
感想 • FPGA化すれば何でも早くなるというのは幻想 • 職人技が必要 •
そもそもFPGAが不向きな計算もある • 結局高速化にはハードウェアの知識は最低限必要 • 高位合成のおかげでだいぶ軽減はされている • 別件でHDLで4bit CPU作ってみたけど楽しかった
18.
Pynqボード • Pythonで高位合成ができるボード! • ARMチップとPLあり •
ARM上のLinuxでjupyter notebookも動く • LAN経由でアクセス可能 • 右上のコードだけでLチカできる! • 229ドル+送料 • アカデミック割で65ドル+送料
19.
まとめ • SW寄りの人も知っておく価値はあり • HDLは書けなくても大丈夫だと思う… •
DLのソフトだけやっててもなあ…って人はぜひ • Pynqボード面白そう • 需要ありそうなら動かした感想をLTで
20.
参考文献 • そろそろプログラマーもFPGAを触ってみよう! • https://qiita.com/kazunori279/items/a9e97a4463cab7dda8b9 •
2値化CNNなDQNをFPGAで動かしてみた • https://www.slideshare.net/HirokiNakahara1/tensor-flow- usergroup-2016 • ソフトウェア技術者から見たFPGAの魅力と可能性 • https://www.slideshare.net/MITSUDA_Kenichiro/fpga2018 • ソフトウェア技術者のためのFPGA入門 石原ひでみ • https://nextpublishing.jp/book/9219.html
Download





![なぜ早い?
CPU
数GHz
FPGA
y[0] = x[0] * x[0];
y[1] = x[1] * x[1];
・・・
y[999] = x[999] * x[999];
x[0] * y[0]
x[1] * y[1]
x[999] * y[999]
・・・](https://image.slidesharecdn.com/dlhacksfpgabeginner-180627050145/85/DL-Hacks-FPGA-5-320.jpg)




![CalcConvolution()のみをFPGA化
• 「何も考えずに」Calc~()をFPGA化
• 2130ms / data
• 50倍遅い!
• メモリ転送がネックになっている
• 周波数が遅い分より効いている
関数構成
main()
├ ReadBMP()
├ CNN()
│ ├ CNNLayer()
│ │ ├ Convolution()
│ │ │ └ CalcConvolution()
│ │ └ Pooling()
│ │ └ MaxPooling()
│ └Perceptron()
├ HiddenLearning()
└ OutLearning()
filter[0]
filter[1]
filter[2]
filter[3]・・・
FPGAによる
処理実行時間
メモリ](https://image.slidesharecdn.com/dlhacksfpgabeginner-180627050145/85/DL-Hacks-FPGA-12-320.jpg)
![CalcConvolution()のみをFPGA化
• 「少し考えて」Calc~()をFPGA化
• 243ms / data
• さっきよりマシだがまだ遅い
• 配列をまとめて転送
• #pragma SDS data access_pattern(filter:SEQUENTIAL)
関数構成
main()
├ ReadBMP()
├ CNN()
│ ├ CNNLayer()
│ │ ├ Convolution()
│ │ │ └ CalcConvolution()
│ │ └ Pooling()
│ │ └ MaxPooling()
│ └Perceptron()
├ HiddenLearning()
└ OutLearning()
filter[0]
filter[1]
filter[2]
filter[3]・・・
FPGAによる
処理実行時間
メモリ](https://image.slidesharecdn.com/dlhacksfpgabeginner-180627050145/85/DL-Hacks-FPGA-13-320.jpg)