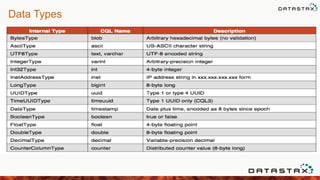
Downloaded 363 times

















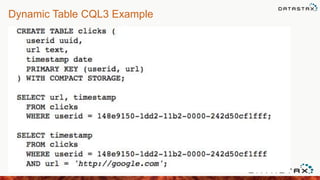
![Cassandra Collections - List
• Ordered by insertion
27
list_example list<text>
Collection
name
Collection
type
CQL
Type
INSERT INTO collections_example (id, list_example)
VALUES(1, ['1-one', '2-two']);](https://image.slidesharecdn.com/meetup-140415122737-phpapp02/85/Apache-Cassandra-Data-Modeling-with-Travis-Price-27-320.jpg)
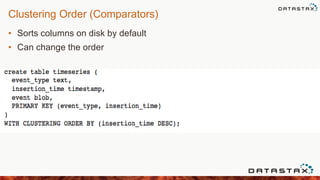
![Cassandra Collections - List Operations
• Adding an element to the end of a list
28
UPDATE collections_example
SET list_example = list_example + ['3-three'] WHERE id = 1;
UPDATE collections_example
SET list_example = ['0-zero'] + list_example WHERE id = 1;
• Adding an element to the beginning of a list
UPDATE collections_example
SET list_example = list_example - ['3-three'] WHERE id = 1;
• Deleting an element from a list](https://image.slidesharecdn.com/meetup-140415122737-phpapp02/85/Apache-Cassandra-Data-Modeling-with-Travis-Price-28-320.jpg)
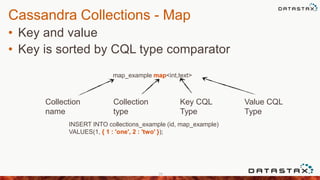
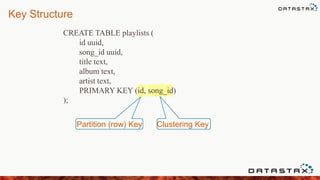
![Cassandra Collections - Map Operations
• Add an element to the map
30
UPDATE collections_example
SET map_example[3] = 'three' WHERE id = 1;
UPDATE collections_example
SET map_example[3] = 'tres' WHERE id = 1;
DELETE map_example[3]
FROM collections_example WHERE id = 1;
• Update an existing element in the map
• Delete an element in the map](https://image.slidesharecdn.com/meetup-140415122737-phpapp02/85/Apache-Cassandra-Data-Modeling-with-Travis-Price-30-320.jpg)

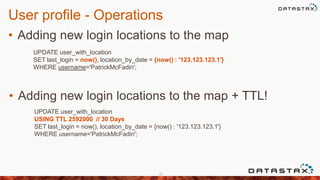





























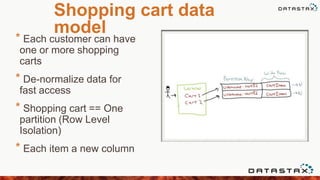
![Concurrent Writes
• A row is always referenced by a Key
• Keys are just bytes
• They must be unique within a CF
• Primary keys are unique
• But Cassandra will not enforce uniqueness
• If you are not careful you will accidentally
[UPSERT] the whole thing](https://image.slidesharecdn.com/meetup-140415122737-phpapp02/85/Apache-Cassandra-Data-Modeling-with-Travis-Price-65-320.jpg)















![The race is on
Process 1 Process 2
SELECT firstName, lastName
FROM users
WHERE username = 'pmcfadin'; SELECT firstName, lastName
FROM users
WHERE username = 'pmcfadin';
(0 rows)
(0 rows)
INSERT INTO users (username, firstname,
lastname, email, password, created_date)
VALUES ('pmcfadin','Patrick','McFadin',
['patrick@datastax.com'],
'ba27e03fd95e507daf2937c937d499ab',
'2011-06-20 13:50:00'); INSERT INTO users (username, firstname,
lastname, email, password, created_date)
VALUES ('pmcfadin','Paul','McFadin',
['paul@oracle.com'],
'ea24e13ad95a209ded8912e937d499de',
'2011-06-20 13:51:00');
T0
T1
T2
T3
Got nothing! Good to go!
This one wins](https://image.slidesharecdn.com/meetup-140415122737-phpapp02/85/Apache-Cassandra-Data-Modeling-with-Travis-Price-86-320.jpg)

![Solution LWT
Process 1
INSERT INTO users (username, firstname,
lastname, email, password, created_date)
VALUES ('pmcfadin','Patrick','McFadin',
['patrick@datastax.com'],
'ba27e03fd95e507daf2937c937d499ab',
'2011-06-20 13:50:00')
IF NOT EXISTS;
T0
T1
[applied]
-----------
True
•Check performed for record
•Paxos ensures exclusive access
•applied = true: Success](https://image.slidesharecdn.com/meetup-140415122737-phpapp02/85/Apache-Cassandra-Data-Modeling-with-Travis-Price-90-320.jpg)
![Solution LWT
Process 2
T2
T3
[applied] | username | created_date | firstname | lastname
-----------+----------+--------------------------+-----------+----------
False | pmcfadin | 2011-06-20 13:50:00-0700 | Patrick | McFadin
INSERT INTO users (username, firstname,
lastname, email, password, created_date)
VALUES ('pmcfadin','Paul','McFadin',
['paul@oracle.com'],
'ea24e13ad95a209ded8912e937d499de',
'2011-06-20 13:51:00')
IF NOT EXISTS;
•applied = false: Rejected
•No record stomping!](https://image.slidesharecdn.com/meetup-140415122737-phpapp02/85/Apache-Cassandra-Data-Modeling-with-Travis-Price-91-320.jpg)














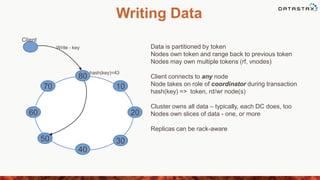
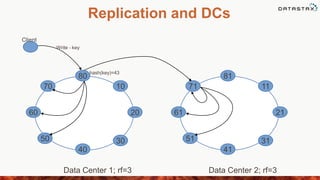
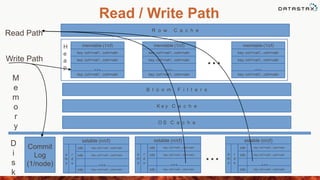
This document provides an overview of data modeling in Cassandra, including: - The components of the Cassandra schema including columns, column families, keyspaces, and clusters. - Best practices for designing Cassandra data models including working backwards from application requirements and de-normalizing data. - Features like compound primary keys, secondary indexes, collections, and partitioning that help optimize data models for Cassandra. - Examples of different types of column families and modeling patterns for user profiles, activity logs, and other common use cases.

































![[Cassandra summit Tokyo, 2015] Cassandra 2015 最新情報 by ジョナサン・エリス(Jonathan Ellis)](https://cdn.slidesharecdn.com/ss_thumbnails/tokyocassandrasummit2015withnotes-150624051836-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)





























































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)










