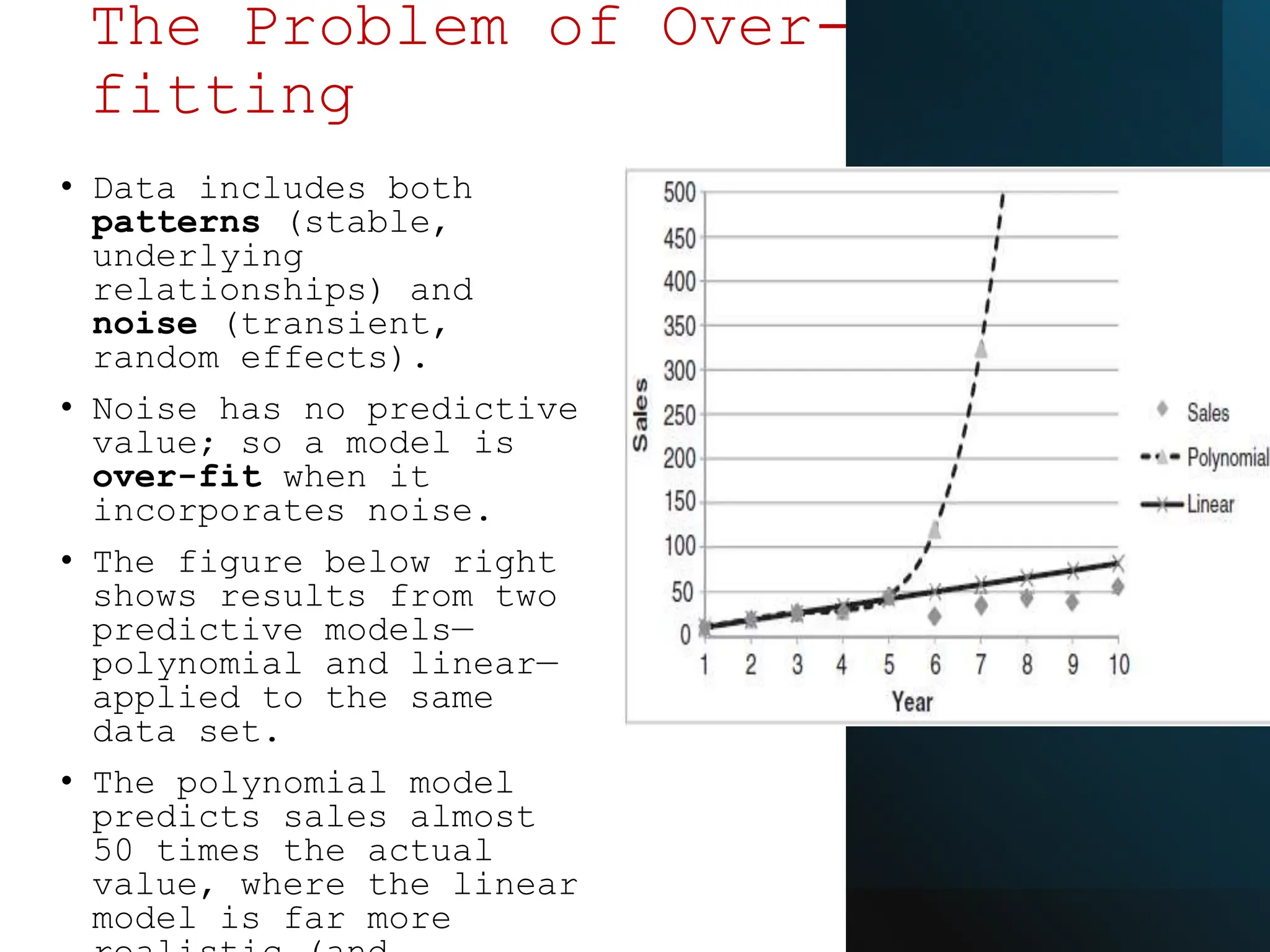
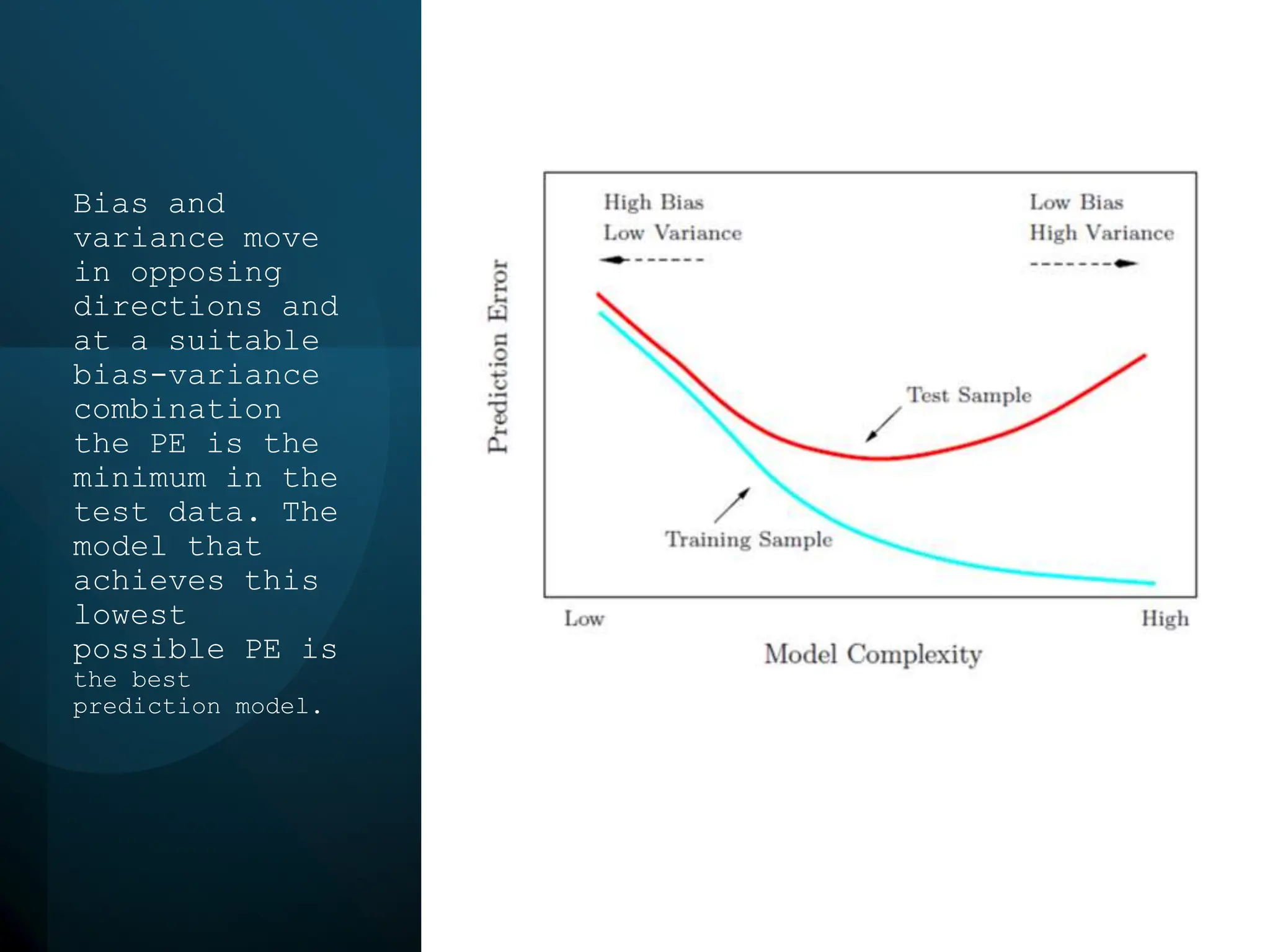
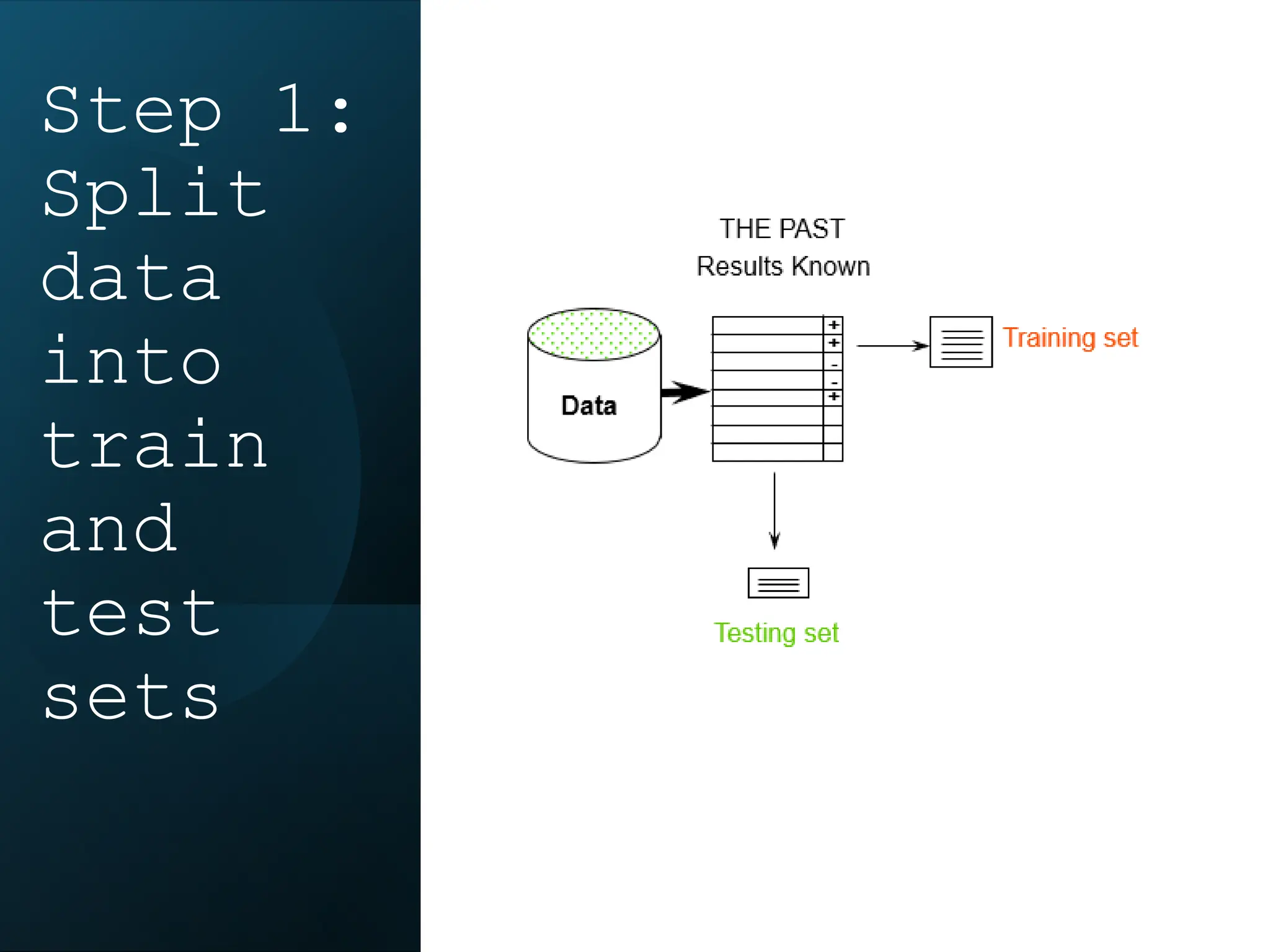
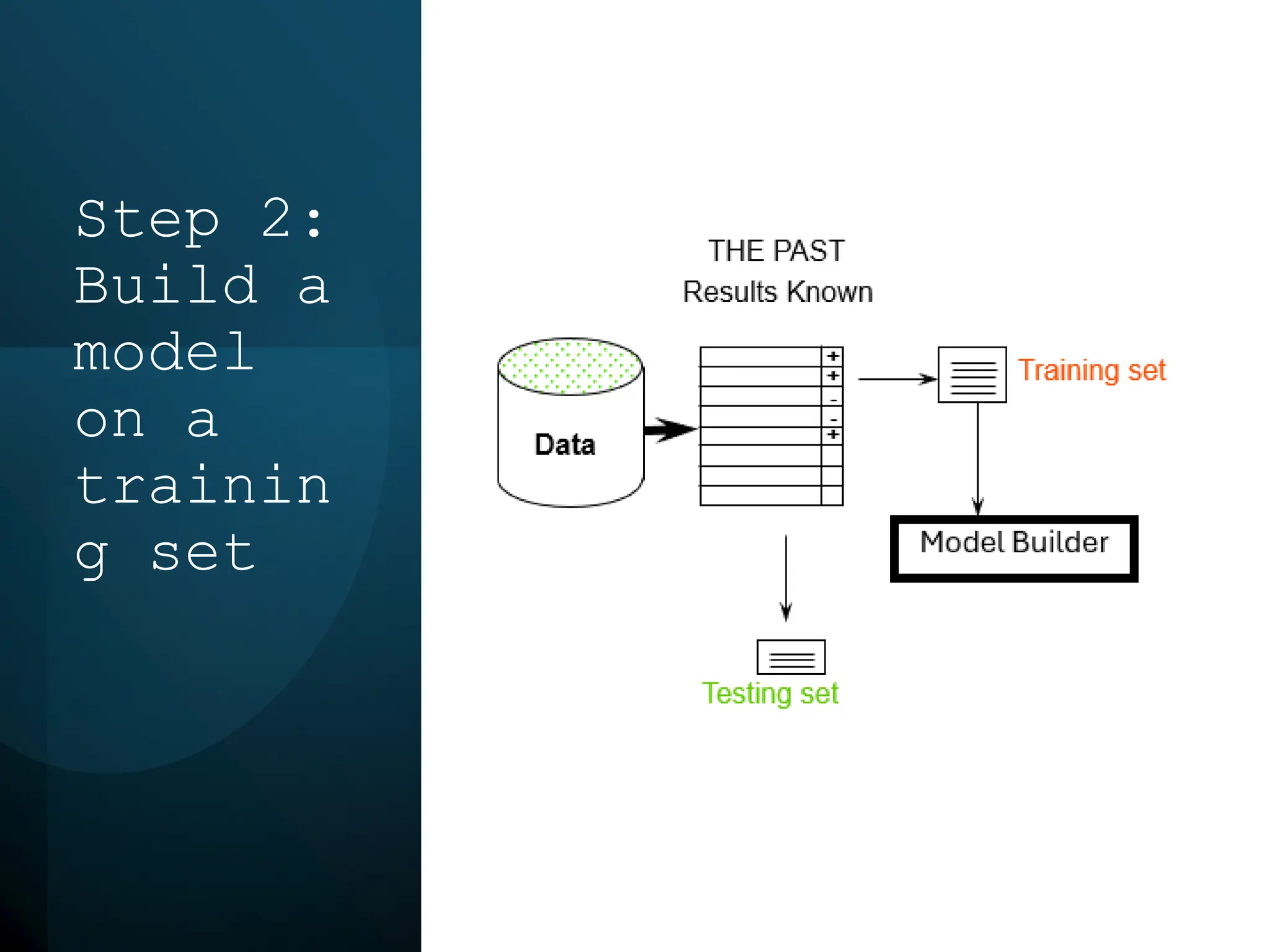
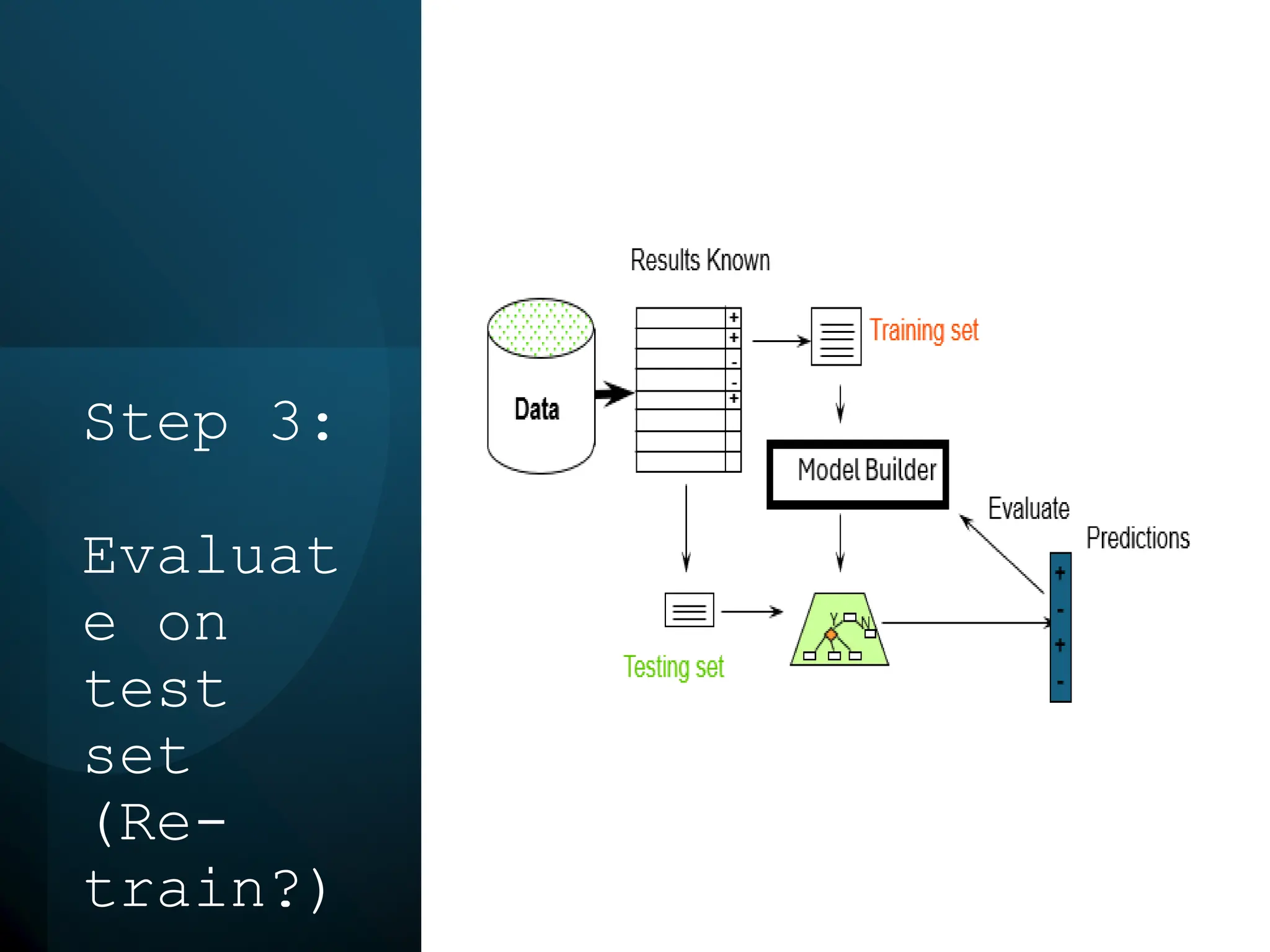
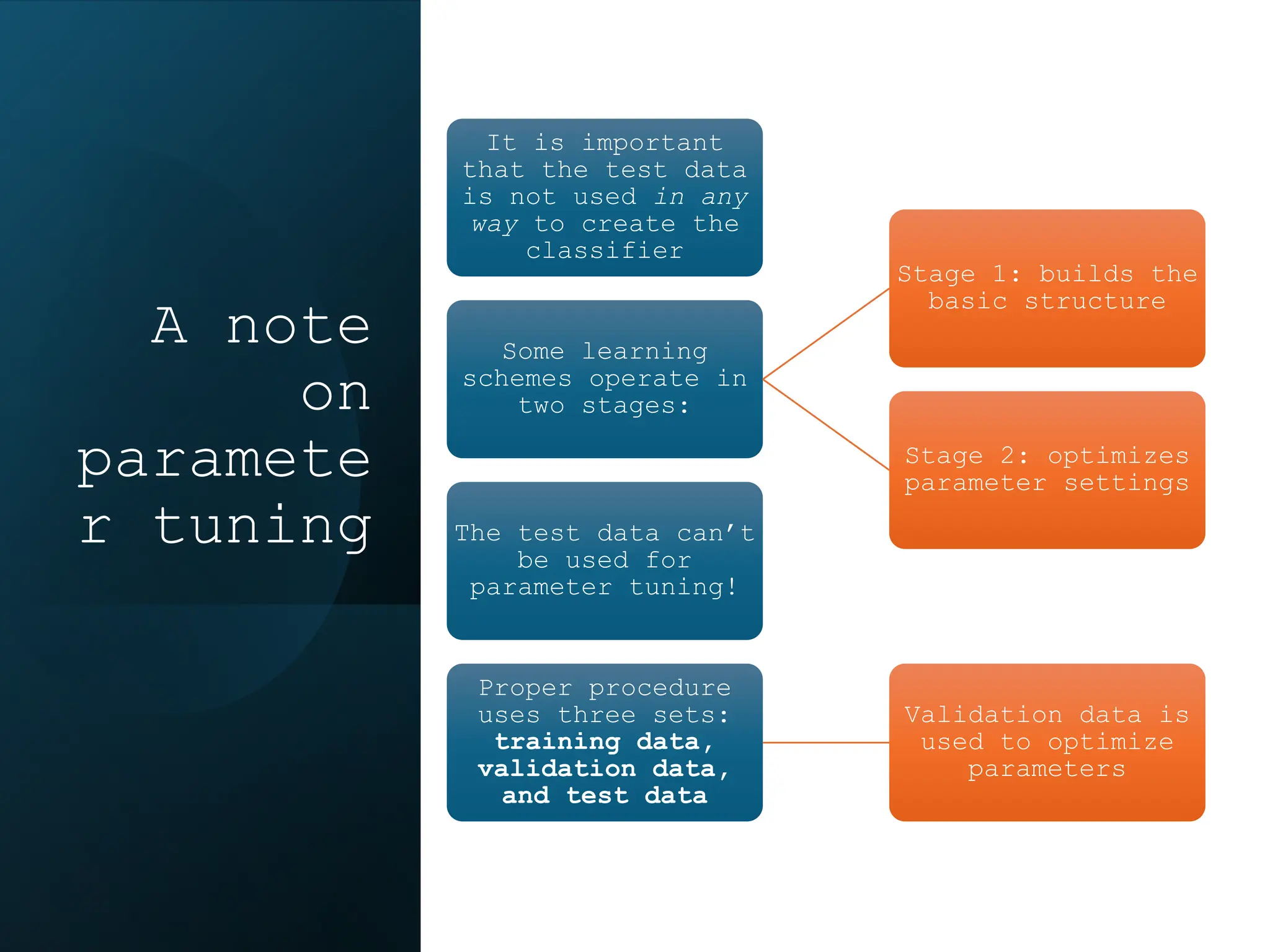
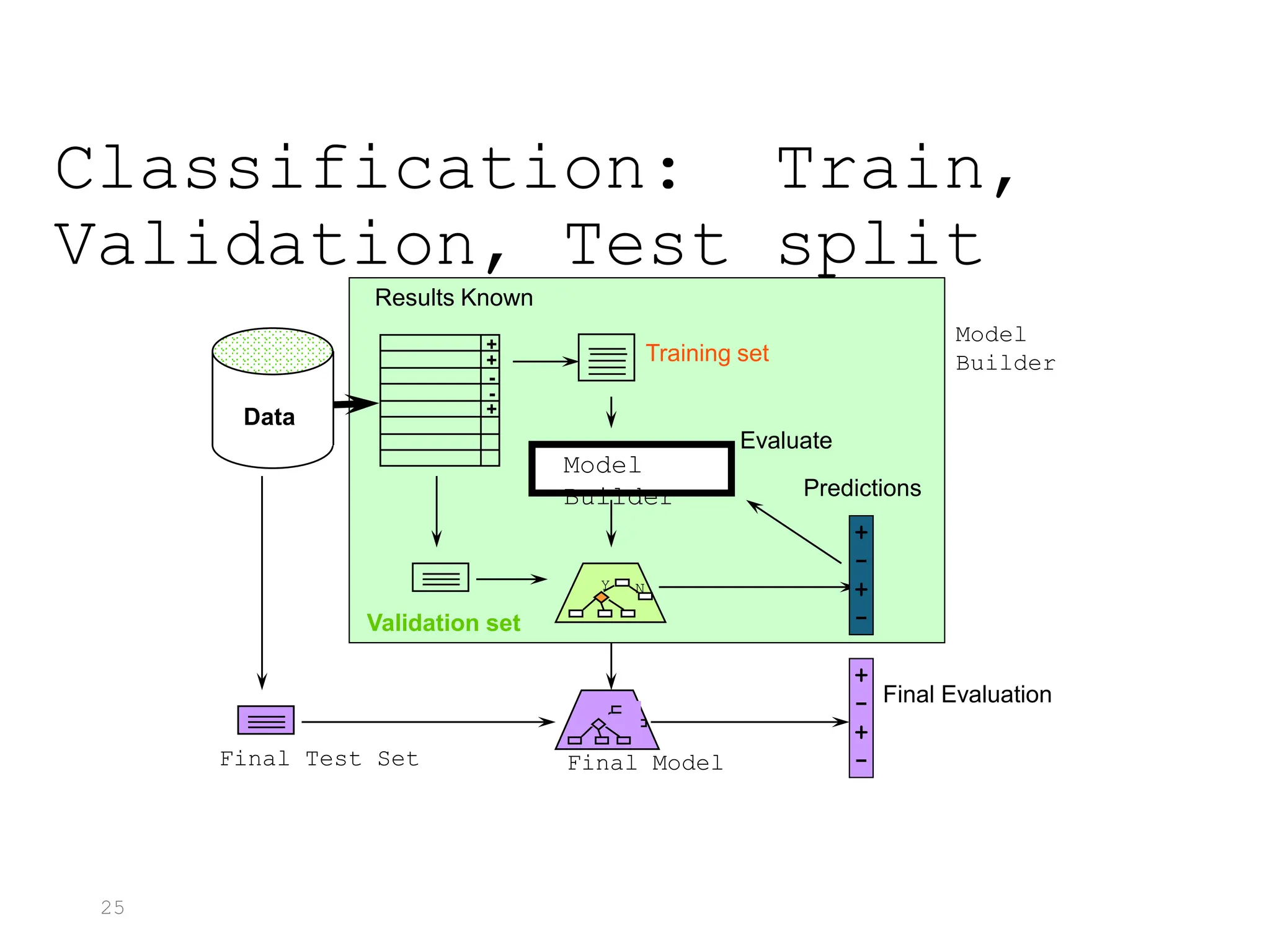
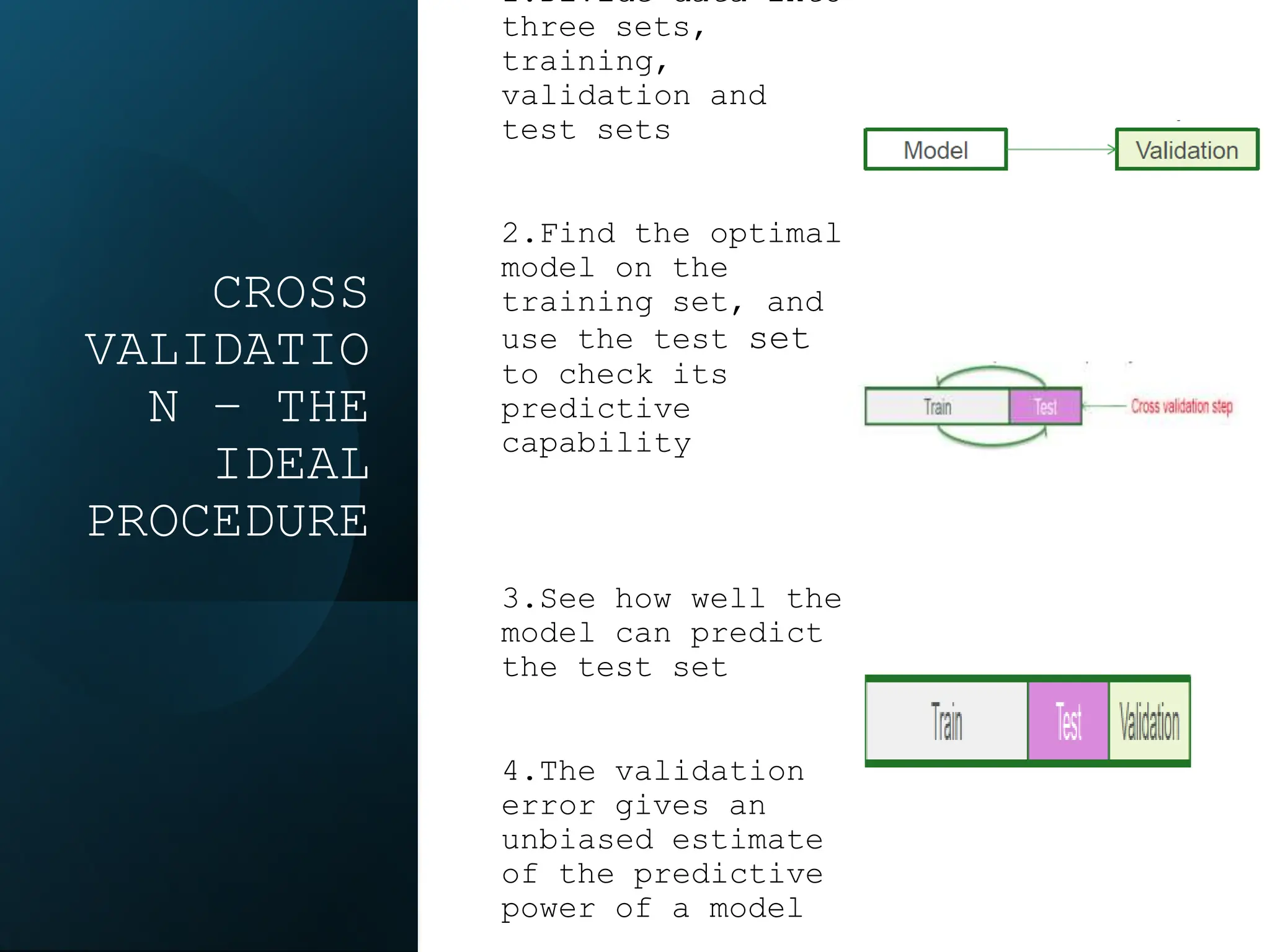
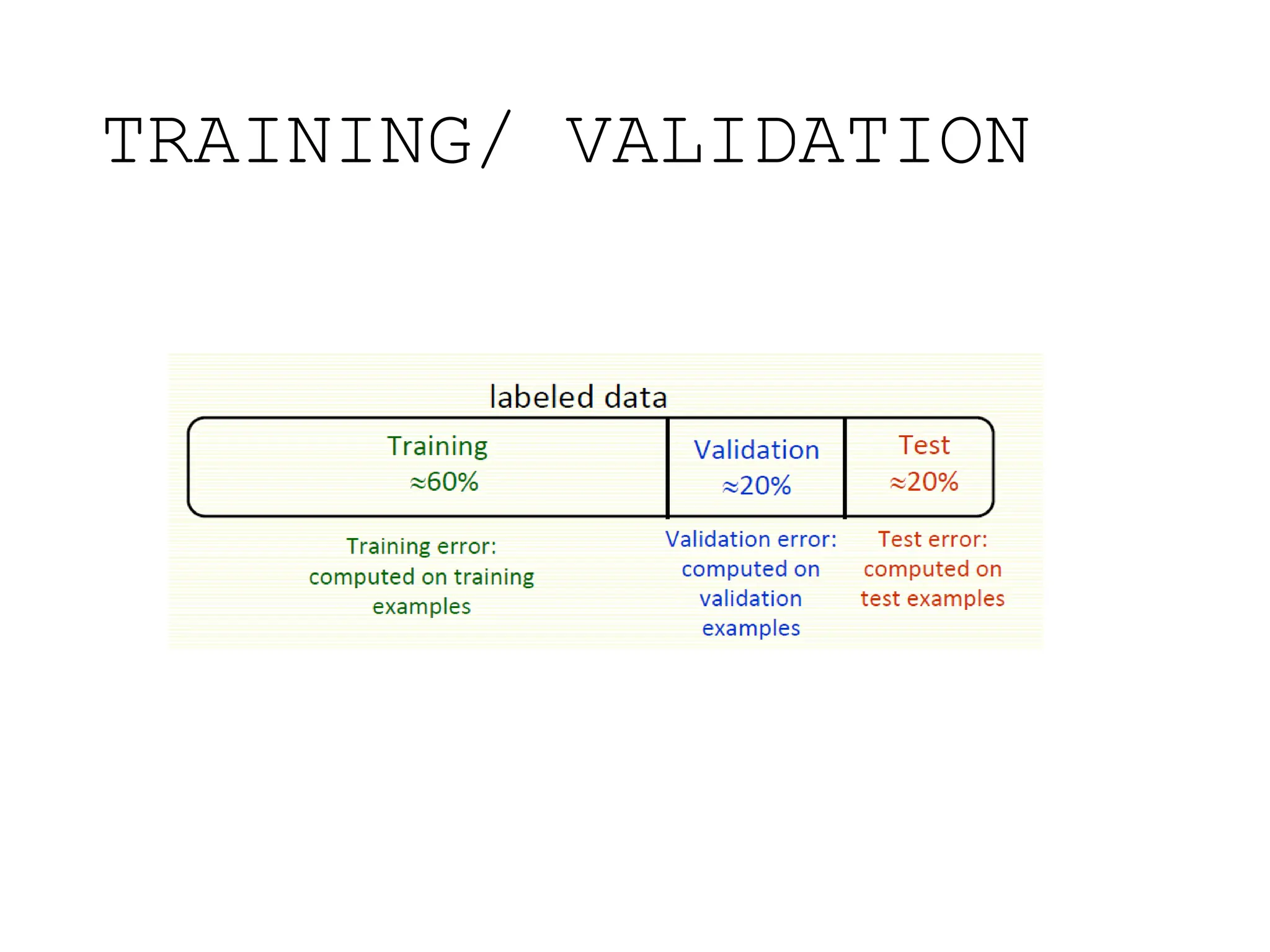
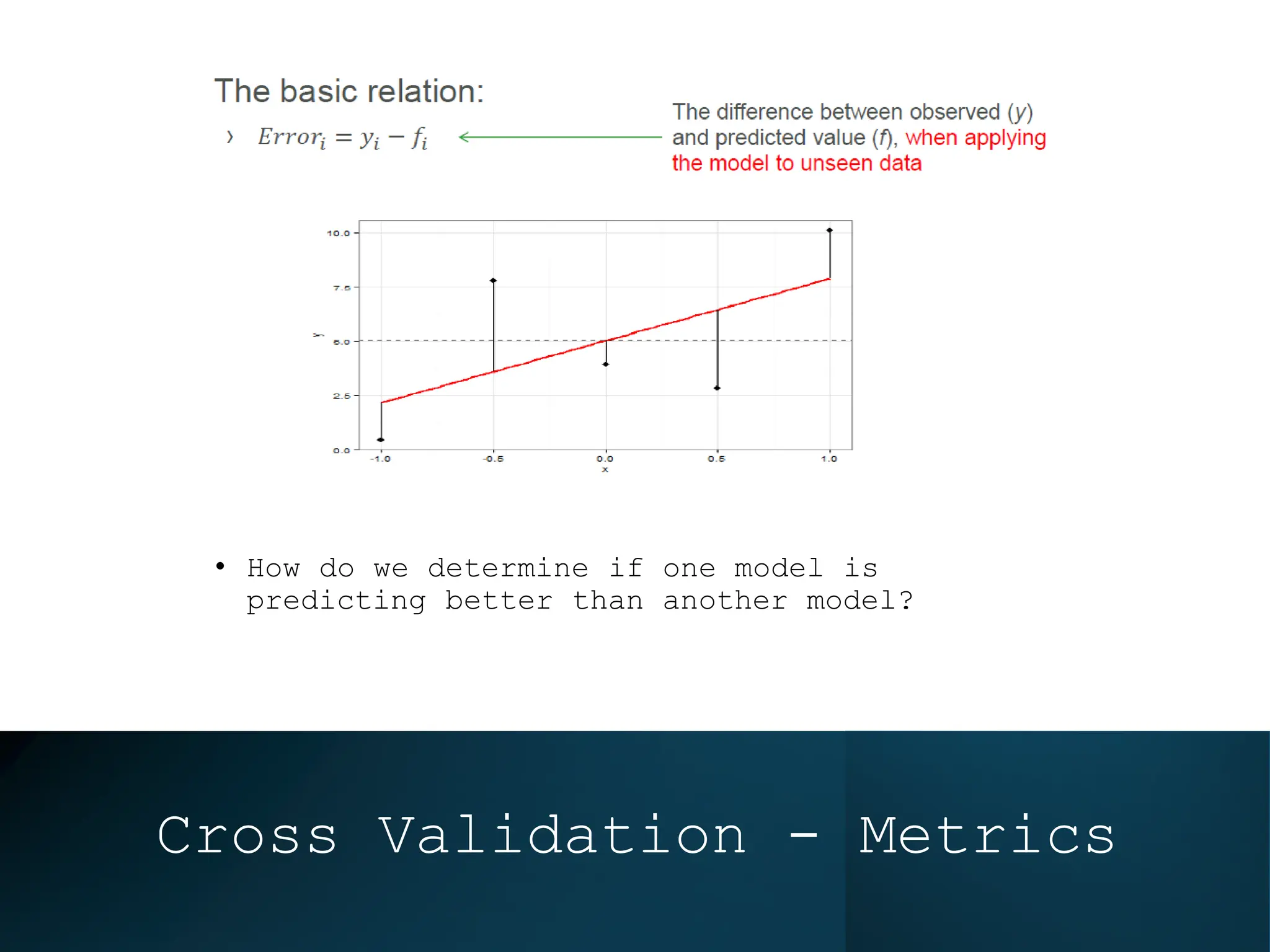
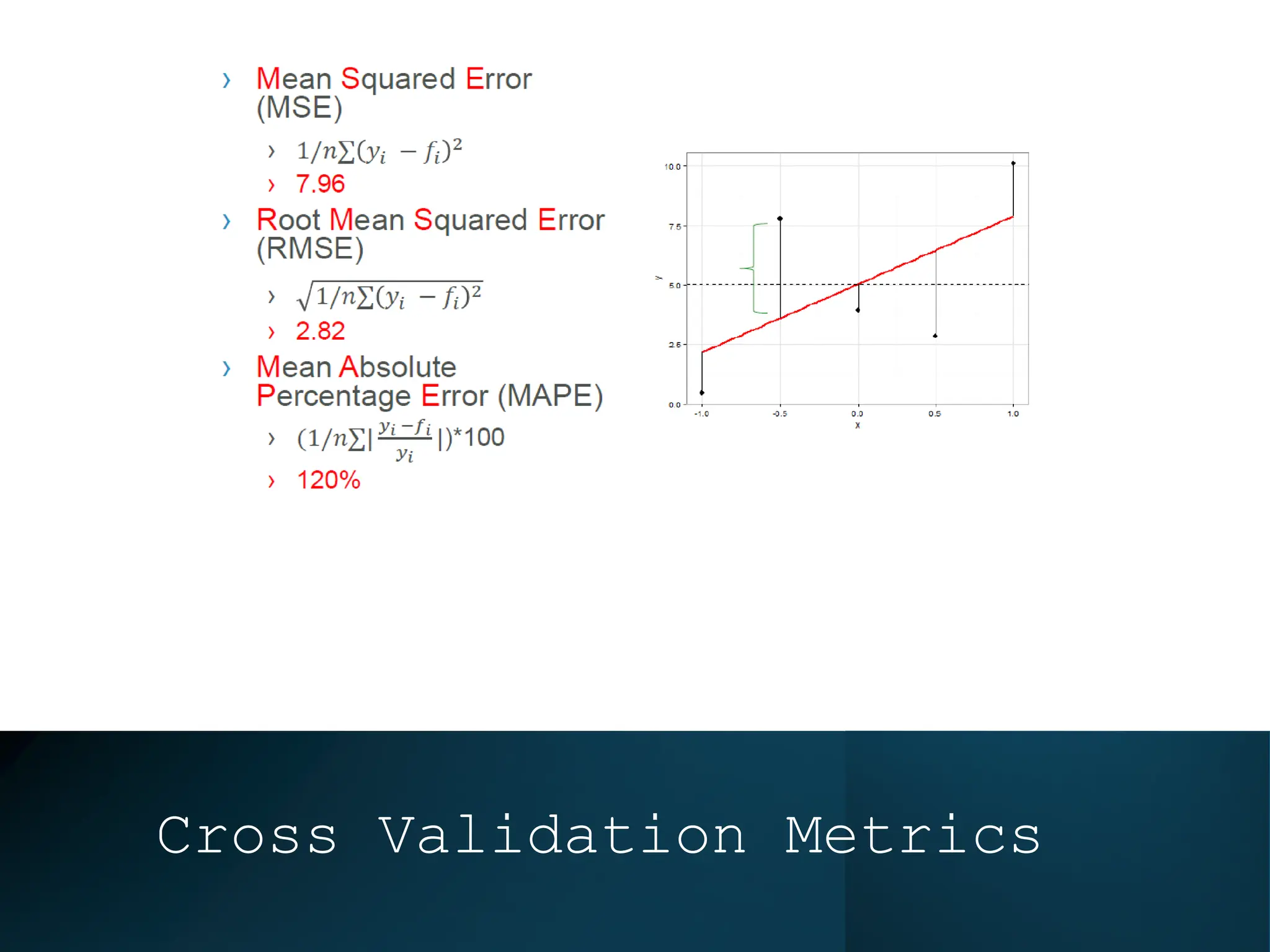
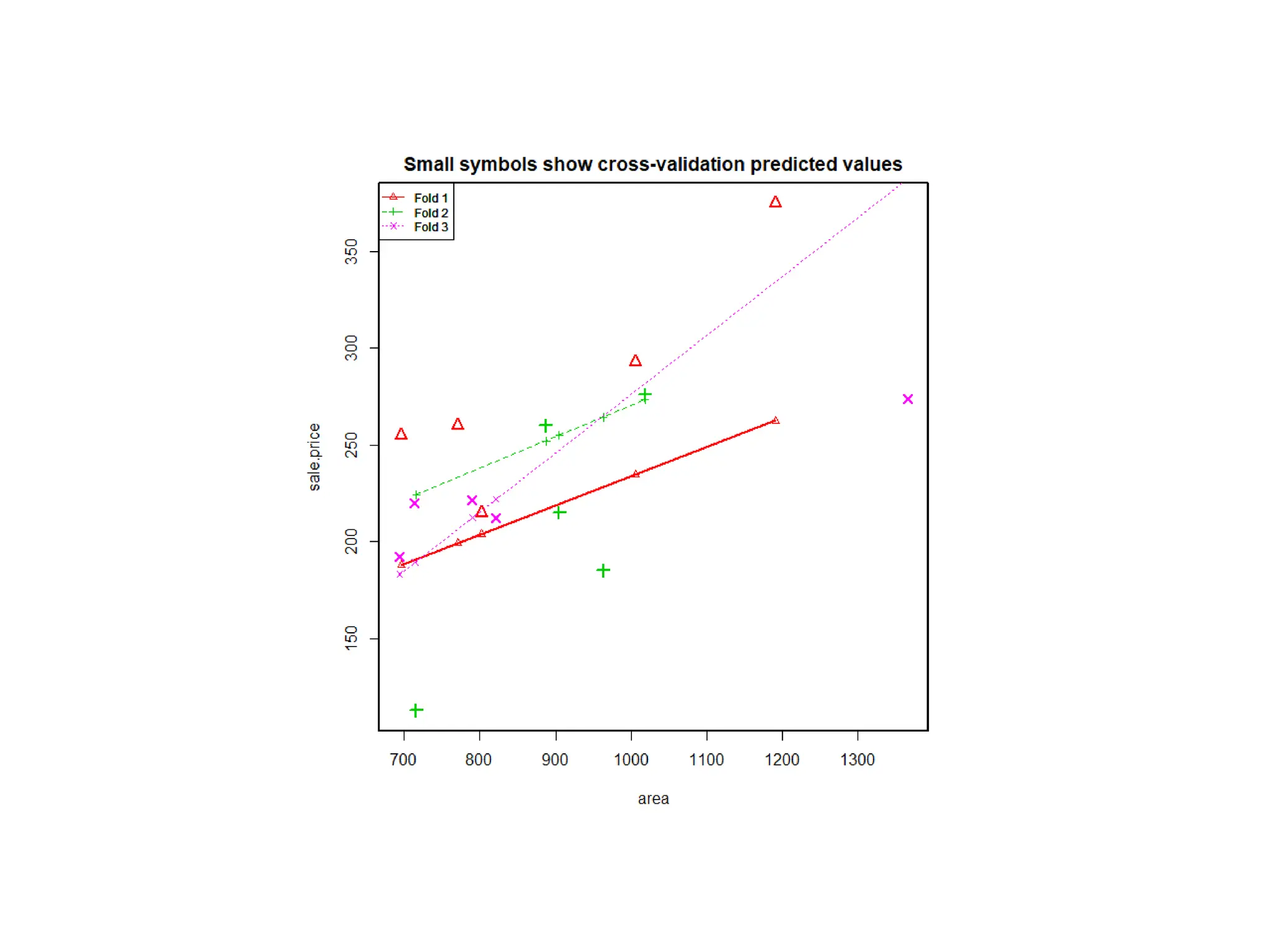
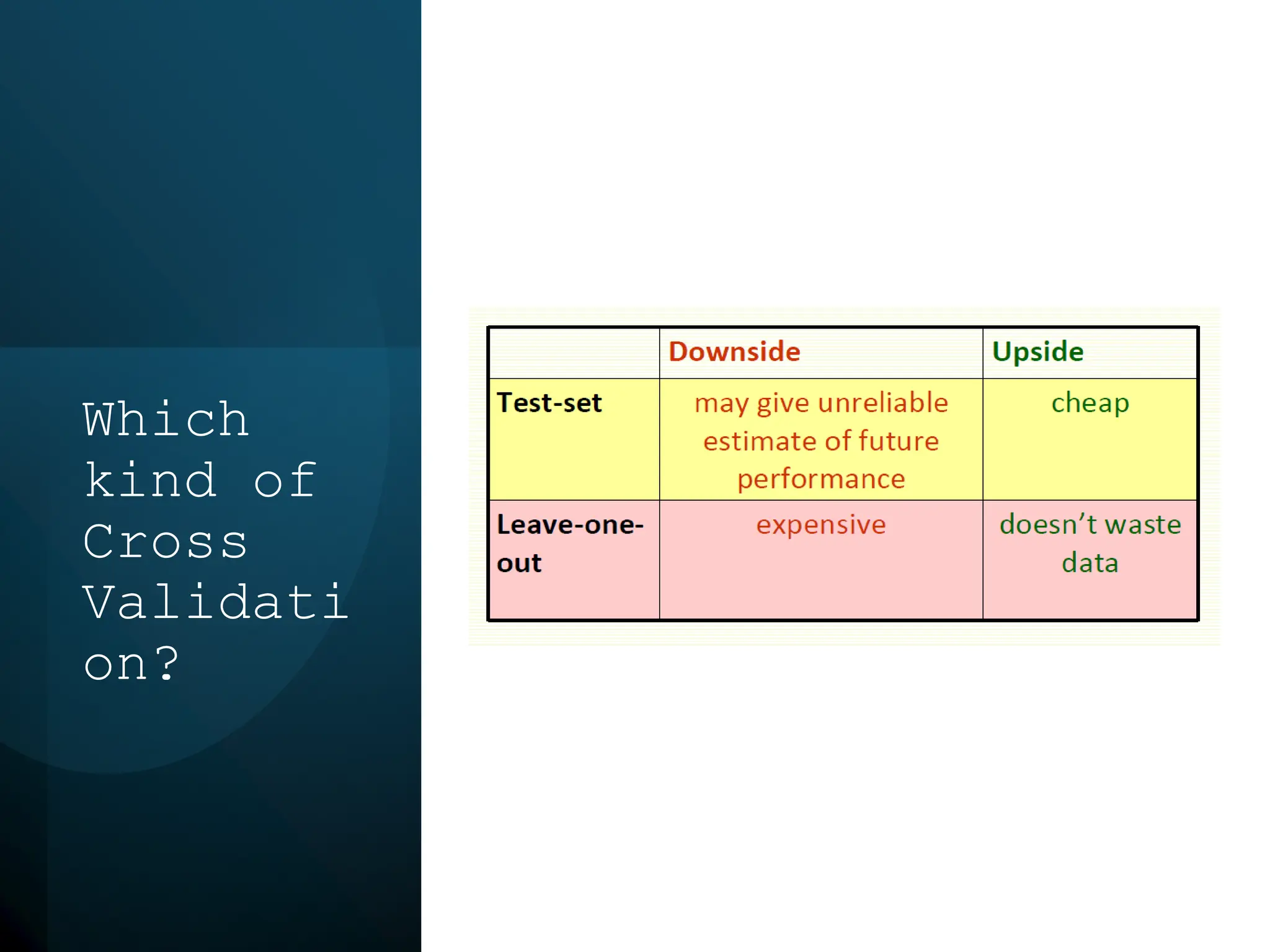
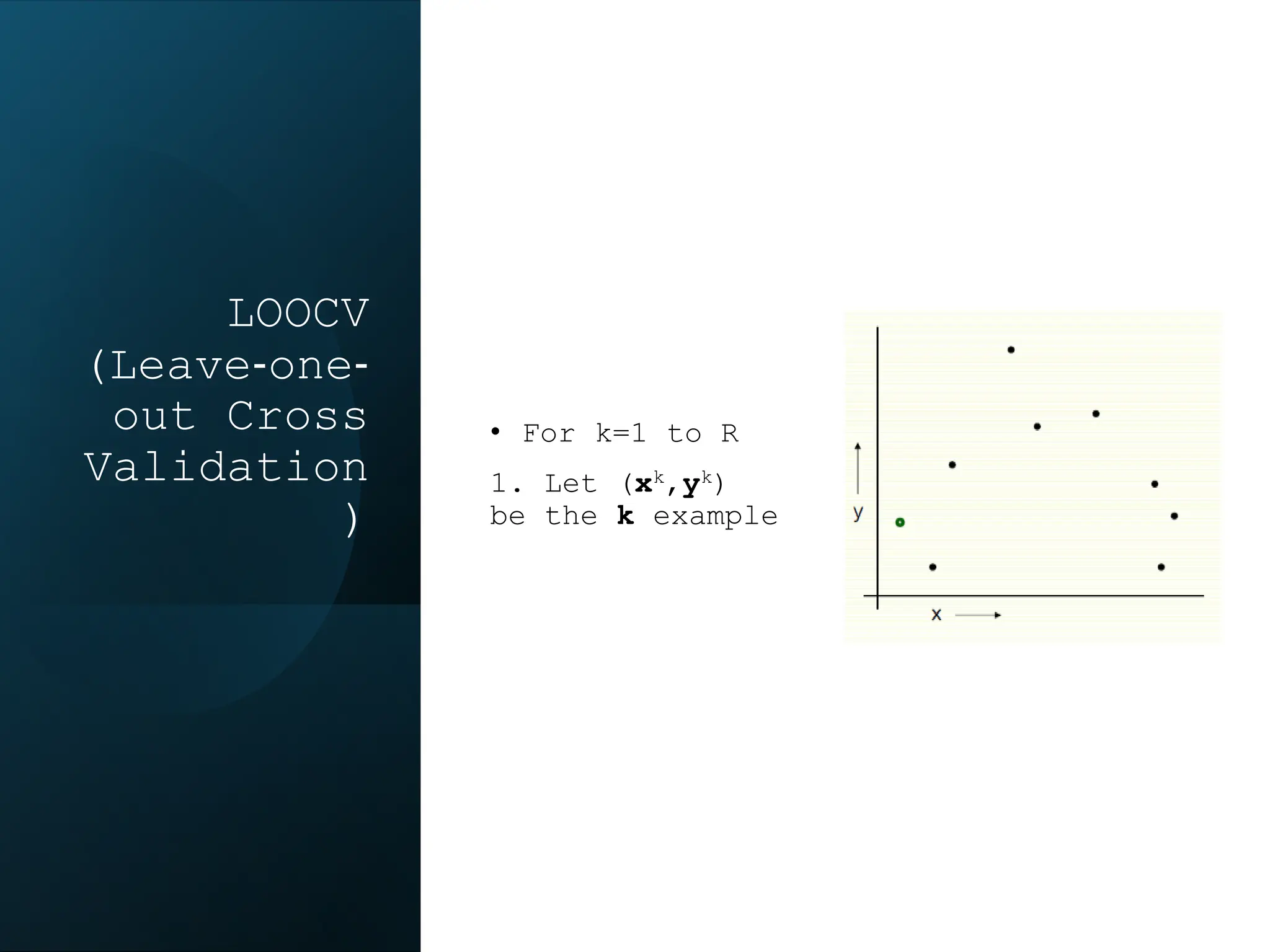
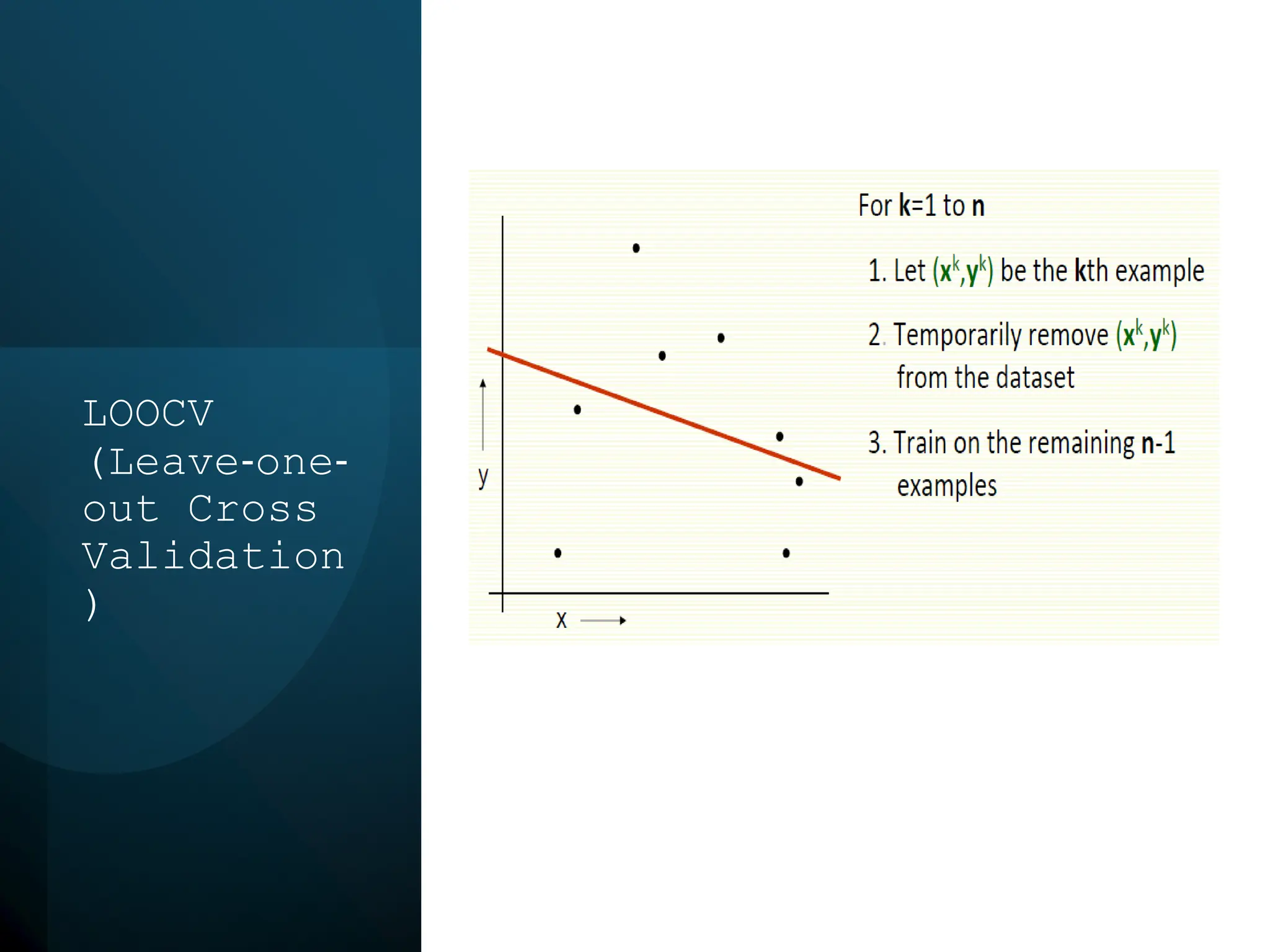
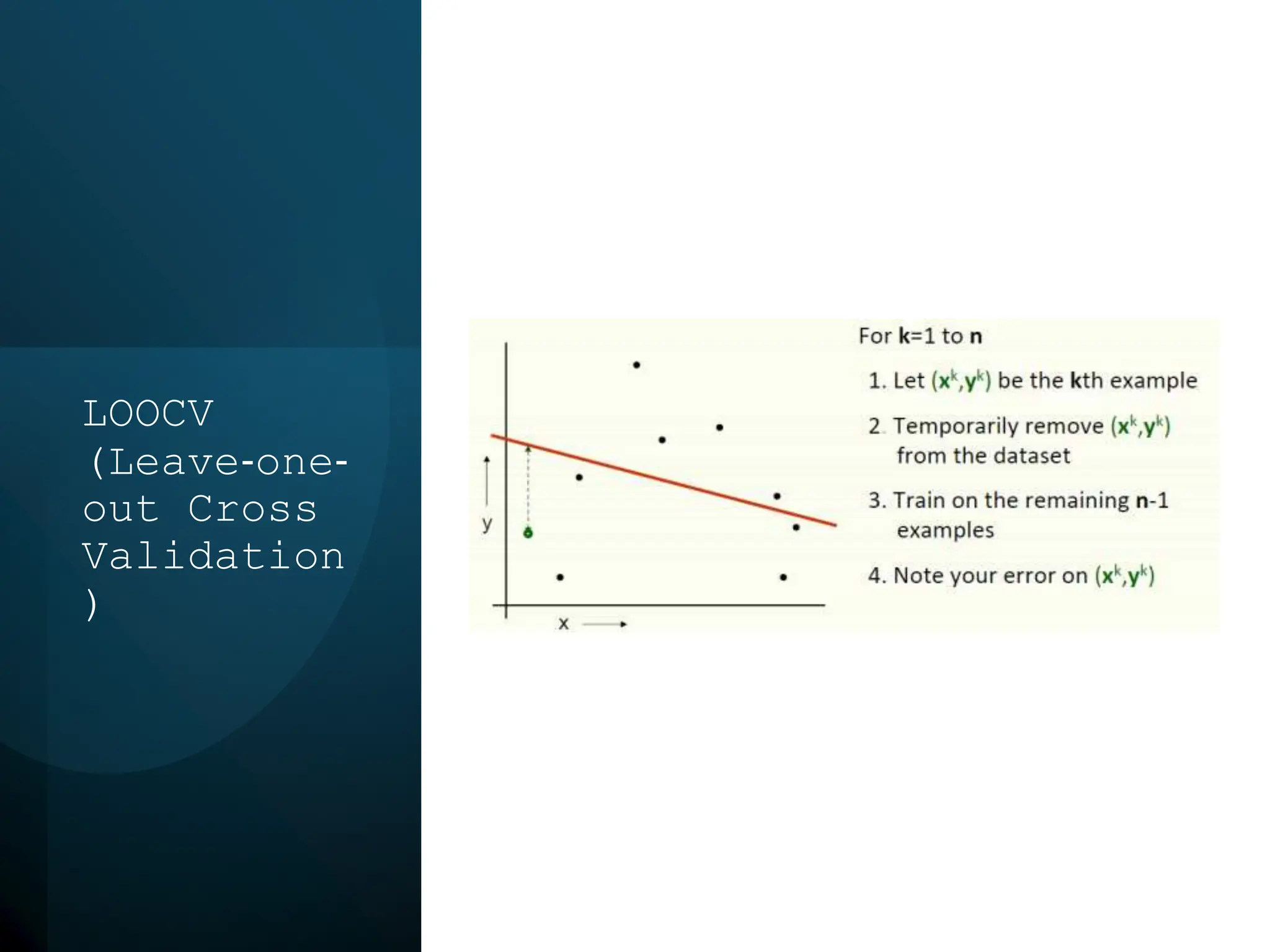
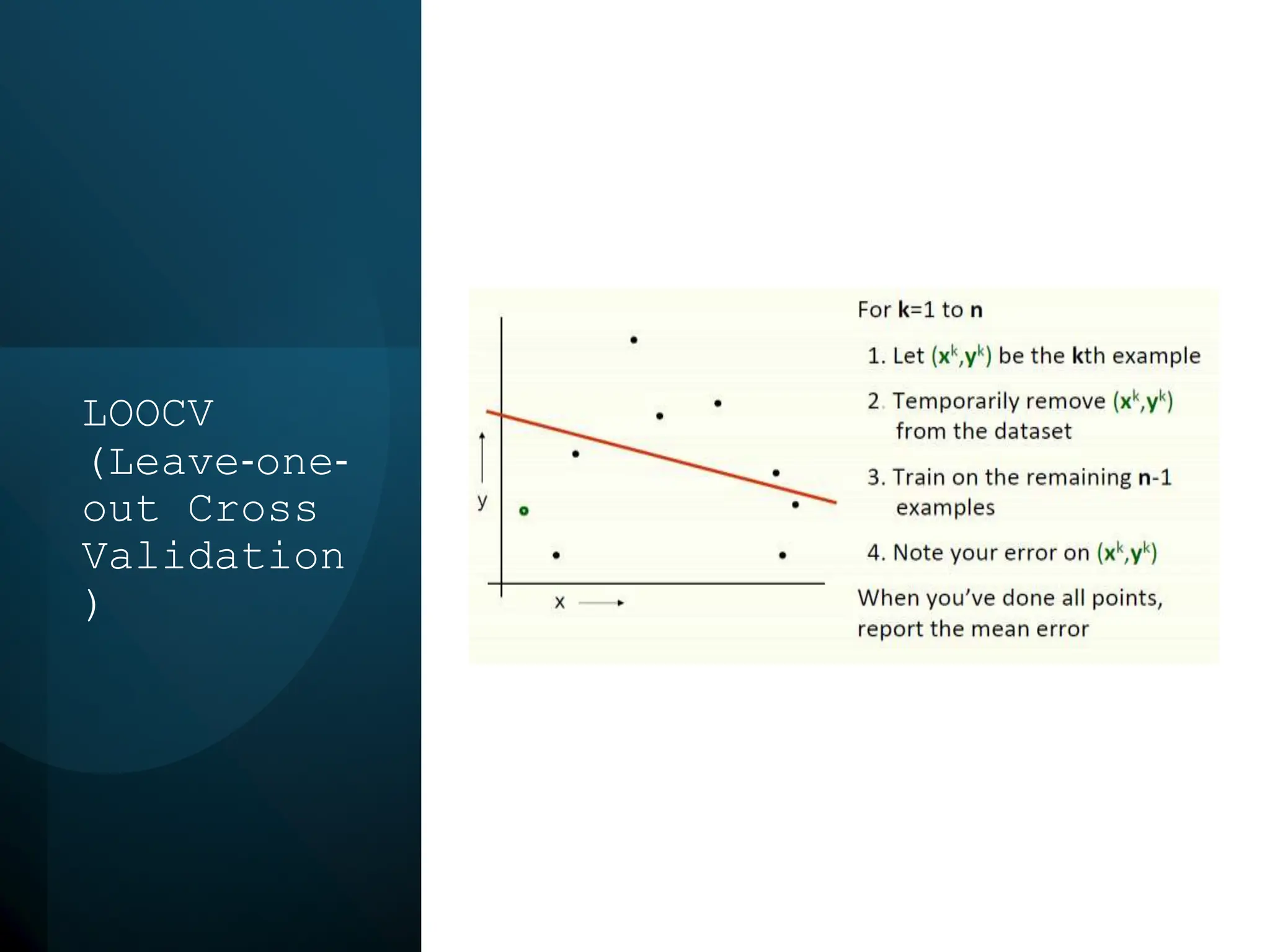
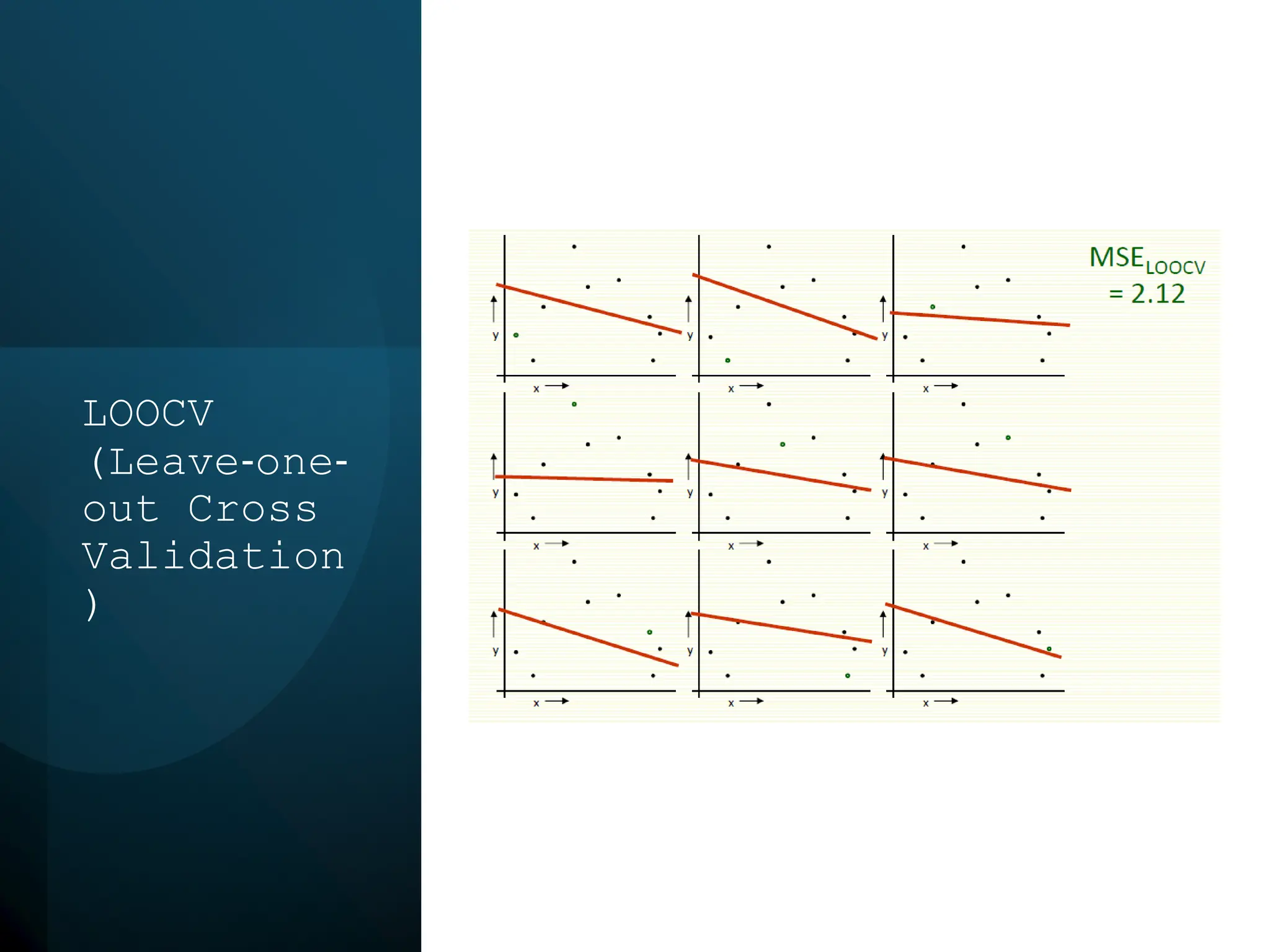
This document discusses statistical learning and model selection. It introduces statistical learning problems, statistical models, the need for statistical modeling, and issues around evaluating models. Key points include: statistical learning involves using data to build a predictive model; a good model balances bias and variance to minimize prediction error; cross-validation is described as the ideal procedure for evaluating models without overfitting to the test data.




























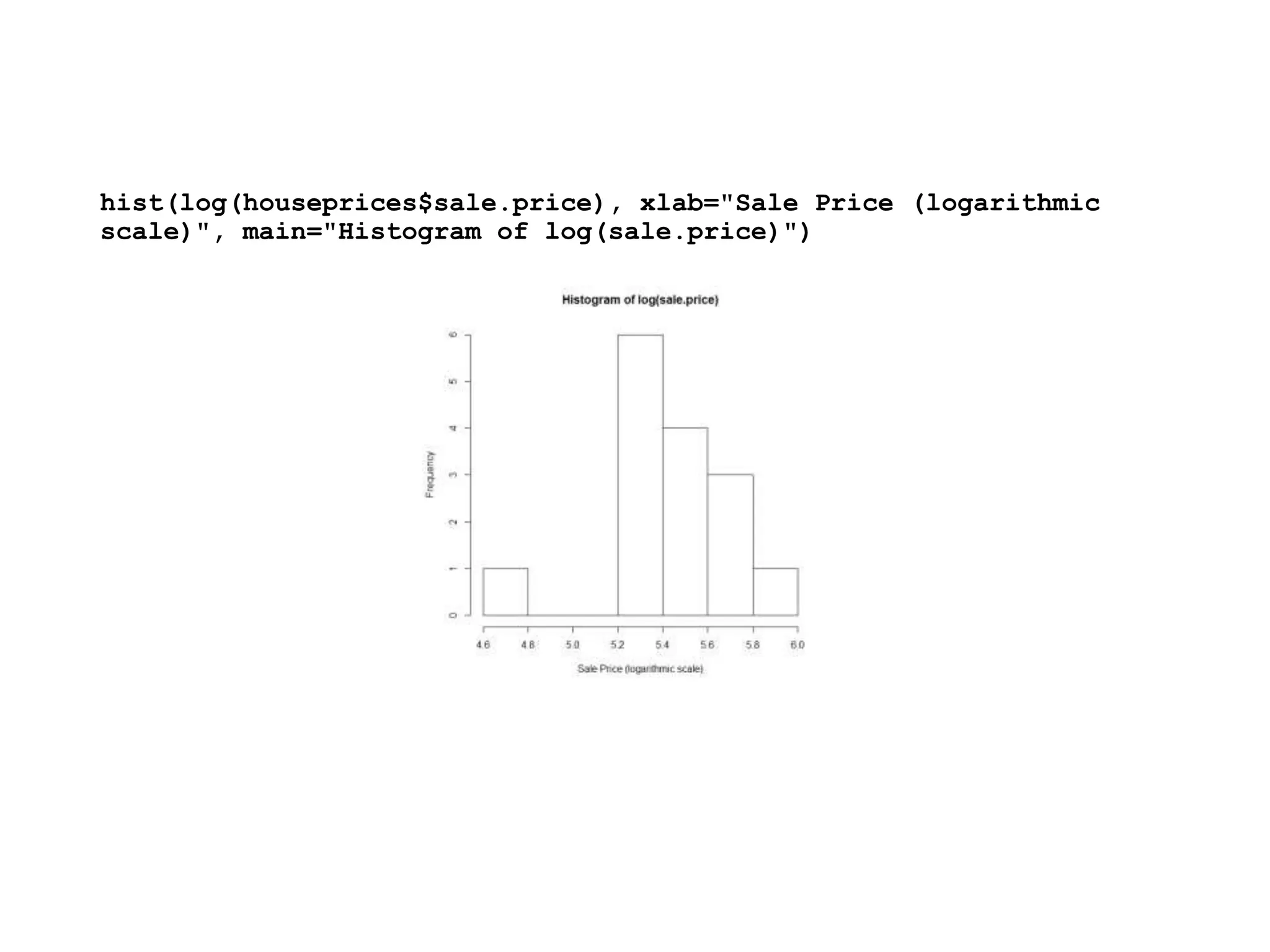
![> houseprices$bedrooms=as.factor(houseprices[,2])
> summary(houseprices)
area bedrooms sale.price
Min. : 694.0 4:11 Min. :112.7
1st Qu.: 743.5 5: 3 1st Qu.:213.5
Median : 821.0 6: 1 Median :221.5
Mean : 889.3 Mean :237.7
3rd Qu.: 984.5 3rd Qu.:267.0
Max. :1366.0 Max. :375.0
plot(sale.price ~ area, data = houseprices, log = "y",pch = 16, xlab = "Floor
Area", ylab = "Sale Price", main = "log(sale.price) vs area")](https://image.slidesharecdn.com/statisticallearningandmodelselection1-240201045511-6e14a9b7/75/Statistical-Learning-and-Model-Selection-1-pptx-40-2048.jpg)
![> #Split row numbers randomly into 3 groups
> rand<- sample(1:15)%%3 + 1
> # a%%3 is a remainder of a modulo 3
> #Subtract from a the largest multiple of 3 that is <= a; take
remainder
> (1:15)[rand == 1] # Observation numbers from the first group
[1] 2 3 5 7 12
> (1:15)[rand == 2] # Observation numbers from the second group
[1] 4 8 9 11 14
> (1:15)[rand == 3] # Observation numbers from the third group
[1] 1 6 10 13 15](https://image.slidesharecdn.com/statisticallearningandmodelselection1-240201045511-6e14a9b7/75/Statistical-Learning-and-Model-Selection-1-pptx-42-2048.jpg)














































![Module_-_3_Product_Mgt_&_Pricing[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/module-3productmgtpricing1-240418034836-e464c428-thumbnail.jpg?width=640&height=640&fit=bounds)





![R basics for MBA Students[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/rbasicsformbastudents1-240213044033-aee3b8d3-thumbnail.jpg?width=640&height=640&fit=bounds)






















