





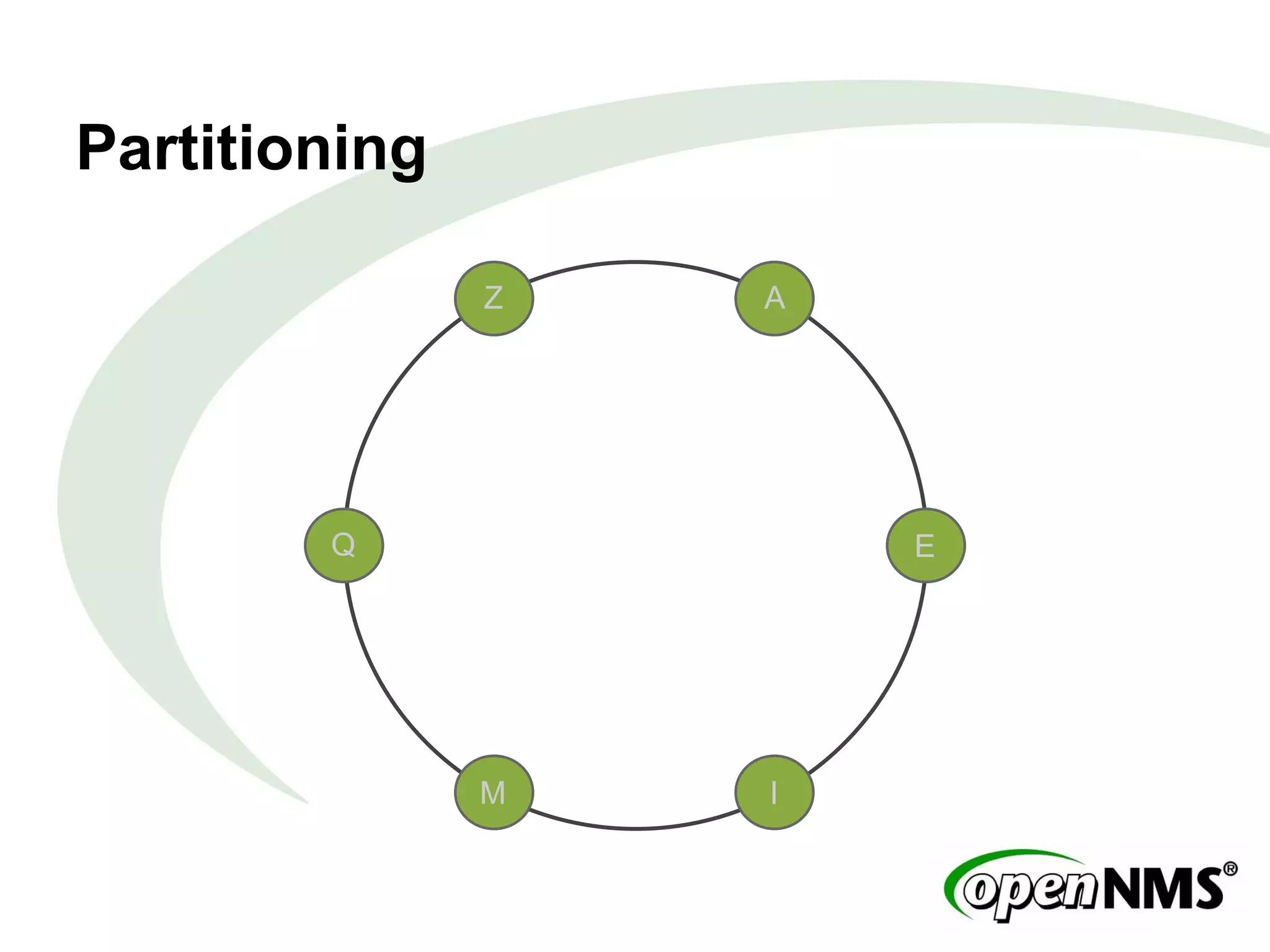
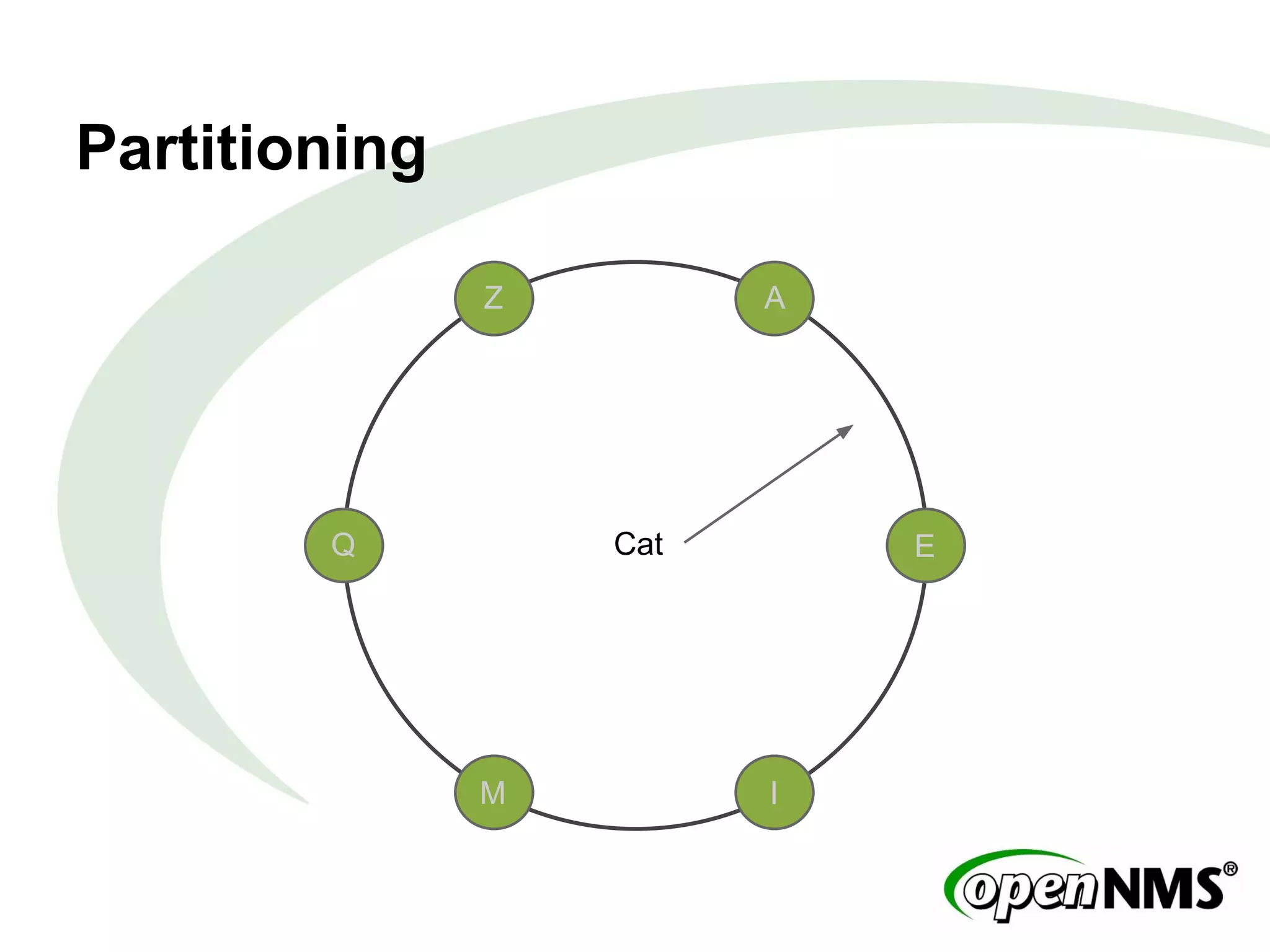
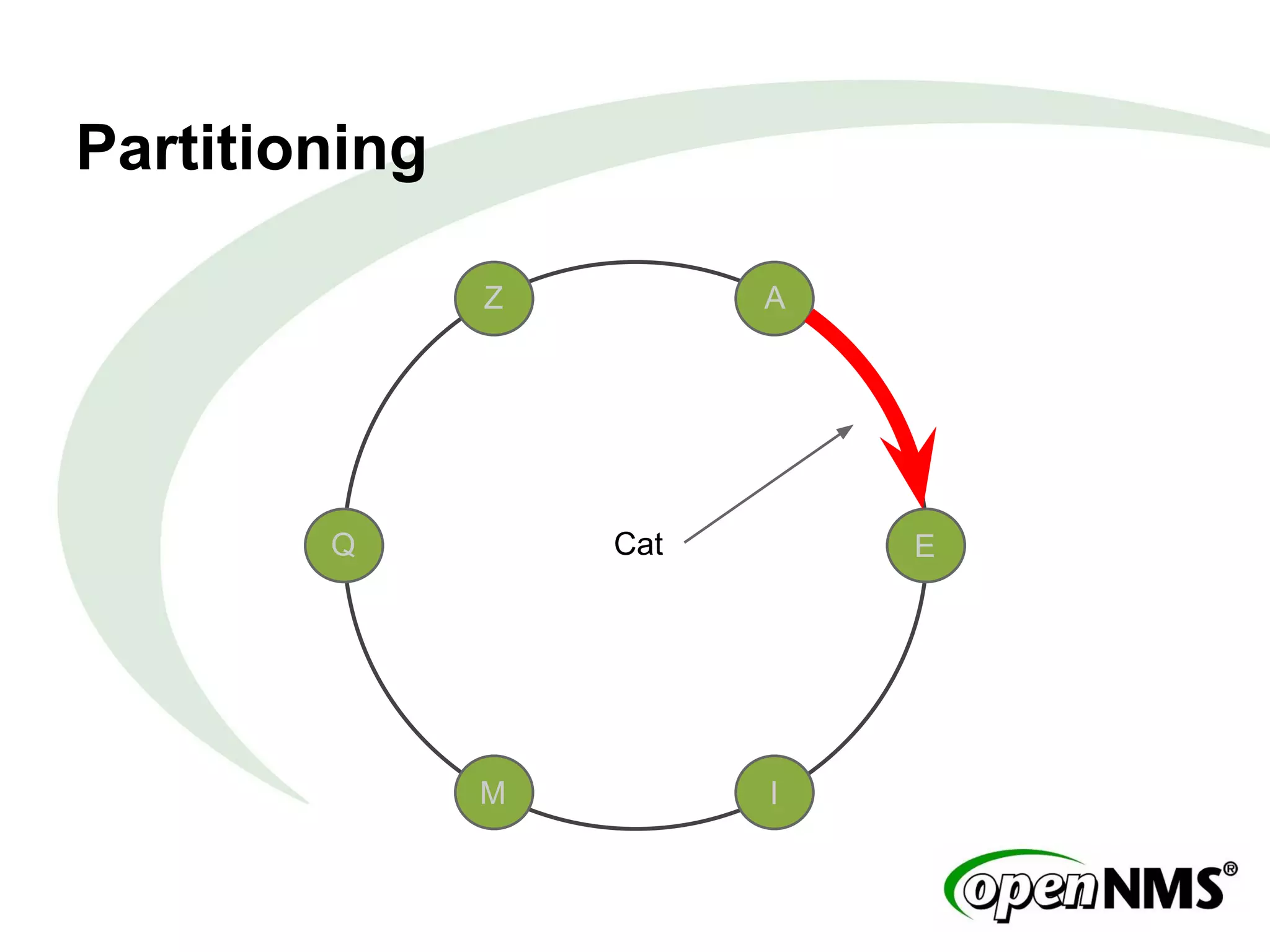
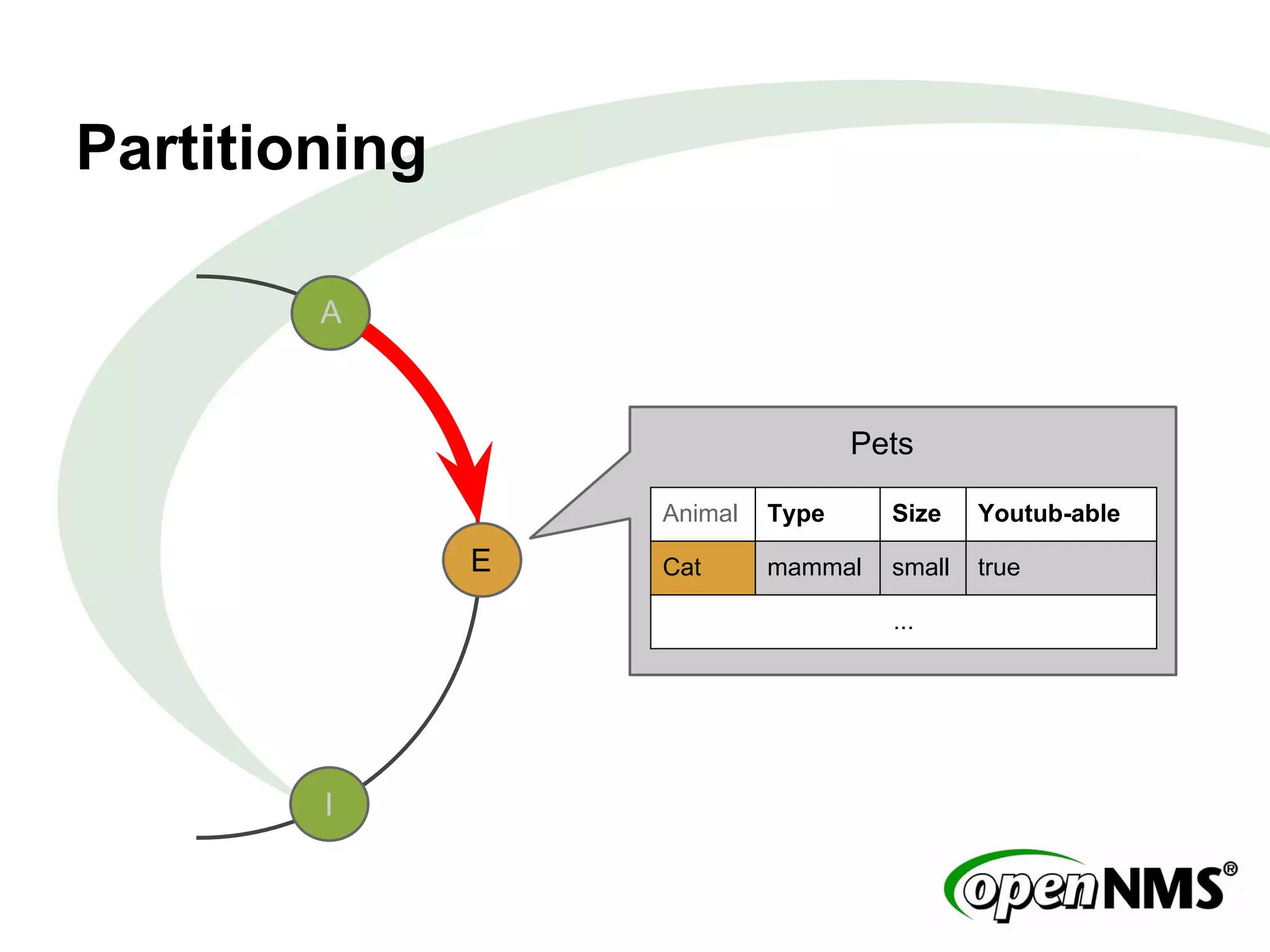


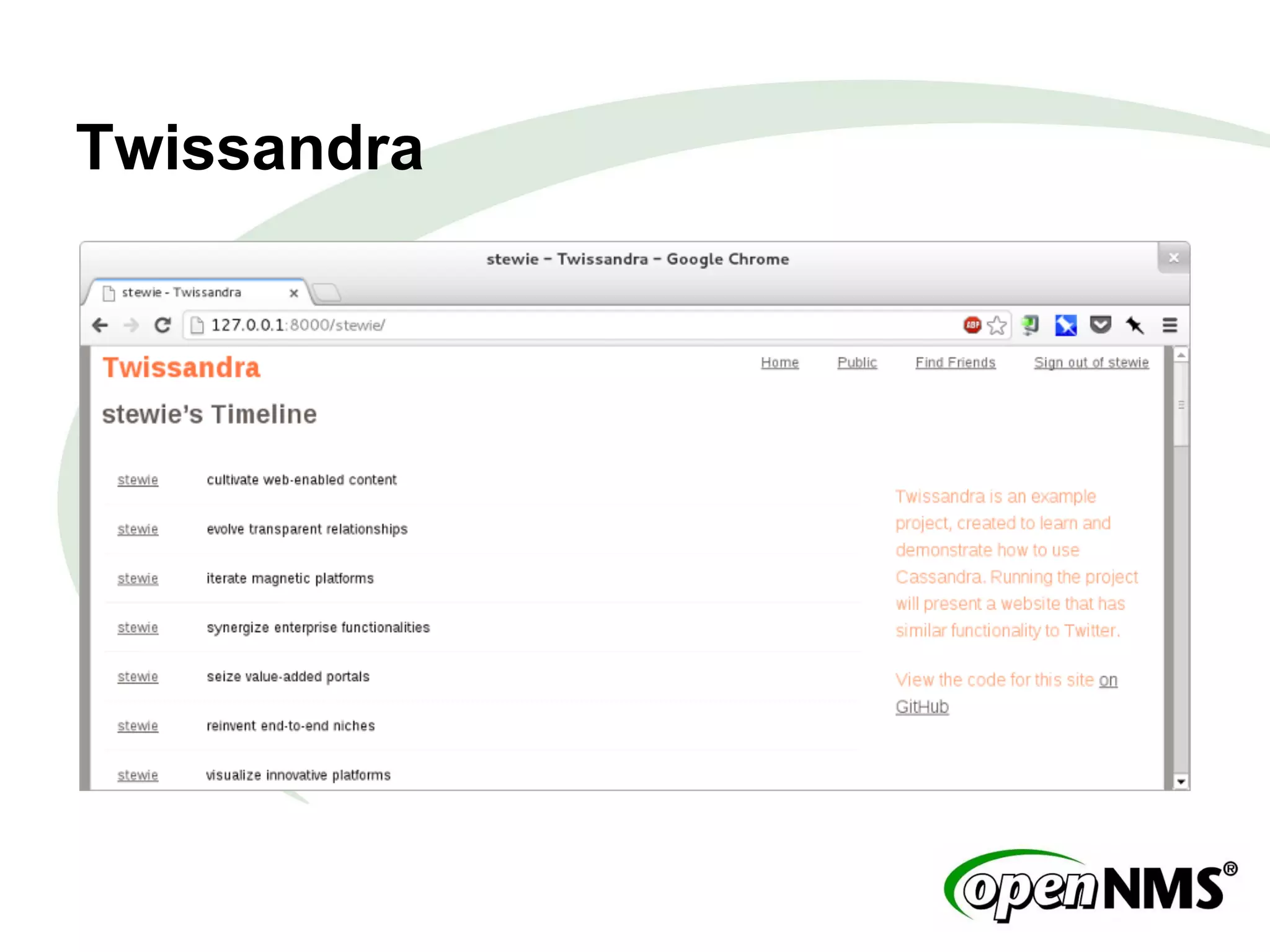




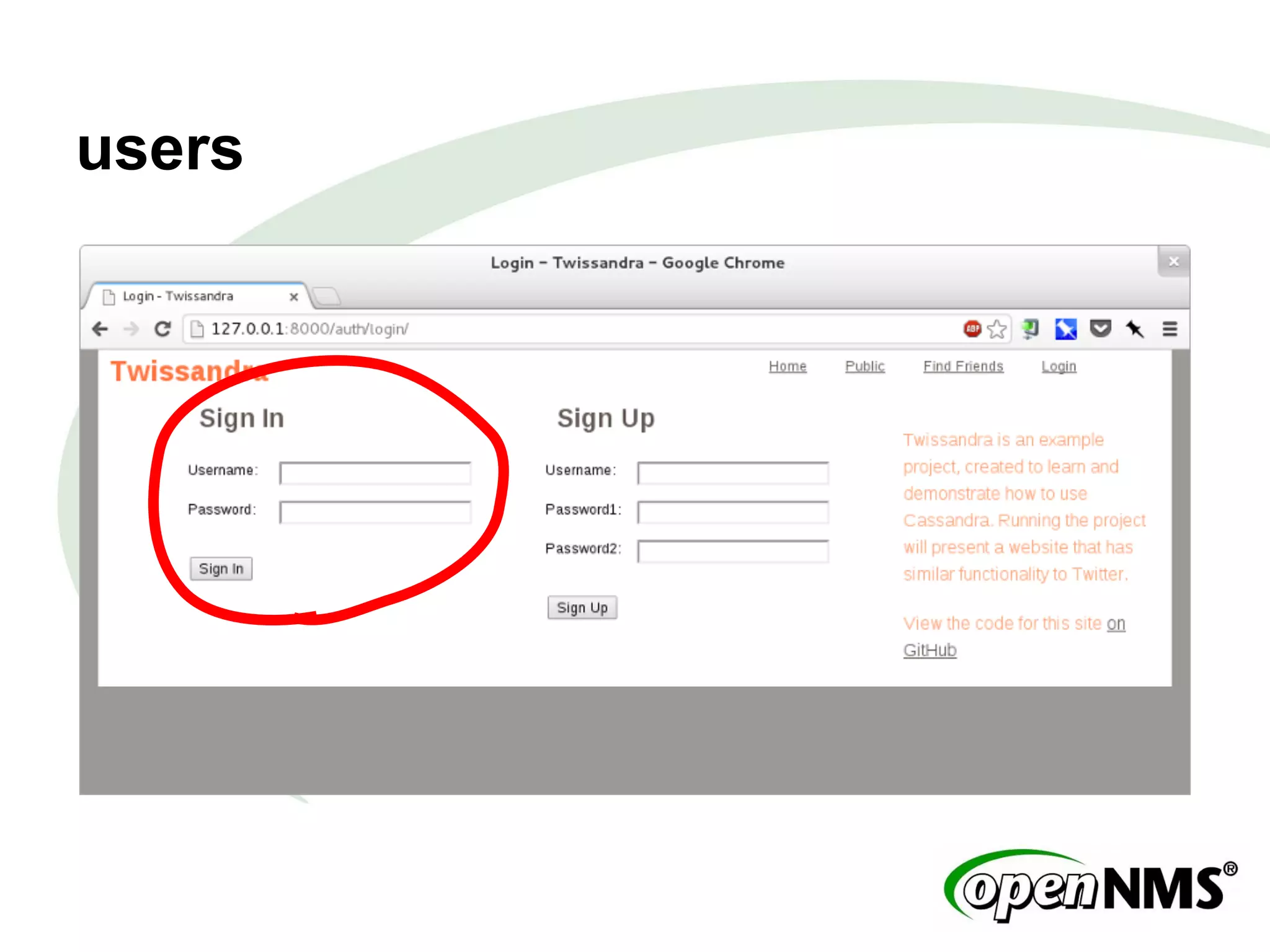

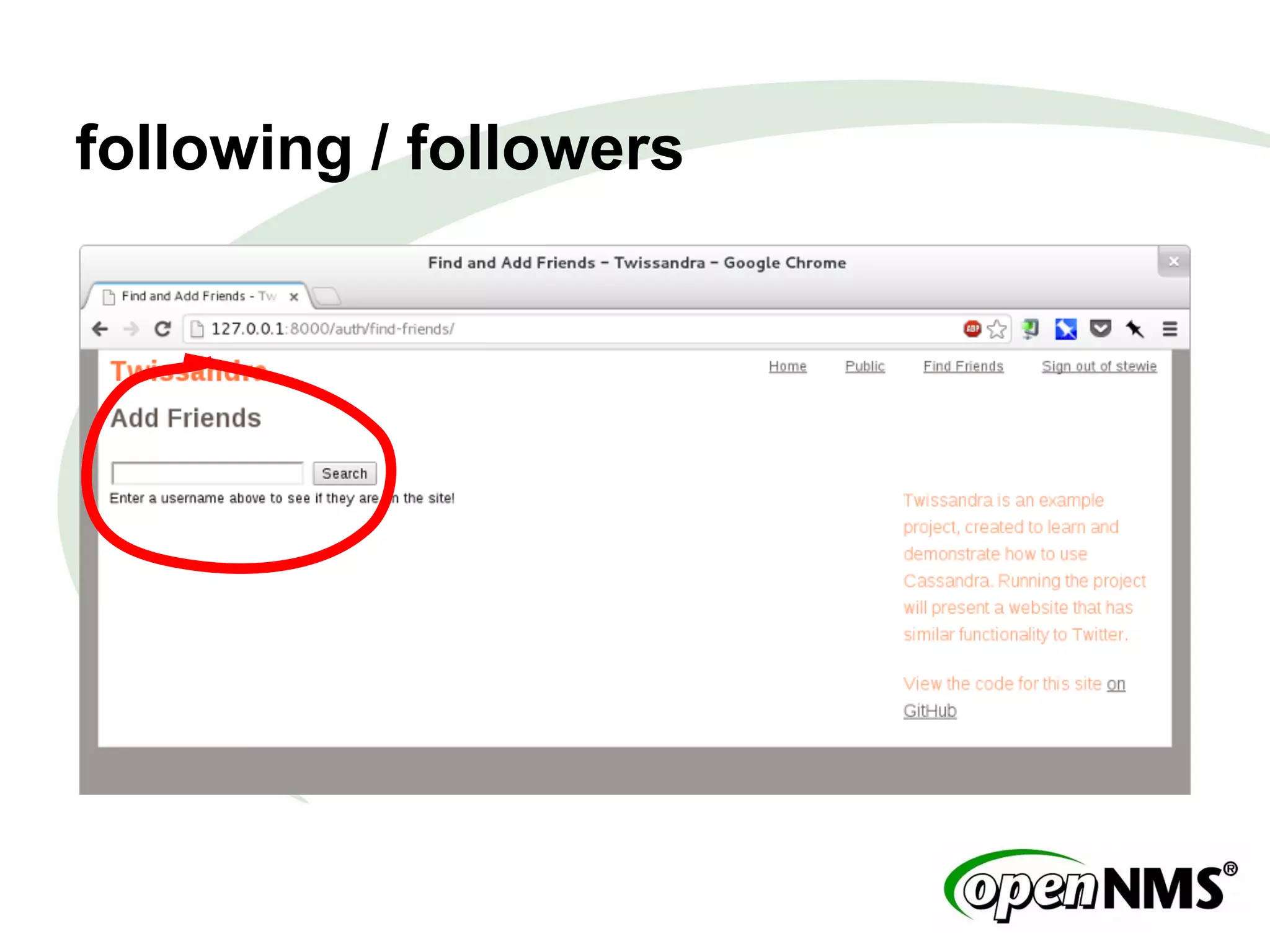


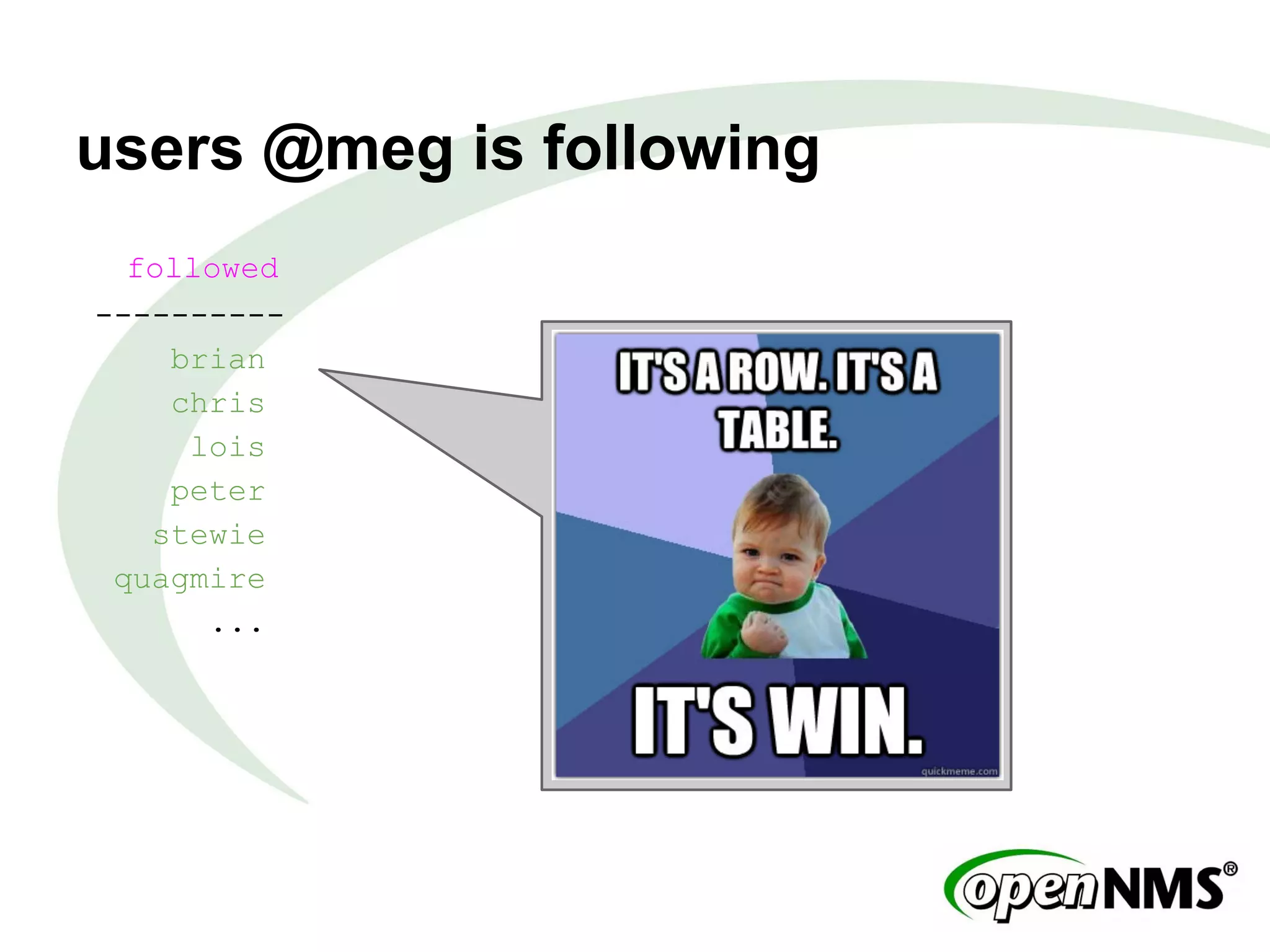




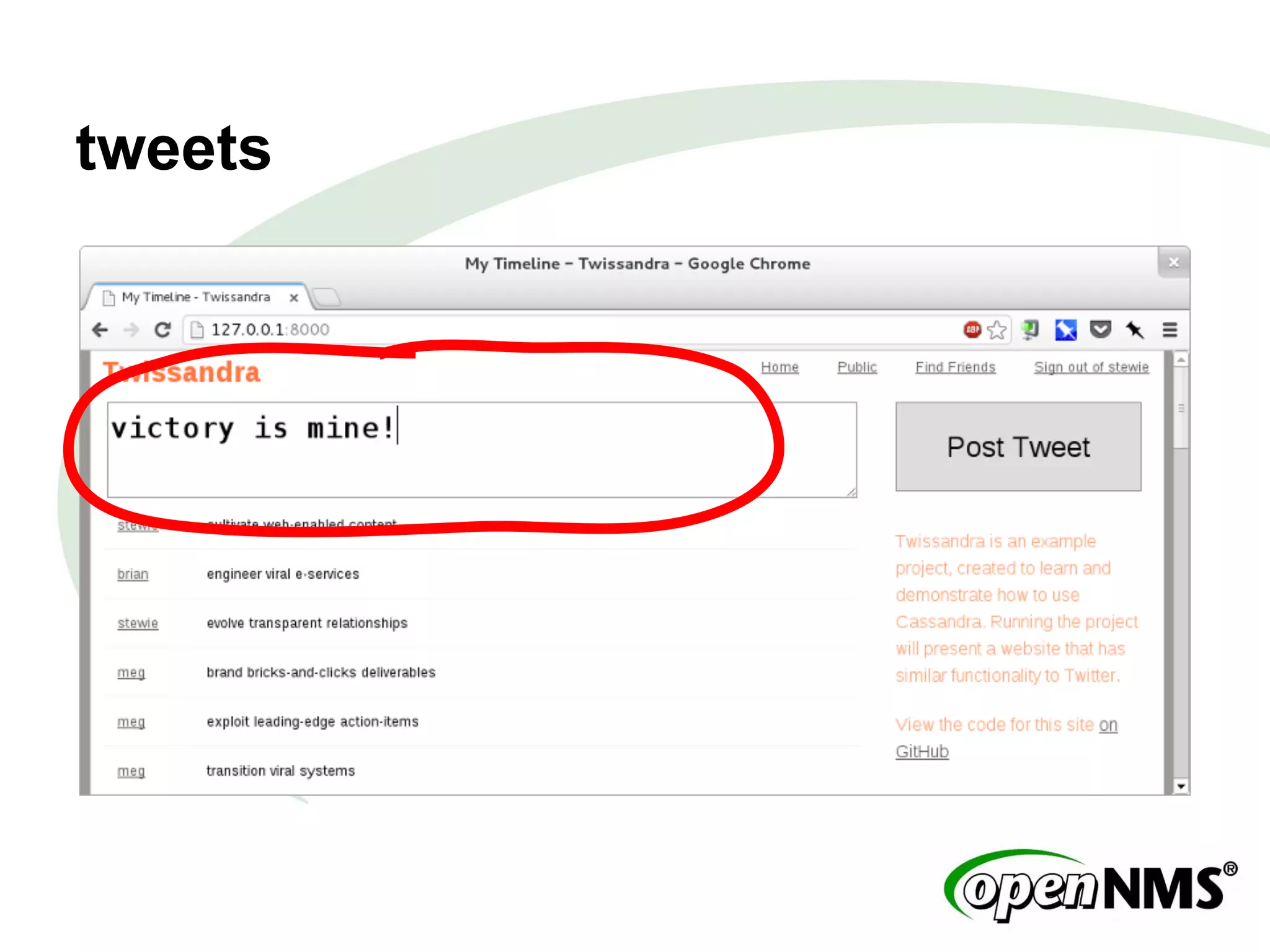




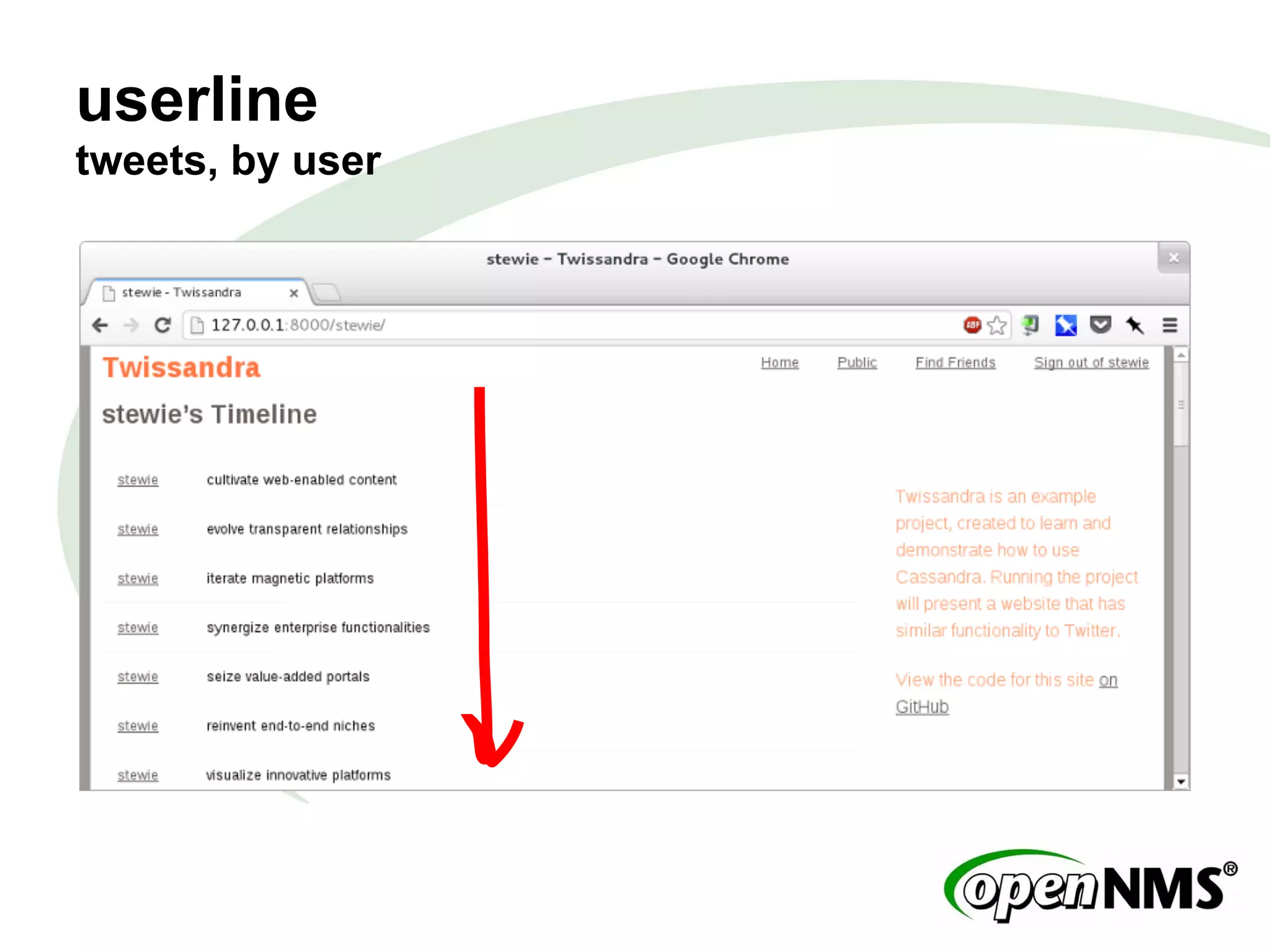




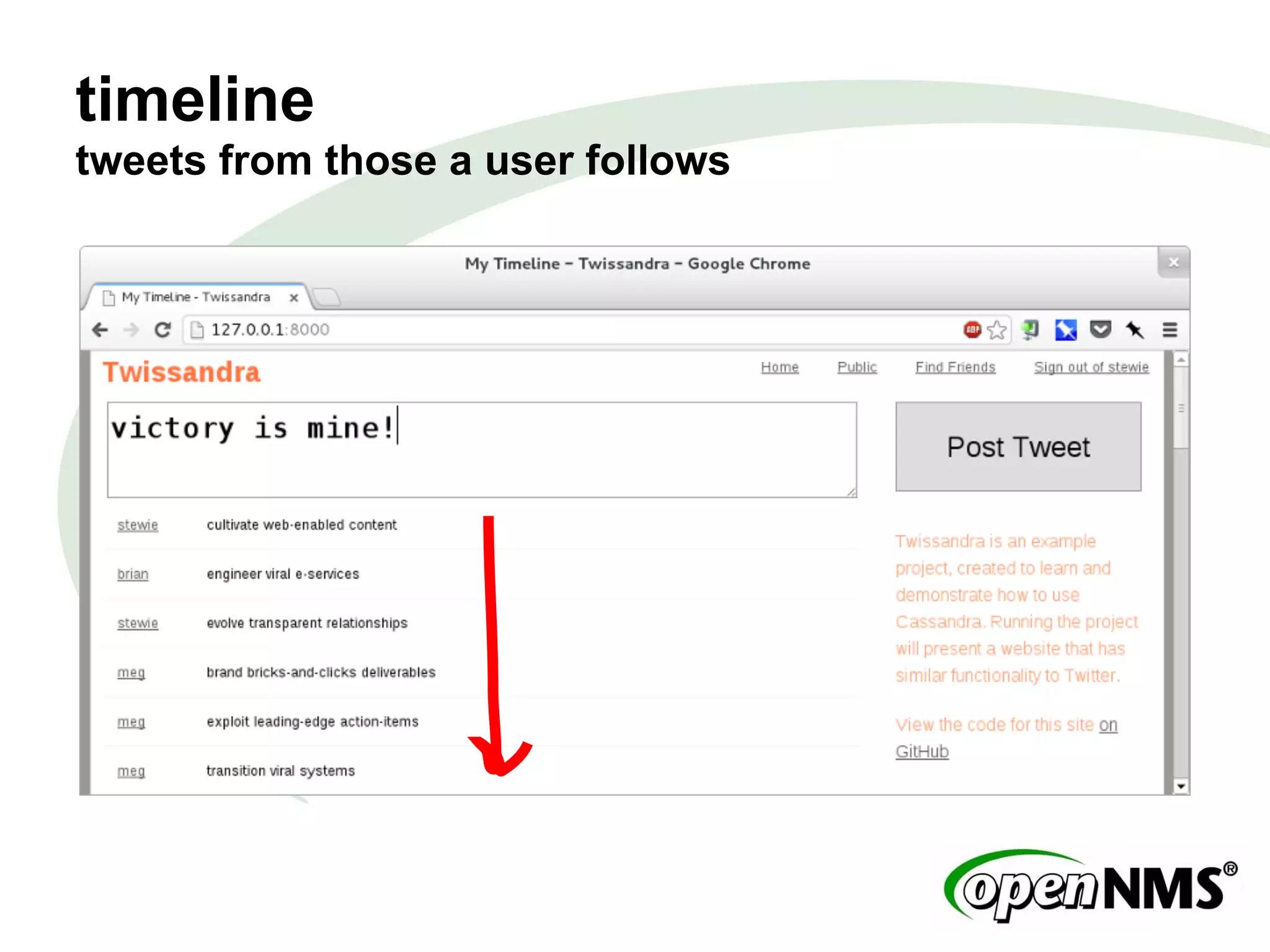







This document summarizes a presentation about modeling data with Cassandra Query Language (CQL) using examples from a Twitter-like application called Twissandra. It introduces CQL as an alternative to Thrift for querying Cassandra and describes how to model users, followers, tweets, timelines and other social media data structures in Cassandra tables. The presentation emphasizes denormalizing data and using materialized views to optimize queries, and concludes by noting that applications can be built in various languages thanks to Cassandra drivers.























































