More Related Content
![[第2版]Python機械学習プログラミング 第15章](https://cdn.slidesharecdn.com/ss_thumbnails/15-190318023254-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[第2版]Python機械学習プログラミング 第15章 ![[第2版]Python機械学習プログラミング 第12章](https://cdn.slidesharecdn.com/ss_thumbnails/12-190318023252-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[第2版]Python機械学習プログラミング 第12章 ![[第2版]Python機械学習プログラミング 第12章](https://cdn.slidesharecdn.com/ss_thumbnails/12-181212011918-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[第2版]Python機械学習プログラミング 第12章 ![[第2版]Python機械学習プログラミング 第14章](https://cdn.slidesharecdn.com/ss_thumbnails/14-190318023253-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[第2版]Python機械学習プログラミング 第14章 ![[第2版]Python機械学習プログラミング 第16章](https://cdn.slidesharecdn.com/ss_thumbnails/16-190318023255-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[第2版]Python機械学習プログラミング 第16章 ![[第2版]Python機械学習プログラミング 第8章](https://cdn.slidesharecdn.com/ss_thumbnails/20181015-181029035714-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[第2版]Python機械学習プログラミング 第8章 
PDF
2013.07.15 はじパタlt scikit-learnで始める機械学習 
PDF
ディープラーニングフレームワーク とChainerの実装 What's hot

PDF

PDF
DTrace for biginners part(2) 
PPTX

PDF

PDF
PythonによるDeep Learningの実装 
PDF
「深層学習」勉強会LT資料 "Chainer使ってみた" 
PDF
Chainerチュートリアル -v1.5向け- ViEW2015 
PDF
![[第2版]Python機械学習プログラミング 第9章](https://cdn.slidesharecdn.com/ss_thumbnails/09-181212011914-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[第2版]Python機械学習プログラミング 第9章 
PPT
17ゼロから作るディープラーニング2章パーセプトロン 
PDF
Deep learning勉強会20121214ochi 
PDF
深層学習フレームワークChainerの紹介とFPGAへの期待 
PDF
BMS Molecular Translation 3rd place solution 
PDF

PPTX
Deep Learning基本理論とTensorFlow 
PDF

PDF
2015年9月18日 (GTC Japan 2015) 深層学習フレームワークChainerの導入と化合物活性予測への応用 
PDF

PDF
Chainer/CuPy v5 and Future (Japanese) 
PPTX
Androidで動かすはじめてのDeepLearning Similar to [第2版]Python機械学習プログラミング 第13章

PPTX
Machine Learning Fundamentals IEEE 
PDF
TensorflowとKerasによる深層学習のプログラム実装実践講座 
PPTX
機械学習 / Deep Learning 大全 (2) Deep Learning 基礎編 
PDF
Scikit-learn and TensorFlow Chap-14 RNN (v1.1) 
PDF

DOCX

PPTX

PPTX

PDF
TensorFlowの使い方(in Japanese) 
PPTX
![[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...](https://cdn.slidesharecdn.com/ss_thumbnails/adobepdffile2-190628001736-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw... 
PDF

PDF

PDF
Deep Learning Demonstration using Tensorflow (7th lecture) 
PDF
「ゼロから作るDeep learning」の畳み込みニューラルネットワークのハードウェア化 
PDF
TensorFlow White Paperを読む 
PDF

PDF
第3回機械学習勉強会「色々なNNフレームワークを動かしてみよう」-Keras編- 
PDF
2018年01月27日 Keras/TesorFlowによるディープラーニング事始め 
PPTX
【macOSにも対応】AI入門「第3回:数学が苦手でも作って使えるKerasディープラーニング」 More from Haruki Eguchi
![[第2版]Python機械学習プログラミング 第11章](https://cdn.slidesharecdn.com/ss_thumbnails/11-181212011918-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[第2版]Python機械学習プログラミング 第11章 ![[第2版]Python機械学習プログラミング 第10章](https://cdn.slidesharecdn.com/ss_thumbnails/10-181212011917-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[第2版]Python機械学習プログラミング 第10章 ![[第2版]Python機械学習プログラミング 第7章](https://cdn.slidesharecdn.com/ss_thumbnails/20181001-181029035713-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[第2版]Python機械学習プログラミング 第7章 ![[第2版]Python機械学習プログラミング 第6章](https://cdn.slidesharecdn.com/ss_thumbnails/20180913-180925002302-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[第2版]Python機械学習プログラミング 第6章 ![[第2版] Python機械学習プログラミング 第5章](https://cdn.slidesharecdn.com/ss_thumbnails/python-machine-learning-2nd-edition-05-180905090112-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[第2版] Python機械学習プログラミング 第5章 ![[第2版] Python機械学習プログラミング 第4章](https://cdn.slidesharecdn.com/ss_thumbnails/python-machine-learning-2nd-edition-04-180905090111-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[第2版] Python機械学習プログラミング 第4章 ![[第2版] Python機械学習プログラミング 第3章(5節~)](https://cdn.slidesharecdn.com/ss_thumbnails/python-machine-learning-2nd-edition-03-2-180905090111-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[第2版] Python機械学習プログラミング 第3章(5節~) ![[第2版] Python機械学習プログラミング 第3章(~4節)](https://cdn.slidesharecdn.com/ss_thumbnails/python-machine-learning-2nd-edition-03-1-180905090110-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[第2版] Python機械学習プログラミング 第3章(~4節) ![[第2版] Python機械学習プログラミング 第2章](https://cdn.slidesharecdn.com/ss_thumbnails/python-machine-learning-2nd-edition-02-180905090109-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[第2版] Python機械学習プログラミング 第2章 ![[第2版] Python機械学習プログラミング 第1章](https://cdn.slidesharecdn.com/ss_thumbnails/python-machine-learning-2nd-edition-01-180905090109-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[第2版] Python機械学習プログラミング 第1章 Recently uploaded

PDF
さくらインターネットの今 法林リージョン:さくらのAIとか GPUとかイベントとか 〜2026年もバク進します!〜 
PDF

PDF
Reiwa 7 IT Strategist Afternoon I Question-1 Ansoff's Growth Vector 
PPTX

PDF
Reiwa 7 IT Strategist Afternoon I Question-1 3C Analysis 
PDF
Starlink Direct-to-Cell (D2C) 技術の概要と将来の展望 
PDF
100年後の知財業界-生成AIスライドアドリブプレゼン イーパテントYouTube配信 
PDF
2025→2026宙畑ゆく年くる年レポート_100社を超える企業アンケート総まとめ!!_企業まとめ_1229_3版 
PDF
第21回 Gen AI 勉強会「NotebookLMで60ページ超の スライドを作成してみた」 [第2版]Python機械学習プログラミング 第13章
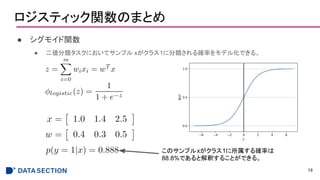
- 1.
- 2.
- 3.
- 4.
- 5.
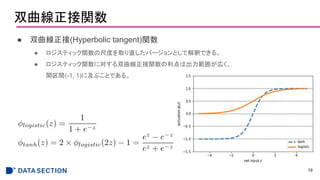
TensorFlowの学び方
● TensorFlowの低レベルAPI
5
>>> importtensorflow as tf
>>>
>>> g = tf.Graph()
>>> with g.as_default():
... x = tf.placeholder(dtype=tf.float32,shape=(None), name='x')
... w = tf.Variable(2.0, name='weight')
... b = tf.Variable(0.7, name='bias')
... z = w*x + b
... init = tf.global_variables_initializer()
...
>>> with tf.Session(graph=g) as sess:
... sess.run(init)
... for t in [1.0, 0.6, -1.8]:
... print('x=%4.1f --> z=%4.1f'%(t, sess.run(z, feed_dict={x:t})))
...
x= 1.0 --> z= 2.7
x= 0.6 --> z= 1.9
x=-1.8 --> z=-2.9
- 6.
TensorFlowの学び方
● TensorFlowの低レベルAPI(配列構造の操作)
6
>>> importnumpy as np
>>>
>>> g = tf.Graph()
>>> with g.as_default():
... x = tf.placeholder(dtype=tf.float32,
... shape=(None, 2, 3), name='input_x')
... x2 = tf.reshape(x, shape=(-1, 6), name='x2')
... xsum = tf.reduce_sum(x2, axis=0, name='col_sum')
... xmean = tf.reduce_mean(x2, axis=0, name='col_mean')
...
>>> with tf.Session(graph=g) as sess:
... x_array = np.arange(18).reshape(3, 2, 3)
... print('input shape: ', x_array.shape)
... print('Reshaped:n', sess.run(x2, feed_dict={x:x_array}))
... print('Column Sums:n',sess.run(xsum, feed_dict={x:x_array}))
... print('Column Means:n',sess.run(xmean, feed_dict={x:x_array}))
input shape: (3, 2, 3)
Reshaped:
[[ 0. 1. 2. 3. 4. 5.]
[ 6. 7. 8. 9. 10. 11.]
[ 12. 13. 14. 15. 16. 17.]]
Column Sums:
[ 18. 21. 24. 27. 30. 33.]
Column Means:
[ 6. 7. 8. 9. 10. 11.]
- 7.
- 8.
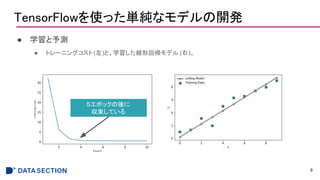
TensorFlowを使った単純なモデルの開発
● 実装
● 線形回帰モデルをz=wx+bと
定義した後、コスト関数として
平均二乗誤差(MSE)を定義する。
●重みパラメータの学習には、
勾配降下法のオプティマイザを
使用する。
8
def build(self):
self.X = tf.placeholder(dtype=tf.float32,
shape=(None, self.x_dim),
name='x_input')
self.y = tf.placeholder(dtype=tf.float32,
shape=(None), name='y_input')
w = tf.Variable(tf.zeros(shape=(1)), name='weight')
b = tf.Variable(tf.zeros(shape=(1)), name="bias")
self.z_net = tf.squeeze(w*self.X + b, name='z_net')
sqr_errors = tf.square(self.y - self.z_net,
name='sqr_errors')
self.mean_cost = tf.reduce_mean(sqr_errors,
name='mean_cost')
optimizer = tf.train.GradientDescentOptimizer(
learning_rate=self.learning_rate,
name='GradientDescent')
self.optimizer = optimizer.minimize(self.mean_cost)
- 9.
- 10.
- 11.
- 12.
- 13.
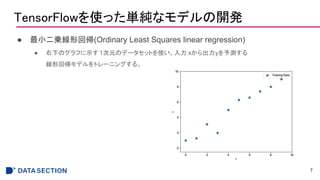
Layers APIを使って多層ニューラルネットワークを構築する
● LayersAPIによる実装
13
import tensorflow as tf
n_features = X_train_centered.shape[1]
n_classes = 10
random_seed = 123
np.random.seed(random_seed)
g = tf.Graph()
with g.as_default():
tf.set_random_seed(random_seed)
tf_x = tf.placeholder(dtype=tf.float32, shape=(None, n_features), name='tf_x')
tf_y = tf.placeholder(dtype=tf.int32, shape=None, name='tf_y')
y_onehot = tf.one_hot(indices=tf_y, depth=n_classes)
h1 = tf.layers.dense(inputs=tf_x, units=50, activation=tf.tanh, name='layer1')
h2 = tf.layers.dense(inputs=h1, units=50, activation=tf.tanh, name='layer2')
logits = tf.layers.dense(inputs=h2, units=10, activation=None, name='layer3')
predictions = {
'classes' : tf.argmax(logits, axis=1, name='predicted_classes'),
'probabilities' : tf.nn.softmax(logits, name='softmax_tensor')
}
activationで
活性化関数を指定する
ただLayerを重ねていくだけで良い
- 14.
- 15.
Kerasを使って多層ニューラルネットワークを構築する
● Kerasによる実装
15
y_train_onehot =keras.utils.to_categorical(y_train)
model = keras.models.Sequential()
model.add(
keras.layers.Dense(units=50, input_dim=X_train_centered.shape[1],
kernel_initializer='glorot_uniform', bias_initializer='zeros', activation='tanh'))
model.add(
keras.layers.Dense(units=50, input_dim=50, kernel_initializer='glorot_uniform',
bias_initializer='zeros', activation='tanh'))
model.add(
keras.layers.Dense(units=y_train_onehot.shape[1], input_dim=50, kernel_initializer='glorot_uniform',
bias_initializer='zeros', activation='softmax'))
sgd_optimizer = keras.optimizers.SGD(lr=0.001, decay=1e-7, momentum=.9)
model.compile(optimizer=sgd_optimizer, loss='categorical_crossentropy')
history = model.fit(X_train_centered, y_train_onehot, batch_size=64, epochs=50,
verbose=1, validation_split=0.1)
one-hotフォーマット変換
.add()で簡単にレイヤーを積み重ねることができる
モデルの初期化
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
![Python機械学習プログラミング
読み会
第13章
ニューラルネットワークのトレーニングをTensorFlowで並列化
1
[第2版]
基盤 江口春紀](https://image.slidesharecdn.com/13-190318023252/85/2-Python-13-1-320.jpg)



![TensorFlowの学び方
● TensorFlowの低レベルAPI
5
>>> import tensorflow as tf
>>>
>>> g = tf.Graph()
>>> with g.as_default():
... x = tf.placeholder(dtype=tf.float32,shape=(None), name='x')
... w = tf.Variable(2.0, name='weight')
... b = tf.Variable(0.7, name='bias')
... z = w*x + b
... init = tf.global_variables_initializer()
...
>>> with tf.Session(graph=g) as sess:
... sess.run(init)
... for t in [1.0, 0.6, -1.8]:
... print('x=%4.1f --> z=%4.1f'%(t, sess.run(z, feed_dict={x:t})))
...
x= 1.0 --> z= 2.7
x= 0.6 --> z= 1.9
x=-1.8 --> z=-2.9](https://image.slidesharecdn.com/13-190318023252/85/2-Python-13-5-320.jpg)
![TensorFlowの学び方
● TensorFlowの低レベルAPI(配列構造の操作)
6
>>> import numpy as np
>>>
>>> g = tf.Graph()
>>> with g.as_default():
... x = tf.placeholder(dtype=tf.float32,
... shape=(None, 2, 3), name='input_x')
... x2 = tf.reshape(x, shape=(-1, 6), name='x2')
... xsum = tf.reduce_sum(x2, axis=0, name='col_sum')
... xmean = tf.reduce_mean(x2, axis=0, name='col_mean')
...
>>> with tf.Session(graph=g) as sess:
... x_array = np.arange(18).reshape(3, 2, 3)
... print('input shape: ', x_array.shape)
... print('Reshaped:n', sess.run(x2, feed_dict={x:x_array}))
... print('Column Sums:n',sess.run(xsum, feed_dict={x:x_array}))
... print('Column Means:n',sess.run(xmean, feed_dict={x:x_array}))
input shape: (3, 2, 3)
Reshaped:
[[ 0. 1. 2. 3. 4. 5.]
[ 6. 7. 8. 9. 10. 11.]
[ 12. 13. 14. 15. 16. 17.]]
Column Sums:
[ 18. 21. 24. 27. 30. 33.]
Column Means:
[ 6. 7. 8. 9. 10. 11.]](https://image.slidesharecdn.com/13-190318023252/85/2-Python-13-6-320.jpg)




![Layers APIを使って多層ニューラルネットワークを構築する
● Layers APIによる実装
13
import tensorflow as tf
n_features = X_train_centered.shape[1]
n_classes = 10
random_seed = 123
np.random.seed(random_seed)
g = tf.Graph()
with g.as_default():
tf.set_random_seed(random_seed)
tf_x = tf.placeholder(dtype=tf.float32, shape=(None, n_features), name='tf_x')
tf_y = tf.placeholder(dtype=tf.int32, shape=None, name='tf_y')
y_onehot = tf.one_hot(indices=tf_y, depth=n_classes)
h1 = tf.layers.dense(inputs=tf_x, units=50, activation=tf.tanh, name='layer1')
h2 = tf.layers.dense(inputs=h1, units=50, activation=tf.tanh, name='layer2')
logits = tf.layers.dense(inputs=h2, units=10, activation=None, name='layer3')
predictions = {
'classes' : tf.argmax(logits, axis=1, name='predicted_classes'),
'probabilities' : tf.nn.softmax(logits, name='softmax_tensor')
}
activationで
活性化関数を指定する
ただLayerを重ねていくだけで良い](https://image.slidesharecdn.com/13-190318023252/85/2-Python-13-13-320.jpg)

![Kerasを使って多層ニューラルネットワークを構築する
● Kerasによる実装
15
y_train_onehot = keras.utils.to_categorical(y_train)
model = keras.models.Sequential()
model.add(
keras.layers.Dense(units=50, input_dim=X_train_centered.shape[1],
kernel_initializer='glorot_uniform', bias_initializer='zeros', activation='tanh'))
model.add(
keras.layers.Dense(units=50, input_dim=50, kernel_initializer='glorot_uniform',
bias_initializer='zeros', activation='tanh'))
model.add(
keras.layers.Dense(units=y_train_onehot.shape[1], input_dim=50, kernel_initializer='glorot_uniform',
bias_initializer='zeros', activation='softmax'))
sgd_optimizer = keras.optimizers.SGD(lr=0.001, decay=1e-7, momentum=.9)
model.compile(optimizer=sgd_optimizer, loss='categorical_crossentropy')
history = model.fit(X_train_centered, y_train_onehot, batch_size=64, epochs=50,
verbose=1, validation_split=0.1)
one-hotフォーマット変換
.add()で簡単にレイヤーを積み重ねることができる
モデルの初期化](https://image.slidesharecdn.com/13-190318023252/85/2-Python-13-15-320.jpg)