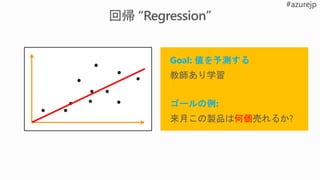
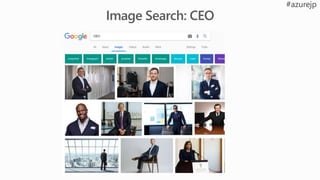
Is there adeer in
the image?
Where is the deer
in the image?
Where exactly is the
deer? What pixels?
Which images are similar
to the query image?
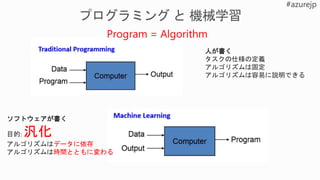
Image
Classification
Object
detection
Image
segmentation
Image
Similarity
Similar
image
Query
imageYes
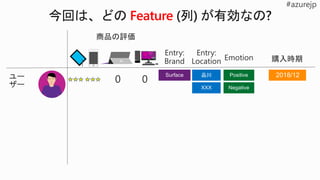
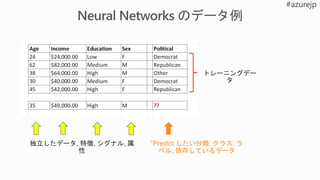
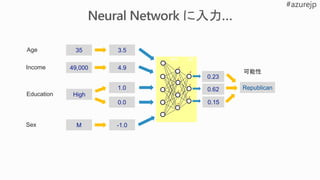
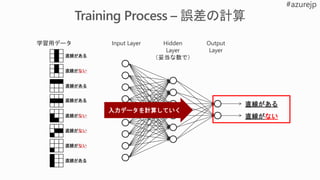
Mileage
Condition
Car brand
Year ofmake
Regulations
…
Parameter 1
Parameter 2
Parameter 3
Parameter 4
…
Gradient Boosted
Nearest Neighbors
SVM
Bayesian Regression
LGBM
…
Mileage Gradient Boosted Criterion
Loss
Min Samples Split
Min Samples Leaf
Others Model
Which algorithm? Which parameters?Which features?
Car brand
Year of make
48.
Criterion
Loss
Min Samples Split
MinSamples Leaf
Others
N Neighbors
Weights
Metric
P
Others
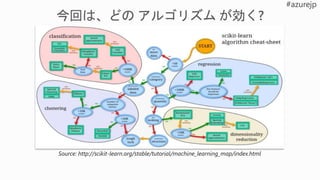
Which algorithm? Which parameters?Which features?
Mileage
Condition
Car brand
Year of make
Regulations
…
Gradient Boosted
Nearest Neighbors
SVM
Bayesian Regression
LGBM
…
Nearest Neighbors
Model
繰り返し
Gradient BoostedMileage
Car brand
Year of make
Car brand
Year of make
Condition
49.
Mileage
Condition
Car brand
Year ofmake
Regulations
…
Gradient Boosted
Nearest Neighbors
SVM
Bayesian Regression
LGBM
…
Gradient Boosted
SVM
Bayesian Regression
LGBM
Nearest Neighbors
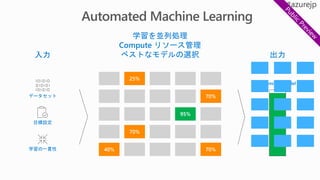
Which algorithm? Which parameters?Which features?
繰り返し
Regulations
Condition
Mileage
Car brand
Year of make
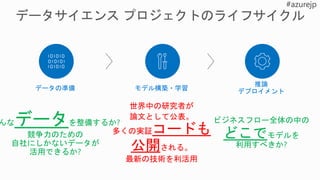
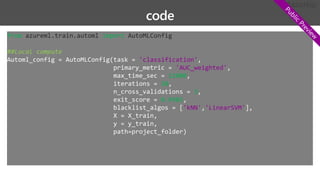
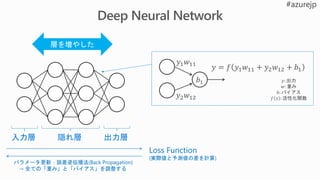
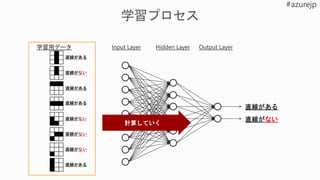
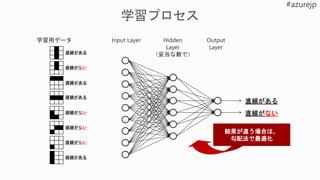
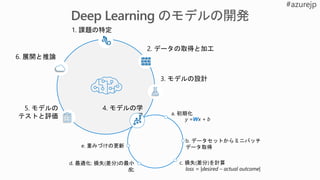
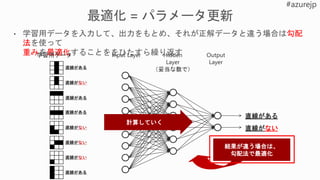
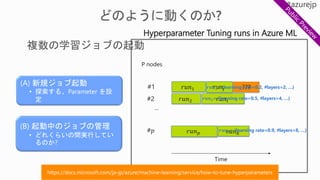
1. 課題の特定
2. データの取得と加工
3.モデルの設計
4. モデルの学
習
5. モデルの
テストと評価 a. 初期化
b. データセットからミニバッチ
データ取得
c. 損失(差分)を計算d. 最適化: 損失(差分)の最小
化
e. 重みづけの更新
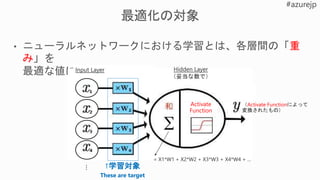
y =Wx + b
loss = |desired – actual outcome|δ
6. 展開と推論
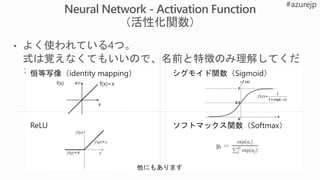
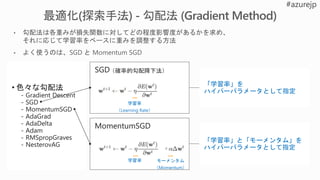
L1
regularization
L2
regularization
Cost function(C0) にL1正規化項を追加
※λ:正規化パラメータ
wが大きい:L1 shrinks the weight much less than L2 does.
wが小さい: L1 shrinks the weight much more than L2 does.
Cost function(C0) にL2正規化項を追加
※λ:正規化パラメータ
→The effect of regularization is to make it so the network
prefer to learn small weight
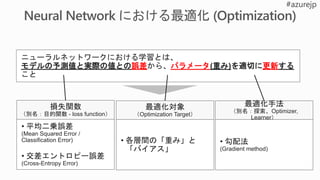
Wight decay it makes weight smaller lower complexity reduce overfitting
引用例:http://sig.tsg.ne.jp/ml2015/ml/2015/06/29/techniques-of-learning.html
















![karugamoが写っているの
に、
モデルは推定できなかっ
た
▶モデルの見逃し
あり[予
測]
なし[予
測]
あり[正
解]
XX XX
なし[正
解]
XX XX](https://image.slidesharecdn.com/or4stdcstso3y2ge9y9j-signature-374c82f34edef39b70b04446703e9695f18e1b3f7ea39a07954eb973cfcf3ba4-poli-181106173251/85/slide-36-320.jpg)
![Karugamo でないもの
に、
Karugamo と推定
▶モデルの過検知?
あり[予
測]
なし[予
測]
あり[正
解]
XX XX
なし[正
解]
XX XX](https://image.slidesharecdn.com/or4stdcstso3y2ge9y9j-signature-374c82f34edef39b70b04446703e9695f18e1b3f7ea39a07954eb973cfcf3ba4-poli-181106173251/85/slide-37-320.jpg)





































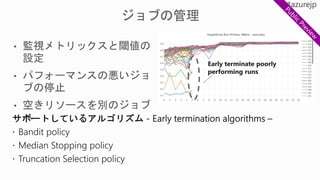
![Challenges
• 探索箇所が広大
• 低密度の中での、最適な値の組み合
わせ
• 評価までのリソースが膨大(時間、人、
カネ)
例えば..
• Number_of_layers と
learning_rate の最適値
• Number_of_layers – [2, 4, 8]
• learning_rate – 0 から 1 の間の
あらゆる値](https://image.slidesharecdn.com/or4stdcstso3y2ge9y9j-signature-374c82f34edef39b70b04446703e9695f18e1b3f7ea39a07954eb973cfcf3ba4-poli-181106173251/85/slide-100-320.jpg)














![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)











![[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...](https://cdn.slidesharecdn.com/ss_thumbnails/dl20220318dlfin-220322065433-thumbnail.jpg?width=640&height=640&fit=bounds)



















































