FPGAによる高速化が注目されています
ソーティング – 主要な計算カーネル
2
[1]Rene Mueller et al, Sorting Networks on FPGAs, The VLDB Journal 2012
[2] Ratnayake, K et al,
An FPGA Architecture of Stable-Sorting on a Large Data Volume : Application to Video Signals,
CISS 2007
[3] Martinez, J et al,
An FPGA-based parallel sorting architecture for the Burrows Wheeler transform
ReConFig 2005
データベース処理[1] 画像処理[2] データ圧縮[3]
DATA
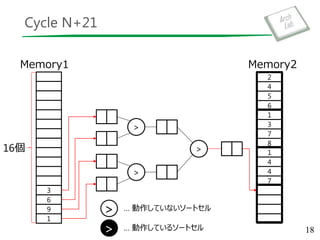
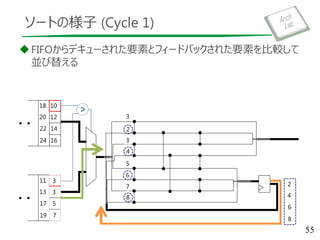
複数のソート済みデータ列を1つにマージするデータパス
図は 4-way MergeSorter Tree
ソート対象のデータ列が入力数より多い場合は複数回通す必要
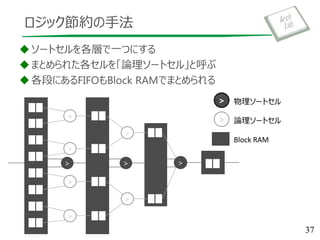
基本的なアーキテクチャ – Merge Sorter Tree
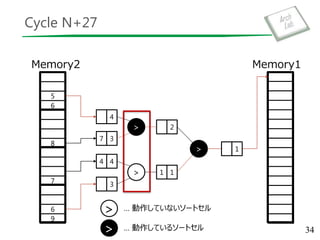
7
参考: A high performance sorting architecture exploiting run-time reconfiguration on fpgas for large problem sorting.
(Dirk Koch and Jim Torresen, FPGA ’11,)
>
>
> > ソートセル
FIFO
入力レーン
=
way
Merge Sorter Tree
例:data = {8, 9, 3, 5, 1, 3, 2, 2}
out = {}
81
参考: A high performance sorting architecture exploiting run-time reconfiguration on fpgas for large problem sorting.
(Dirk Koch and Jim Torresen, FPGA ’11,)
>
>
>
9 8
5 3
3 1
2 2
Unit: ソート済みデータ列
59.
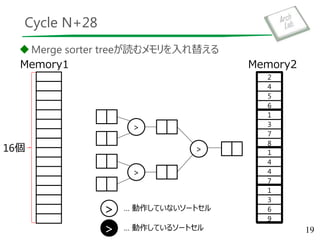
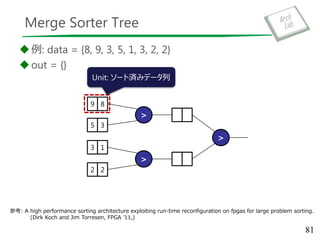
Merge Sorter Tree
data= {8, 9, 3, 5, 1, 3, 2, 2}
out = {}
82
参考: A high performance sorting architecture exploiting run-time reconfiguration on fpgas for large problem sorting.
(Dirk Koch and Jim Torresen, FPGA ’11,)
>
>
>
9 8
5 3
3 1
2 2
3
1
60.
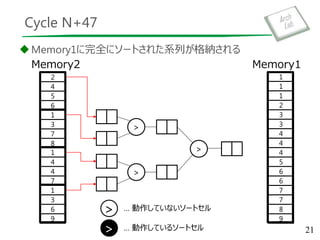
Merge Sorter Tree
data= {8, 9, 3, 5, 1, 3, 2, 2}
out = {}
83
参考: A high performance sorting architecture exploiting run-time reconfiguration on fpgas for large problem sorting.
(Dirk Koch and Jim Torresen, FPGA ’11,)
>
>
>
9 8
5
3
2 2
3
1
5
2
1
61.
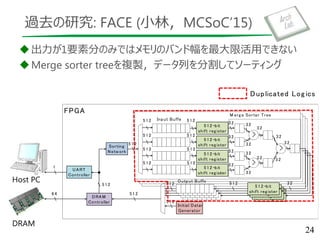
Merge Sorter Tree
data= {8, 9, 3, 5, 1, 3, 2, 2}
out = {1}
84
参考: A high performance sorting architecture exploiting run-time reconfiguration on fpgas for large problem sorting.
(Dirk Koch and Jim Torresen, FPGA ’11,)
>
>
>
9 8
5
3
2
3
2
5
2
2
62.
Merge Sorter Tree
data= {8, 9, 3, 5, 1, 3, 2, 2}
out = {1,2}
85
参考: A high performance sorting architecture exploiting run-time reconfiguration on fpgas for large problem sorting.
(Dirk Koch and Jim Torresen, FPGA ’11,)
>
>
>
9 8
5
3
3
2
5
3
2
63.
Merge Sorter Tree
data= {8, 9, 3, 5, 1, 3, 2, 2}
out = {1,2,2}
86
参考: A high performance sorting architecture exploiting run-time reconfiguration on fpgas for large problem sorting.
(Dirk Koch and Jim Torresen, FPGA ’11,)
>
>
>
9 8
5
3
3
5
3
64.
Merge Sorter Tree
data= {8, 9, 3, 5, 1, 3, 2, 2}
out = {1,2,2,3}
87
参考: A high performance sorting architecture exploiting run-time reconfiguration on fpgas for large problem sorting.
(Dirk Koch and Jim Torresen, FPGA ’11,)
>
>
>
9 8
5
3
8
3
65.
Merge Sorter Tree
data= {8, 9, 3, 5, 1, 3, 2, 2}
out = {1,2,2,3,3}
88
参考: A high performance sorting architecture exploiting run-time reconfiguration on fpgas for large problem sorting.
(Dirk Koch and Jim Torresen, FPGA ’11,)
>
>
>
9 8
5
8
5
66.
Merge Sorter Tree
data= {8, 9, 3, 5, 1, 3, 2, 2}
out = {1,2,2,3,3,5,8,9}
89
参考: A high performance sorting architecture exploiting run-time reconfiguration on fpgas for large problem sorting.
(Dirk Koch and Jim Torresen, FPGA ’11,)
>
>
>
![世界最速のFPGA
ソーティングアクセラレータの初期検討
2016/03/17 情報処理学会 第78回全国大会 @慶應義塾大学日吉キャンパス
アクセラレータ(1)[1H会場] 発表12分 + 質疑応答3分
☆臼井 琢真†1 眞下 達†1 松田 裕貴†1 小林 諒平†1 吉瀬 謙二†1
†1 東京工業大学 大学院情報理工学研究科
A Study of the World’s Fastest FPGA Sorting Accelerator](https://image.slidesharecdn.com/zenkoku78-160804180504/85/Zenkoku78-1-320.jpg)

![FPGAによる高速化が注目されています
ソーティング – 主要な計算カーネル
2
[1] Rene Mueller et al, Sorting Networks on FPGAs, The VLDB Journal 2012
[2] Ratnayake, K et al,
An FPGA Architecture of Stable-Sorting on a Large Data Volume : Application to Video Signals,
CISS 2007
[3] Martinez, J et al,
An FPGA-based parallel sorting architecture for the Burrows Wheeler transform
ReConFig 2005
データベース処理[1] 画像処理[2] データ圧縮[3]
DATA](https://image.slidesharecdn.com/zenkoku78-160804180504/85/Zenkoku78-3-320.jpg)
![FPGAアクセラレータ
FPGAアクセラレータ
►特定の処理を低消費電力かつ高速に実行可能
►科学技術計算やデータベース処理など
近年は次世代メモリの開発が盛ん
►Hyper memory cube, HBM2
►メモリ帯域によるボトルネックについては
今回は考えない
3
HMCイメージ図
過去の研究: ステンシル計算[4]
Microsoft Bing[5]
[4]小林諒平,吉瀬謙二, 多数の小容量FPGAを用いたスケーラブルなステンシル計算機, IPSJ ACS Transaction 44
[5] Andrew Putnam et al, A Reconfigurable Fabric for Accelerating Large-Scale Datacenter Services, ISCA’14](https://image.slidesharecdn.com/zenkoku78-160804180504/85/Zenkoku78-4-320.jpg)


![基本的なソーティングデータパス
Sorting network [1]
►一定数のデータをソート
►様々なアルゴリズムで
構成可能
►Batcherの奇遇転置マージ
ソートが最適
►メモリバンド幅を活かせる
Merge sorter tree [4]
►多数のデータを
再帰的にソート
(マージソート)
6
Merge sorter tree
>
>
>
Sorting network
7
4
3
1
1
3
4
7
[1] Rene Mueller et al, Sorting Networks on FPGAs, The VLDB Journal 2012
[4] A high performance sorting architecture exploiting run-time reconfiguration on fpgas for large problem sorting.
(Dirk Koch and Jim Torresen, FPGA ’11,)](https://image.slidesharecdn.com/zenkoku78-160804180504/85/Zenkoku78-7-320.jpg)















![現状のソーティングアクセラレータの性能(1)
データ列: 32bit, 合計1G要素
PCはIntel Core i7-4770K CPU 3.4GHz, 16GB DDR3搭載
8-way/8-parallelが, クイックソート比8.8倍, マージソート比10.6倍
26
0
10
20
30
40
50
60
SortingProcessTime[sec]
xorshift
sorted
reverse
Estimated
8.8x10.6x](https://image.slidesharecdn.com/zenkoku78-160804180504/85/Zenkoku78-27-320.jpg)
![ハードウェア使用量
8-way merge sorter tree/4-parallelから
16-way merge sorter tree/4-parallelにすると
ロジック使用量10%増
28
0
10
20
30
40
50
60
70
80
90
100
HardwareResourceUtilization[%]
FF
LUT Logic
LUT RAM
Block RAM
10%↑](https://image.slidesharecdn.com/zenkoku78-160804180504/85/Zenkoku78-28-320.jpg)








![1サイクルに4要素出力できるソートセル[Casper+, FPGA’14]
複数の要素を扱えるソートセル
52](https://image.slidesharecdn.com/zenkoku78-160804180504/85/Zenkoku78-39-320.jpg)











![性能見積もり
例として64-bit 512M要素 (4GB) のソーティングを想定
Casper+は8k-wayで200MHz
見積もりの式は予稿に記載のものを用いた
67
6.083 4.8
0
1
2
3
4
5
6
7
Proposed Casper+
Throughput[GB/s]
Sorting architecture
1.27x](https://image.slidesharecdn.com/zenkoku78-160804180504/85/Zenkoku78-52-320.jpg)



















![[DL Hacks]FPGA入門](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksfpgabeginner-180627050145-thumbnail.jpg?width=640&height=640&fit=bounds)

































