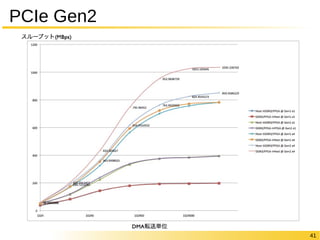
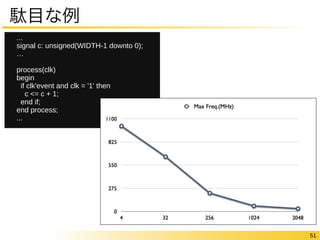
Ratio = FPGA/ASIC,種々のベンチマークの相乗平均
12
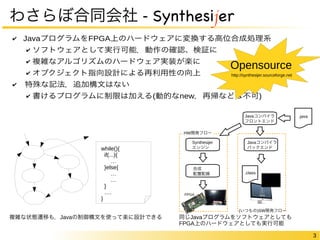
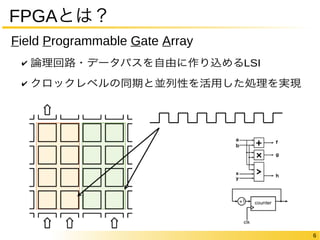
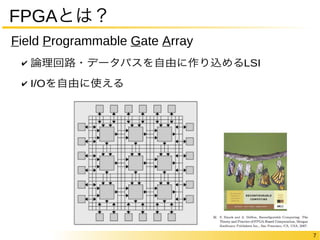
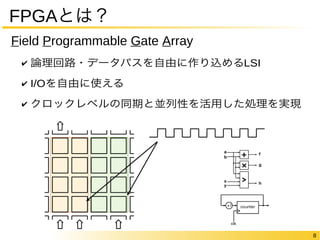
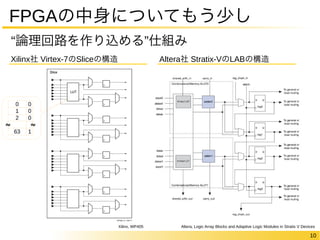
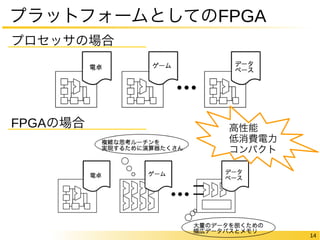
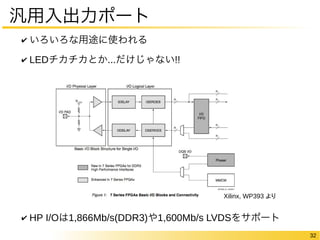
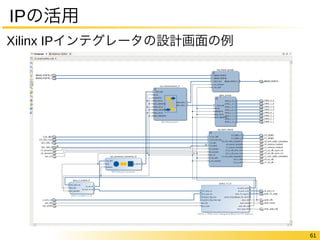
FPGAの中身についてもう少し
“論理回路を作り込める”仕組みのオーバヘッド
Logic Only Logic & DSP Logic &
Memory
Logic, Memory
& DSP
Area Ratio 40 28 37 21
Critical Path
Delay(Fastest Grade) 3.2 3.4 2.3 2.1
Critical Path
Delay(Slowest Grade) 4.3 4.5 3.1 2.8
Dynamic Power
Consumption 12 12 9.2 9.0
[7] I. Kuon and J. Rose, “Measuring the gap between fpgas and asics,”
Proceedings of the 2006 ACM/SIGDA 14th Inter- national Symposium on Field Programmable Gate Arrays, pp.21–30,
FPGA ’06, ACM, New York, NY, USA, 2006.
18
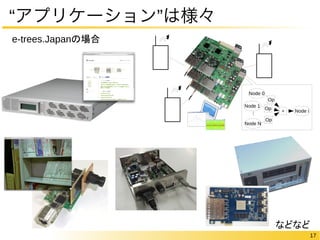
アプリケーション研究事例
@FCCM2014,FPL2014,FPGA2014
- Fast, Power-Efficient Biophotonic Simulations for Cancer Treatment Using FPGAs
- SMCGen: Generating Reconfigurable Design for Sequential Monte Carlo Applications
- FPGA Gaussian Random Number Generators with Guaranteed Statistical Accuracy
- FPGA Implementation of EM Algorithm for 3D CT Reconstruction
- A Scalable Multi-engine Xpress9 Compressor with Asynchronous Data Transfer
- FPGA Accelerated Online Boosting for Multi-target Tracking
- High-Throughput Implementation of a Million-Point Sparse Fourier Transform
- Power-efficient Re-gridding Architecture for Accelerating Non-uniform Fast Fourier Transform
- Radix-4 and Radix-8 Booth Encoded Interleaved Modular Multipliers Over General Fp
- Dataflow Acceleration of Krylov Subspace Sparse Banded Problems
- A Highly-efficient and Green Data Flow Engine for Solving Euler Atmospheric Equations
- An Efficient FPGA-based Hardware Framework for Natural Feature Extraction and Related Computer Vision Tasks
- An Efficient Sparse Conjugate Gradient Solver Using a Benes Permutation Network
- Efficient 3D Triangulation in Hardware for Dense Structure-from-Motion in Low-Speed Automotive Scenarios
- FPGA-based Biophysically-Meaningful Modeling of Olivocerebellar Neurons
- Square-Rich Fixed Point Polynomial Evaluation on FPGAs
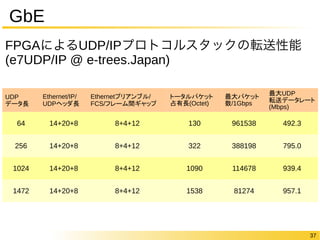
- Hardware Acceleration of Database Operations
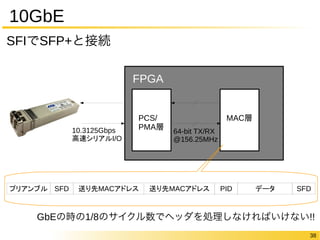
- A Scalable Sparse Matrix-Vector Multiplication Kernel For Energy-Efficient Sparse-BLAS On FPGAs
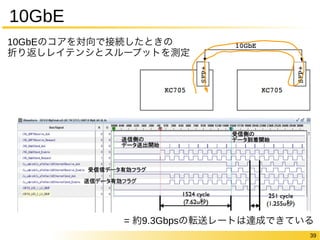
- Binary Stochastic Implementation of Digital Logic
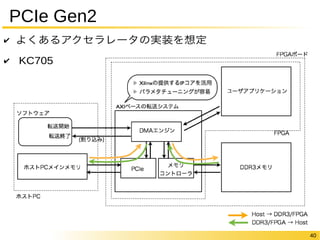
- Accelerating Parameter Estimation for Multivariate Self-Exciting Point Processes
- Energy-Efficient Multiplier-Less Discrete Convolver through Probabilistic Domain Transformation
- …..
19.
19
アプリケーション研究事例
FPGAドミナントではない会議での事例
- The Click2NetFPGA Toolchain @USENIX ATC2012
- SURF Algorithm in FPGA: a Novel Architecture for High Demanding Industrial Applications @DATE2012
- Achieving 10Gbps line-rate key-value stores with FPGAs @USENIX HotCloud 2013
- FPGA Acceleration for the Frequent Item Problem @ICDE 2010
- An FPGA-based pattern classifier using data compression @IEEEI 2010
- A reconfigurable fabric for accelerating large-scale datacenter services @ISCA 2014
- LINQits: big data on little clients @ISCA 2013
- Parallel Real-time Garbage Collection of Multiple Heaps in Reconfigurable Hardware @ISMM2014
- Accelerating Machine-Learning Algorithms on FPGAs using Pattern-Based Decomposition @J. of Sig. Process. Syst.
- Willow: A User-Programmable SSD @USENIX OSDI2014
- Hardware Enforcement of Application Security Policies Using Tagged Memory @USENIX OSDI2008
- Histograms as a Side Effect of Data Movement for Big Data @SIGMOD2014
- Flexible Query Processor on FPGAs @VLDB2013
- Complex Event Detection at Wire Speed with FPGAs @VLDB2010
- Data Processing on FPGAs @VLDB2009
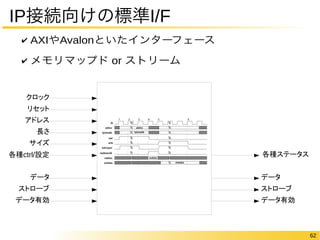
- …..
などなどなど沢山
22
アプリケーション研究事例
FPGAドミナントではない会議での事例
- The Click2NetFPGA Toolchain @USENIX ATC2012
- SURF Algorithm in FPGA: a Novel Architecture for High Demanding Industrial Applications @DATE2012
- Achieving 10Gbps line-rate key-value stores with FPGAs @USENIX HotCloud 2013
- FPGA Acceleration for the Frequent Item Problem @ICDE 2010
- An FPGA-based pattern classifier using data compression @IEEEI 2010
- A reconfigurable fabric for accelerating large-scale datacenter services @ISCA 2014
- LINQits: big data on little clients @ISCA 2013
- Parallel Real-time Garbage Collection of Multiple Heaps in Reconfigurable Hardware @ISMM2014
- Accelerating Machine-Learning Algorithms on FPGAs using Pattern-Based Decomposition @J. of Sig. Process. Syst.
- Willow: A User-Programmable SSD @USENIX OSDI2014
- Hardware Enforcement of Application Security Policies Using Tagged Memory @USENIX OSDI2008
- Histograms as a Side Effect of Data Movement for Big Data @SIGMOD2014
- Flexible Query Processor on FPGAs @VLDB2013
- Complex Event Detection at Wire Speed with FPGAs @VLDB2010
- Data Processing on FPGAs @VLDB2009
- …..
などなどなど沢山
27
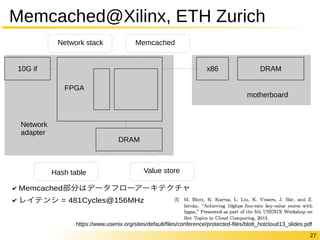
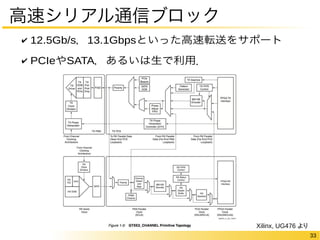
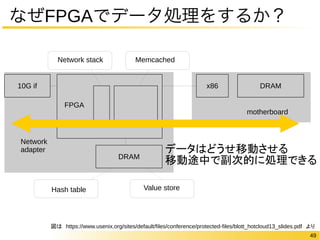
Memcached@Xilinx, ETHZurich
10G if
Network stack Memcached
DRAM
Network
adapter
FPGA
x86 DRAM
motherboard
Hash table Value store
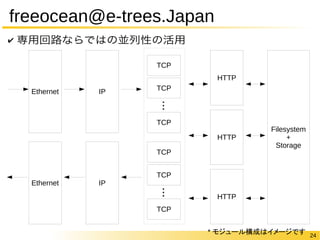
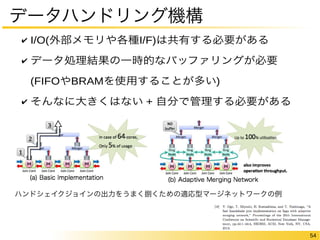
✔ Memcached部分はデータフローアーキテクチャ
✔ レイテンシ = 481Cycles@156MHz
https://www.usenix.org/sites/default/files/conference/protected-files/blott_hotcloud13_slides.pdf
データはどうせ移動させる
移動途中で副次的に処理できる
49
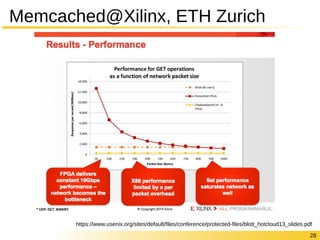
なぜFPGAでデータ処理をするか?
10G if
Network stack Memcached
DRAM
Network
adapter
FPGA
x86 DRAM
motherboard
Hash table Value store
図は https://www.usenix.org/sites/default/files/conference/protected-files/blott_hotcloud13_slides.pdf より






![Ratio = FPGA/ASIC, 種々のベンチマークの相乗平均
12
FPGAの中身についてもう少し
“論理回路を作り込める”仕組みのオーバヘッド
Logic Only Logic & DSP Logic &
Memory
Logic, Memory
& DSP
Area Ratio 40 28 37 21
Critical Path
Delay(Fastest Grade) 3.2 3.4 2.3 2.1
Critical Path
Delay(Slowest Grade) 4.3 4.5 3.1 2.8
Dynamic Power
Consumption 12 12 9.2 9.0
[7] I. Kuon and J. Rose, “Measuring the gap between fpgas and asics,”
Proceedings of the 2006 ACM/SIGDA 14th Inter- national Symposium on Field Programmable Gate Arrays, pp.21–30,
FPGA ’06, ACM, New York, NY, USA, 2006.](https://image.slidesharecdn.com/cpsy2014-141201000025-conversion-gate01/85/ICD-CPSY-201412-12-320.jpg)






![26
freeocean@e-trees.Japan
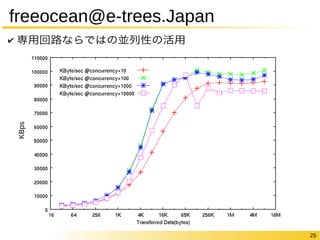
✔ [参考] 今時のApache/PCにabで負荷をかけてみる
✔ PCのスペック
✔ 結果
CPU Intel(R) Core(TM) i5-3570 CPU@3.4GHz
メモリ 32GB
ディスク Intel SSDC2W24
OS Fedora release 17
Apache Apache/2.2.23
➔ 1kB ➔ 1MB
並列度スループット(kBps)
10 40225
100 48865
1000 12494
並列度スループット(kBps)
10 114565
100 114568
1000 N/A](https://image.slidesharecdn.com/cpsy2014-141201000025-conversion-gate01/85/ICD-CPSY-201412-26-320.jpg)







![53
パイプライン並列化
FIFO
w [byte]
f [Hz]
実行
ステージ
スループット T [bps]
FIFO
実行
ステージ
実行
ステージ
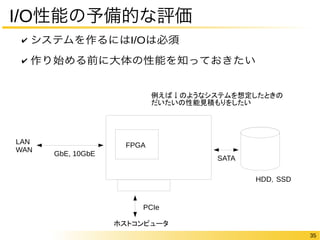
パケットデータが d [byte] のとき全データ入力を受け取るのにかかる時間 = (d/w)*(1/f) [sec]
同様に、全データの出力にかかる時間 = (d/w)*(1/f) [sec]
スループットT [bps]を実現するとき、パケットデータを(8*d)*(1/T) [sec]内で処理し続ける必要がある
→ 各モジュールで処理に使える時間 t は 8*d/T-2*d/(w*f) [sec] → (8*d/T-2*d/(w*f))/(1/f) [cycle]
たとえば、d=1500, T=1G, w=4, f=100Mのとき
1パケットあたりの処理にかけられるサイクル数は450サイクル.
f=200Mなら1650サイクル,w=16なら1012サイクル](https://image.slidesharecdn.com/cpsy2014-141201000025-conversion-gate01/85/ICD-CPSY-201412-53-320.jpg)






































![[DL Hacks]FPGA入門](https://cdn.slidesharecdn.com/ss_thumbnails/dlhacksfpgabeginner-180627050145-thumbnail.jpg?width=640&height=640&fit=bounds)





































