Downloaded 940 times




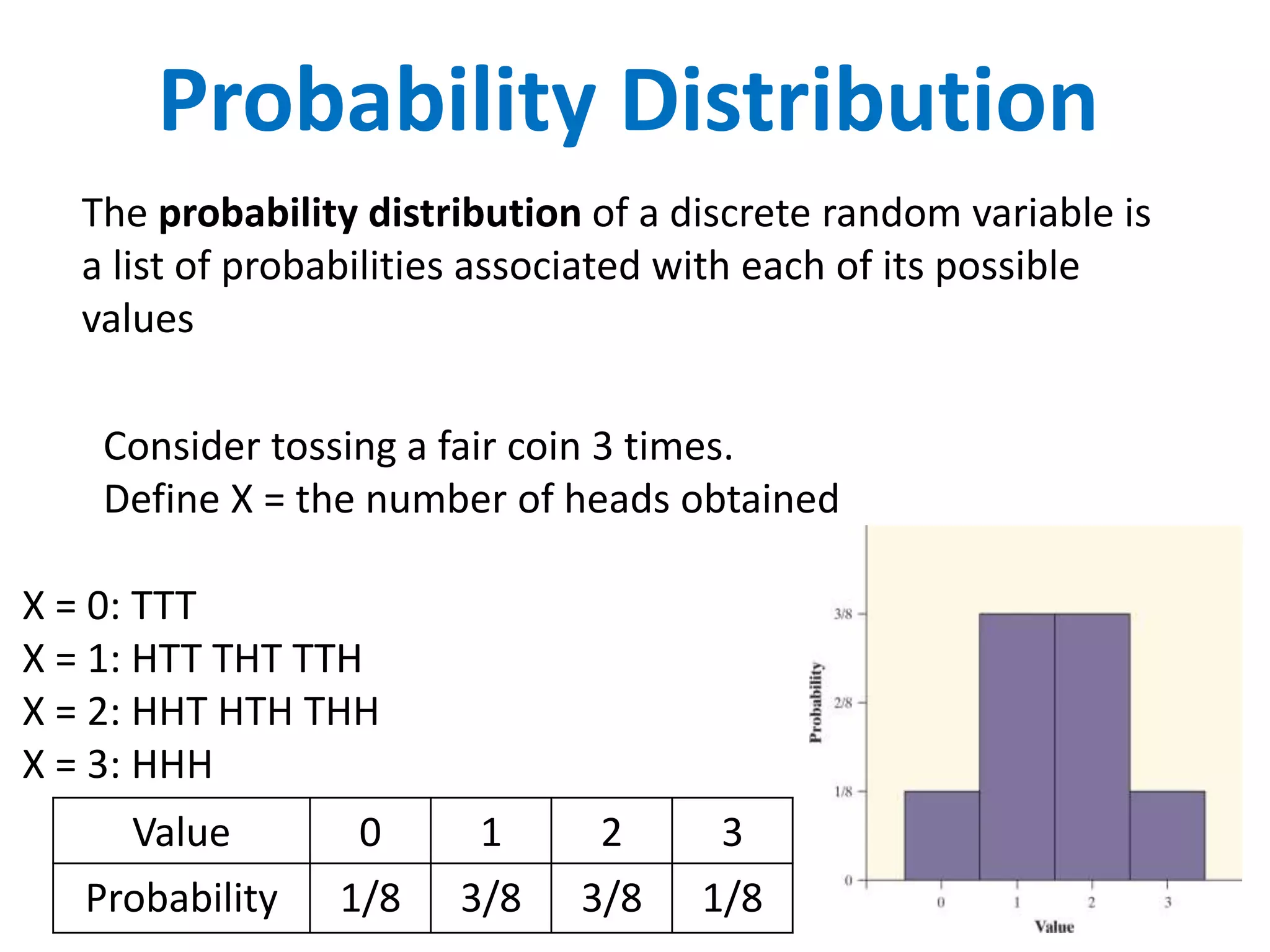

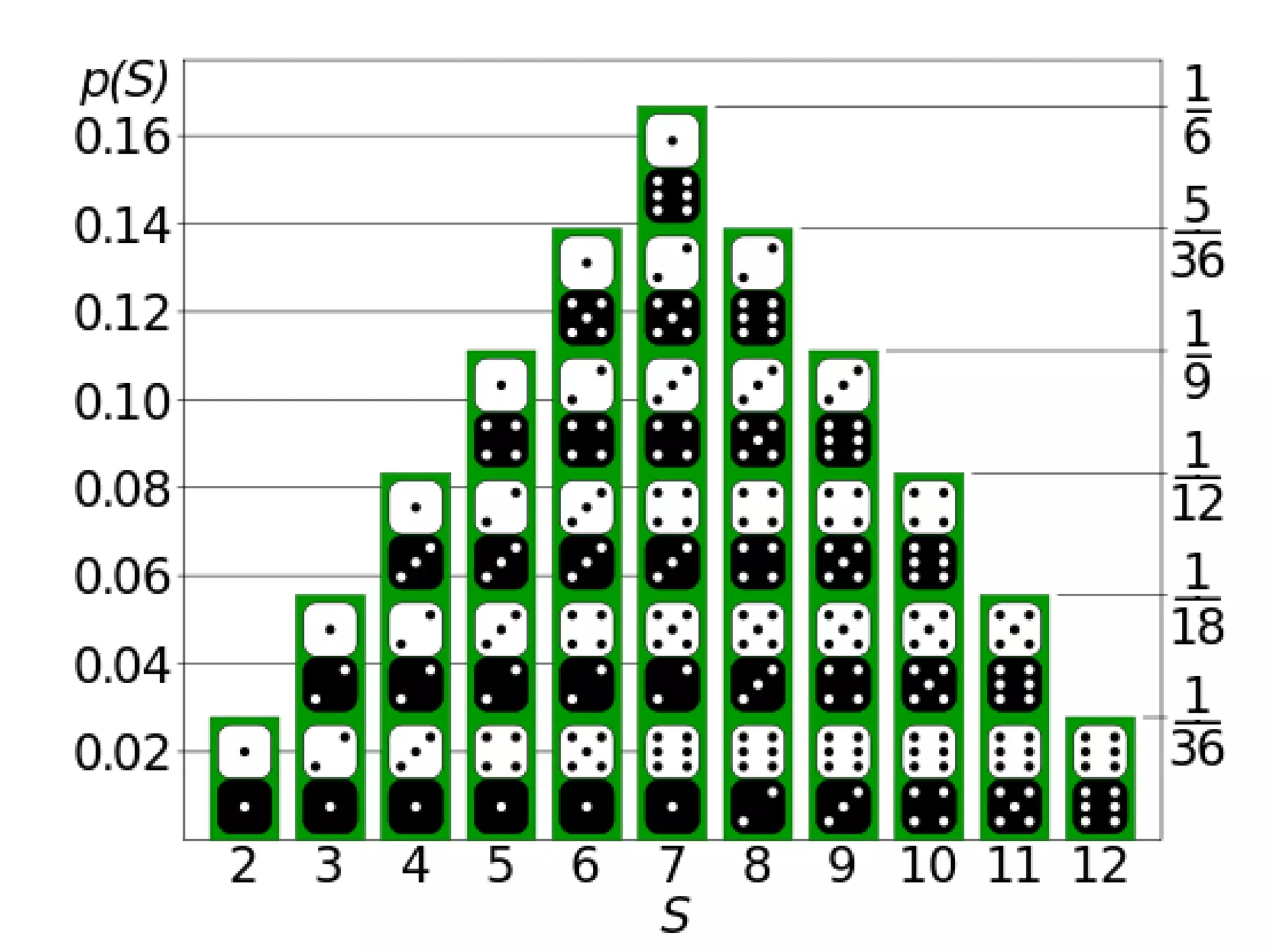

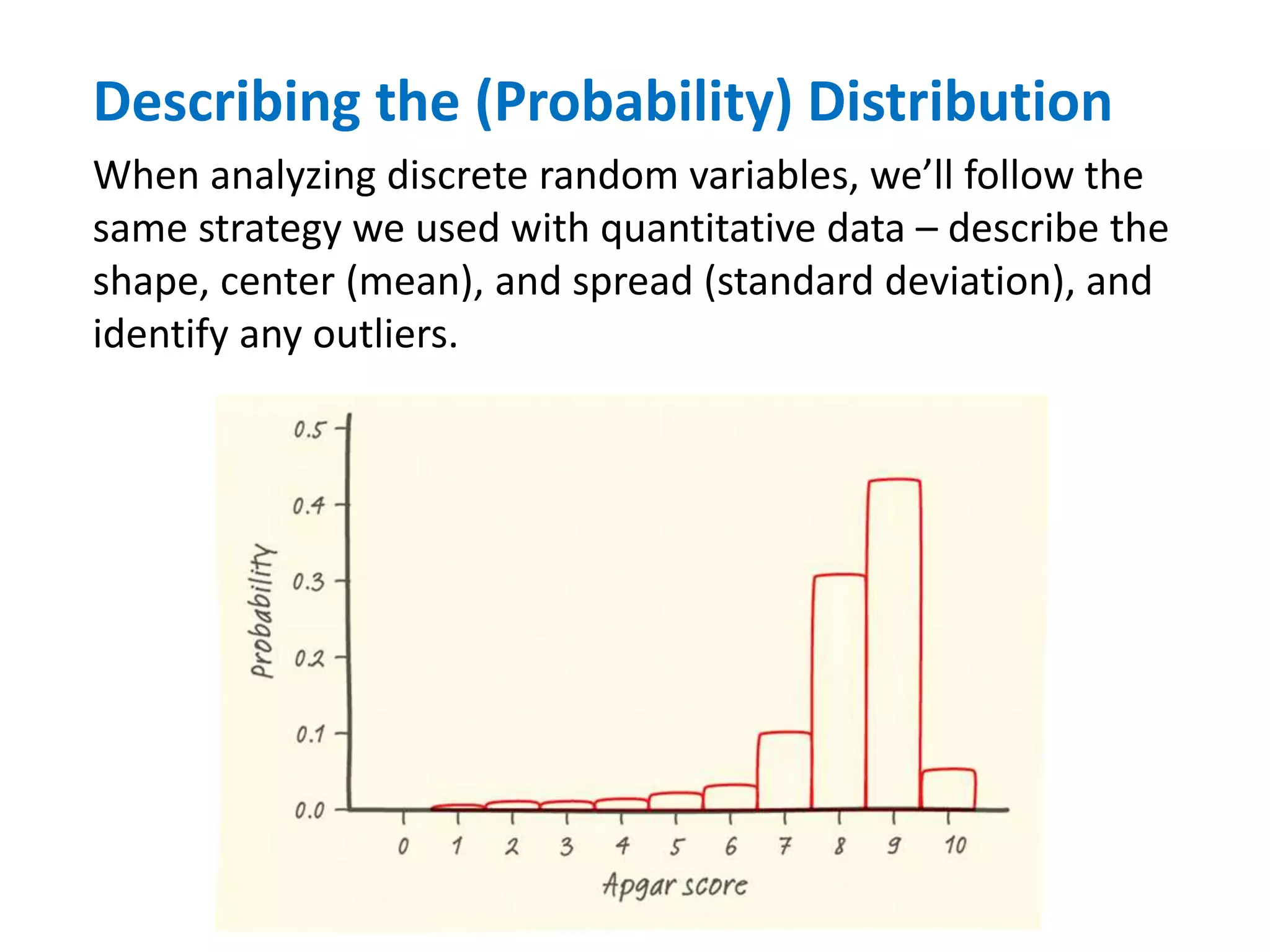


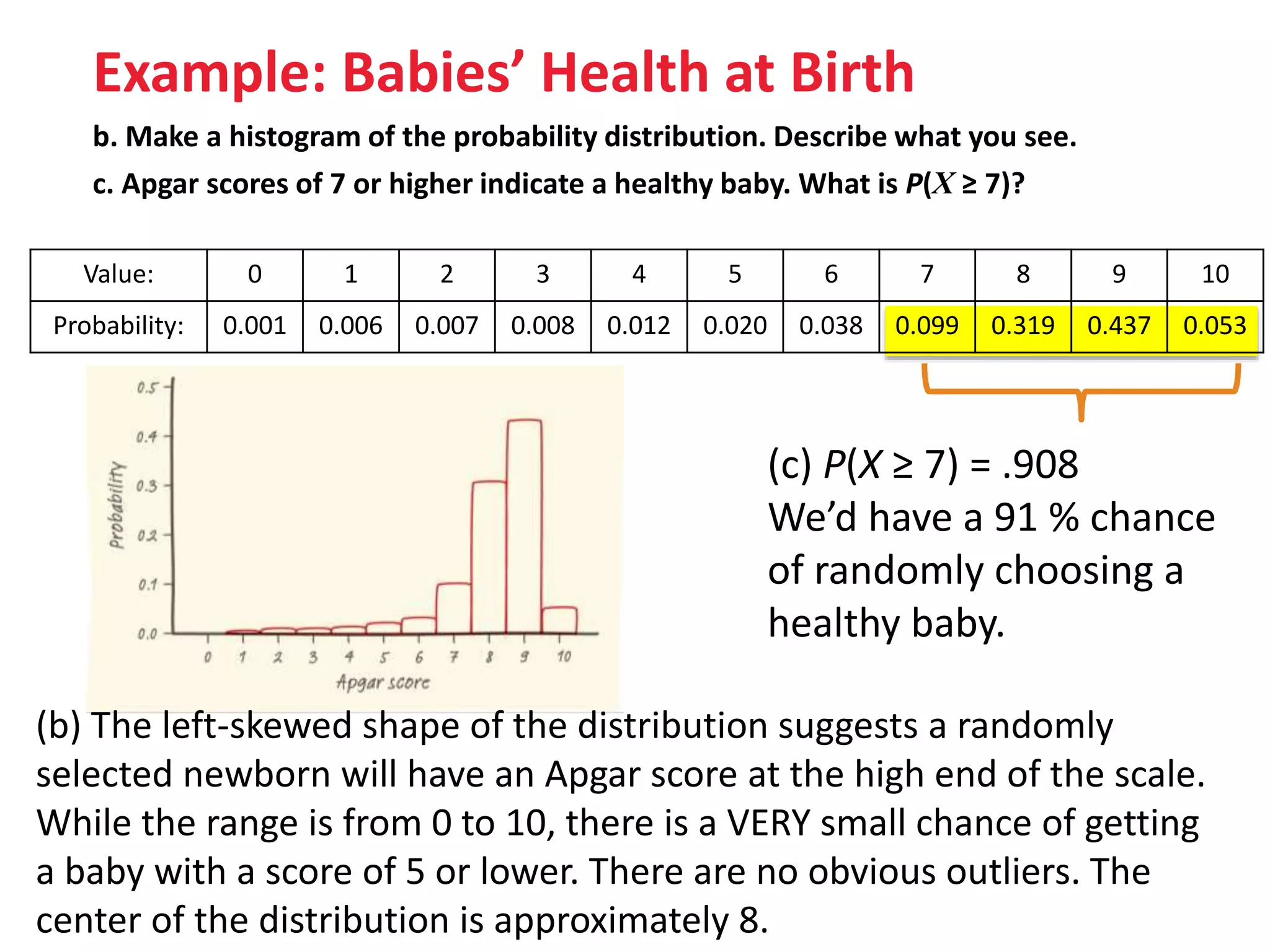






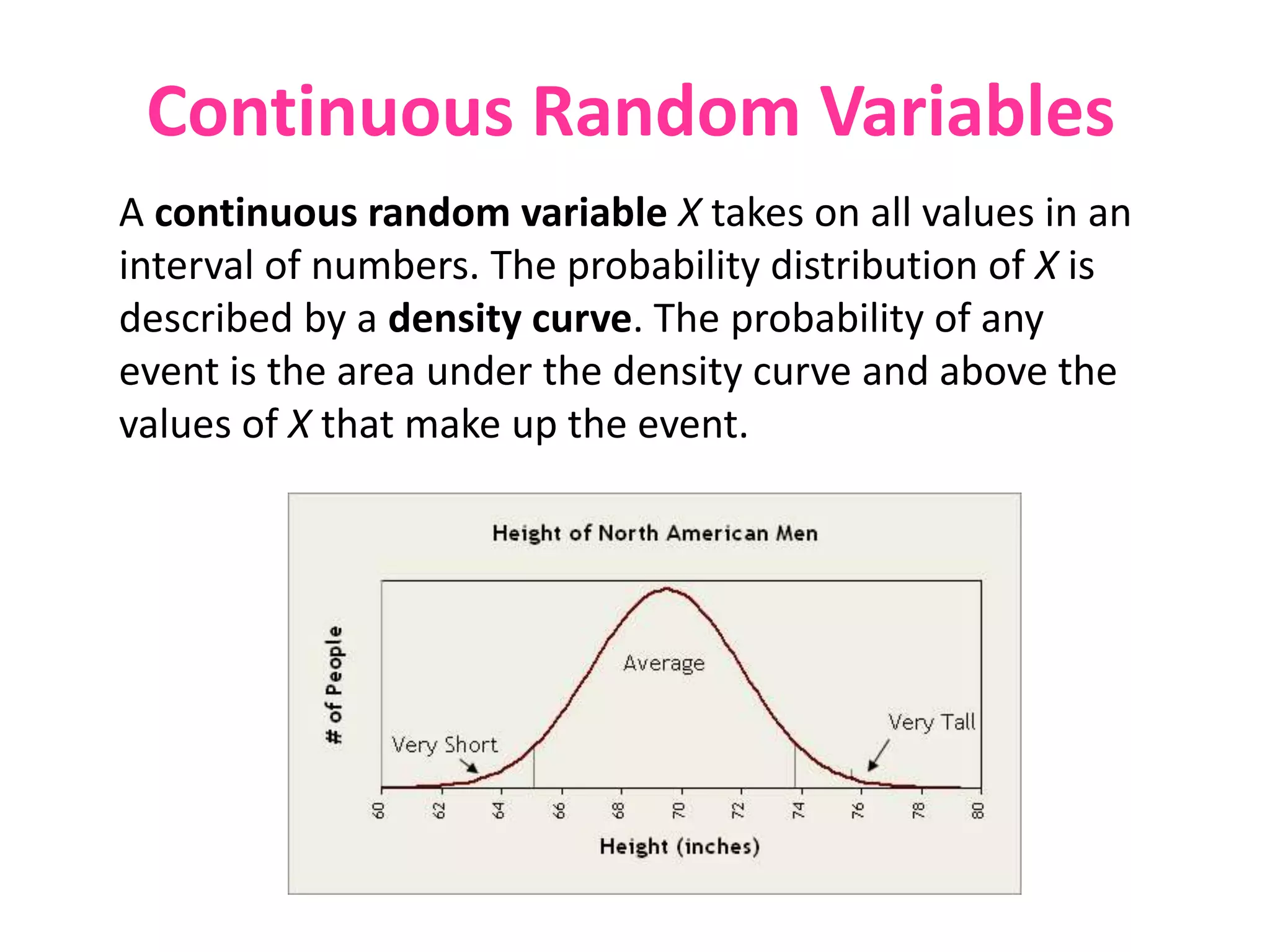
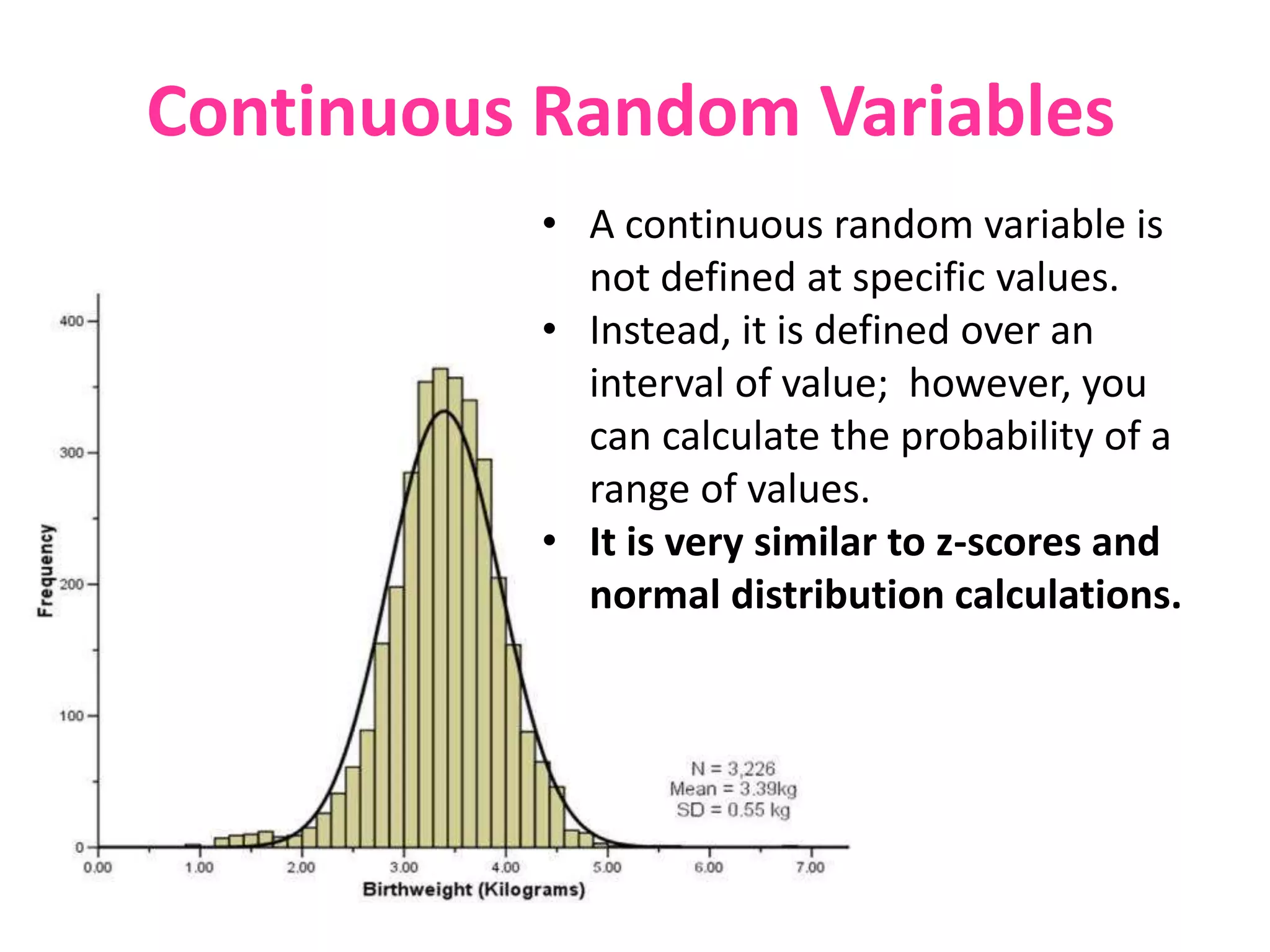

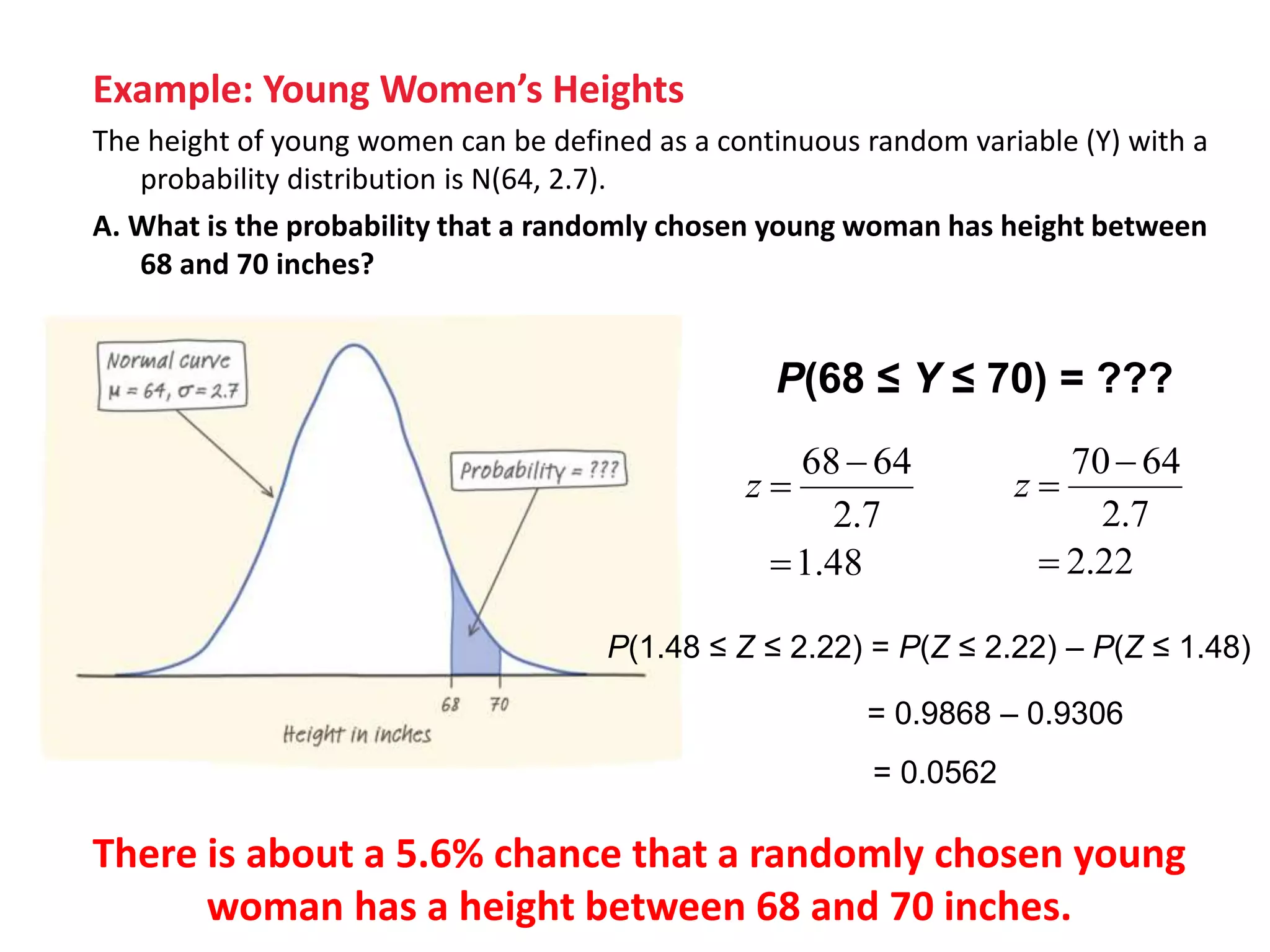



The document discusses discrete and continuous random variables. It defines discrete random variables as variables that can take on countable values, like the number of heads from coin flips. Continuous random variables can take any value within a range, like height. The document explains how to calculate and interpret the mean, standard deviation, and probabilities of events for both types of random variables using examples like Apgar scores for babies and heights of young women.













































































