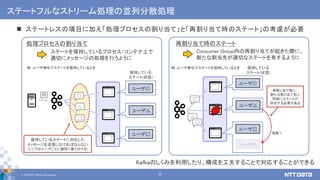
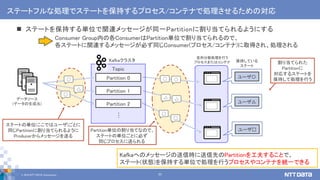
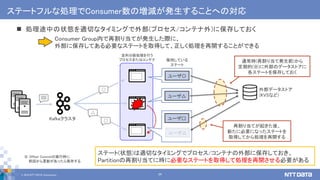
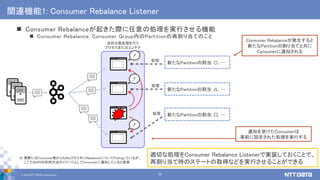
え、まって。その並列分散処理、Kafkaのしくみでもできるの? Apache Kafkaの機能を利用した大規模ストリームデータの並列分散処理 (NTTデータ テクノロジーカンファレンス 2019 講演資料、2019/09/05) NTTデータ 技術革新統括本部 システム技術本部生産技術部 インテグレーション技術センタ データ活用チーム 佐々木 徹











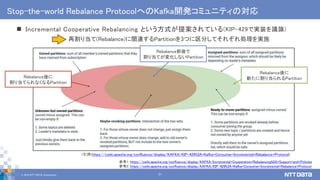












































![[DI06] 並列分散処理の考え方とオープンソース分散処理系の動向](https://cdn.slidesharecdn.com/ss_thumbnails/di06-170605024555-thumbnail.jpg?width=640&height=640&fit=bounds)
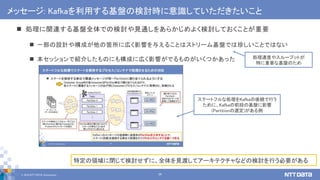
![[de:code 2017] 並列分散処理の考え方とオープンソース分散処理系の動向](https://cdn.slidesharecdn.com/ss_thumbnails/20170524decode17di06hdinsight-170702125017-thumbnail.jpg?width=640&height=640&fit=bounds)























