- Traditional tests have fixed forms with all examinees answering the same items, which is inefficient and leads to differences in precision.
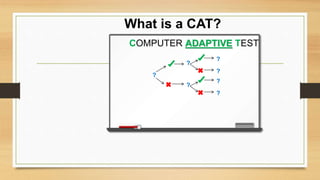
- Computer adaptive testing (CAT) tailors the difficulty and number of items to each examinee based on their responses to previous questions. CAT aims to maximize precision by selecting subsequent questions based on the examinee's estimated ability level.
- CAT requires fewer items than traditional tests to arrive at equally accurate scores while providing a more personalized experience for each examinee.



















































![Adaptive Testing Methodology [ ATM ]](https://cdn.slidesharecdn.com/ss_thumbnails/atm-appseccali2016-160129024703-thumbnail.jpg?width=640&height=640&fit=bounds)













































