Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
直住
Uploaded by
直久 住川
430 views
第9回ACRiウェビナー_日立/島田様ご講演資料
第9回ACRiウェビナー_日立/島田様ご講演資料
Engineering
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Downloaded 14 times
1
/ 11
2
/ 11
3
/ 11
4
/ 11
5
/ 11
6
/ 11
7
/ 11
8
/ 11
9
/ 11
10
/ 11
11
/ 11
More Related Content
PDF
第9回ACRiウェビナー_セック/岩渕様ご講演資料
by
直久 住川
PDF
CTF for ビギナーズ ネットワーク講習資料
by
SECCON Beginners
PPTX
モデル高速化百選
by
Yusuke Uchida
PDF
SAT/SMTソルバの仕組み
by
Masahiro Sakai
PPTX
DeClang 誕生!Clang ベースのハッキング対策コンパイラ【DeNA TechCon 2020 ライブ配信】
by
DeNA
PDF
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
PDF
PFNのML/DL基盤を支えるKubernetesにおける自動化 / DevOpsDays Tokyo 2021
by
Preferred Networks
PDF
高速な倍精度指数関数expの実装
by
MITSUNARI Shigeo
第9回ACRiウェビナー_セック/岩渕様ご講演資料
by
直久 住川
CTF for ビギナーズ ネットワーク講習資料
by
SECCON Beginners
モデル高速化百選
by
Yusuke Uchida
SAT/SMTソルバの仕組み
by
Masahiro Sakai
DeClang 誕生!Clang ベースのハッキング対策コンパイラ【DeNA TechCon 2020 ライブ配信】
by
DeNA
【DL輪読会】Self-Supervised Learning from Images with a Joint-Embedding Predictive...
by
Deep Learning JP
PFNのML/DL基盤を支えるKubernetesにおける自動化 / DevOpsDays Tokyo 2021
by
Preferred Networks
高速な倍精度指数関数expの実装
by
MITSUNARI Shigeo
What's hot
PDF
Magnum IO GPUDirect Storage 最新情報
by
NVIDIA Japan
PDF
Automatic Mixed Precision の紹介
by
Kuninobu SaSaki
PDF
2値ディープニューラルネットワークと組込み機器への応用: 開発中のツール紹介
by
Hiroki Nakahara
PPTX
女の子になれなかった人のために
by
京大 マイコンクラブ
PDF
SSII2019OS: 深層学習にかかる時間を短くしてみませんか? ~分散学習の勧め~
by
SSII
PDF
CTF超入門 (for 第12回セキュリティさくら)
by
kikuchan98
PDF
2値化CNN on FPGAでGPUとガチンコバトル(公開版)
by
Hiroki Nakahara
PDF
最近のディープラーニングのトレンド紹介_20200925
by
小川 雄太郎
PDF
[Dl輪読会]dl hacks輪読
by
Deep Learning JP
PPTX
[DL輪読会] MoCoGAN: Decomposing Motion and Content for Video Generation
by
Deep Learning JP
PDF
バイナリニューラルネットとハードウェアの関係
by
Kento Tajiri
PDF
研究室における研究・実装ノウハウの共有
by
Naoaki Okazaki
PDF
CV分野におけるサーベイ方法
by
Hirokatsu Kataoka
PDF
[DL輪読会]Relational inductive biases, deep learning, and graph networks
by
Deep Learning JP
PDF
マルチコアを用いた画像処理
by
Norishige Fukushima
PDF
[DL輪読会]"CyCADA: Cycle-Consistent Adversarial Domain Adaptation"&"Learning Se...
by
Deep Learning JP
PDF
【DL輪読会】Egocentric Video Task Translation (CVPR 2023 Highlight)
by
Deep Learning JP
PPTX
【DL輪読会】Flamingo: a Visual Language Model for Few-Shot Learning 画像×言語の大規模基盤モ...
by
Deep Learning JP
PPTX
【DL輪読会】時系列予測 Transfomers の精度向上手法
by
Deep Learning JP
PDF
(DL輪読)Variational Dropout Sparsifies Deep Neural Networks
by
Masahiro Suzuki
Magnum IO GPUDirect Storage 最新情報
by
NVIDIA Japan
Automatic Mixed Precision の紹介
by
Kuninobu SaSaki
2値ディープニューラルネットワークと組込み機器への応用: 開発中のツール紹介
by
Hiroki Nakahara
女の子になれなかった人のために
by
京大 マイコンクラブ
SSII2019OS: 深層学習にかかる時間を短くしてみませんか? ~分散学習の勧め~
by
SSII
CTF超入門 (for 第12回セキュリティさくら)
by
kikuchan98
2値化CNN on FPGAでGPUとガチンコバトル(公開版)
by
Hiroki Nakahara
最近のディープラーニングのトレンド紹介_20200925
by
小川 雄太郎
[Dl輪読会]dl hacks輪読
by
Deep Learning JP
[DL輪読会] MoCoGAN: Decomposing Motion and Content for Video Generation
by
Deep Learning JP
バイナリニューラルネットとハードウェアの関係
by
Kento Tajiri
研究室における研究・実装ノウハウの共有
by
Naoaki Okazaki
CV分野におけるサーベイ方法
by
Hirokatsu Kataoka
[DL輪読会]Relational inductive biases, deep learning, and graph networks
by
Deep Learning JP
マルチコアを用いた画像処理
by
Norishige Fukushima
[DL輪読会]"CyCADA: Cycle-Consistent Adversarial Domain Adaptation"&"Learning Se...
by
Deep Learning JP
【DL輪読会】Egocentric Video Task Translation (CVPR 2023 Highlight)
by
Deep Learning JP
【DL輪読会】Flamingo: a Visual Language Model for Few-Shot Learning 画像×言語の大規模基盤モ...
by
Deep Learning JP
【DL輪読会】時系列予測 Transfomers の精度向上手法
by
Deep Learning JP
(DL輪読)Variational Dropout Sparsifies Deep Neural Networks
by
Masahiro Suzuki
Similar to 第9回ACRiウェビナー_日立/島田様ご講演資料
PDF
2012研究室紹介(大川)
by
猛 大川
PDF
Synthesijer fpgax 20150201
by
Takefumi MIYOSHI
PDF
Zenkoku78
by
Takuma Usui
PPTX
Myoshimi extreme
by
Masato Yoshimi
PDF
[DL Hacks]FPGA入門
by
Deep Learning JP
PDF
FPGAを用いた世界最速のソーティングハードウェアの実現に向けた試み
by
Ryohei Kobayashi
PPTX
Starc verilog hdl2013d
by
Kiyoshi Ogawa
PDF
多数の小容量FPGAを用いた スケーラブルなステンシル計算機の開発
by
Ryohei Kobayashi
PDF
FPGAベースのソーティングアクセラレータの設計と実装
by
Ryohei Kobayashi
PDF
ACRi_webinar_20220118_miyo
by
Takefumi MIYOSHI
PDF
IEICE technical report (RECONF), January 2015.
by
Takuma Usui
PDF
ACRiポジショントーク_山科.pdf
by
直久 住川
PDF
High-speed Sorting using Portable FPGA Accelerator (IPSJ 77th National Conven...
by
Takuma Usui
PPTX
ソフトウェア志向の組込みシステム協調設計環境
by
Hideki Takase
PDF
発表資料 Fortranを用いた高位合成技術FortRockの開発
by
貴大 山下
PDF
FPGAをロボット(ROS)で「やわらかく」使うには
by
Hideki Takase
PDF
Fpga online seminar by fixstars (1st)
by
Fixstars Corporation
PDF
Tuning, etc.
by
Hiroshi Watanabe
PDF
アルゴリズムのハードウェア化から学ぶ問題解決教育プログラム
by
情報処理学会 情報システム教育委員会
PDF
Halide, Darkroom - 並列化のためのソフトウェア・研究
by
Yuichi Yoshida
2012研究室紹介(大川)
by
猛 大川
Synthesijer fpgax 20150201
by
Takefumi MIYOSHI
Zenkoku78
by
Takuma Usui
Myoshimi extreme
by
Masato Yoshimi
[DL Hacks]FPGA入門
by
Deep Learning JP
FPGAを用いた世界最速のソーティングハードウェアの実現に向けた試み
by
Ryohei Kobayashi
Starc verilog hdl2013d
by
Kiyoshi Ogawa
多数の小容量FPGAを用いた スケーラブルなステンシル計算機の開発
by
Ryohei Kobayashi
FPGAベースのソーティングアクセラレータの設計と実装
by
Ryohei Kobayashi
ACRi_webinar_20220118_miyo
by
Takefumi MIYOSHI
IEICE technical report (RECONF), January 2015.
by
Takuma Usui
ACRiポジショントーク_山科.pdf
by
直久 住川
High-speed Sorting using Portable FPGA Accelerator (IPSJ 77th National Conven...
by
Takuma Usui
ソフトウェア志向の組込みシステム協調設計環境
by
Hideki Takase
発表資料 Fortranを用いた高位合成技術FortRockの開発
by
貴大 山下
FPGAをロボット(ROS)で「やわらかく」使うには
by
Hideki Takase
Fpga online seminar by fixstars (1st)
by
Fixstars Corporation
Tuning, etc.
by
Hiroshi Watanabe
アルゴリズムのハードウェア化から学ぶ問題解決教育プログラム
by
情報処理学会 情報システム教育委員会
Halide, Darkroom - 並列化のためのソフトウェア・研究
by
Yuichi Yoshida
More from 直久 住川
PDF
20th ACRi Webinar - Kyoto SU Oura-san Presentation
by
直久 住川
PDF
20th ACRi Webinar - Kyoto SU Presentation
by
直久 住川
PDF
20th ACRi Webiner - Presentation by MathWorks
by
直久 住川
PDF
18th ACRi Webinar : Presentation Slide ; Fukuda-san, ChipTip Technology
by
直久 住川
PDF
18th ACRi Webinar : Presentation Material - Prof. Yamaguchi
by
直久 住川
PDF
16th_ACRi_Webinar_Kumamoto-Univ_Okawa_20240308.pdf
by
直久 住川
PDF
16th_ACRi_Webiner_SEC_Takebe_20240308.pdf
by
直久 住川
PDF
17th_ACRi_Webinar_Sadasue-san_Slide_20240724
by
直久 住川
PDF
公開用_講演資料_SCSK.pdf
by
直久 住川
PDF
ACRi-Webinar_Feb2023_agenda_20230225.pdf
by
直久 住川
PDF
第11回ACRiウェビナー_東工大/坂本先生ご講演資料
by
直久 住川
PDF
第11回ACRiウェビナー_インテル/竹村様ご講演資料
by
直久 住川
PDF
2022-12-17-room.pdf
by
直久 住川
PDF
ACRiルーム副室長_安藤様_講演資料
by
直久 住川
PDF
DSF実行委員長_酒井様_講演資料
by
直久 住川
PDF
ACRi事務局_住川_講演資料
by
直久 住川
PDF
VCK5000_Webiner_GIGABYTE様ご講演資料
by
直久 住川
PDF
AMD_Xilinx_AI_VCK5000_20220602R1.pdf
by
直久 住川
PDF
VCK5000_Webiner_Fixstars様ご講演資料
by
直久 住川
PDF
20220525_kobayashi.pdf
by
直久 住川
20th ACRi Webinar - Kyoto SU Oura-san Presentation
by
直久 住川
20th ACRi Webinar - Kyoto SU Presentation
by
直久 住川
20th ACRi Webiner - Presentation by MathWorks
by
直久 住川
18th ACRi Webinar : Presentation Slide ; Fukuda-san, ChipTip Technology
by
直久 住川
18th ACRi Webinar : Presentation Material - Prof. Yamaguchi
by
直久 住川
16th_ACRi_Webinar_Kumamoto-Univ_Okawa_20240308.pdf
by
直久 住川
16th_ACRi_Webiner_SEC_Takebe_20240308.pdf
by
直久 住川
17th_ACRi_Webinar_Sadasue-san_Slide_20240724
by
直久 住川
公開用_講演資料_SCSK.pdf
by
直久 住川
ACRi-Webinar_Feb2023_agenda_20230225.pdf
by
直久 住川
第11回ACRiウェビナー_東工大/坂本先生ご講演資料
by
直久 住川
第11回ACRiウェビナー_インテル/竹村様ご講演資料
by
直久 住川
2022-12-17-room.pdf
by
直久 住川
ACRiルーム副室長_安藤様_講演資料
by
直久 住川
DSF実行委員長_酒井様_講演資料
by
直久 住川
ACRi事務局_住川_講演資料
by
直久 住川
VCK5000_Webiner_GIGABYTE様ご講演資料
by
直久 住川
AMD_Xilinx_AI_VCK5000_20220602R1.pdf
by
直久 住川
VCK5000_Webiner_Fixstars様ご講演資料
by
直久 住川
20220525_kobayashi.pdf
by
直久 住川
第9回ACRiウェビナー_日立/島田様ご講演資料
1.
1 © Hitachi, Ltd.
2022. All rights reserved. 株式会社 日立製作所 研究開発グループ デジタルプラットフォームイノベーションセンタ データストレージ研究部 2022/7/26 島田 健太郎 複雑なアルゴリズムのハード化における高位合成の活用事例 第9回ACRiウェビナー © Hitachi, Ltd. 2022. All rights reserved. 1. 自己紹介 2. 背景:複雑なアルゴリズムのハード化における課題・高位合成の利点 3. 題材:圧縮アルゴリズムLZMA 4. 課題:高位合成の初期試行状況 5. 施策①:メモリアクセス幅拡大 6. 施策②:データフロー化 7. 施策③:文字列比較ループアンローリング 8. 評価:本事例における改善施策の効果 9. 高位合成の活用まとめ Contents 1 0 1
2.
2 2 © Hitachi, Ltd.
2022. All rights reserved. 1.自己紹介 島田 健太郎 研究開発グループ デジタルプラットフォームイノベーションセンタ データストレージ研究部 所属 • 1993年入社 • 入社当初は、スーパーコンピュータのプロセッサの設計開発に従事 • その後、ハードウェア・アーキテクチャの研究開発に従事 • 論理設計は、ASICで、RTLやゲートレベル設計/スケマティックな設計を経験 • 今回、FPGAを用いて複雑なアルゴリズムをハード化するに当たり、高位合成の活用を行った ゲートレベル設計/スケマティック設計 Adder(int a, int b, int c) { c = a + b; } 高位合成(高位言語記述) a b c 3 © Hitachi, Ltd. 2022. All rights reserved. 2.1 背景(1):複雑なアルゴリズムのハード化における課題 1. 複雑なアルゴリズムをハード化する場合、通常のRTL設計であると、詳細設計・実装設計を含め、 多大な開発工数を要し、ハード化の見通しを得るのに⾧期間かかる 2. 設計当初の段階(仕様設計/機能設計段階)では、性能や物量の見通しが困難 3. 設計した結果を性能等評価できるのが、後工程となり、フィードバックを行う工数大 4. 更に元のアルゴリズムレベルでの最適化を行うと、多大な再設計の工数が発生 詳細設計 (RTL設計) 実装設計 FPGA 論理合成 仕様設計/機能設計 RTL 記述 実装結果 •性能(詳細) •物量(詳細) 機能仕様/アルゴリズム 改善/最適化(フィードバック) (実装改善) 実装情報 (部分的RTL改善) アルゴリズムレベル改善⇒大工数発生 RTL設計過程(イメージ) 2 3
3.
3 4 © Hitachi, Ltd.
2022. All rights reserved. 2.2 背景(2):複雑なアルゴリズムのハード化における高位合成の利点 1. 高位言語で記述された複雑なアルゴリズムでも、短期間でハードウェア化の見通しが得られる 2. 最低限達成可能な、性能や物量が早期にわかる 3. 性能や物量を、早期にプロファイルデータから見ることにより、フィードバックの工数低減可能 4. アルゴリズムレベルでの最適化が容易 Adder(int a, int b, int c) { c = a + b; } 高位合成 合成結果 高位言語ソース (アルゴリズム記述) FPGA プロファイル データ •性能(全体、関数単位) •物量(同上) •詳細データ(依存関係等) 改善/最適化(フィードバック) 仕様設計/機能設計 高位合成設計過程 (イメージ) 5 © Hitachi, Ltd. 2022. All rights reserved. 3. 題材:圧縮アルゴリズム LZMA • 複雑なアルゴリズムへの適用事例として、圧縮アルゴリズム LZMA(Lempel-Ziv-Markov chain-Algorithm)を取 り上げる。 • LZMAは、圧縮率の高い可逆圧縮アルゴリズム。 辞書圧縮部と、レンジコーダによる符号化部からなる。 辞書圧縮部: ①入力データをバイト列として“辞書”に登録 ②”辞書”の内容を探索し、入力データ内の重複を抽出 レンジコーダ: ①データ重複パターンに基づき、0/1の出現確率を予測 ②予測との差分を符号に生成 • ハード化は、辞書探索の制御が複雑になる辞書圧縮部の 方が、確率計算の反復で処理できるレンジコーダより難 A B C D A B C E 入力 データ A B C D E 圧縮 データ 辞書に登録 4文字前と3字一致 図A. 辞書圧縮部の動作例 先 後 A B C D E 圧縮 データ 4文字前と3字一致 0 0 1 0 1 1 1 0 重複パターンを示す 0/1の記号列(中間コード) 図B. レンジコーダの動作例 先行するビットパターンで次の1bitの0/1の 出現確率を予測 予測との差分を 符号に生成 4 5
4.
4 6 © Hitachi, Ltd.
2022. All rights reserved. 4. 課題:高位合成の初期試行状況 • LZMAのオープンソース(C言語)をベースに、高位合成を試行 合成することはできた。 性能は、見積りの約1/40(圧縮処理時間40倍)。 • プロファイルデータより要因分析 最大の要因は、辞書圧縮部で、文字列検索のためのハッシュテーブルを更新する箇所 ⇒1バイトずつアクセスし、更新していた。 その他は、辞書圧縮部とレンジコーダ部が逐次に実行される構造。 ⇒辞書圧縮部がレンジコーダ部の処理完了を待つ。 また、辞書圧縮部の文字列検索自体も1文字ずつ比較。 Adder(int a, int b, int c) { c = a + b; } 高位合成 合成結果 高位言語ソース プロファイル データ 改善/最適化(フィードバック) 7 © Hitachi, Ltd. 2022. All rights reserved. 4. 課題:高位合成の初期試行状況 Adder(int a, int b, int c) { c = a + b; } 高位合成 合成結果 高位言語ソース プロファイル データ 改善/最適化(フィードバック) • LZMAのオープンソース(C言語)をベースに、高位合成を試行 合成することはできた。 性能は、見積りの約1/40(圧縮処理時間40倍)。 • プロファイルデータより要因分析 最大の要因は、辞書圧縮部で、文字列検索のためのハッシュテーブルを更新する箇所 ⇒1バイトずつアクセスし、更新していた。 ①メモリのアクセス幅拡大 その他は、辞書圧縮部とレンジコーダ部が逐次に実行される構造。 ⇒辞書圧縮部がレンジコーダ部の処理完了を待つ。 ②データフロー化 また、辞書圧縮部の文字列検索自体も1文字ずつ比較。 ③文字列比較ループアンローリング 6 7
5.
5 8 © Hitachi, Ltd.
2022. All rights reserved. 5.1 施策①:メモリのアクセス幅拡大(1):概要 コピー元配列 コピー先配列 コピー元配列 コピー先配列 Start i = 0 d[i] = s[i] i < N? End s[] d[] s[] d[] t[] i = i + 1 Start i = 0 t[0] = s[i] t[1] = s[i + 1] ... t[7] = s[i + 7] i < N? End i = i + 8 d[i] = t[0] d[i + 1] = t[1] ... d[i + 7] = t[7] No Yes No Yes • 配列から配列にデータをコピーするケース 配列は、コピー元・コピー先とも、FPGAの内部メモリにマップするケース • 配列から配列へ直接コピーする記述や、ループ・アンローリングがされない 場合に、1要素ずつの逐次コピーになり易い • 途中にレジスタ配列を置き、ループ展開することで複数要素同時にコピー • 配列から配列にデータをコピーするケース 配列は、コピー元・コピー先とも、FPGAの内部メモリにマップするケース • 配列から配列へ直接コピーする記述や、ループ・アンローリングがされない 場合に、1要素ずつの逐次コピーになり易い • 途中にレジスタ配列を置き、ループ展開することで複数要素同時にコピー レジスタ配列 • レジスタ配列を 経由 • ループ・ アンローリング • レジスタ配列を 経由 • ループ・ アンローリング 1要素ずつコピー 複数要素 同時コピー (コピー元/コピー先配列ともFPGA内部 メモリにマップ) 9 © Hitachi, Ltd. 2022. All rights reserved. 5.2 施策①:メモリアクセス幅拡大(2): ハッシュテーブル更新 元の構造 文字列(9文字) 位置 文字列(9文字) ①先頭4文字で ハッシュ値計算 位置 ②一組ずつシフト ③先頭に記録 先 後 ハッシュテーブル 入力データ (辞書) 16bit 8bit×9文字 = 72bit Start ①先頭4文字でハッシュ値を計算 i = 7 i ≧1? ハッシュテーブル[ハッシュ値][i].位置 =ハッシュテーブル[ハッシュ値][i-1].位置 現在位置 j = 0 コピー先文字列[j] = コピー元文字列[j] j = j +1 i = i - 1 j < 9? ハッシュテーブル[ハッシュ値][0].位置 =現在位置 9文字コピー: ハッシュテーブル[ハッシュ値][0].文字列 = 現在位置の文字列 9文字コピー: ハッシュテーブル[ハッシュ値][i].文字列 = ハッシュテーブル[ハッシュ値][i-1].文字列 End 9文字コピー End ②一組ずつシフト ③先頭に記録 • ハッシュテーブルに辞書内の位置と先頭の 9文字ずつが登録されている • 既存内容を移動(シフト)した上で、入力デー タの現在位置からの9文字を新規登録 • ハッシュテーブルに辞書内の位置と先頭の 9文字ずつが登録されている • 既存内容を移動(シフト)した上で、入力デー タの現在位置からの9文字を新規登録 先頭から検査 ハッシュテーブル更新 のフローチャート(元) (サブルーチンで記載) No Yes No Yes (16bit+72bit)×8(シノニム) = 704bit(88byte) 大きなエントリを 1文字(バイト)ずつ 逐次アクセス 8 9
6.
6 10 © Hitachi, Ltd.
2022. All rights reserved. 5.3 施策①:メモリアクセス幅拡大(3):ハッシュテーブル更新 改善策 • ハッシュテーブルを、位置の情報のテーブルと 文字列のテーブルに分割 • エントリ(位置+文字列8組分)をレジスタに ずらして読上げ、書き戻す • ハッシュテーブルを、位置の情報のテーブルと 文字列のテーブルに分割 • エントリ(位置+文字列8組分)をレジスタに ずらして読上げ、書き戻す 位置 16bit 位置 16bit×8 = 128bit 位置 72bit×8 = 576bit ①先頭4文字で ハッシュ値計算 ②ずらして読み上げ ③先頭に格納 先 後 ハッシュテーブル (分割後) 入力データ (辞書) 16bit 8bit×9文字 = 72bit 現在位置 先頭から検査 文字列(9文字) レジスタ ④書き戻し Start ①先頭4文字でハッシュ値を計算 i = 7 i ≧1? レジスタ(位置)[i] =ハッシュテーブル(位置)[ハッシュ値][i-1] i = i - 1 レジスタ(位置)[0] = 現在位置 9文字コピー(プラグマでアンローリング) レジスタ(文字列)[0]=現在位置の文字列 9文字コピー(プラグマでアンローリング) レジスタ(文字列)[i] = ハッシュテーブル(文字列)[ハッシュ値][i-1] End ②ずらして読み上げ ③先頭に格納 ハッシュテーブル更新の フローチャート(改善版) 位置、文字列をそれぞれ 並列にアクセス No Yes ハッシュテーブル(位置)[ハッシュ値][0~7] = レジスタ(位置)[0~7] 9文字コピー(プラグマでアンローリング)×8: ハッシュテーブル(文字列)[ハッシュ値][0~7] = レジスタ(文字列)[0~7] ④書き戻し ② ④ ③ 11 © Hitachi, Ltd. 2022. All rights reserved. 6.1 施策②:データフロー化(1) データーフロー化適用前 • 二つの処理を含むループ • それぞれの処理の間で、変数を用いて、一方から他方へデータを受け渡し ⇒それぞれの回路が逐次動作となる • 二つの処理を含むループ • それぞれの処理の間で、変数を用いて、一方から他方へデータを受け渡し ⇒それぞれの回路が逐次動作となる Start 初期化処理 処理a 終了判定 処理b End 終了処理 変数 変数 変数 初期化処理 回路 処理a 回路 処理b 回路 判定回路 終了処理 回路 初期データ 中間データ 出力データ 繰返し 信号 終了データ 時間軸 T1 T2 T3 T4 T5 T6 T7 T8 初期化回路 動作 処理a 回路 動作 動作 動作 処理b 回路 動作 動作 判定回路 動作 動作 終了処理回路 逐次動作:3サイクルピッチ 処理フローチャート 回路構成 10 11
7.
7 12 © Hitachi, Ltd.
2022. All rights reserved. 6.2 施策②:データフロー化(2) データフロー化適用後 • 二つの処理のループを分割 • 分割したループの処理の間で、FIFO(ストリーム変数)を用いてデータを受け渡し ⇒それぞれの回路の並列動作が可能となる • 二つの処理のループを分割 • 分割したループの処理の間で、FIFO(ストリーム変数)を用いてデータを受け渡し ⇒それぞれの回路の並列動作が可能となる Start 初期化処理 処理a 終了判定b 処理b End 終了処理 変数 変数 初期化処理 回路 処理a 回路 処理b 回路 判定b回路 終了処理 回路 初期データ 中間データ 出力データ 繰返し 信号 終了データ 時間軸 T1 T2 T3 T4 T5 T6 T7 T8 初期化回路 動作 処理a 回路 動作 動作 動作 動作 判定a回路 動作 動作 動作 処理b 回路 動作 動作 動作 判定b回路 動作 動作 終了処理回路 終了判定a 判定a回路 中間データ 中間データ FIFO 繰返し 信号 FIFO 並列(オーバーラップ)動作: 2サイクルピッチ 13 © Hitachi, Ltd. 2022. All rights reserved. 6.3 施策②:データフロー化(3) LZMAにおける適用 • 辞書圧縮部と、レンジコーダの呼び出しに適用 ⇒辞書圧縮部と、レンジコーダを並列動作させ、動作時間をほぼ半減 • 辞書圧縮部と、レンジコーダの呼び出しに適用 ⇒辞書圧縮部と、レンジコーダを並列動作させ、動作時間をほぼ半減 Start 辞書圧縮部 終了? レンジコーダ End Start 辞書圧縮部 終了? レンジコーダ End 終了? No Yes No Yes 時間軸 T1 T2 T3 T4 T5 T6 辞書圧縮部 動作 動作 動作 レンジコーダ 動作 動作 動作 辞書圧縮回路 レンジコーダ回路 中間データ 圧縮データ 平文データ 繰返し 信号 No Yes 時間軸 T1 T2 T3 T4 T5 T6 辞書圧縮部 動作 動作 動作 動作 動作 動作 レンジコーダ 動作 動作 動作 動作 動作 FIFO 辞書圧縮回路 レンジコーダ回路 中間データ 圧縮データ 平文データ FIFO 中間データ 12 13
8.
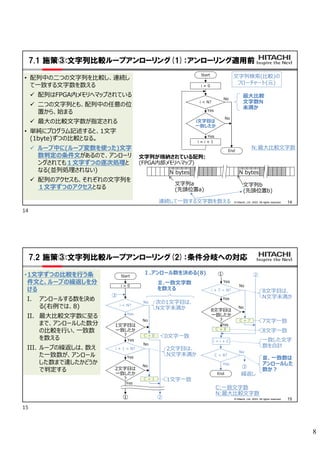
8 14 © Hitachi, Ltd.
2022. All rights reserved. 7.1 施策③:文字列比較ループアンローリング(1):アンローリング適用前 • 配列中の二つの文字列を比較し、連続し て一致する文字数を数える 配列はFPGA内メモリへマップされている 二つの文字列とも、配列中の任意の位 置から、始まる 最大の比較文字数が指定される • 単純にプログラム記述すると、1文字 (1byte)ずつの比較となる。 ループ中に(ループ変数を使った)文字 数判定の条件文があるので、アンローリ ングされても1文字ずつの逐次処理と なる(並列処理されない) 配列のアクセスも、それぞれの文字列を 1文字ずつのアクセスとなる • 配列中の二つの文字列を比較し、連続し て一致する文字数を数える 配列はFPGA内メモリへマップされている 二つの文字列とも、配列中の任意の位 置から、始まる 最大の比較文字数が指定される • 単純にプログラム記述すると、1文字 (1byte)ずつの比較となる。 ループ中に(ループ変数を使った)文字 数判定の条件文があるので、アンローリ ングされても1文字ずつの逐次処理と なる(並列処理されない) 配列のアクセスも、それぞれの文字列を 1文字ずつのアクセスとなる N bytes 文字列a (先頭位置a) 文字列b (先頭位置b) N bytes 文字列が格納されている配列: (FPGA内部メモリへマップ) Start i = 0 i < N? End i = i + 1 i文字目は 一致したか No Yes No Yes N:最大比較文字数 連続して一致する文字数を数える 最大比較 文字数N 未満か 文字列検索(比較)の フローチャート(元) 15 © Hitachi, Ltd. 2022. All rights reserved. 7.2 施策③:文字列比較ループアンローリング(2):条件分岐への対応 •1文字ずつの比較を行う条 件文と、ループの繰返しを分 ける I. アンロールする数を決め る(右例では、8) II. 最大比較文字数に至る まで、アンロールした数分 の比較を行い、一致数 を数える III. ループの繰返しは、数え た一致数が、アンロール した数まで達したかどうか で判定する •1文字ずつの比較を行う条 件文と、ループの繰返しを分 ける I. アンロールする数を決め る(右例では、8) II. 最大比較文字数に至る まで、アンロールした数分 の比較を行い、一致数 を数える III. ループの繰返しは、数え た一致数が、アンロール した数まで達したかどうか で判定する Start i = 0 i < N? End 1文字目は 一致したか ? No Yes No Yes 次の1文字目は、 N文字未満か C = 0 i + 1 < N? 2文字目は 一致したか ? No Yes No Yes C = 1 0文字一致 2文字目は、 N文字未満か 1文字一致 Yes i + 7 < N? 8文字目は 一致したか ? No Yes No Yes C = 7 8文字目は、 N文字未満か 7文字一致 C = 8 i = i + C C < 8? No Yes 8文字一致 一致した文字 数を合計 Ⅱ.一致文字数 を数える ③ ③ ① ② ① ② 繰返し Ⅲ. 一致数は アンロールした 数か? C:一致文字数 N:最大比較文字数 Ⅰ.アンロール数を決める(8) 14 15
9.
9 16 © Hitachi, Ltd.
2022. All rights reserved. 7.3 施策③:文字列比較ループアンローリング(3):配列アクセスへの対応 •レジスタ配列を二つ使用、それぞれの文字列を レジスタ配列に一旦格納して比較 文字列を格納する配列を、アクセス幅(右 例ではアンロール数に合わせた8Byte)を単 位とする二次元配列とする レジスタ配列は、一回の配列アクセス幅 (8)の2倍(16)の要素数とする 比較はレジスタ配列上で、それぞれの文字 列位置から、一回に最大アンロール数分 =アクセス幅分の文字数(8)を比較 比較後、レジスタ配列の内容をシフト 1. レジスタ配列の後半内容を前半にコピー 2. 文字列を格納する配列からアクセス幅 (8Byte)分読出し、レジスタ配列の後 半に格納 •レジスタ配列を二つ使用、それぞれの文字列を レジスタ配列に一旦格納して比較 文字列を格納する配列を、アクセス幅(右 例ではアンロール数に合わせた8Byte)を単 位とする二次元配列とする レジスタ配列は、一回の配列アクセス幅 (8)の2倍(16)の要素数とする 比較はレジスタ配列上で、それぞれの文字 列位置から、一回に最大アンロール数分 =アクセス幅分の文字数(8)を比較 比較後、レジスタ配列の内容をシフト 1. レジスタ配列の後半内容を前半にコピー 2. 文字列を格納する配列からアクセス幅 (8Byte)分読出し、レジスタ配列の後 半に格納 8bytes 前半 後半 アクセル幅(8byte)単位に読出し、 レジスタ配列の後半に格納 レジスタ配列a 一回の比較対象 (最大8文字) 文字列b (先頭位置b) 文字列a (先頭位置a) 文字列が格納されている配列: (2次元配列として、FPGA内部 メモリへマップ) 前半 後半 レジスタ配列b 後半から 前半へ コピー 後半から 前半へ コピー N bytes N bytes 一回当たりの 読出し単位 一回当たりの 読出し単位 17 © Hitachi, Ltd. 2022. All rights reserved. 7.4 施策③:文字列比較ループアンローリング(4):改善後 8bytes N bytes N bytes 前半 後半 レジスタ配列a 一回の比較対象 (最大8文字) 文字列b (先頭位置b) 文字列a (先頭位置a) 文字列が格納されている配列: 前半 後半 レジスタ配列b • ループ開始前の初期化でレジスタ配列の最 初の内容、文字列比較位置を準備 • 繰返し時にレジスタ配列内容を順にシフト • ループ開始前の初期化でレジスタ配列の最 初の内容、文字列比較位置を準備 • 繰返し時にレジスタ配列内容を順にシフト Start i < N? レジスタ配列a[x]= レジスタ配列b[y]? No Yes No Yes C = 0 ③ ① ② レジスタ配列a[] ← 文字列aの先頭含む8byte + 次の8byte レジスタ配列b[] ← 文字列bの先頭含む8byte + 次の8byte x = 文字列aの開始位置(8の剰余) y = 文字列bの開始位置(8の剰余) i = 0 End Yes i + 7 < N? No Yes No Yes C = 7 C = 8 i = i + C C < 8? No Yes ③ ① ② 繰返し レジスタ配列a[x+7]= レジスタ配列b[y+7]? レジスタ配列aの内容シフト (配列前半←配列後半、 配列後半←文字列aの 次の8byte) レジスタ配列bの内容シフト (配列前半←配列後半、 配列後半←文字列bの 次の8byte) y x (文字列aの開始 位置の8の剰余) (文字列bの開始 位置の8の剰余) 16 17
10.
10 18 © Hitachi, Ltd.
2022. All rights reserved. 8. 評価:本事例における改善施策の効果 • LZMAの高位合成を、以下の三種の改善策により、改善した ① メモリのアクセス幅拡大: ハッシュテーブル更新に適用 ② データフロー化:辞書圧縮部とレンジコーダ、及びレンジコーダ内部へ適用 ③ 文字列比較ループアンローリング:文字列検索に適用 • 改善の結果、ほぼ見積り通りになった(下表)。 見積り 改善前 改善後 主な改善策 全体処理時間 500μS (1.0) 21,540μS (43.1) 516μS (1.0) ② 辞書圧縮部 - 17,461μS 476μS ハッシュテーブル更新 - 12,007μS 246μS ① 文字列検索 - 4,584μS 176μS ③ レンジコーダ - 3,339μS 250μS ② ■32KBのデータの圧縮処理における処理時間の改善結果 19 © Hitachi, Ltd. 2022. All rights reserved. 9. 高位合成の活用まとめ • LZMAを題材とした本事例では、高位合成のプロファイルデータを分析し、元の高位言語ソースの記述へ フィードバックすることで、複雑なアルゴリズムの最適化を行うことができた。 • このような高位合成におけるアルゴリズムレベルの最適化は、複雑なアルゴリズムをハード化する場合の、上流 工程としても活用することが可能。 全体をRTL設計で行うのに比べて、開発工数を大きく短縮することが可能 Adder(int a, int b, int c) { c = a + b; } 高位合成 プロファイル データ 改善/最適化(フィードバック) 上流工程(高位合成) (アルゴルズムレベル最適化) 下流工程(RTL設計) 仕様設計/機能設計 高位言語ソース (アルゴリズム記述) 詳細設計 (RTL設計) RTL 記述 アルゴリズム (最適化済み) 改善のための 手戻り不要 開発工数短縮 = 18 19
11.
11 © Hitachi, Ltd.
2022. All rights reserved. 20 END 複雑なアルゴリズムのハード化における高位合成の活用事例 第9回ACRiウェビナー 2022/7/26 株式会社 日立製作所 研究開発グループ デジタルプラットフォームイノベーションセンタ データストレージ研究部 島田 健太郎 20 21
Download





![5
8
© Hitachi, Ltd. 2022. All rights reserved.
5.1 施策①:メモリのアクセス幅拡大(1):概要
コピー元配列
コピー先配列
コピー元配列
コピー先配列
Start
i = 0
d[i] = s[i]
i < N?
End
s[]
d[]
s[]
d[]
t[]
i = i + 1
Start
i = 0
t[0] = s[i]
t[1] = s[i + 1]
...
t[7] = s[i + 7]
i < N?
End
i = i + 8
d[i] = t[0]
d[i + 1] = t[1]
...
d[i + 7] = t[7]
No
Yes
No
Yes
• 配列から配列にデータをコピーするケース
配列は、コピー元・コピー先とも、FPGAの内部メモリにマップするケース
• 配列から配列へ直接コピーする記述や、ループ・アンローリングがされない
場合に、1要素ずつの逐次コピーになり易い
• 途中にレジスタ配列を置き、ループ展開することで複数要素同時にコピー
• 配列から配列にデータをコピーするケース
配列は、コピー元・コピー先とも、FPGAの内部メモリにマップするケース
• 配列から配列へ直接コピーする記述や、ループ・アンローリングがされない
場合に、1要素ずつの逐次コピーになり易い
• 途中にレジスタ配列を置き、ループ展開することで複数要素同時にコピー
レジスタ配列
• レジスタ配列を
経由
• ループ・
アンローリング
• レジスタ配列を
経由
• ループ・
アンローリング
1要素ずつコピー 複数要素
同時コピー
(コピー元/コピー先配列ともFPGA内部
メモリにマップ)
9
© Hitachi, Ltd. 2022. All rights reserved.
5.2 施策①:メモリアクセス幅拡大(2): ハッシュテーブル更新 元の構造
文字列(9文字) 位置 文字列(9文字)
①先頭4文字で
ハッシュ値計算
位置
②一組ずつシフト
③先頭に記録
先 後
ハッシュテーブル
入力データ
(辞書)
16bit 8bit×9文字 = 72bit
Start
①先頭4文字でハッシュ値を計算
i = 7
i ≧1?
ハッシュテーブル[ハッシュ値][i].位置
=ハッシュテーブル[ハッシュ値][i-1].位置
現在位置
j = 0
コピー先文字列[j] = コピー元文字列[j]
j = j +1
i = i - 1
j < 9?
ハッシュテーブル[ハッシュ値][0].位置
=現在位置
9文字コピー:
ハッシュテーブル[ハッシュ値][0].文字列
= 現在位置の文字列
9文字コピー:
ハッシュテーブル[ハッシュ値][i].文字列 =
ハッシュテーブル[ハッシュ値][i-1].文字列
End
9文字コピー
End
②一組ずつシフト ③先頭に記録
• ハッシュテーブルに辞書内の位置と先頭の
9文字ずつが登録されている
• 既存内容を移動(シフト)した上で、入力デー
タの現在位置からの9文字を新規登録
• ハッシュテーブルに辞書内の位置と先頭の
9文字ずつが登録されている
• 既存内容を移動(シフト)した上で、入力デー
タの現在位置からの9文字を新規登録
先頭から検査
ハッシュテーブル更新
のフローチャート(元)
(サブルーチンで記載)
No
Yes
No
Yes
(16bit+72bit)×8(シノニム) = 704bit(88byte)
大きなエントリを
1文字(バイト)ずつ
逐次アクセス
8
9](https://image.slidesharecdn.com/9acri-220726104108-f8d2c96f/85/9-ACRi-_-5-320.jpg)
![6
10
© Hitachi, Ltd. 2022. All rights reserved.
5.3 施策①:メモリアクセス幅拡大(3):ハッシュテーブル更新 改善策
• ハッシュテーブルを、位置の情報のテーブルと
文字列のテーブルに分割
• エントリ(位置+文字列8組分)をレジスタに
ずらして読上げ、書き戻す
• ハッシュテーブルを、位置の情報のテーブルと
文字列のテーブルに分割
• エントリ(位置+文字列8組分)をレジスタに
ずらして読上げ、書き戻す
位置
16bit
位置
16bit×8 = 128bit
位置
72bit×8 = 576bit
①先頭4文字で
ハッシュ値計算
②ずらして読み上げ
③先頭に格納
先 後
ハッシュテーブル
(分割後)
入力データ
(辞書)
16bit 8bit×9文字 = 72bit
現在位置 先頭から検査
文字列(9文字)
レジスタ
④書き戻し
Start
①先頭4文字でハッシュ値を計算
i = 7
i ≧1?
レジスタ(位置)[i]
=ハッシュテーブル(位置)[ハッシュ値][i-1]
i = i - 1
レジスタ(位置)[0] = 現在位置
9文字コピー(プラグマでアンローリング)
レジスタ(文字列)[0]=現在位置の文字列
9文字コピー(プラグマでアンローリング)
レジスタ(文字列)[i] =
ハッシュテーブル(文字列)[ハッシュ値][i-1]
End
②ずらして読み上げ ③先頭に格納
ハッシュテーブル更新の
フローチャート(改善版)
位置、文字列をそれぞれ
並列にアクセス
No
Yes
ハッシュテーブル(位置)[ハッシュ値][0~7]
= レジスタ(位置)[0~7]
9文字コピー(プラグマでアンローリング)×8:
ハッシュテーブル(文字列)[ハッシュ値][0~7]
= レジスタ(文字列)[0~7]
④書き戻し
②
④
③
11
© Hitachi, Ltd. 2022. All rights reserved.
6.1 施策②:データフロー化(1) データーフロー化適用前
• 二つの処理を含むループ
• それぞれの処理の間で、変数を用いて、一方から他方へデータを受け渡し
⇒それぞれの回路が逐次動作となる
• 二つの処理を含むループ
• それぞれの処理の間で、変数を用いて、一方から他方へデータを受け渡し
⇒それぞれの回路が逐次動作となる
Start
初期化処理
処理a
終了判定
処理b
End
終了処理
変数
変数
変数
初期化処理
回路
処理a 回路
処理b 回路
判定回路
終了処理
回路
初期データ
中間データ
出力データ
繰返し
信号
終了データ
時間軸 T1 T2 T3 T4 T5 T6 T7 T8
初期化回路 動作
処理a 回路 動作 動作 動作
処理b 回路 動作 動作
判定回路 動作 動作
終了処理回路
逐次動作:3サイクルピッチ
処理フローチャート 回路構成
10
11](https://image.slidesharecdn.com/9acri-220726104108-f8d2c96f/85/9-ACRi-_-6-320.jpg)

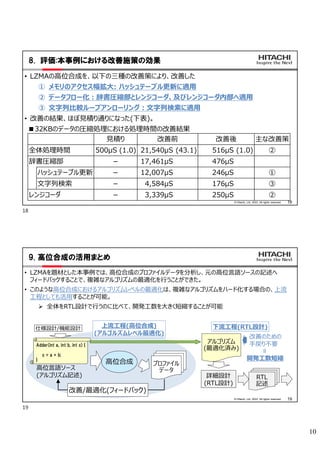
![9
16
© Hitachi, Ltd. 2022. All rights reserved.
7.3 施策③:文字列比較ループアンローリング(3):配列アクセスへの対応
•レジスタ配列を二つ使用、それぞれの文字列を
レジスタ配列に一旦格納して比較
文字列を格納する配列を、アクセス幅(右
例ではアンロール数に合わせた8Byte)を単
位とする二次元配列とする
レジスタ配列は、一回の配列アクセス幅
(8)の2倍(16)の要素数とする
比較はレジスタ配列上で、それぞれの文字
列位置から、一回に最大アンロール数分
=アクセス幅分の文字数(8)を比較
比較後、レジスタ配列の内容をシフト
1. レジスタ配列の後半内容を前半にコピー
2. 文字列を格納する配列からアクセス幅
(8Byte)分読出し、レジスタ配列の後
半に格納
•レジスタ配列を二つ使用、それぞれの文字列を
レジスタ配列に一旦格納して比較
文字列を格納する配列を、アクセス幅(右
例ではアンロール数に合わせた8Byte)を単
位とする二次元配列とする
レジスタ配列は、一回の配列アクセス幅
(8)の2倍(16)の要素数とする
比較はレジスタ配列上で、それぞれの文字
列位置から、一回に最大アンロール数分
=アクセス幅分の文字数(8)を比較
比較後、レジスタ配列の内容をシフト
1. レジスタ配列の後半内容を前半にコピー
2. 文字列を格納する配列からアクセス幅
(8Byte)分読出し、レジスタ配列の後
半に格納
8bytes
前半
後半
アクセル幅(8byte)単位に読出し、
レジスタ配列の後半に格納
レジスタ配列a
一回の比較対象
(最大8文字)
文字列b
(先頭位置b)
文字列a
(先頭位置a)
文字列が格納されている配列:
(2次元配列として、FPGA内部
メモリへマップ)
前半
後半
レジスタ配列b
後半から
前半へ
コピー
後半から
前半へ
コピー
N bytes
N bytes
一回当たりの
読出し単位
一回当たりの
読出し単位
17
© Hitachi, Ltd. 2022. All rights reserved.
7.4 施策③:文字列比較ループアンローリング(4):改善後
8bytes
N bytes
N bytes
前半
後半
レジスタ配列a
一回の比較対象
(最大8文字)
文字列b
(先頭位置b)
文字列a
(先頭位置a)
文字列が格納されている配列:
前半
後半
レジスタ配列b
• ループ開始前の初期化でレジスタ配列の最
初の内容、文字列比較位置を準備
• 繰返し時にレジスタ配列内容を順にシフト
• ループ開始前の初期化でレジスタ配列の最
初の内容、文字列比較位置を準備
• 繰返し時にレジスタ配列内容を順にシフト
Start
i < N?
レジスタ配列a[x]=
レジスタ配列b[y]?
No
Yes
No
Yes
C = 0
③
① ②
レジスタ配列a[]
← 文字列aの先頭含む8byte
+ 次の8byte
レジスタ配列b[]
← 文字列bの先頭含む8byte
+ 次の8byte
x = 文字列aの開始位置(8の剰余)
y = 文字列bの開始位置(8の剰余)
i = 0
End
Yes
i + 7 < N?
No
Yes
No
Yes
C = 7
C = 8
i = i + C
C < 8?
No
Yes
③
① ②
繰返し
レジスタ配列a[x+7]=
レジスタ配列b[y+7]?
レジスタ配列aの内容シフト
(配列前半←配列後半、
配列後半←文字列aの
次の8byte)
レジスタ配列bの内容シフト
(配列前半←配列後半、
配列後半←文字列bの
次の8byte)
y
x (文字列aの開始
位置の8の剰余)
(文字列bの開始
位置の8の剰余)
16
17](https://image.slidesharecdn.com/9acri-220726104108-f8d2c96f/85/9-ACRi-_-9-320.jpg)

















![[Dl輪読会]dl hacks輪読](https://cdn.slidesharecdn.com/ss_thumbnails/dldlhacks-161125051944-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会] MoCoGAN: Decomposing Motion and Content for Video Generation](https://cdn.slidesharecdn.com/ss_thumbnails/0911mocogan-170911121936-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]Relational inductive biases, deep learning, and graph networks](https://cdn.slidesharecdn.com/ss_thumbnails/180629dlseminarrelationalinductivebias-180706003755-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]"CyCADA: Cycle-Consistent Adversarial Domain Adaptation"&"Learning Se...](https://cdn.slidesharecdn.com/ss_thumbnails/20180803dlakuzawa-180803003349-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL Hacks]FPGA入門](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksfpgabeginner-180627050145-thumbnail.jpg?width=640&height=640&fit=bounds)


































