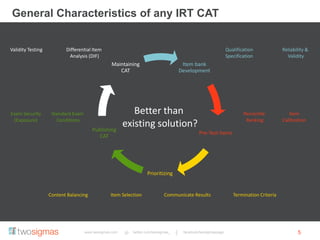
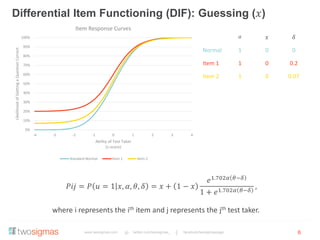
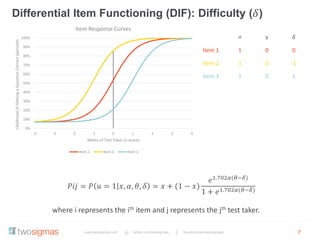
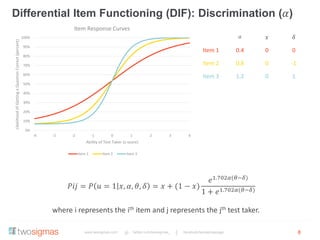
The document discusses the advantages of an Item Response Theory (IRT) based Computer Adaptive Testing (CAT) system, outlining considerations such as item bank development, test fairness, reliability, and validity. It highlights the importance of differential item functioning analysis and provides references for further reading on assessment methodologies. Additionally, it identifies potential markets for adaptive testing solutions, such as educational institutions, corporations, and government organizations.