Downloaded 36 times





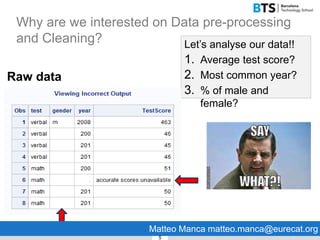

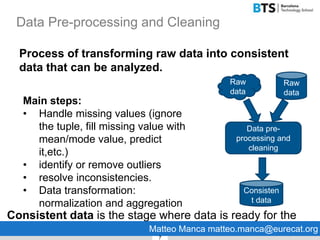
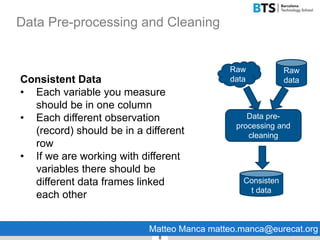
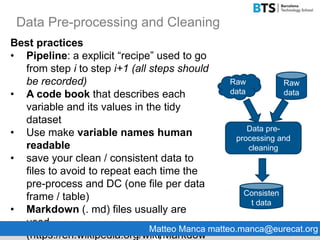






This document discusses data preparation and cleaning. It begins by explaining why data cleaning is important, as raw data is often incomplete, noisy, inconsistent, or not in a format suitable for analysis. The main steps of data cleaning are then outlined, including handling missing values, identifying outliers, resolving inconsistencies, and transforming data. Best practices for data cleaning like using pipelines to document the cleaning process and saving clean data files are also presented. Finally, the document introduces R and RStudio as tools that can be used for data cleaning.























































































