Logic Only Logic& DSP Logic & Memory Logic, Memory & DSP
Area Ratio 40 28 37 21
Critical Path
Delay(Fastest)
3.2 3.4 2.3 2.1
Critical Path
Delay(Slowest)
4.3 4.5 3.1 2.8
Dynamic Power
Consumption
12 12 9.2 9.0
FPGAのオーバーヘッド
[7] I. Kuon and J. Rose, “Measuring the gap between fpgas and asics,”
Proceedings of the 2006 ACM/SIGDA 14th Inter- national Symposium on Field Programmable Gate Arrays,
pp.21–30, FPGA ’06, ACM, New York, NY, USA, 2006.
Altera Stratix II(90nm) vs. STMicro. CMOS090
Ratio = FPGA/ASIC, 種々のベンチマークの相乗平均
論理回路を作る仕組みのためのオーバーヘッド
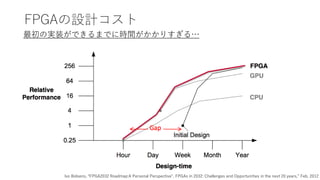
FPGAの設計コスト
Ivo Bolsens, “FPGA2032Roadmap:A Personal Perspective", FPGAs in 2032: Challenges and Opportunities in the next 20 years,” Feb. 2012
最初の実装ができるまでに時間がかかりすぎる…
6.
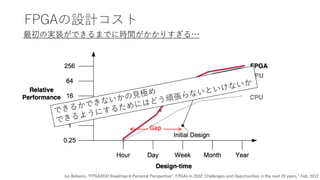
FPGAの設計コスト
Ivo Bolsens, “FPGA2032Roadmap:A Personal Perspective", FPGAs in 2032: Challenges and Opportunities in the next 20 years,” Feb. 2012
最初の実装ができるまでに時間がかかりすぎる…
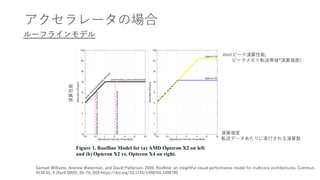
アクセラレータの場合
ルーフラインモデル
Samuel Williams, AndrewWaterman, and David Patterson. 2009. Roofline: an insightful visual performance model for multicore architectures. Commun.
ACM 52, 4 (April 2009), 65–76. DOI:https://doi.org/10.1145/1498765.1498785
演算性能
演算強度
転送データあたりに実行される演算数
min(ピーク演算性能,
ピークメモリ転送帯域*演算強度)
11.
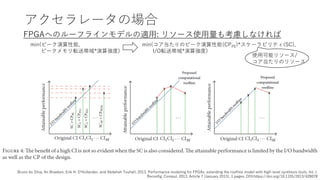
アクセラレータの場合
FPGAへのルーフラインモデルの適用
Cathal McCabe, “Programmingand Benchmarking FPGAs with Software-Centric Design Entries,”
First Workshop on Resource Awareness and Application Autotuning in Adaptive and Heterogeneous Computing(DATE16), Mar. 2016
http://res4ant.deib.polimi.it/2016/presentations/Cathal_2016-03-17_DATE_resource_aware_hetrogeneous_computing.pdf
CPU: Xeon Processor(E5-2660)
- OoO 10cores@2.2GHz
- Memory 64GB@60GBps
- 256b vector units per core
Phi: Xeon Phi(5110P)
- 60cores@1.053GHz
- 8GB@320GBps
- 512b vector units per core
GPU: Nvidia K20x
- SIMT(13*192@732MHz)
- Memory 6GB@250GBps
FPGA: ADM PCIe 7V3
- Memory 16GB@21.3GBps
12.
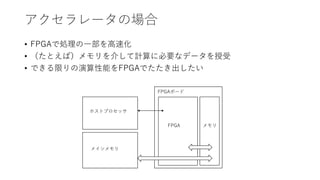
アクセラレータの場合
FPGAへのルーフラインモデルの適用: リソース使用量も考慮しなければ
Bruno daSilva, An Braeken, Erik H. D'Hollander, and Abdellah Touhafi. 2013. Performance modeling for FPGAs: extending the roofline model with high-level synthesis tools. Int. J.
Reconfig. Comput. 2013, Article 7 (January 2013), 1 pages. DOI:https://doi.org/10.1155/2013/428078
min(ピーク演算性能,
ピークメモリ転送帯域*演算強度)
min(コア当たりのピーク演算性能(CPPE)*スケーラビリティ(SC),
I/O転送帯域*演算強度)
使用可能リソース/
コア当たりのリソース




![Logic Only Logic & DSP Logic & Memory Logic, Memory & DSP
Area Ratio 40 28 37 21
Critical Path
Delay(Fastest)
3.2 3.4 2.3 2.1
Critical Path
Delay(Slowest)
4.3 4.5 3.1 2.8
Dynamic Power
Consumption
12 12 9.2 9.0
FPGAのオーバーヘッド
[7] I. Kuon and J. Rose, “Measuring the gap between fpgas and asics,”
Proceedings of the 2006 ACM/SIGDA 14th Inter- national Symposium on Field Programmable Gate Arrays,
pp.21–30, FPGA ’06, ACM, New York, NY, USA, 2006.
Altera Stratix II(90nm) vs. STMicro. CMOS090
Ratio = FPGA/ASIC, 種々のベンチマークの相乗平均
論理回路を作る仕組みのためのオーバーヘッド](https://image.slidesharecdn.com/acriwebinar20220118miyo-220119021937/85/ACRi_webinar_20220118_miyo-3-320.jpg)

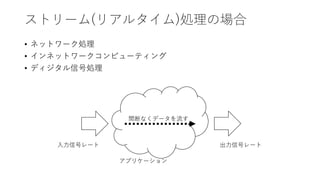
![ストリーム(リアルタイム)処理の場合
・・・
例:
10GbE: 156.25MHz*64bit => 内部を156.25MHz*256bitで4クロックに1回出力するようなロジックで構成
125Msps, 16bit/sample: 125MHz*16bit => 内部を250MHz*64bitで8クロックに1回出力するようなロジックで構成
FIFO/BRAM FIFO/BRAM FIFO/BRAM
必要な外部リソースの
アクセスレイテンシ分を
カバーできるように
- 処理サイクル数のゆらぎ
の緩衝
- 必要なデータにアクセス
できるように
FPGA
T [bps]
T [bps]
f [Hz], w [bit], II [cycles]
T ≦ f * w / II
処理 処理
- 処理のパイプライン段数と並列度分の
LUT,DSP,FFが必要はあるか?
- FIFO/BRAM用のメモリがあるか?
外部リソース
(DRAMなど)](https://image.slidesharecdn.com/acriwebinar20220118miyo-220119021937/85/ACRi_webinar_20220118_miyo-8-320.jpg)






























![[DL Hacks]FPGA入門](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksfpgabeginner-180627050145-thumbnail.jpg?width=640&height=640&fit=bounds)





































