Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
cyberagent
3,574 views
ログ解析基盤におけるストリーム処理パイプラインについて
ログ解析基盤におけるストリーム処理パイプラインについて
Engineering
◦
Read more
1
Save
Share
Embed
Embed presentation
Download
Download to read offline
1
/ 28
2
/ 28
3
/ 28
4
/ 28
5
/ 28
6
/ 28
7
/ 28
8
/ 28
9
/ 28
10
/ 28
11
/ 28
12
/ 28
13
/ 28
14
/ 28
15
/ 28
16
/ 28
17
/ 28
18
/ 28
19
/ 28
20
/ 28
21
/ 28
22
/ 28
23
/ 28
24
/ 28
25
/ 28
26
/ 28
27
/ 28
28
/ 28
More Related Content
PDF
Kinesis + Elasticsearchでつくるさいきょうのログ分析基盤
by
Amazon Web Services Japan
PDF
PFN のオンプレML基盤の取り組み / オンプレML基盤 on Kubernetes 〜PFN、ヤフー〜
by
Preferred Networks
PDF
At least onceってぶっちゃけ問題の先送りだったよね #kafkajp
by
Yahoo!デベロッパーネットワーク
PPTX
GraalVM を普通の Java VM として使う ~クラウドベンチマークなどでの比較~
by
Shinji Takao
PDF
PostgreSQLをKubernetes上で活用するためのOperator紹介!(Cloud Native Database Meetup #3 発表資料)
by
NTT DATA Technology & Innovation
PDF
Vacuum徹底解説
by
Masahiko Sawada
PDF
"Kong Summit, Japan 2022" パートナーセッション:Kong on AWS で実現するスケーラブルな API 基盤の構築
by
Junji Nishihara
PDF
アーキテクチャから理解するPostgreSQLのレプリケーション
by
Masahiko Sawada
Kinesis + Elasticsearchでつくるさいきょうのログ分析基盤
by
Amazon Web Services Japan
PFN のオンプレML基盤の取り組み / オンプレML基盤 on Kubernetes 〜PFN、ヤフー〜
by
Preferred Networks
At least onceってぶっちゃけ問題の先送りだったよね #kafkajp
by
Yahoo!デベロッパーネットワーク
GraalVM を普通の Java VM として使う ~クラウドベンチマークなどでの比較~
by
Shinji Takao
PostgreSQLをKubernetes上で活用するためのOperator紹介!(Cloud Native Database Meetup #3 発表資料)
by
NTT DATA Technology & Innovation
Vacuum徹底解説
by
Masahiko Sawada
"Kong Summit, Japan 2022" パートナーセッション:Kong on AWS で実現するスケーラブルな API 基盤の構築
by
Junji Nishihara
アーキテクチャから理解するPostgreSQLのレプリケーション
by
Masahiko Sawada
What's hot
PDF
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
by
Noritaka Sekiyama
PPTX
Dockerからcontainerdへの移行
by
Akihiro Suda
PPTX
PostgreSQLのロール管理とその注意点(Open Source Conference 2022 Online/Osaka 発表資料)
by
NTT DATA Technology & Innovation
PDF
続・PFN のオンプレML基盤の取り組み / オンプレML基盤 on Kubernetes 〜PFN、ヤフー〜 #2
by
Preferred Networks
PDF
俺のTerraform CI/CD ライフサイクル
by
HonMarkHunt
PDF
OpenAPI 3.0でmicroserviceのAPI定義を試みてハマった話
by
Daichi Koike
PDF
AWSにおけるバッチ処理の ベストプラクティス - Developers.IO Meetup 05
by
都元ダイスケ Miyamoto
PDF
Paxos
by
Preferred Networks
PDF
20200422 AWS Black Belt Online Seminar Amazon Elastic Container Service (Amaz...
by
Amazon Web Services Japan
PDF
マイクロにしすぎた結果がこれだよ!
by
mosa siru
PPTX
え、まって。その並列分散処理、Kafkaのしくみでもできるの? Apache Kafkaの機能を利用した大規模ストリームデータの並列分散処理
by
NTT DATA Technology & Innovation
PDF
ビッグデータ処理データベースの全体像と使い分け
by
Recruit Technologies
PDF
IoT時代におけるストリームデータ処理と急成長の Apache Flink
by
Takanori Suzuki
PDF
爆速クエリエンジン”Presto”を使いたくなる話
by
Kentaro Yoshida
PDF
[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス
by
Amazon Web Services Japan
PDF
KafkaとPulsar
by
Yahoo!デベロッパーネットワーク
PDF
機密データとSaaSは共存しうるのか!?セキュリティー重視のユーザー層を取り込む為のネットワーク通信のアプローチ
by
Amazon Web Services Japan
PDF
コンテナにおけるパフォーマンス調査でハマった話
by
Yuta Shimada
PPTX
データ収集の基本と「JapanTaxi」アプリにおける実践例
by
Tetsutaro Watanabe
PDF
単なるキャッシュじゃないよ!?infinispanの紹介
by
AdvancedTechNight
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
by
Noritaka Sekiyama
Dockerからcontainerdへの移行
by
Akihiro Suda
PostgreSQLのロール管理とその注意点(Open Source Conference 2022 Online/Osaka 発表資料)
by
NTT DATA Technology & Innovation
続・PFN のオンプレML基盤の取り組み / オンプレML基盤 on Kubernetes 〜PFN、ヤフー〜 #2
by
Preferred Networks
俺のTerraform CI/CD ライフサイクル
by
HonMarkHunt
OpenAPI 3.0でmicroserviceのAPI定義を試みてハマった話
by
Daichi Koike
AWSにおけるバッチ処理の ベストプラクティス - Developers.IO Meetup 05
by
都元ダイスケ Miyamoto
Paxos
by
Preferred Networks
20200422 AWS Black Belt Online Seminar Amazon Elastic Container Service (Amaz...
by
Amazon Web Services Japan
マイクロにしすぎた結果がこれだよ!
by
mosa siru
え、まって。その並列分散処理、Kafkaのしくみでもできるの? Apache Kafkaの機能を利用した大規模ストリームデータの並列分散処理
by
NTT DATA Technology & Innovation
ビッグデータ処理データベースの全体像と使い分け
by
Recruit Technologies
IoT時代におけるストリームデータ処理と急成長の Apache Flink
by
Takanori Suzuki
爆速クエリエンジン”Presto”を使いたくなる話
by
Kentaro Yoshida
[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス
by
Amazon Web Services Japan
KafkaとPulsar
by
Yahoo!デベロッパーネットワーク
機密データとSaaSは共存しうるのか!?セキュリティー重視のユーザー層を取り込む為のネットワーク通信のアプローチ
by
Amazon Web Services Japan
コンテナにおけるパフォーマンス調査でハマった話
by
Yuta Shimada
データ収集の基本と「JapanTaxi」アプリにおける実践例
by
Tetsutaro Watanabe
単なるキャッシュじゃないよ!?infinispanの紹介
by
AdvancedTechNight
Similar to ログ解析基盤におけるストリーム処理パイプラインについて
PPTX
Modern stream processing by Spark Structured Streaming
by
Sotaro Kimura
PDF
最近のストリーム処理事情振り返り
by
Sotaro Kimura
PDF
B14 「今」を分析するストリームデータ処理技術とその可能性 by Kazunori Tamura
by
Insight Technology, Inc.
PDF
[C23] 「今」を分析するストリームデータ処理技術とその可能性 by Takahiro Yokoyama
by
Insight Technology, Inc.
PDF
Amebaにおけるログ解析基盤Patriotの活用事例
by
cyberagent
PDF
ストリーム処理プラットフォームにおけるKafka導入事例 #kafkajp
by
Yahoo!デベロッパーネットワーク
PDF
Storm×couchbase serverで作るリアルタイム解析基盤
by
NTT Communications Technology Development
PDF
ストリーム処理エンジン「Zero」の開発と運用
by
Eiichi Sato
Modern stream processing by Spark Structured Streaming
by
Sotaro Kimura
最近のストリーム処理事情振り返り
by
Sotaro Kimura
B14 「今」を分析するストリームデータ処理技術とその可能性 by Kazunori Tamura
by
Insight Technology, Inc.
[C23] 「今」を分析するストリームデータ処理技術とその可能性 by Takahiro Yokoyama
by
Insight Technology, Inc.
Amebaにおけるログ解析基盤Patriotの活用事例
by
cyberagent
ストリーム処理プラットフォームにおけるKafka導入事例 #kafkajp
by
Yahoo!デベロッパーネットワーク
Storm×couchbase serverで作るリアルタイム解析基盤
by
NTT Communications Technology Development
ストリーム処理エンジン「Zero」の開発と運用
by
Eiichi Sato
More from cyberagent
PDF
WWW2019で見るモバイルコンピューティングの技術と動向 山本悠ニ
by
cyberagent
PDF
Web フィルタリング最前線: 「「検閲回避」回避」 角田孝昭
by
cyberagent
PDF
WebにおけるHuman Dynamics 武内慎
by
cyberagent
PDF
Webと経済学 數見拓朗
by
cyberagent
PDF
Data Engineering Meetup #1 持続可能なデータ基盤のためのデータの多様性に対する取り組み
by
cyberagent
PDF
継続的な開発スタイル AbemaTVのiOSアプリを週1でリリースしている話
by
cyberagent
PDF
AbemaTVにおける推薦システム
by
cyberagent
PDF
AbemaTV レコメンド開発エンジニアによる RecSys 2018 参加レポート
by
cyberagent
PDF
機械学習エンジニアを見せたAWSの再:発明とは? 〜re:Invent 2018 参加レポート〜
by
cyberagent
PPTX
インターネットテレビ局「AbemaTV」プロダクトの変遷
by
cyberagent
PDF
番組宣伝に関するAbemaTV分析事例の紹介
by
cyberagent
PDF
WWW2018 論文読み会 Webと経済学
by
cyberagent
PDF
WWW2018 論文読み会 WebにおけるHuman Dynamics
by
cyberagent
PDF
WWW2018 論文読み会 Web Search and Mining
by
cyberagent
PDF
サイバーエージェントの機械学習エンジニアが体験したGoogle I/O 2018
by
cyberagent
PDF
Orion an integrated multimedia content moderation system for web services
by
cyberagent
PDF
Orion an integrated multimedia content moderation system for web services
by
cyberagent
PDF
「これ危ない設定じゃないでしょうか」とヒアリングするための仕組み @AWS Summit Tokyo 2018
by
cyberagent
PPTX
"マルチメディア機械学習" の取り組み
by
cyberagent
PDF
推薦アルゴリズムの今までとこれから
by
cyberagent
WWW2019で見るモバイルコンピューティングの技術と動向 山本悠ニ
by
cyberagent
Web フィルタリング最前線: 「「検閲回避」回避」 角田孝昭
by
cyberagent
WebにおけるHuman Dynamics 武内慎
by
cyberagent
Webと経済学 數見拓朗
by
cyberagent
Data Engineering Meetup #1 持続可能なデータ基盤のためのデータの多様性に対する取り組み
by
cyberagent
継続的な開発スタイル AbemaTVのiOSアプリを週1でリリースしている話
by
cyberagent
AbemaTVにおける推薦システム
by
cyberagent
AbemaTV レコメンド開発エンジニアによる RecSys 2018 参加レポート
by
cyberagent
機械学習エンジニアを見せたAWSの再:発明とは? 〜re:Invent 2018 参加レポート〜
by
cyberagent
インターネットテレビ局「AbemaTV」プロダクトの変遷
by
cyberagent
番組宣伝に関するAbemaTV分析事例の紹介
by
cyberagent
WWW2018 論文読み会 Webと経済学
by
cyberagent
WWW2018 論文読み会 WebにおけるHuman Dynamics
by
cyberagent
WWW2018 論文読み会 Web Search and Mining
by
cyberagent
サイバーエージェントの機械学習エンジニアが体験したGoogle I/O 2018
by
cyberagent
Orion an integrated multimedia content moderation system for web services
by
cyberagent
Orion an integrated multimedia content moderation system for web services
by
cyberagent
「これ危ない設定じゃないでしょうか」とヒアリングするための仕組み @AWS Summit Tokyo 2018
by
cyberagent
"マルチメディア機械学習" の取り組み
by
cyberagent
推薦アルゴリズムの今までとこれから
by
cyberagent
ログ解析基盤におけるストリーム処理パイプラインについて
1.
ログ解析基盤における ストリーム処理パイプラインについて 斎藤貴文 1
2.
自己紹介 ● 名前 ○ 斎藤貴文 ●
所属 ○ 株式会社サイバーエージェント秋葉原ラボ ● 担当案件 ○ データ転送管理基盤開発・運用 ○ 効果計測ツール開発・運用 ○ アクセス解析システム開発・運用 ○ ステートフルストリーム処理基盤開発 ○ ストリーム処理・データフローについて色々やっていたり 2
3.
はじめに 3 ● 今回の発表内容は初心者~中級者向けです ○ 実装の具体的な話はあまりしません ●
このスライドにはOSSがいくつか出てきますが、 OSS固有の話はしません ○ 皆さん馴染みのOSSに脳内変換して問題ございません ■ Flume → Fluentd, Logstash ■ Kafka → Kinesis Stream, Google Cloud Pub/Sub, Palser ■ Hive → Pig, BigQuery, Redshift, Presto, Impala ● CADEDAの発表から加筆修正しています
4.
目次 ● 背景 ○ ログ解析基盤Patriotについて ○
Patriotにおけるストリーム処理 ● ストリーム処理パイプライン ○ ストリーム処理パイプラインの変遷 ○ ストリーム処理パイプラインにおける遅延ログ問題 ● 現在の取り組み ○ ストリーム処理 ○ ストリーム処理以外 4
5.
目次 ● 背景 ○ ログ解析基盤Patriotについて ○
Patriotにおけるストリーム処理 ● ストリーム処理パイプライン ○ ストリーム処理パイプラインの変遷 ○ ストリーム処理パイプラインにおける遅延ログ問題 ● 現在の取り組み ○ ストリーム処理 ○ ストリーム処理以外 5
6.
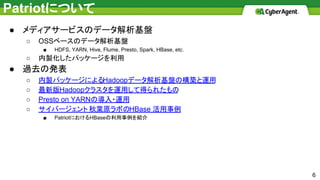
Patriotについて ● メディアサービスのデータ解析基盤 ○ OSSベースのデータ解析基盤 ■
HDFS, YARN, Hive, Flume, Presto, Spark, HBase, etc. ○ 内製化したパッケージを利用 ● 過去の発表 ○ 内製パッケージによるHadoopデータ解析基盤の構築と運用 ○ 最新版Hadoopクラスタを運用して得られたもの ○ Presto on YARNの導入・運用 ○ サイバージェント 秋葉原ラボのHBase 活用事例 ■ PatriotにおけるHBaseの利用事例を紹介 6
7.
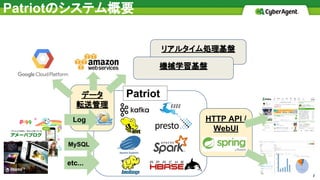
Patriotのシステム概要 7 システム構成 リアルタイム処理基盤 MySQL etc... 機械学習基盤 HTTP API / WebUI データ 転送管理 Log Patriot
8.
Patriotにおけるストリーム処理 ● ログの転送 ○ サービスにおけるユーザの行動ログを適切な場所に転送 ●
ログのフィルタリング ○ ログスキーマに則ったバリデーション等 ● ログの加工 ○ Online Joiner等 ● リアルタイム集計 ○ 秋葉原ラボのプロダクトとしてはZeroが担当 8
9.
目次 ● 背景 ○ ログ解析基盤Patriotについて ○
Patriotにおけるストリーム処理 ● ストリーム処理パイプライン ○ ストリーム処理パイプラインの変遷 ○ ストリーム処理パイプラインにおける遅延ログ問題 ● 現在の取り組み ○ ストリーム処理 ○ ストリーム処理以外の取り組み 9
10.
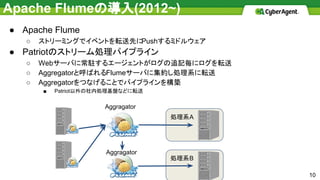
Apache Flumeの導入(2012~) ● Apache
Flume ○ ストリーミングでイベントを転送先にPushするミドルウェア ● Patriotのストリーム処理パイプライン ○ Webサーバに常駐するエージェントがログの追記毎にログを転送 ○ Aggregatorと呼ばれるFlumeサーバに集約し処理系に転送 ○ Aggregatorをつなげることでパイプラインを構築 ■ Patriot以外の社内処理基盤などに転送 処理系A 10 Aggragator Aggragator 処理系B
11.
Apache Flume導入直後の課題 ● Flumeの転送先増加に伴うパイプラインの硬直化 ○
Aggregatorに様々な条件の転送設定を追加 ○ 転送設定が複雑化し転送状況の把握や転送の変更が困難 ○ 扱える人間が限られて属人化 転送先 Aggragator 転送先 転送先 11
12.
転送管理システムの開発(2014~) ● ログの転送時にDBの転送設定を参照 ● オンラインで転送設定を変更可能 ○
管理画面から登録済み転送先を変更可能 ○ フィルタリング処理も可能 転送先 Aggragator 転送先 転送先 DB 12
13.
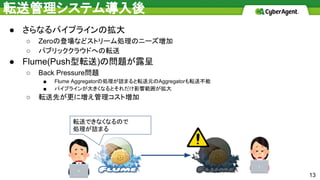
● さらなるパイプラインの拡大 ○ Zeroの登場などストリーム処理のニーズ増加 ○
パブリッククラウドへの転送 ● Flume(Push型転送)の問題が露呈 ○ Back Pressure問題 ■ Flume Aggregatorの処理が詰まると転送元のAggregatorも転送不能 ■ パイプラインが大きくなるとそれだけ影響範囲が拡大 ○ 転送先が更に増え管理コスト増加 転送管理システム導入後 転送できなくなるので 処理が詰まる 13
14.
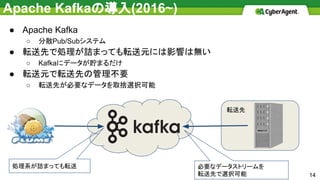
Apache Kafkaの導入(2016~) ● Apache
Kafka ○ 分散Pub/Subシステム ● 転送先で処理が詰まっても転送元には影響は無い ○ Kafkaにデータが貯まるだけ ● 転送元で転送先の管理不要 ○ 転送先が必要なデータを取捨選択可能 転送先 必要なデータストリームを 転送先で選択可能 処理系が詰まっても転送 14
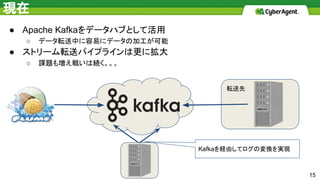
15.
現在 ● Apache Kafkaをデータハブとして活用 ○
データ転送中に容易にデータの加工が可能 ● ストリーム転送パイプラインは更に拡大 ○ 課題も増え戦いは続く。。。 転送先 15 Kafkaを経由してログの変換を実現
16.
目次 ● 背景 ○ ログ解析基盤Patriotについて ○
Patriotにおけるストリーム処理 ● ストリーム処理パイプライン ○ ストリーム処理パイプラインの変遷 ○ ストリーム処理パイプラインにおける遅延ログ問題 ● 現在の取り組み ○ ストリーム処理 ○ ストリーム処理以外の取り組み 16
17.
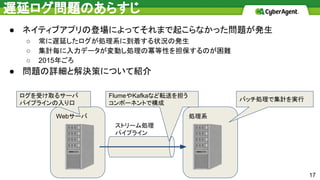
遅延ログ問題のあらすじ 17 ● ネイティブアプリの登場によってそれまで起こらなかった問題が発生 ○ 常に遅延したログが処理系に到着する状況の発生 ○
集計毎に入力データが変動し処理の冪等性を担保するのが困難 ○ 2015年ごろ ● 問題の詳細と解決策について紹介 処理系Webサーバ ストリーム処理 パイプライン バッチ処理で集計を実行 FlumeやKafkaなど転送を担う コンポーネントで構成 ログを受け取るサーバ パイプラインの入り口
18.
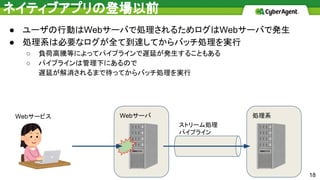
● ユーザの行動はWebサーバで処理されるためログはWebサーバで発生 ● 処理系は必要なログが全て到達してからバッチ処理を実行 ○
負荷高騰等によってパイプラインで遅延が発生することもある ○ パイプラインは管理下にあるので 遅延が解消されるまで待ってからバッチ処理を実行 処理系Webサーバ ネイティブアプリの登場以前 Webサービス ストリーム処理 パイプライン 18
19.
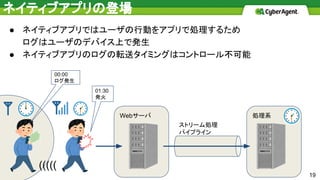
処理系Webサーバ ストリーム処理 パイプライン ● ネイティブアプリではユーザの行動をアプリで処理するため ログはユーザのデバイス上で発生 ● ネイティブアプリのログの転送タイミングはコントロール不可能 ネイティブアプリの登場 ((((( 19 00:00 ログ発生 01:30 発火
20.
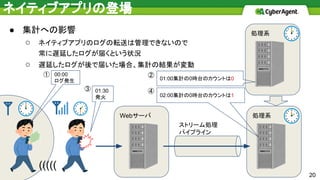
処理系Webサーバ ストリーム処理 パイプライン ● 集計への影響 ○ ネイティブアプリのログの転送は管理できないので 常に遅延したログが届くという状況 ○
遅延したログが後で届いた場合、集計の結果が変動 ネイティブアプリの登場 ((((( 20 00:00 ログ発生 処理系 01:30 発火 01:00集計の0時台のカウントは0 02:00集計の0時台のカウントは1 ① ② ③ ④
21.
遅延ログによって生じる問題 21 ● 集計に冪等性が保てない ○ バッチ処理の集計とは一度だけではない ■
パイプラインで遅延が生じていたとき ■ ログをバックアップから再取り込みするとき ○ 冪等性を確保できないということは正確な集計ができないことと同義 ● 実行タイミングを決めることができない ○ 遅延ログが常に届くので集計時刻を遅らせた方が集計値は大きくなる ○ しかしログを待ち続けているといつまでも集計を開始できない → そのため集計の冪等性を保ちつつ 実行タイミングを適切に決定するための仕組みが必要
22.
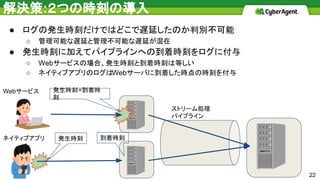
解決策:2つの時刻の導入 ● ログの発生時刻だけではどこで遅延したのか判別不可能 ○ 管理可能な遅延と管理不可能な遅延が混在 ●
発生時刻に加えてパイプラインへの到着時刻をログに付与 ○ Webサービスの場合、発生時刻と到着時刻は等しい ○ ネイティブアプリのログはWebサーバに到着した時点の時刻を付与 ネイティブアプリ 発生時刻 ストリーム処理 パイプライン Webサービス 発生時刻=到着時 刻 到着時刻 22
23.
解決策:DataFlow Model*の導入 ● DataFlow
Modelを参考にデータの選定ルールを決定 ○ ログの発生時刻だけでなくwatermark(到着時刻の最新値)を 基準に入力データの範囲と処理開始時刻を決定 ● watermarkを導入することで集計の冪等性を実現し 実行タイミングを決定 ○ 入力データの範囲は発生時刻とwatermarkによって決定 ■ watermarkよりも後に到着したログは無視することで 処理のタイミングを問わず常に同じ結果を算出可能 ○ watermarkが規定の時刻に到達した時点で処理を開始 23* [The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing Akidau et al.,2015] 到着時刻に関係しないので watermarkには影響しない 遅延によって watermarkに影響が及ぶ
24.
解決策:実装編 ● ログフォーマットの統一 ○ 時刻の配置やネイティブアプリとWebサーバのログの識別等 ○
フォーマットについては過去にデータの品質管理で紹介 ● 到着時刻の付与 ○ Webサーバでログに変換するときに付与 ○ Flumeの転送中に付与 ■ Interceptorを追加するだけで実現 ● データの選定ルール ○ Hiveのクエリで実現 24 発生時刻(event_time)の範囲 watermarkの範囲 到着時刻+1時間まで許容
25.
目次 ● 背景 ○ ログ解析基盤Patriotについて ○
Patriotにおけるストリーム処理 ● ストリーム処理パイプライン ○ ストリーム処理パイプラインの変遷 ○ ストリーム処理パイプラインにおける遅延ログ問題 ● 現在の取り組み ○ ストリーム処理 ○ ストリーム処理以外の取り組み 25
26.
ストリーム処理に関する取り組み ● ステートフルストリーム処理基盤Phalanx ○ ストリーム処理でステートフルデータの変更を実現する際に CRDT*を利用することで更新操作を簡略的に表現可能 ○
DEIM 2018で発表 ● ストリーム処理パイプライン管理基盤 ○ パイプラインに必要な簡単な処理だけを提供 ■ ログの加工、ログの選択 ○ 誰でも容易にパイプライン処理の追加を可能にするのが目的 * [Conflict-free Replicated Data TypesShapiro et al.,2011] 26
27.
ストリーム処理以外の取り組み ● Zeppelin ○ Sparkなど分散処理環境へのアクセシビリティ向上 ○
解析方法・結果の共有を容易に ● Kudu ○ Fast Data処理向けに試験的に導入中 ● Hadoopクラスタ管理ツールの開発 ○ 各プロセスの開始・停止、Rolling Restart/Upgrade ○ Zookeeper経由でGitと連携し設定変更など ● バッチ系データフローのオープン化 ○ 誰でも自由にシステム横断してバッチ処理のデータフロー管理が可能 ○ 機械学習エンジニア・データ活用エンジニアの利用を想定 27
28.
終 28
Download













![解決策:DataFlow Model*の導入
● DataFlow Modelを参考にデータの選定ルールを決定
○ ログの発生時刻だけでなくwatermark(到着時刻の最新値)を
基準に入力データの範囲と処理開始時刻を決定
● watermarkを導入することで集計の冪等性を実現し
実行タイミングを決定
○ 入力データの範囲は発生時刻とwatermarkによって決定
■ watermarkよりも後に到着したログは無視することで
処理のタイミングを問わず常に同じ結果を算出可能
○ watermarkが規定の時刻に到達した時点で処理を開始
23* [The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing Akidau et al.,2015]
到着時刻に関係しないので
watermarkには影響しない
遅延によって
watermarkに影響が及ぶ](https://image.slidesharecdn.com/cadeda5streamprocessingpipeline-180717005637/85/slide-23-320.jpg)


![ストリーム処理に関する取り組み
● ステートフルストリーム処理基盤Phalanx
○ ストリーム処理でステートフルデータの変更を実現する際に
CRDT*を利用することで更新操作を簡略的に表現可能
○ DEIM 2018で発表
● ストリーム処理パイプライン管理基盤
○ パイプラインに必要な簡単な処理だけを提供
■ ログの加工、ログの選択
○ 誰でも容易にパイプライン処理の追加を可能にするのが目的
* [Conflict-free Replicated Data TypesShapiro et al.,2011]
26](https://image.slidesharecdn.com/cadeda5streamprocessingpipeline-180717005637/85/slide-26-320.jpg)
























![[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス](https://cdn.slidesharecdn.com/ss_thumbnails/amazonauroratips-170307140000-thumbnail.jpg?width=640&height=640&fit=bounds)








![[C23] 「今」を分析するストリームデータ処理技術とその可能性 by Takahiro Yokoyama](https://cdn.slidesharecdn.com/ss_thumbnails/c23hitachiyokoyama-131215225816-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)























