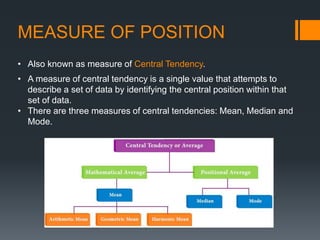
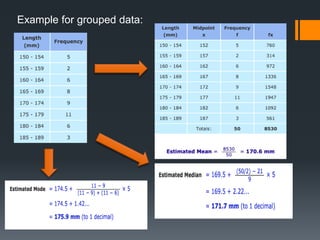
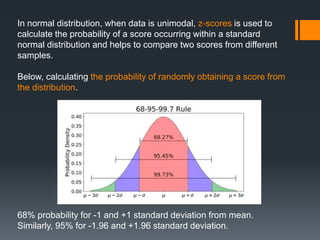
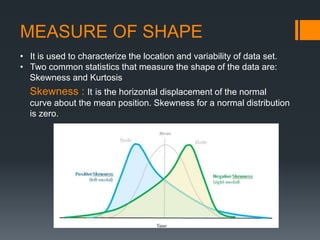
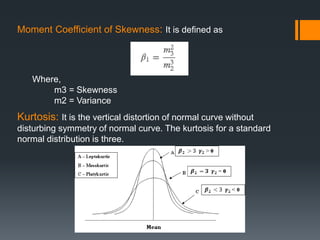
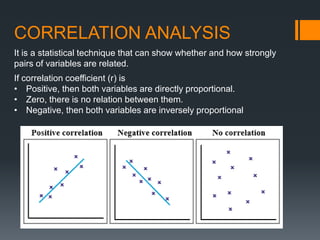
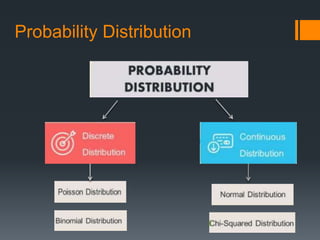
This document provides an introduction to statistics and probability. It discusses key concepts in descriptive statistics including measures of central tendency (mean, median, mode), measures of dispersion (range, standard deviation), and measures of shape (skewness, kurtosis). It also covers correlation analysis, regression analysis, and foundational probability topics such as sample spaces, events, independent and dependent events, and theorems like the addition rule, multiplication rule, and total probability theorem.




















































































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)















