Downloaded 32 times











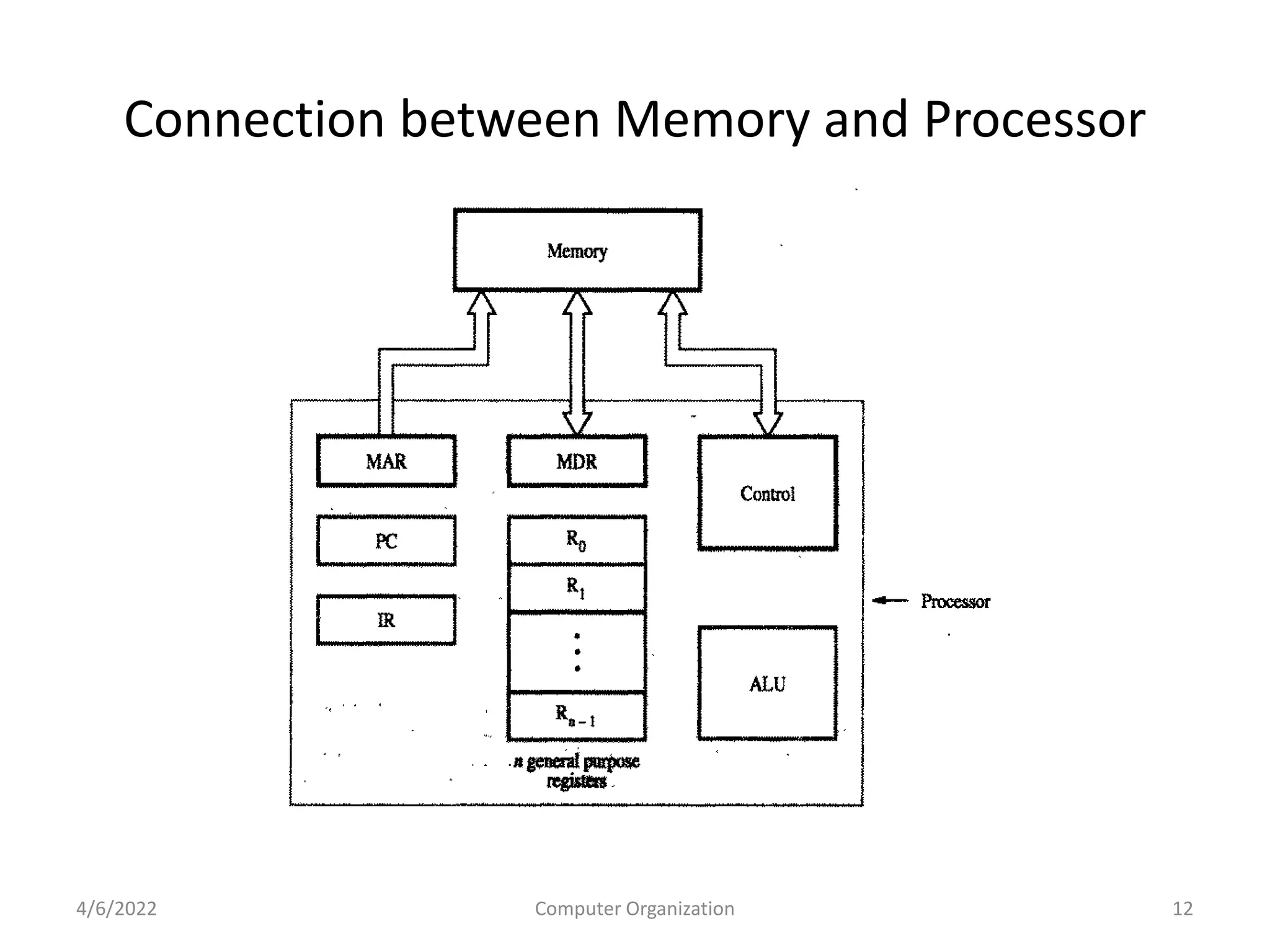


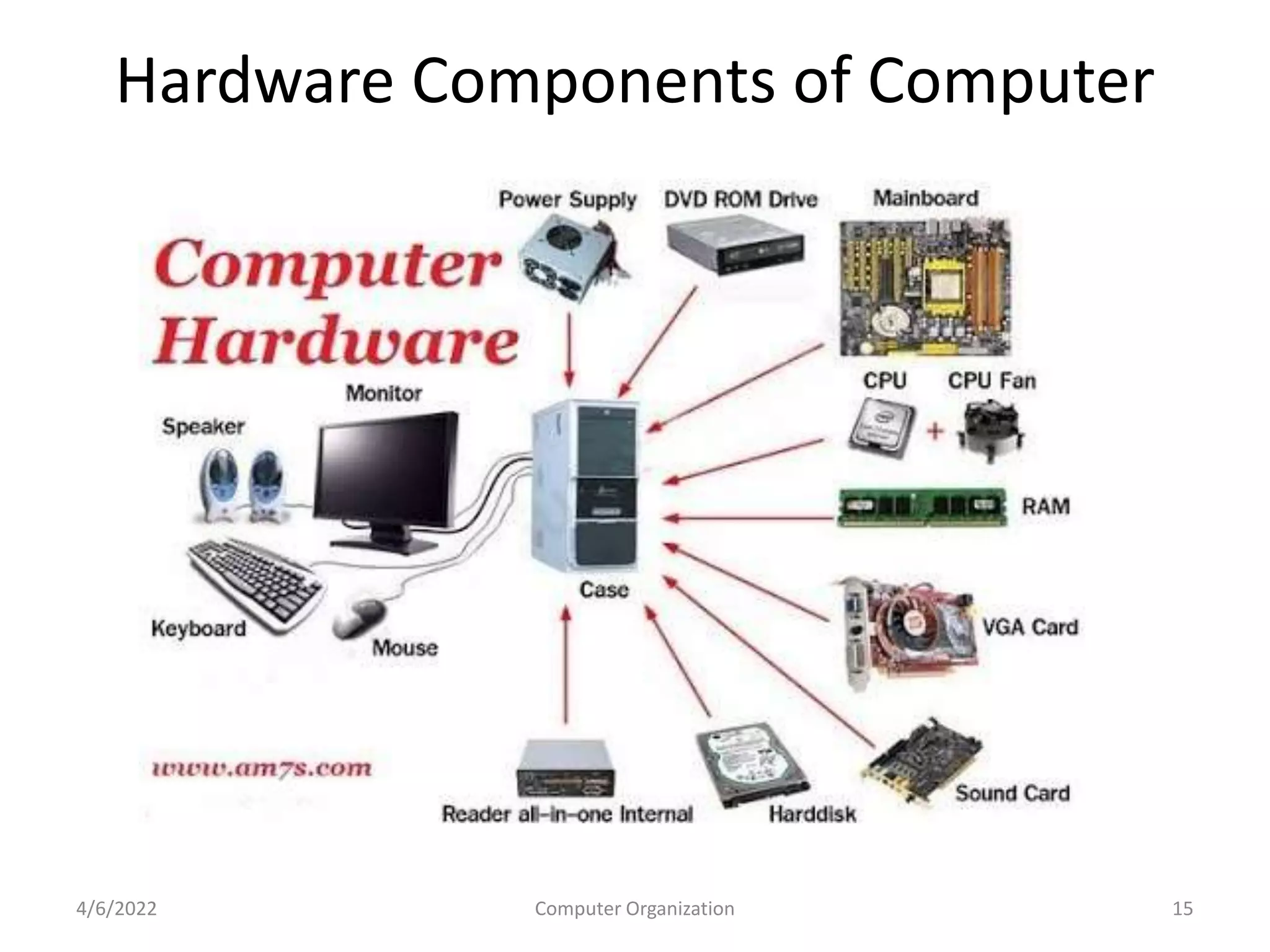
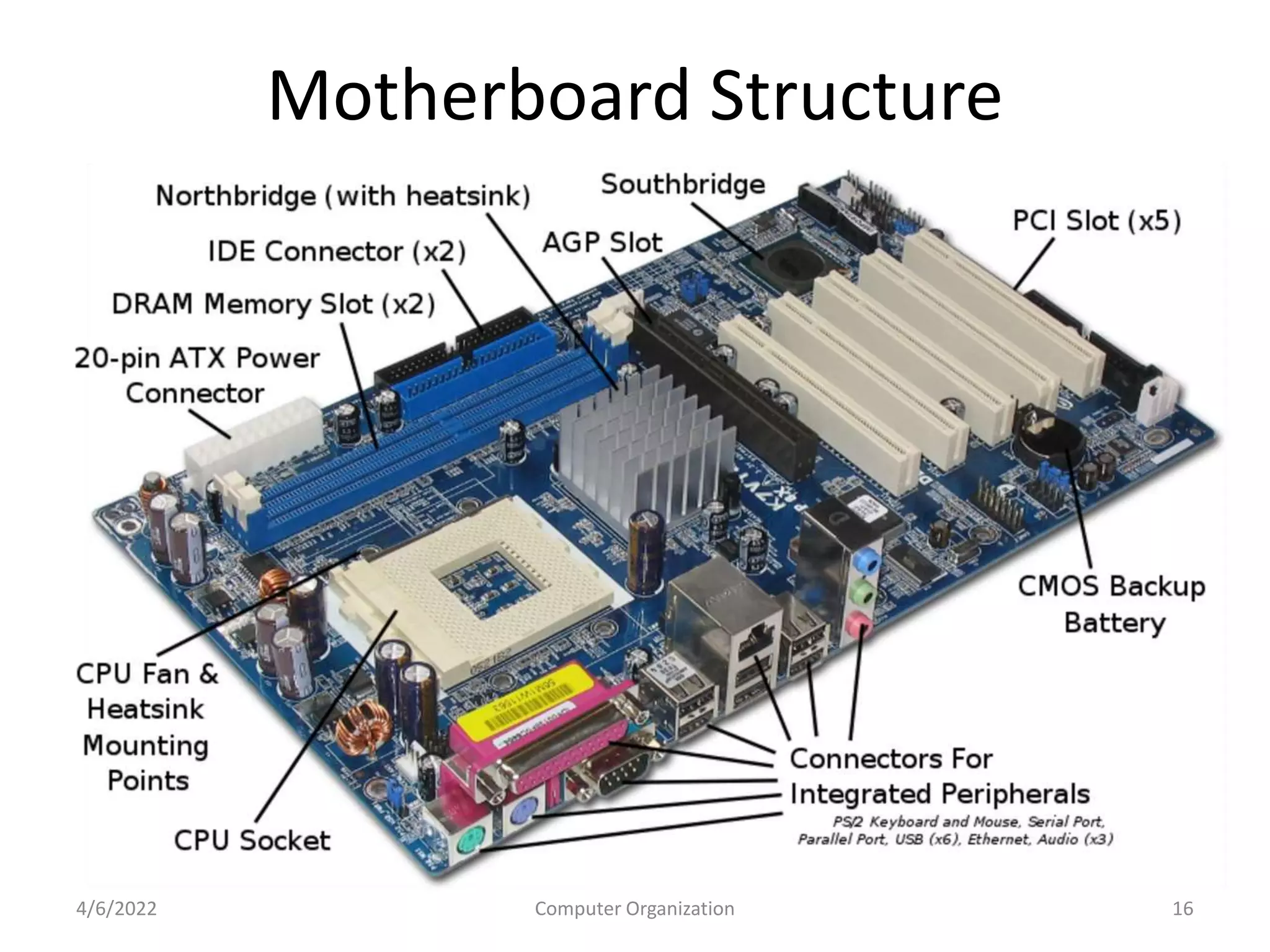






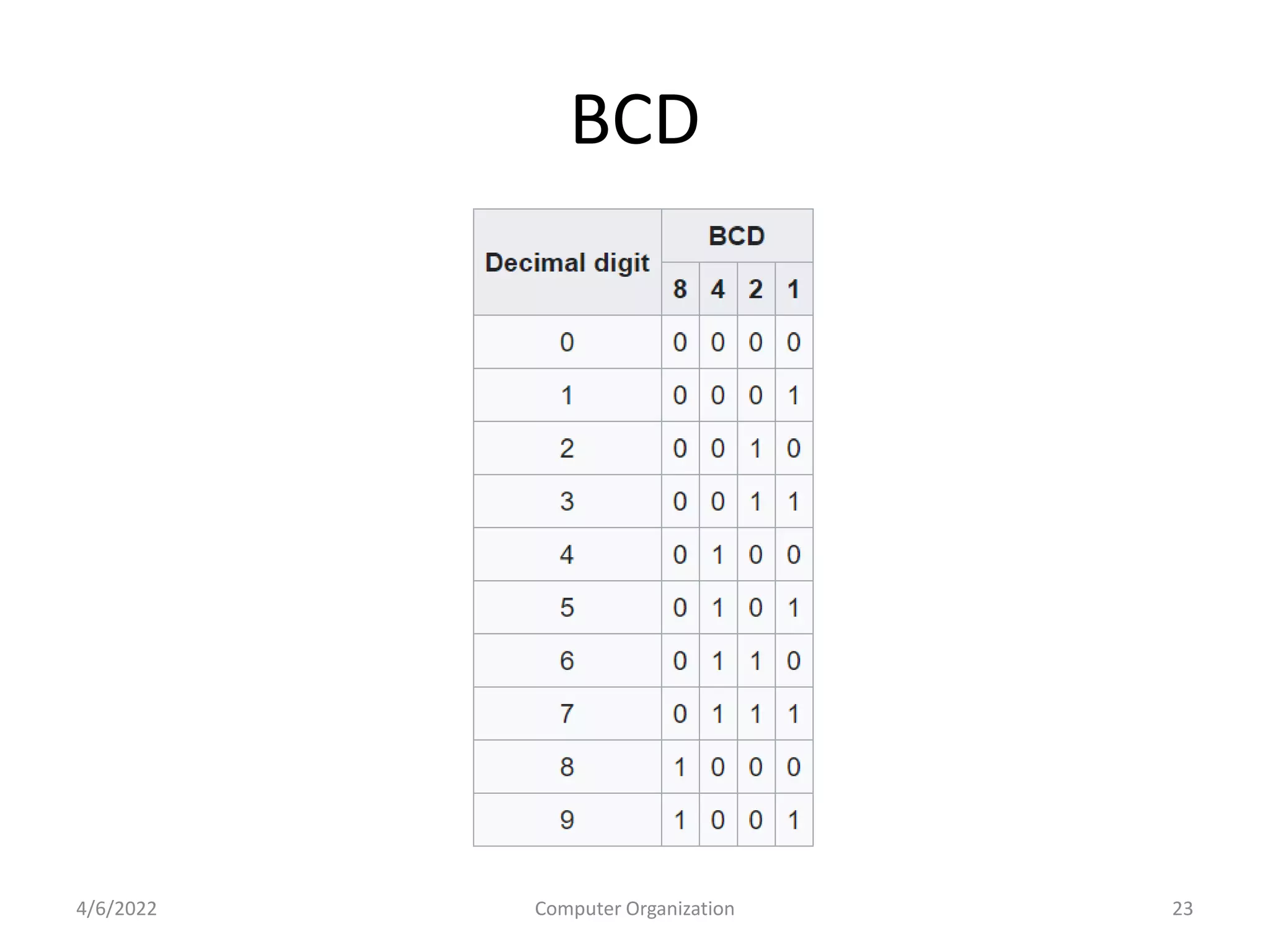
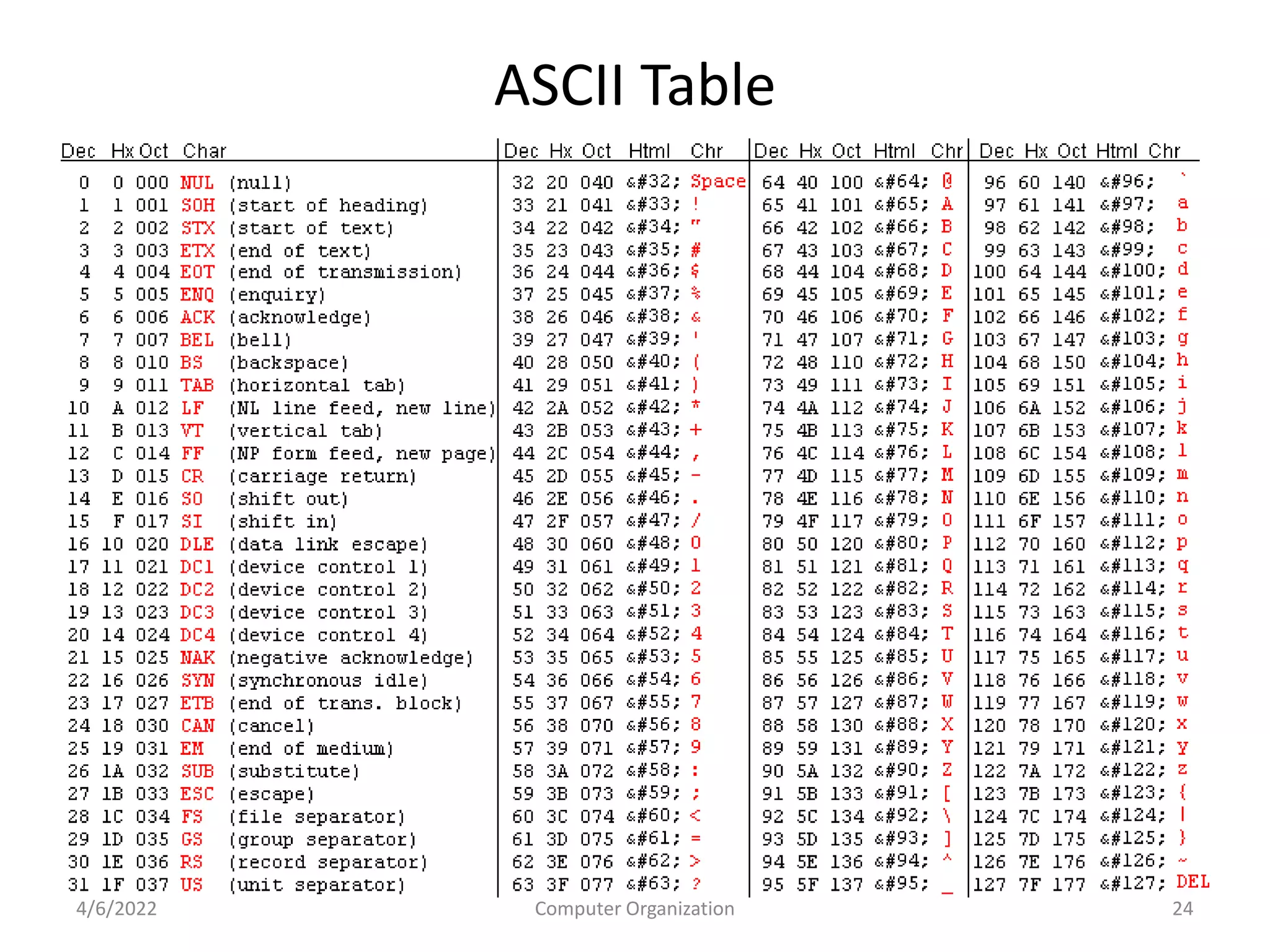

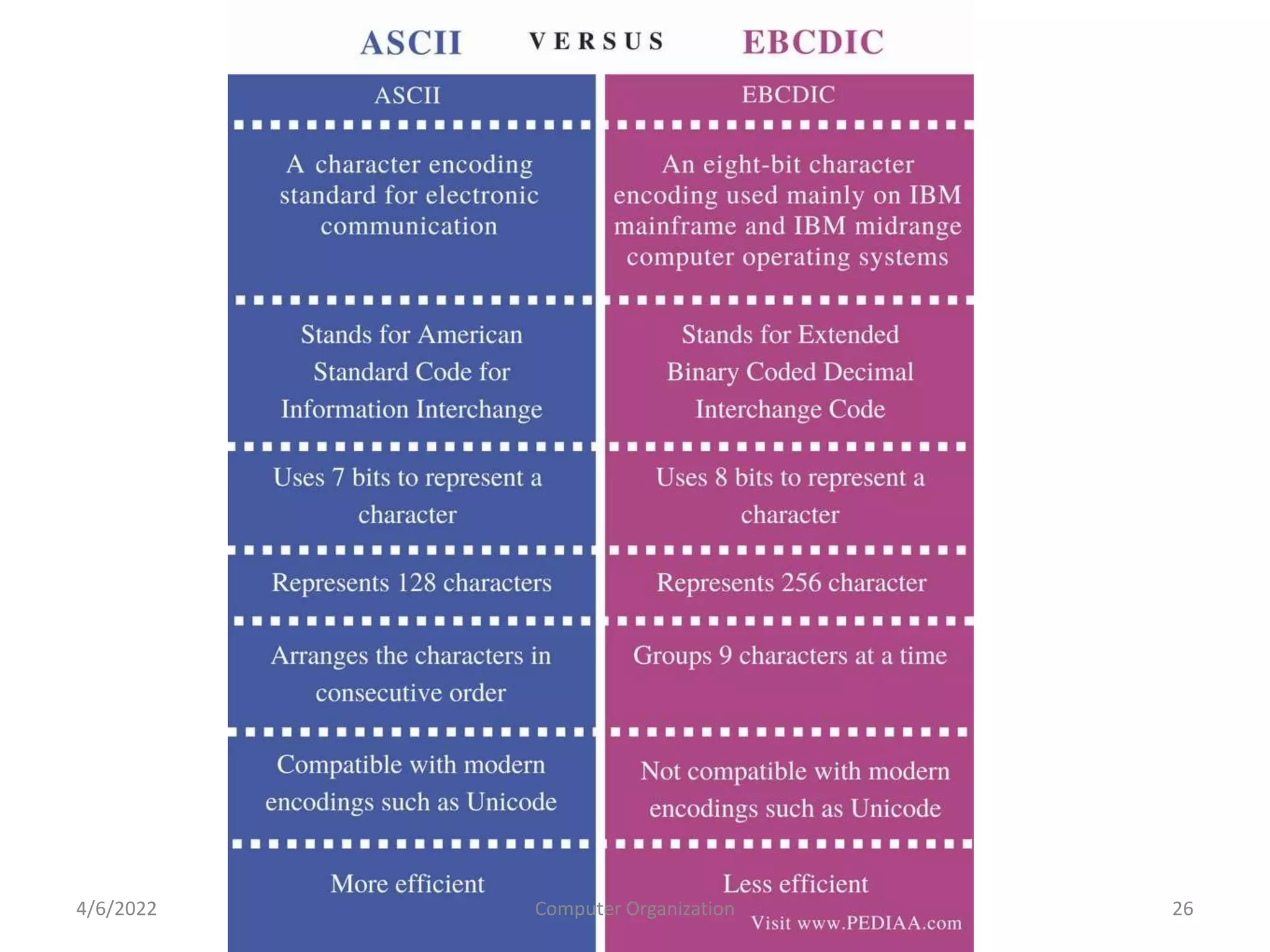

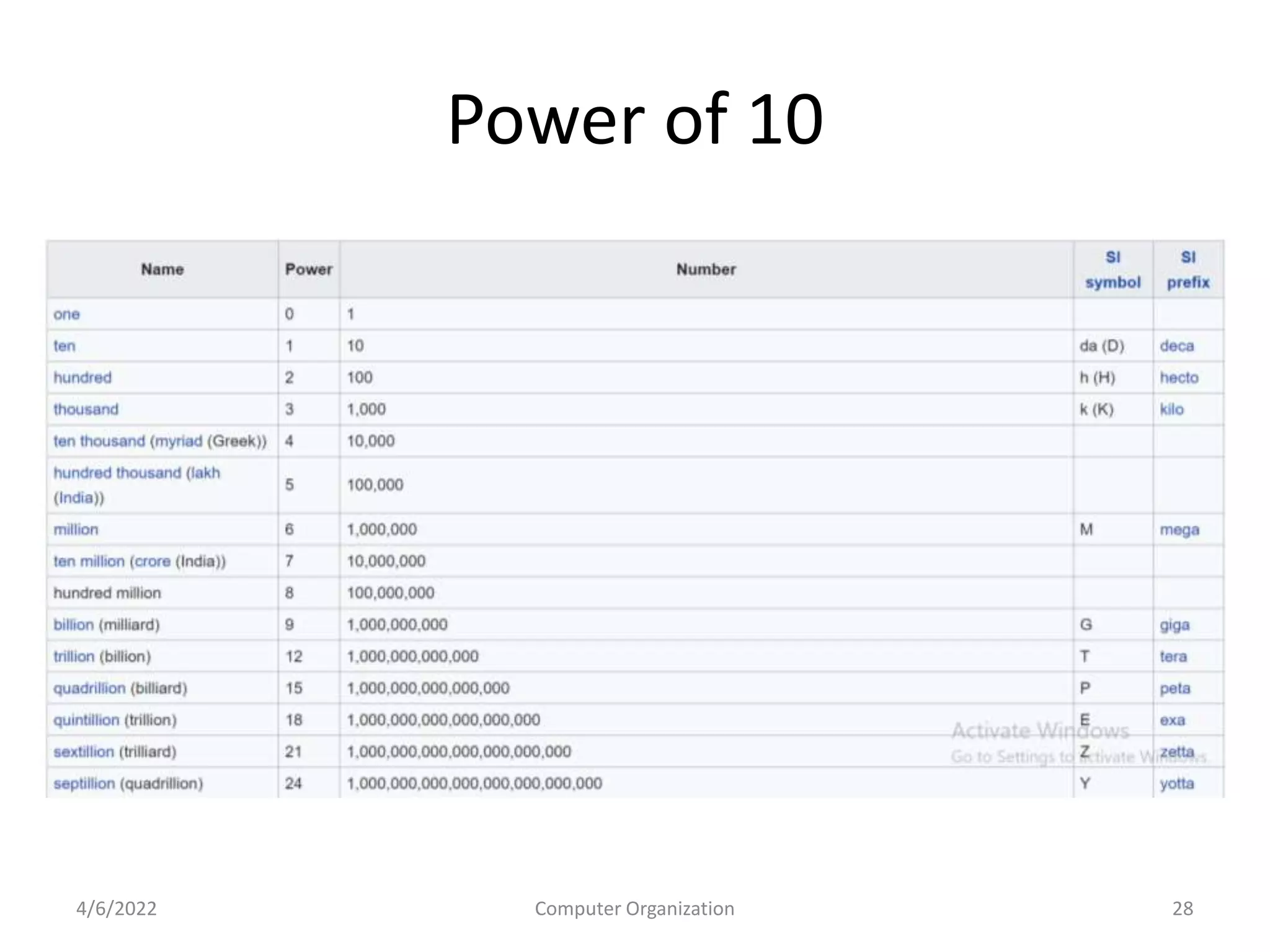

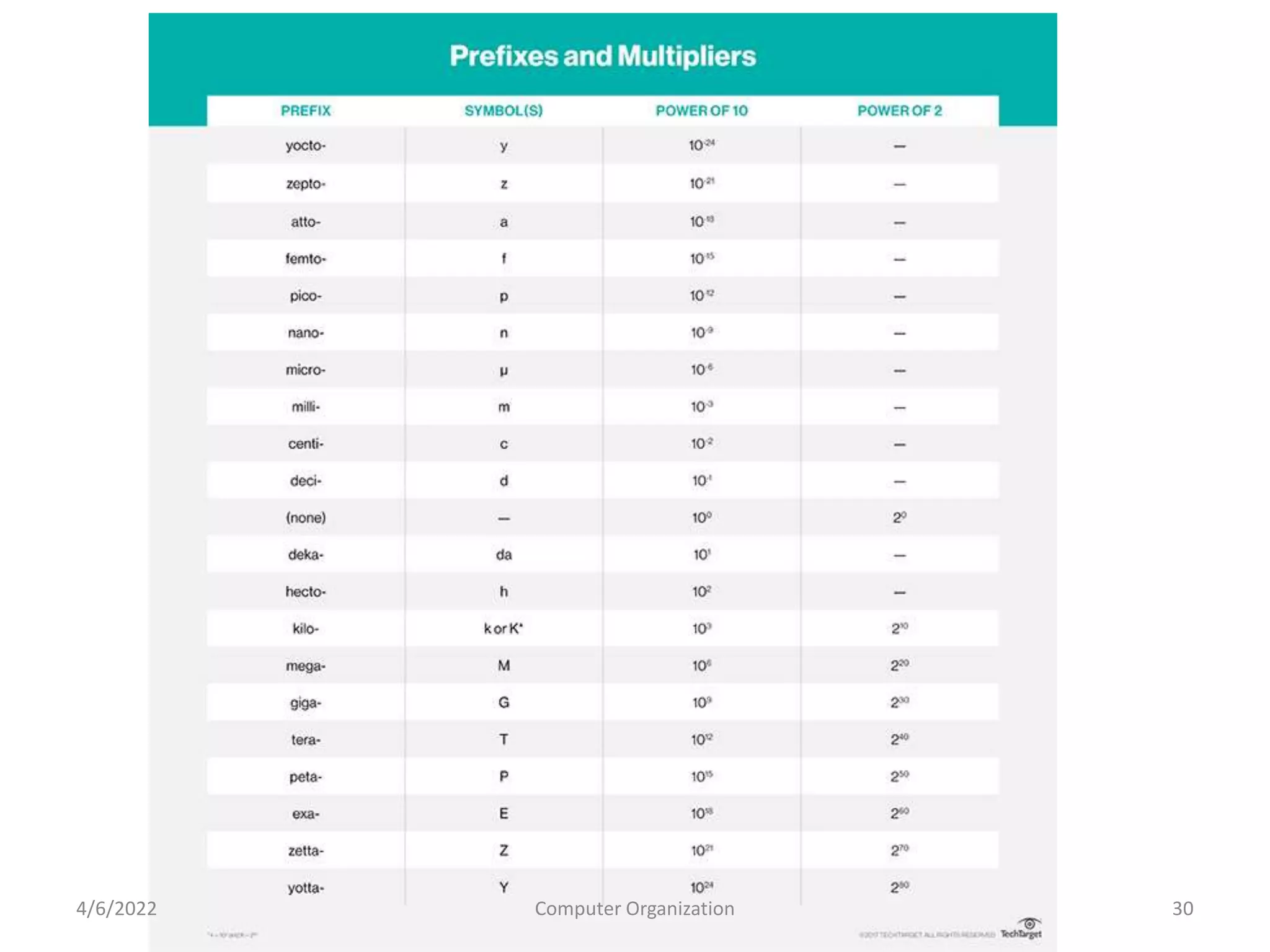







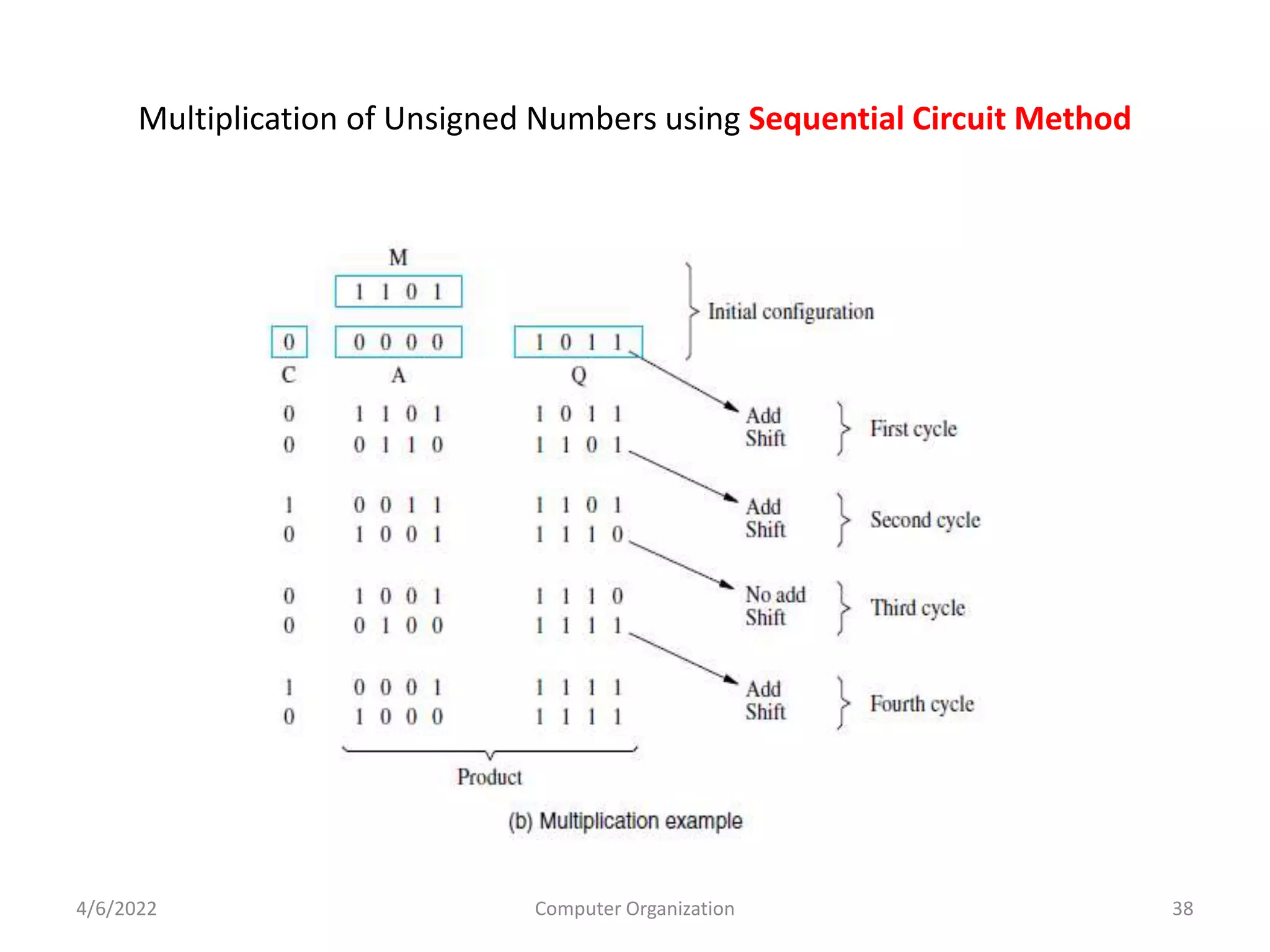









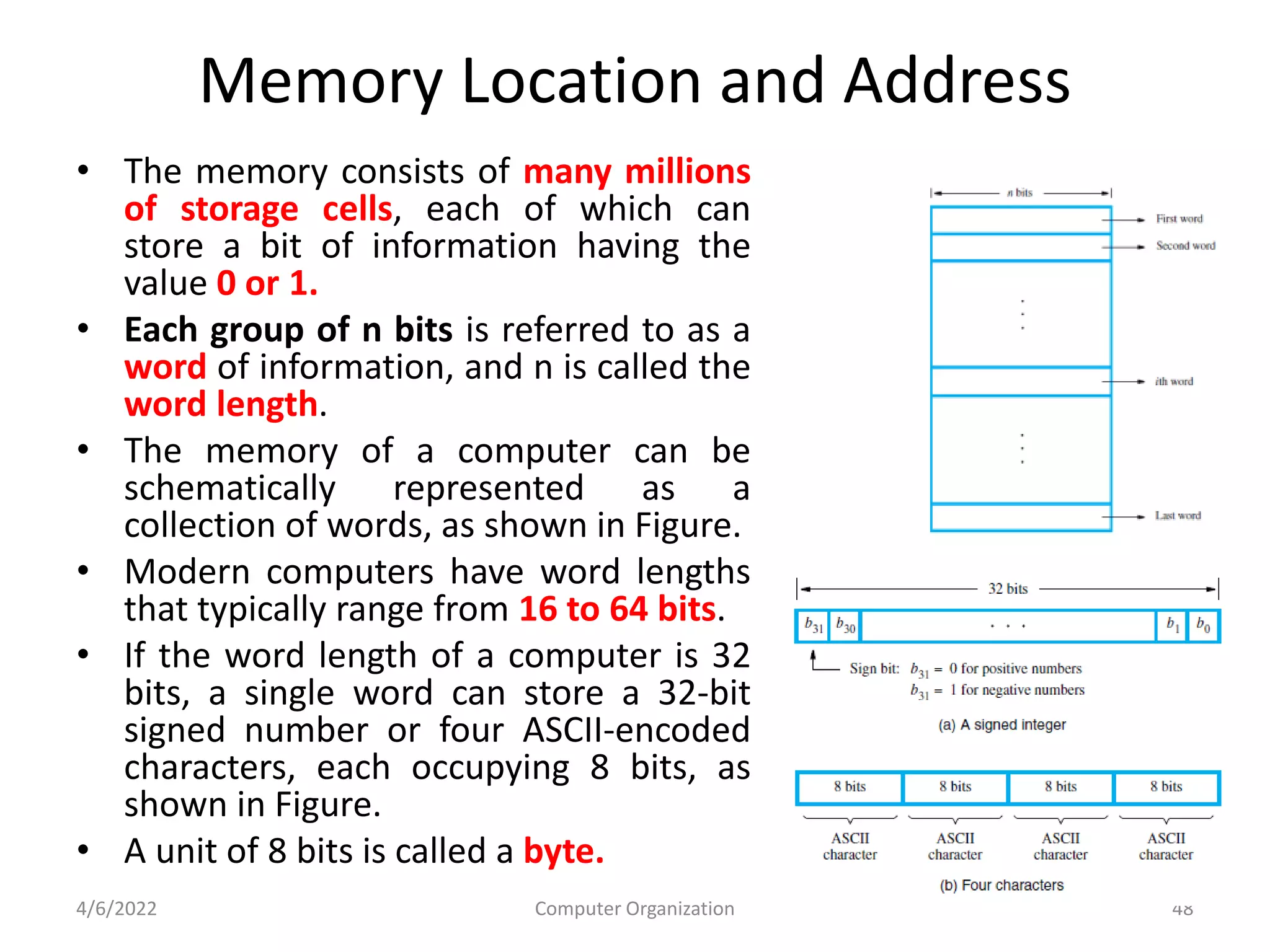



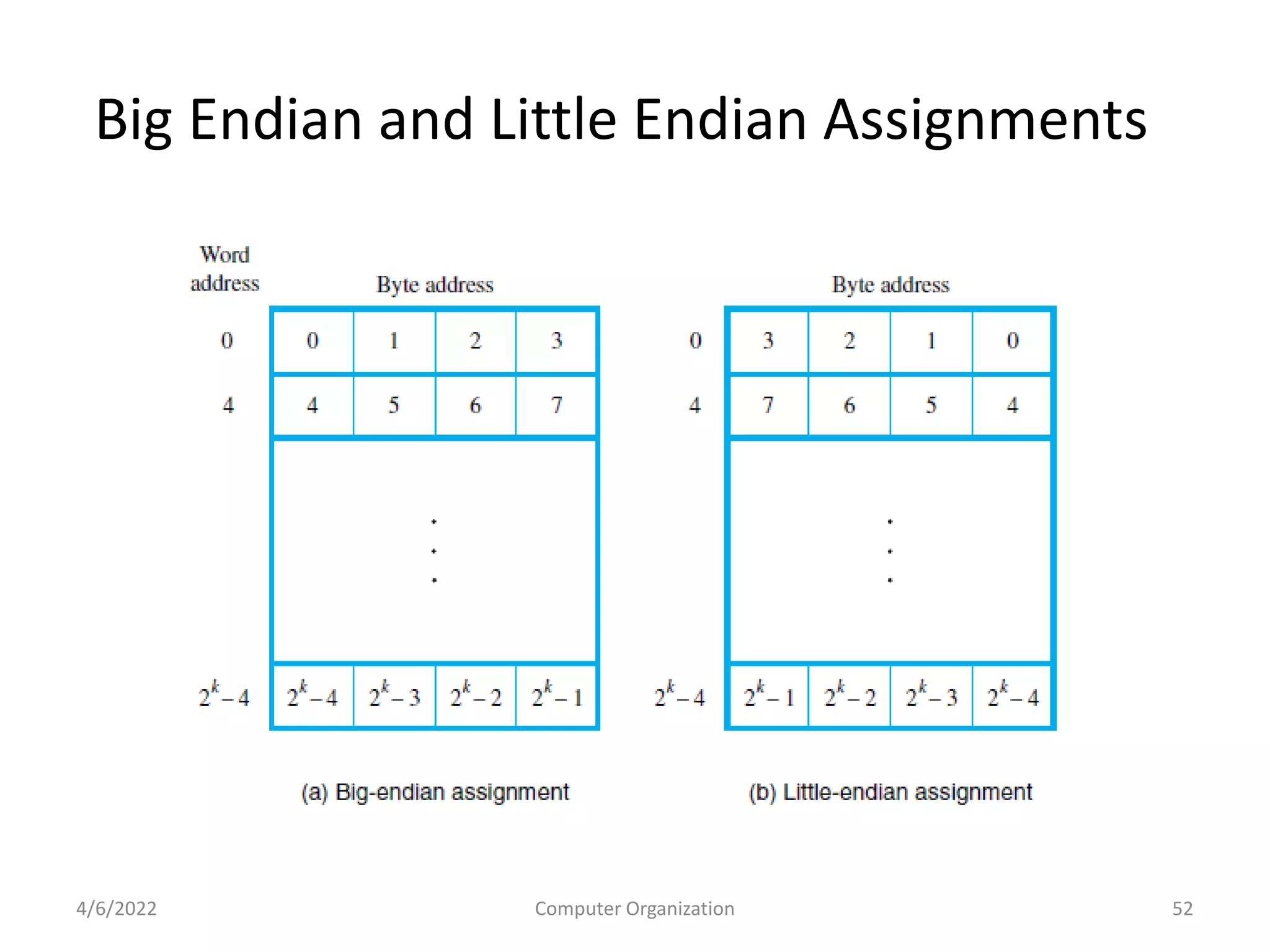













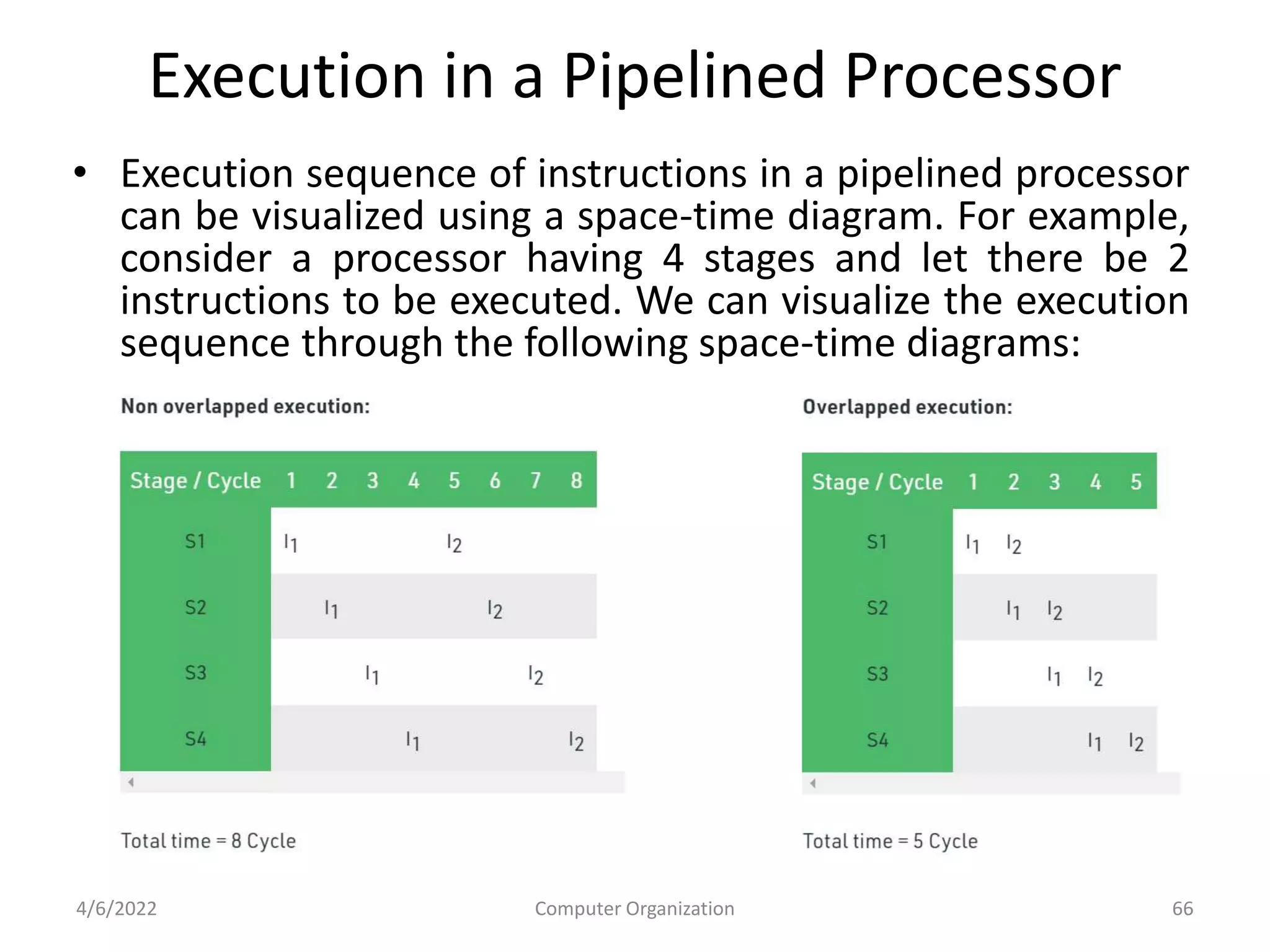













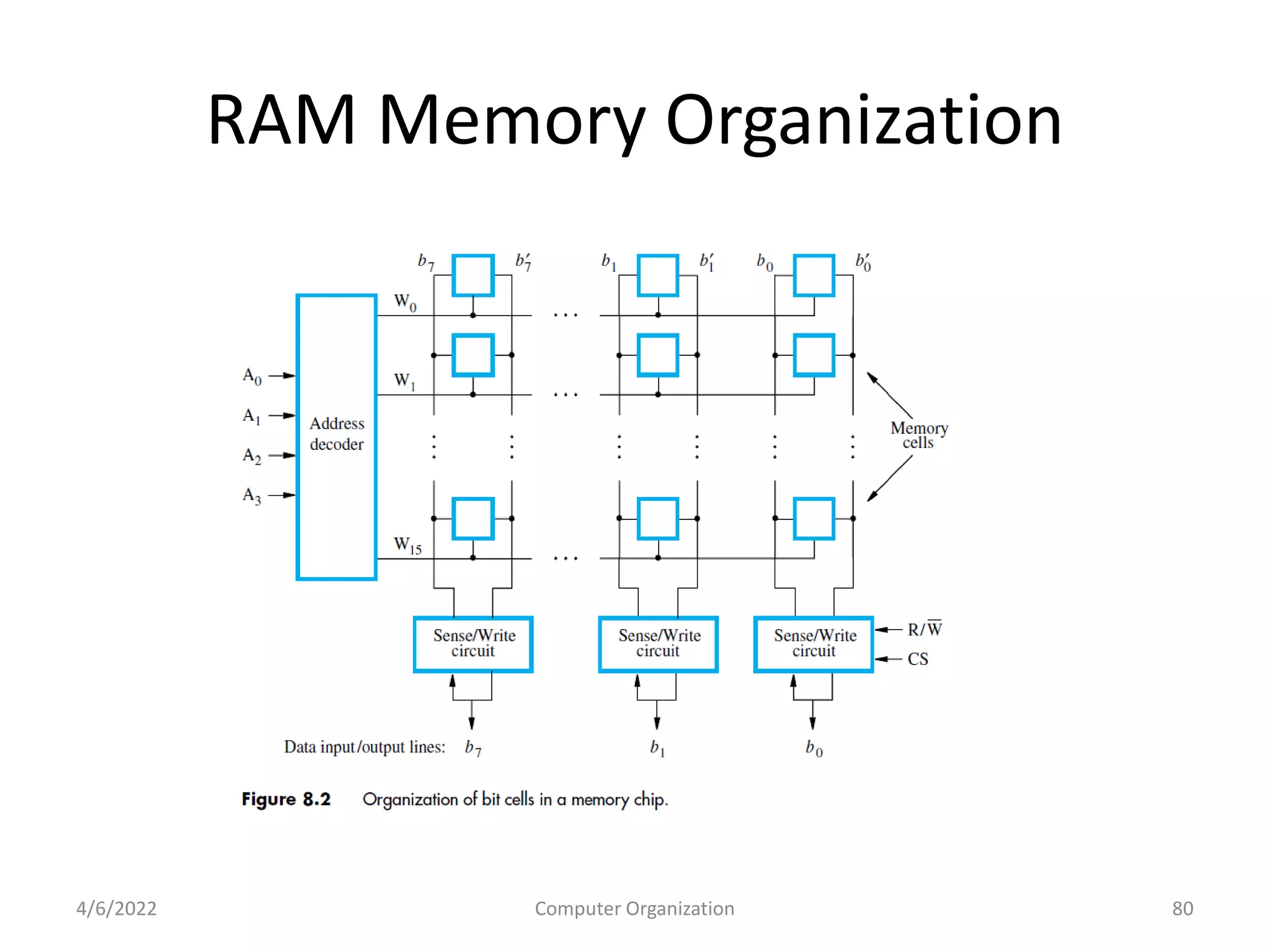


















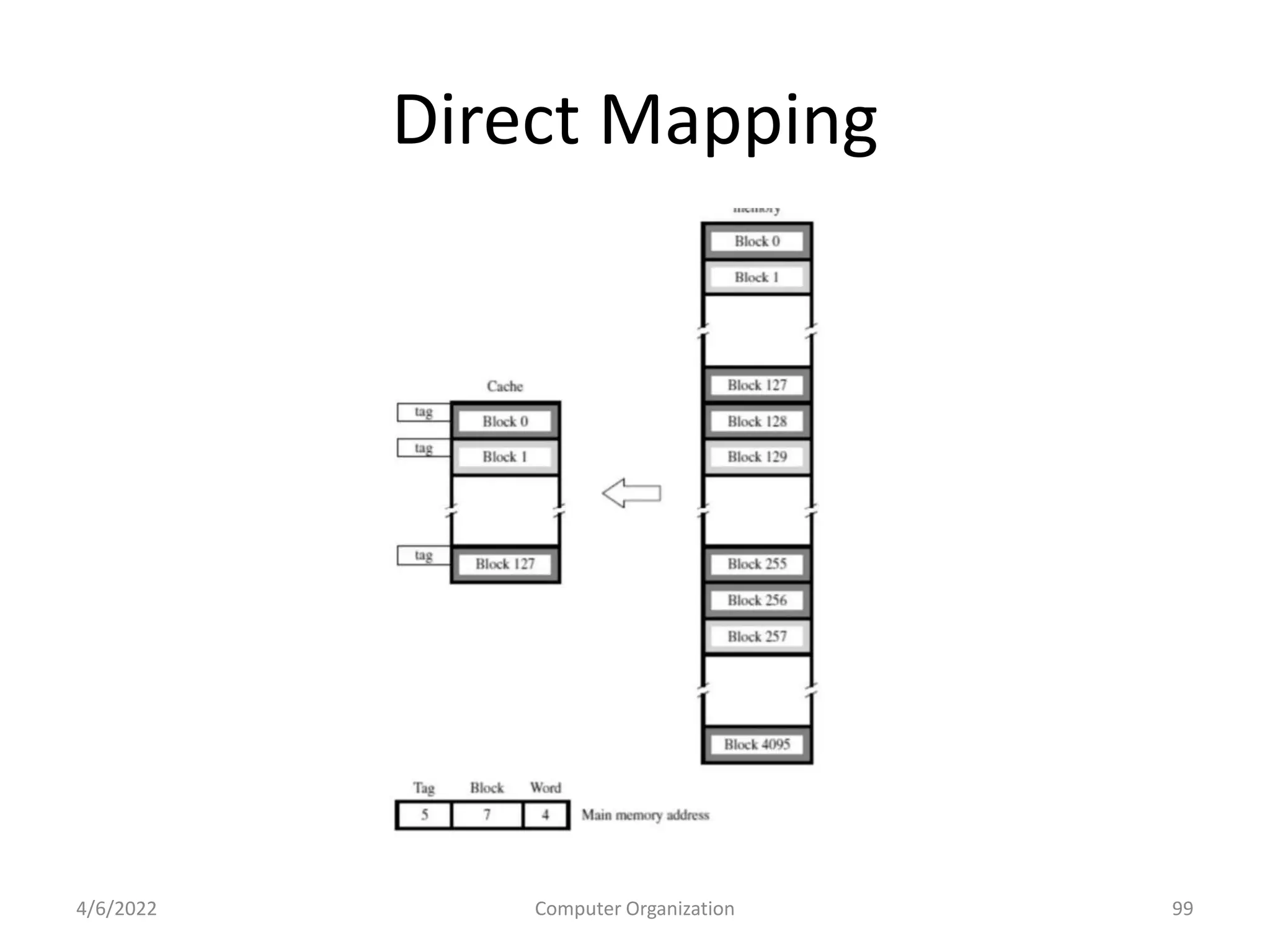




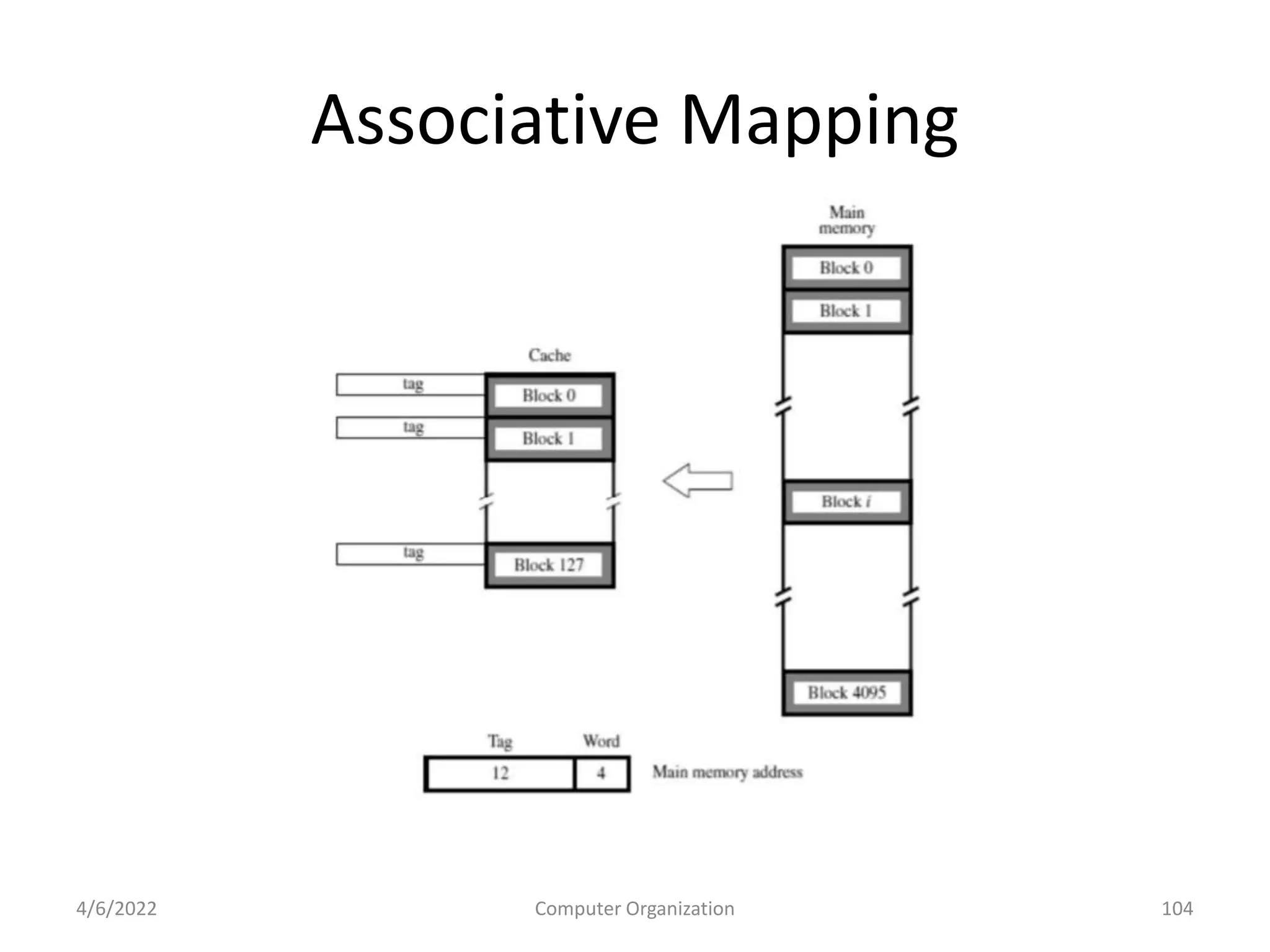


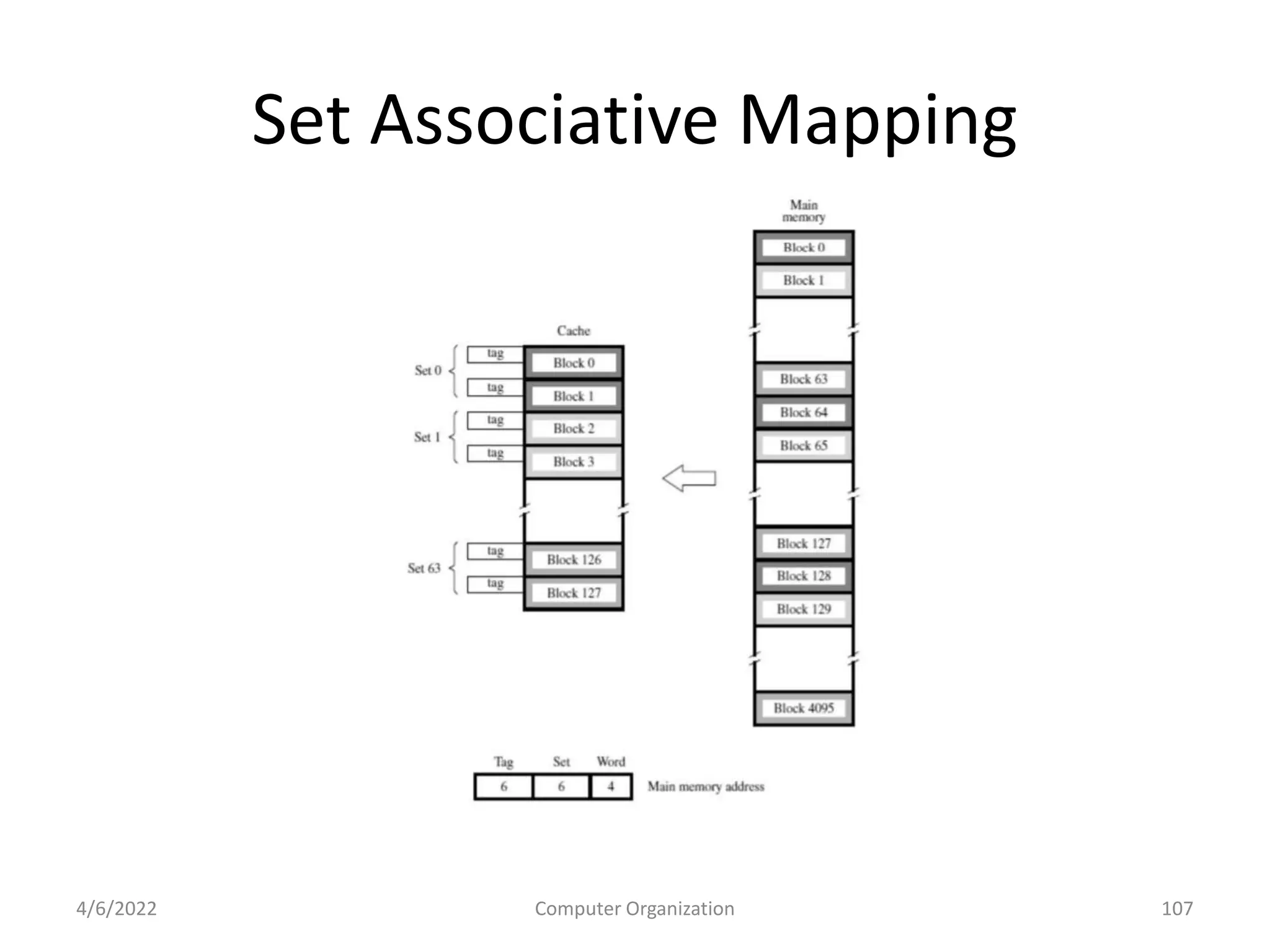



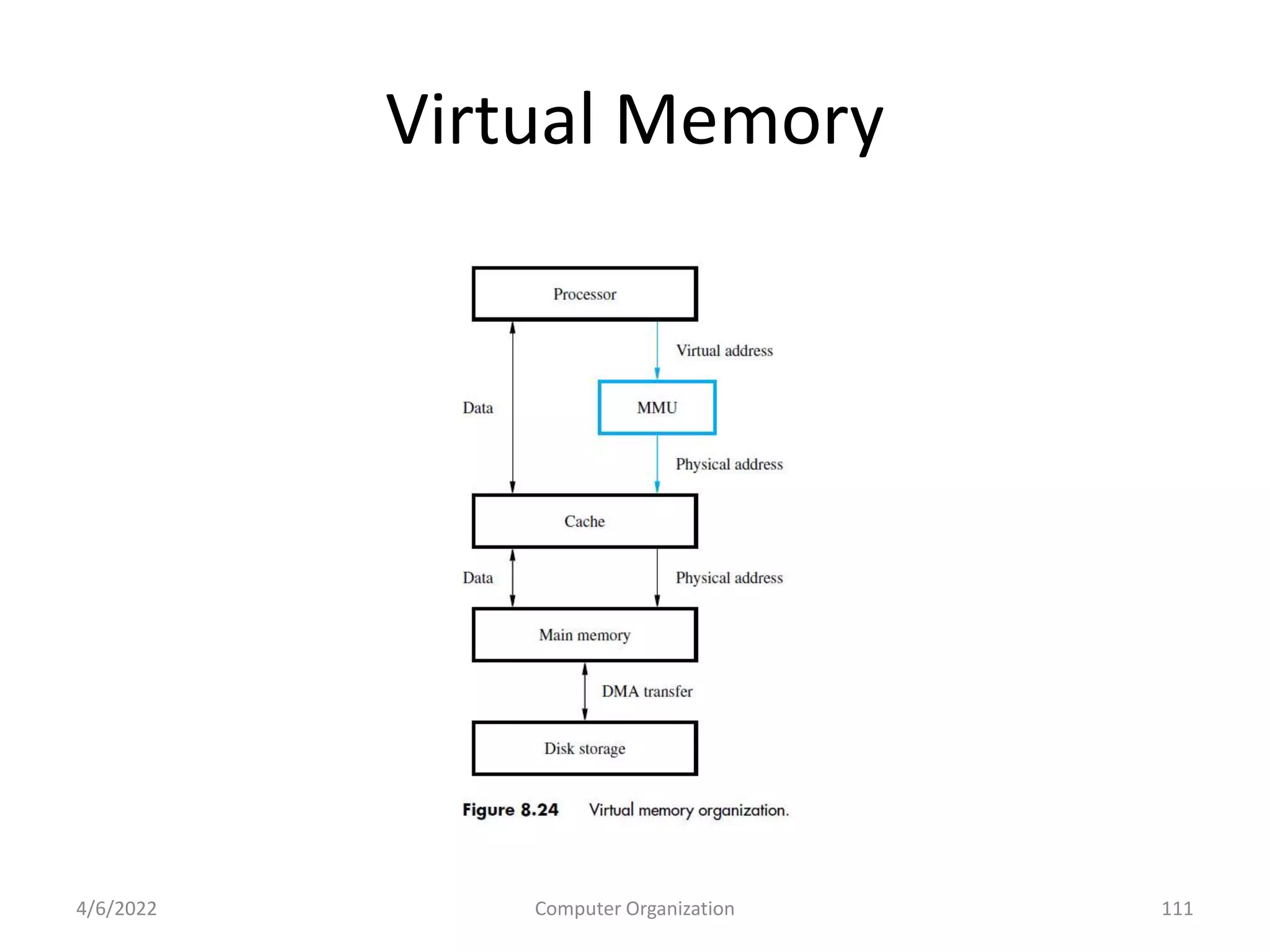

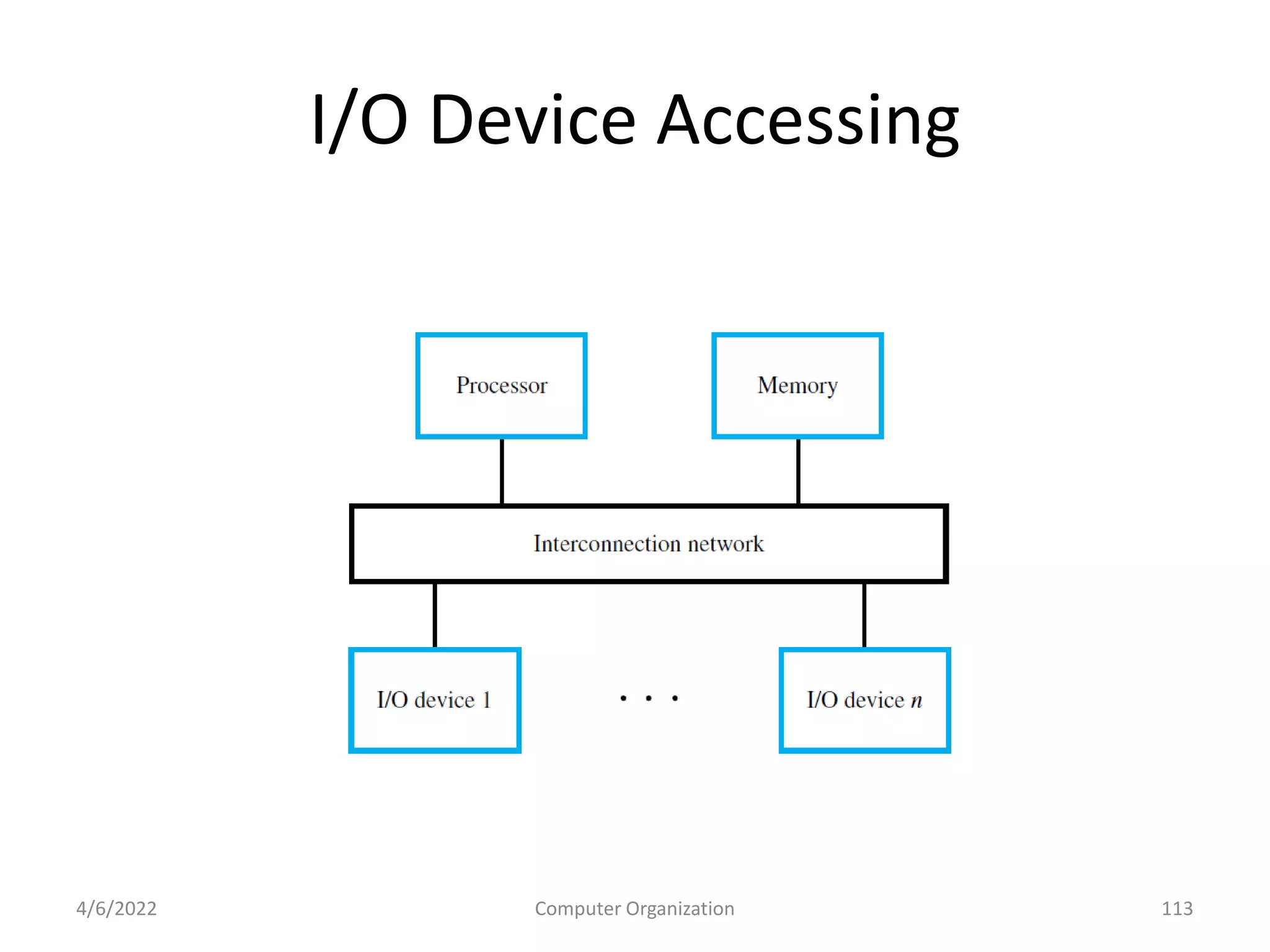










This document provides an overview of computer organization. It discusses the functional units of a computer including taking input, storing data, processing data, outputting information, and controlling workflow. It also describes the components of a processor such as the instruction register, program counter, memory address register, and general purpose registers. Finally, it examines concepts like pipelining, where instructions are broken down into stages to allow simultaneous execution and improve performance compared to non-pipelined processors.

















































![[PPT] _ Unit 2 _ 9.0 _ Domain Specific IoT _Home Automation.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/pptunit29-220516115946-098632b6-thumbnail.jpg?width=640&height=640&fit=bounds)





![[PPT] _ Unit 5 _ Evolve.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/pptunit5evolve-220707120639-5c6df843-thumbnail.jpg?width=640&height=640&fit=bounds)


![[PPT] _ Unit 3 _ Experiment.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/pptunit3experiment-220707114954-1996fe08-thumbnail.jpg?width=640&height=640&fit=bounds)





![[PPT] _ Unit 4 _ Engage.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/pptunit4engage-220707115545-9dce3530-thumbnail.jpg?width=640&height=640&fit=bounds)


![[PPT] _ UNIT 1 _ COMPLETE.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/pptunit1complete-220516121012-45cab1a3-thumbnail.jpg?width=640&height=640&fit=bounds)



















