Download as ODP, PPTX



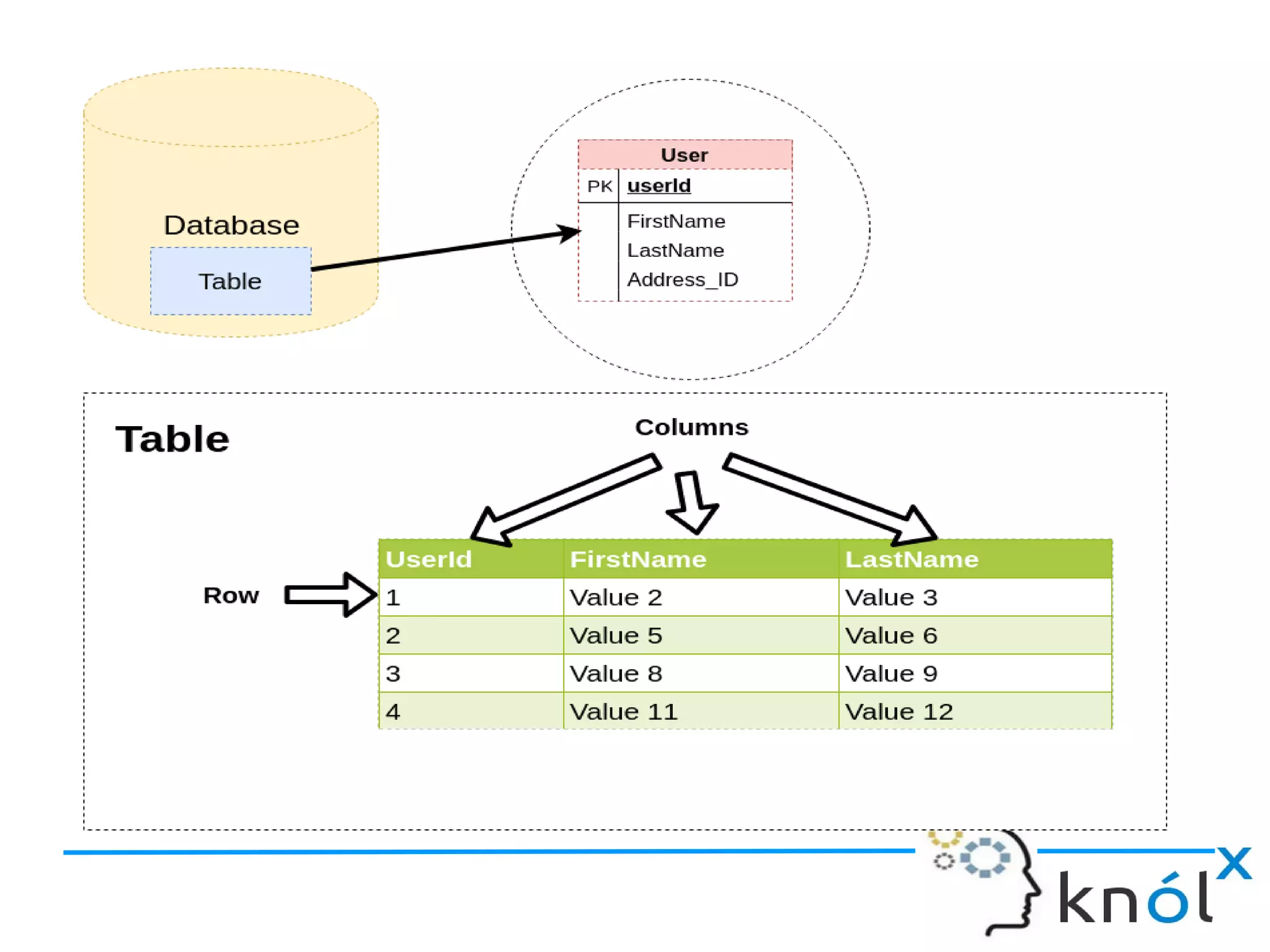




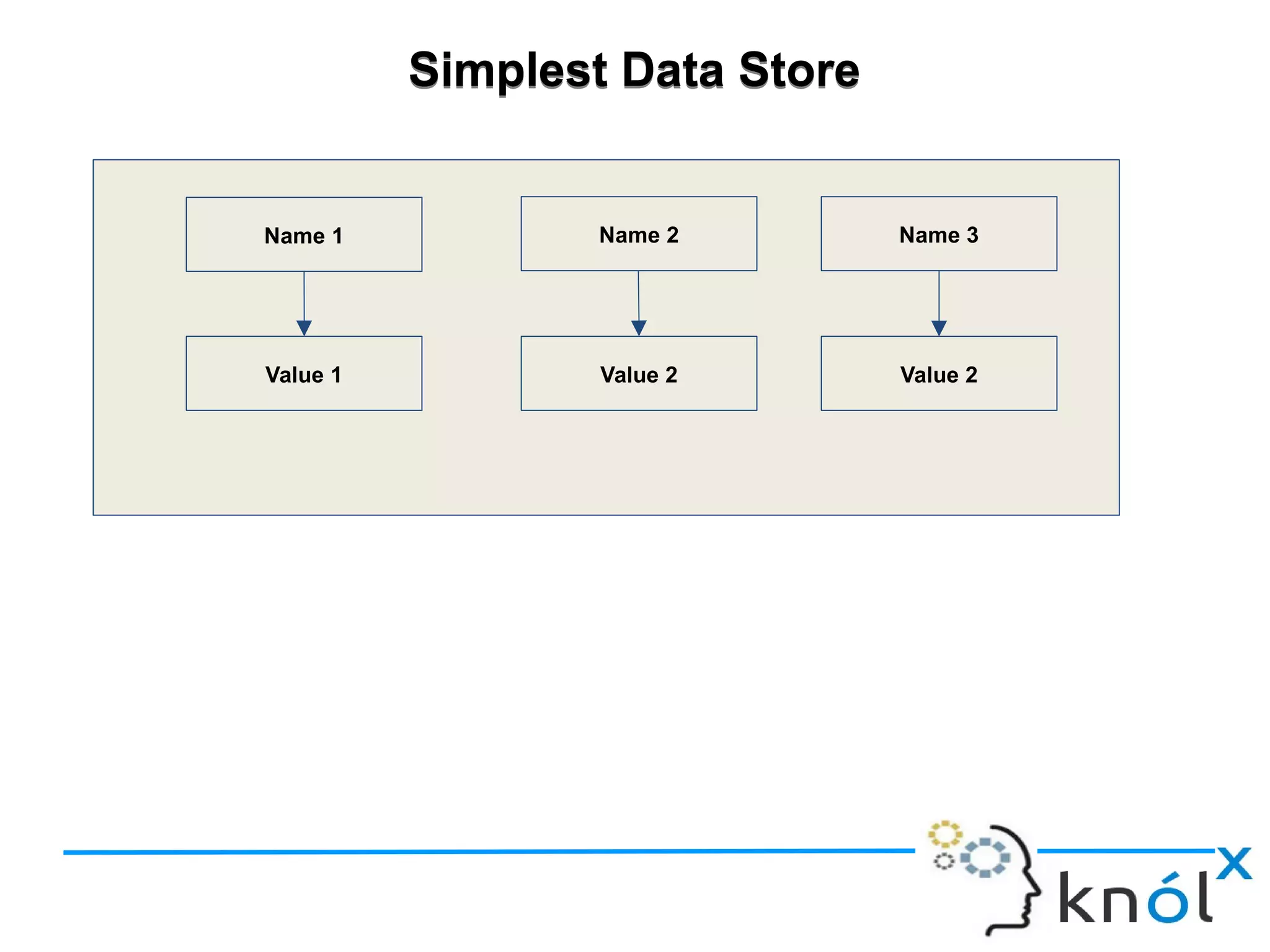
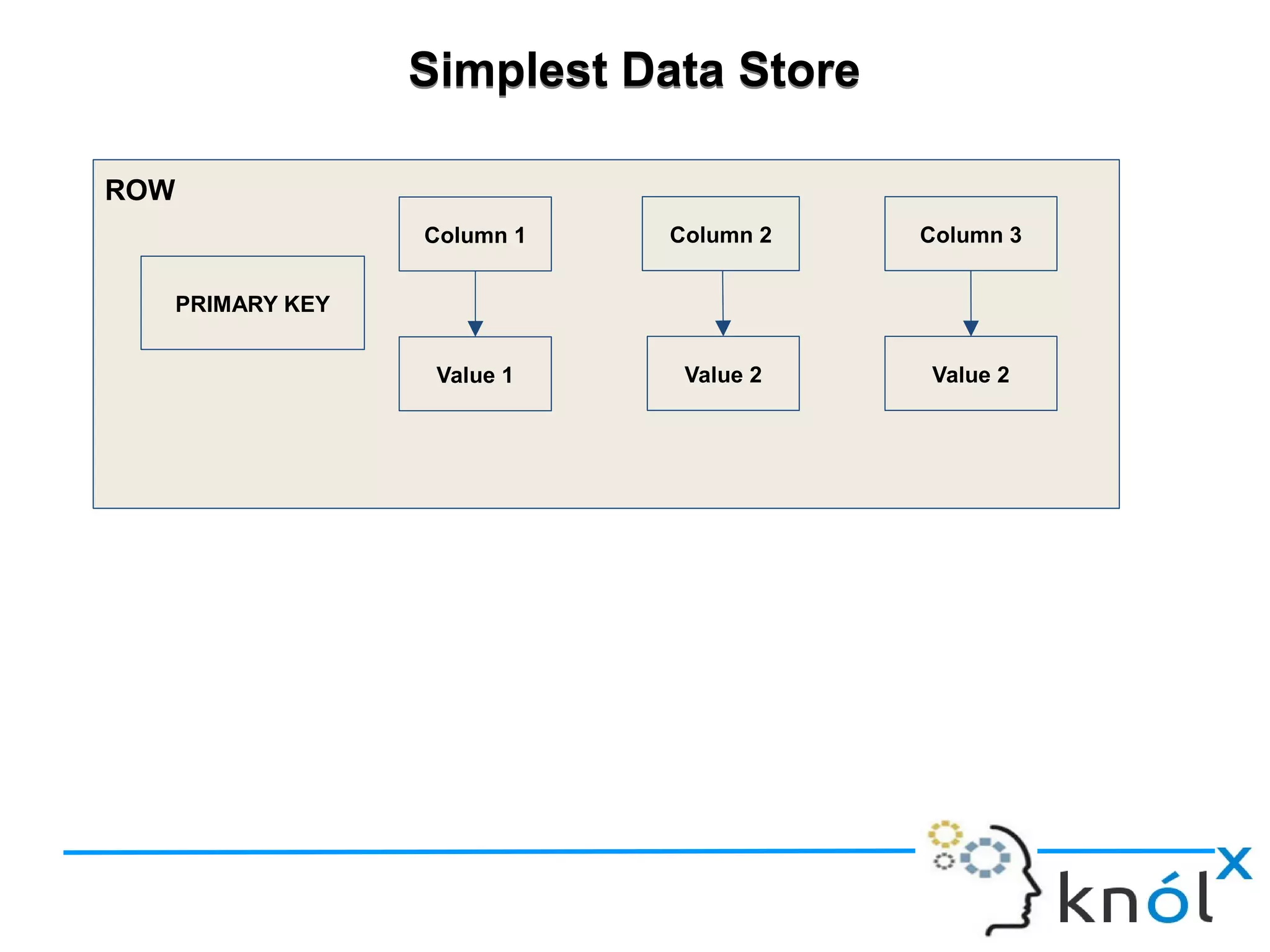
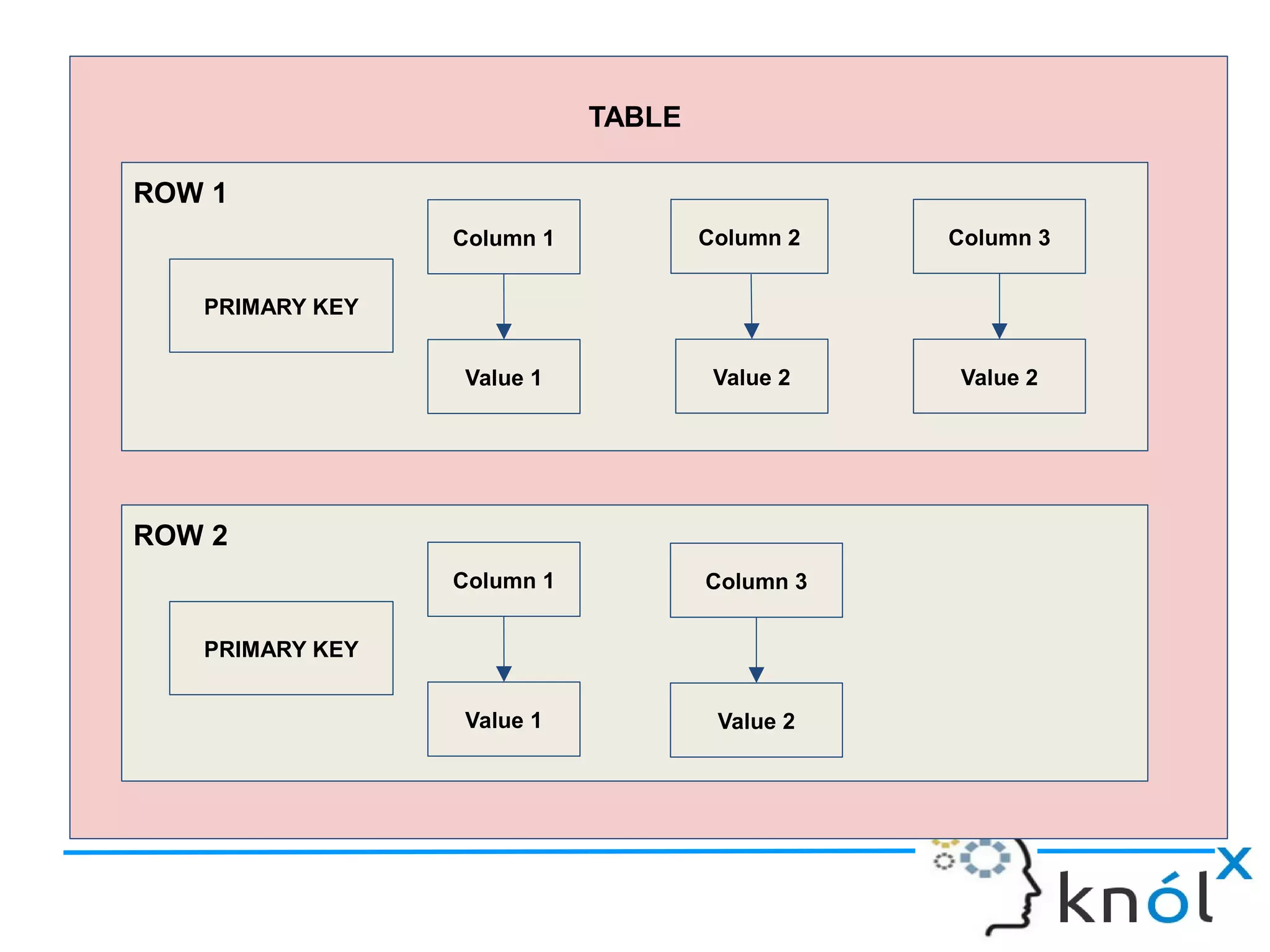
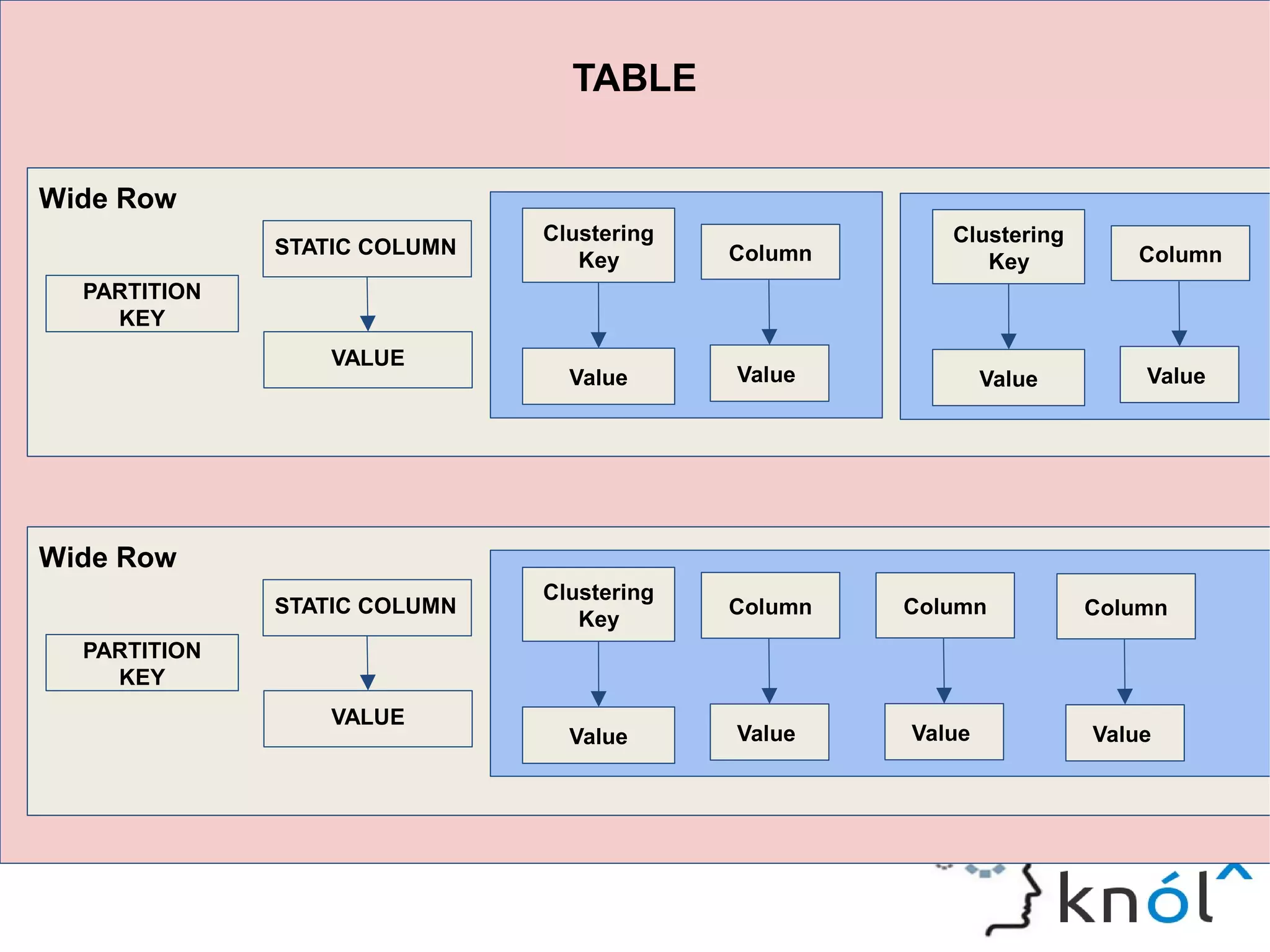


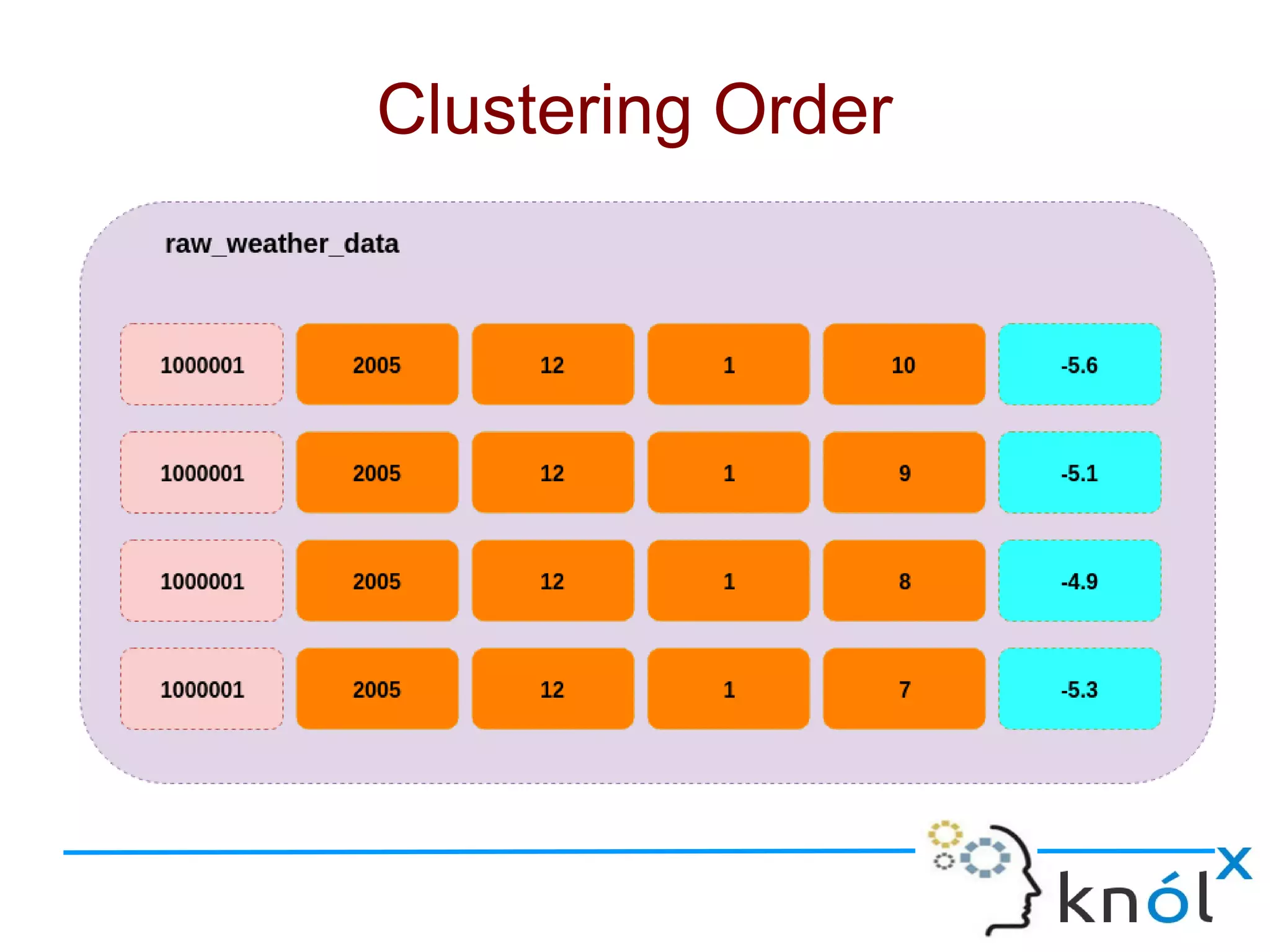


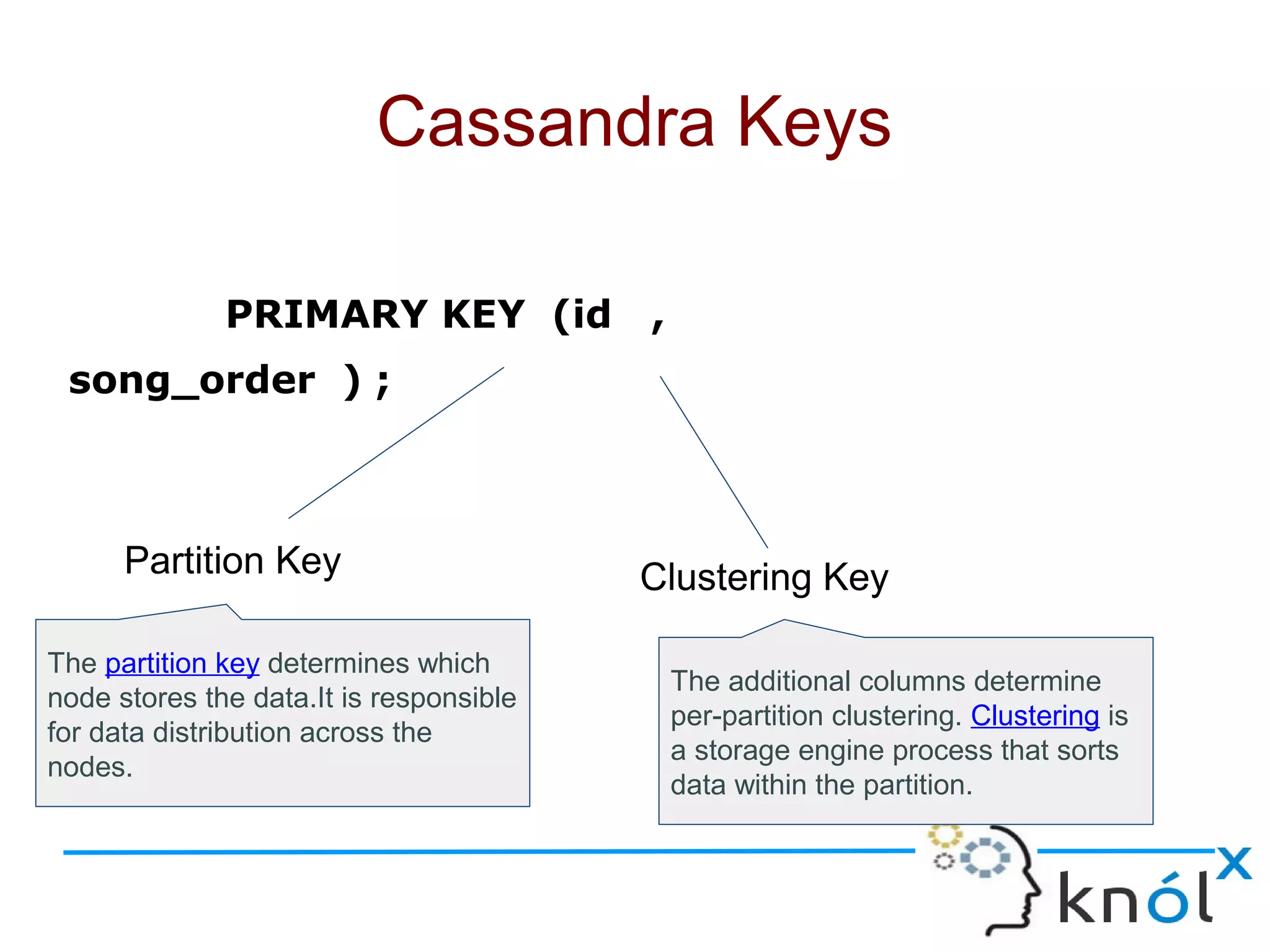

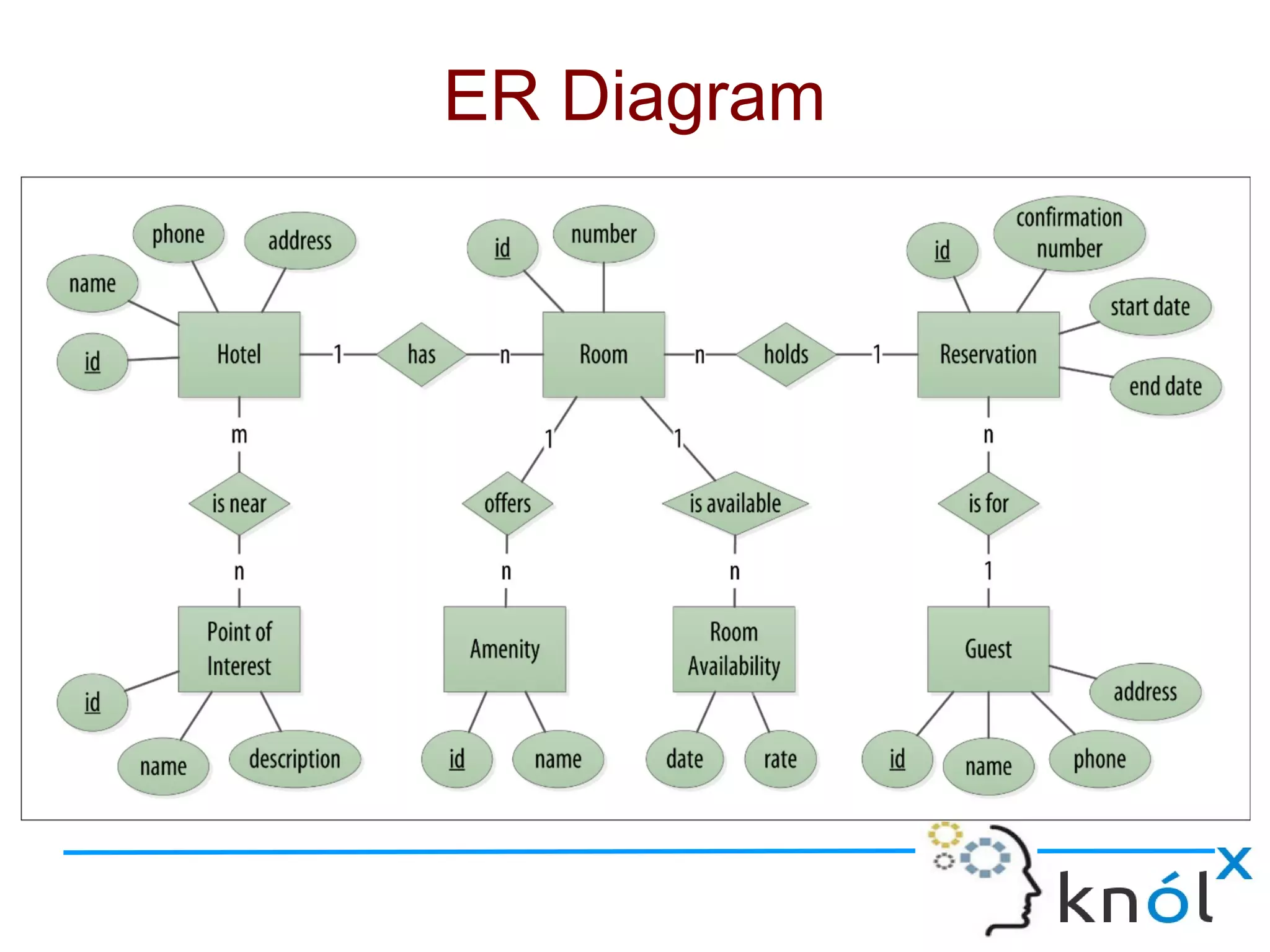
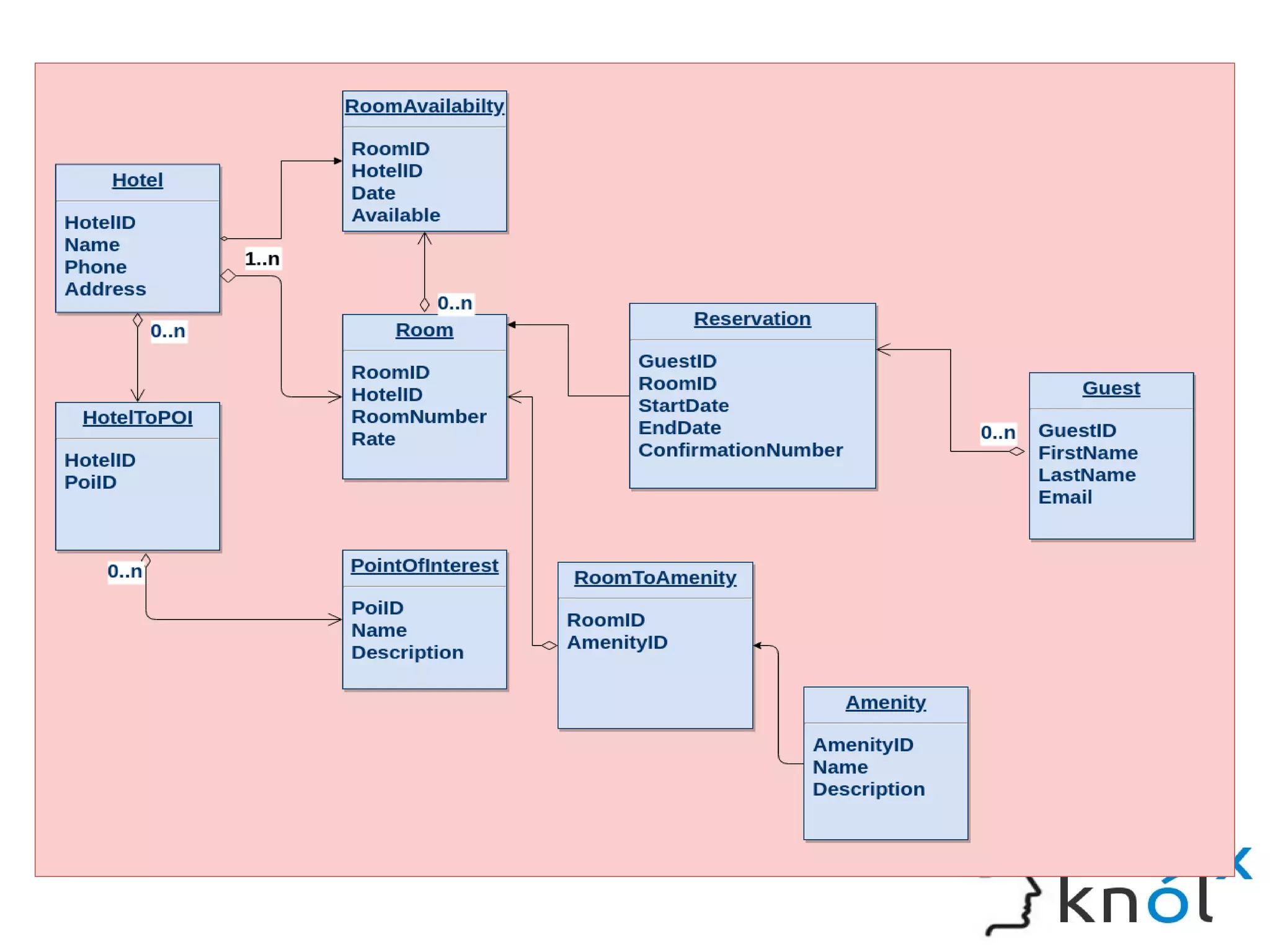









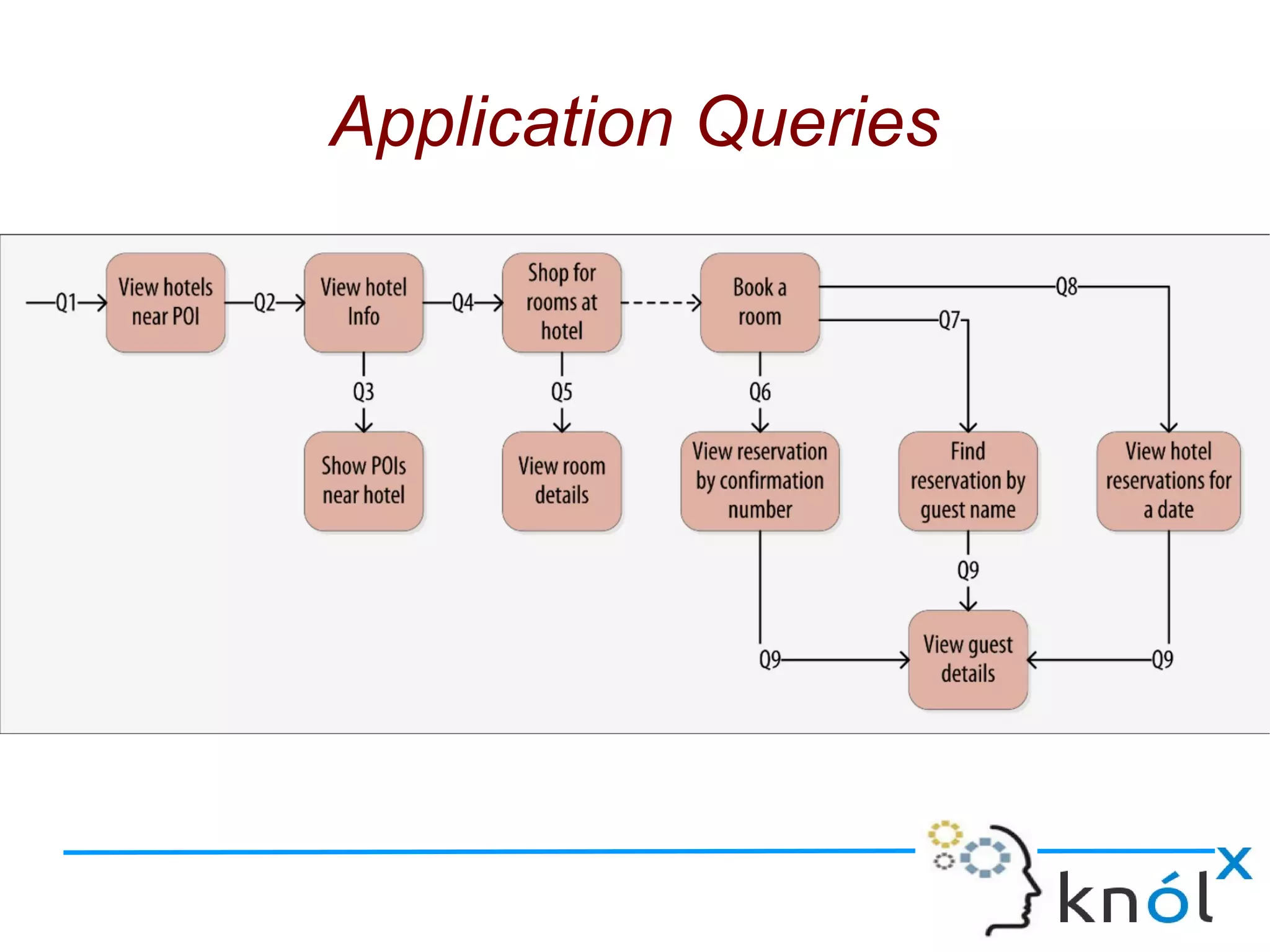


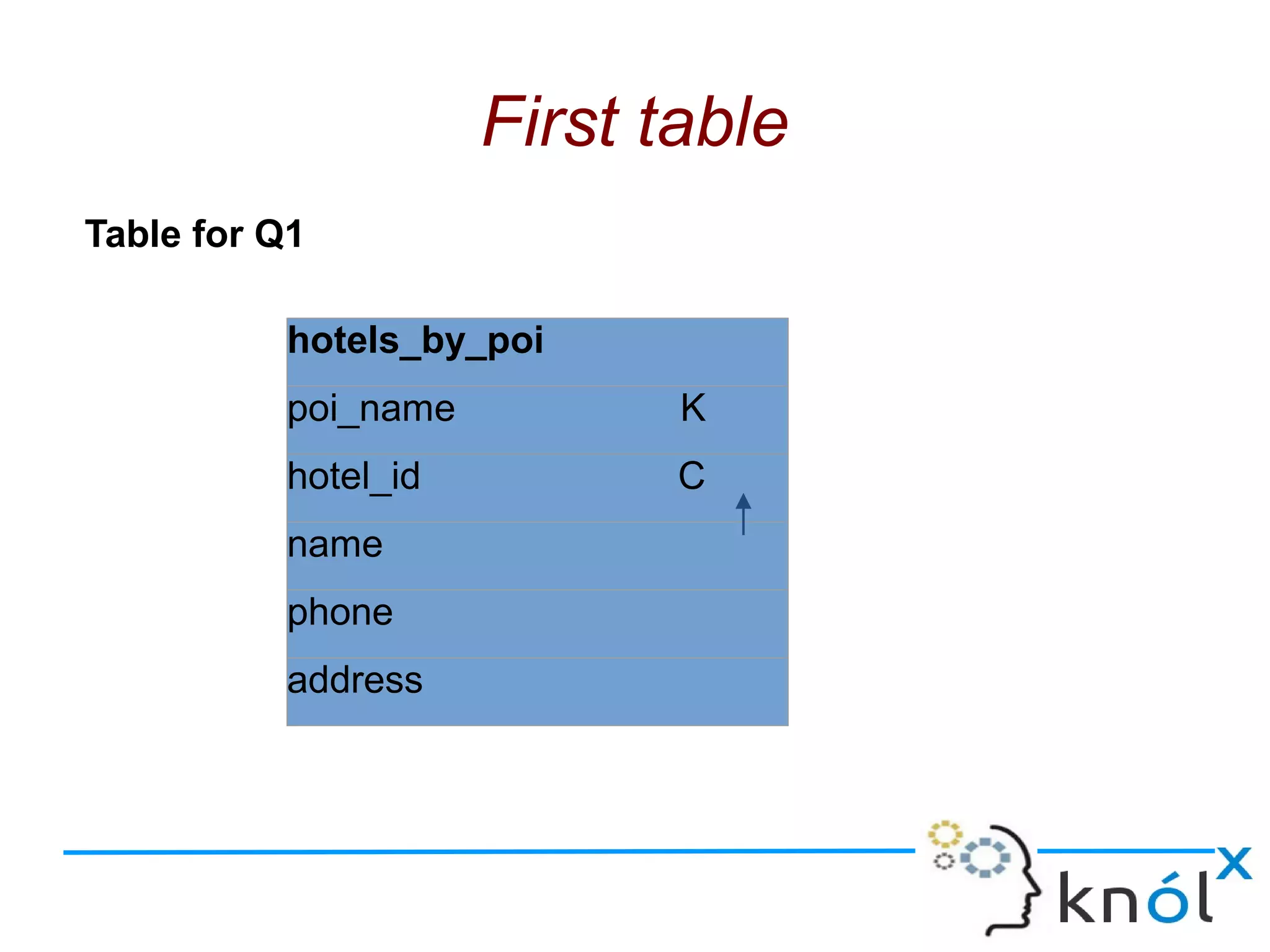
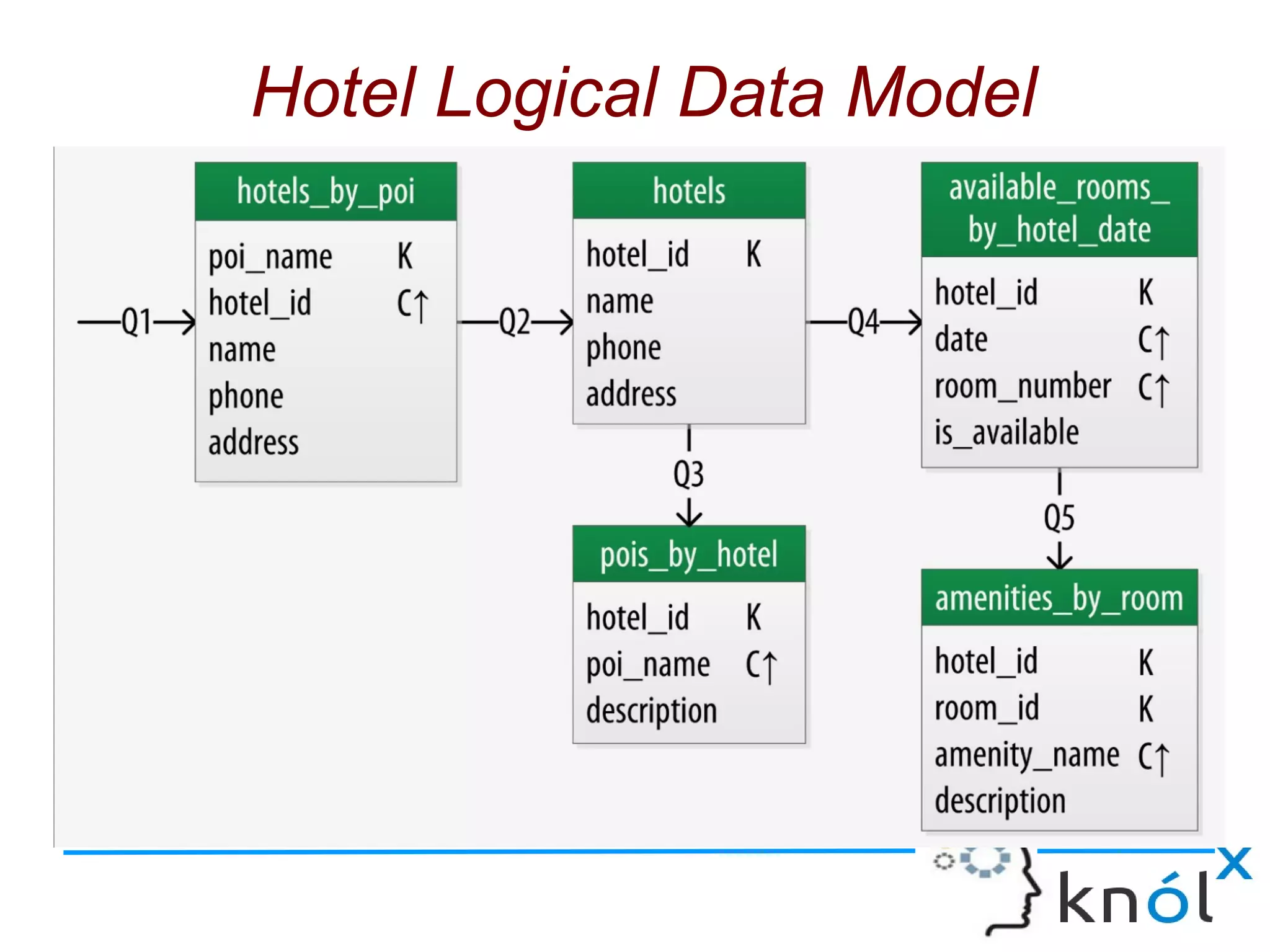
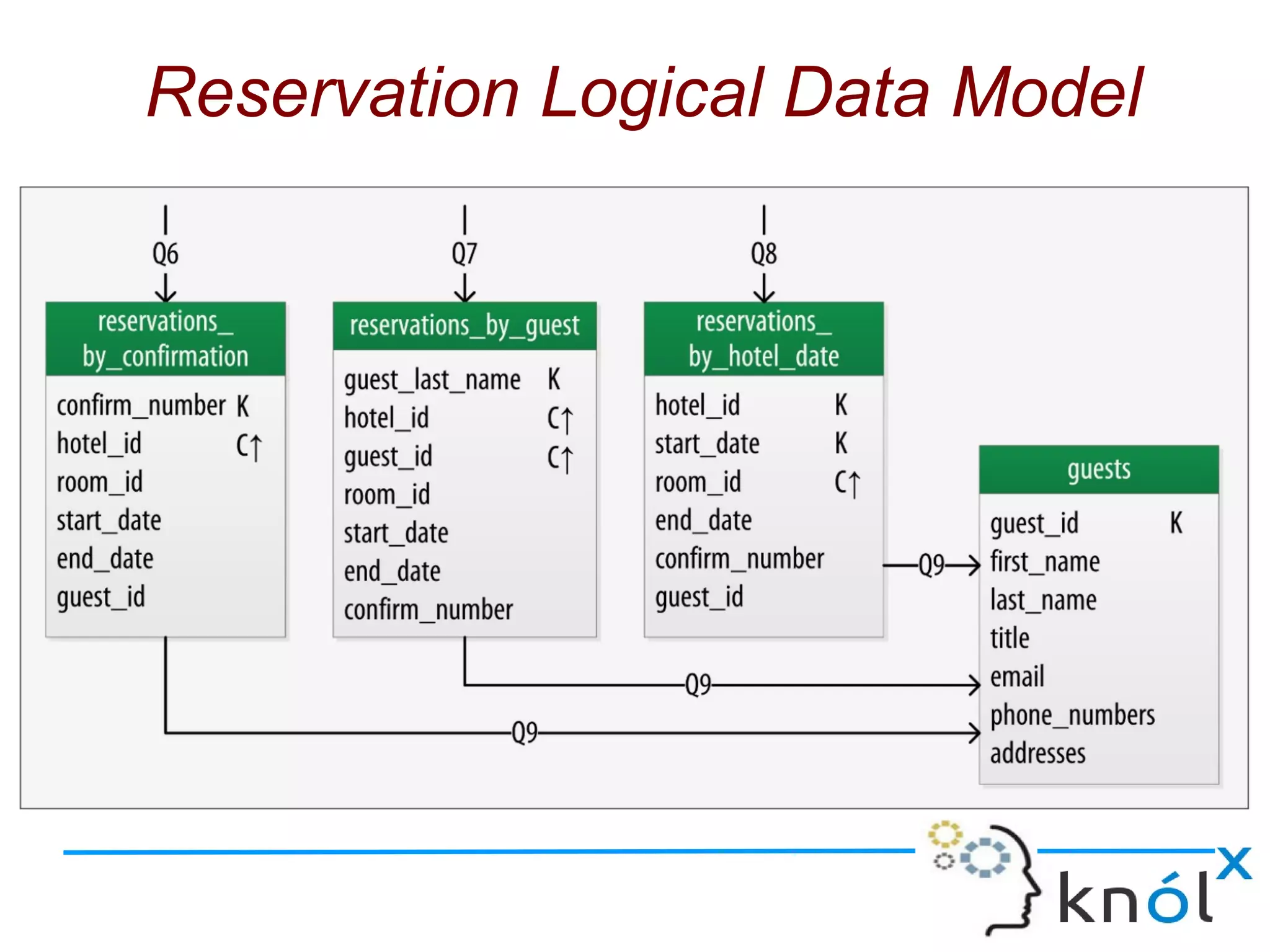
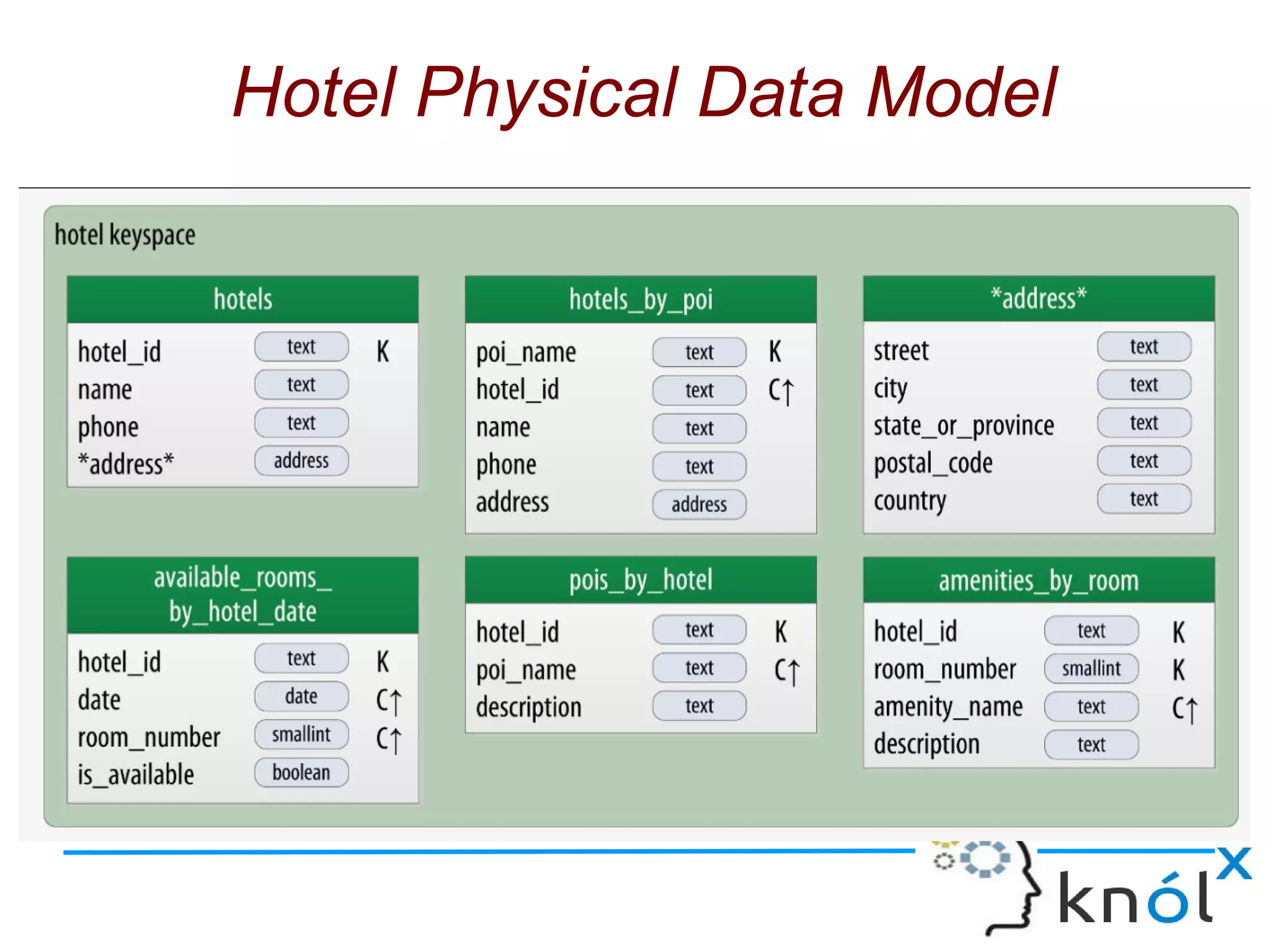
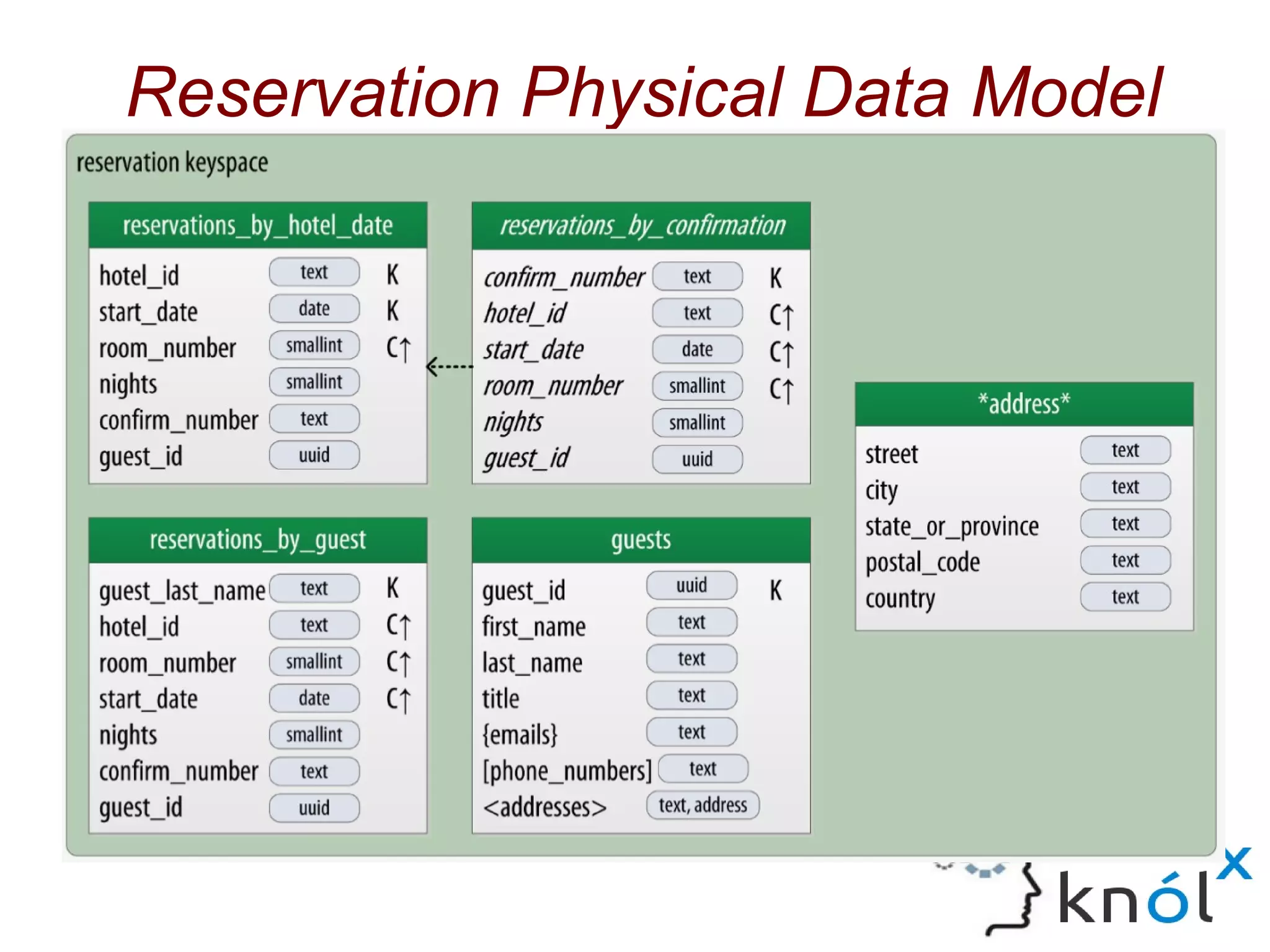





The document discusses Cassandra data modeling, highlighting its differences from relational databases, including a focus on scalability and denormalization. Key concepts such as primary keys, clustering keys, query-first design, and materialized views are covered, illustrating how Cassandra optimizes data storage and retrieval. Practical examples demonstrate how to create table structures and design queries suitable for specific application needs.























































































