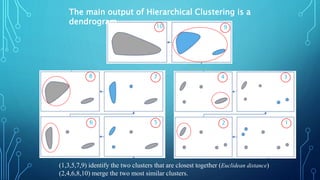
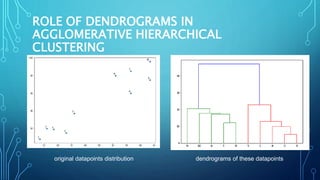
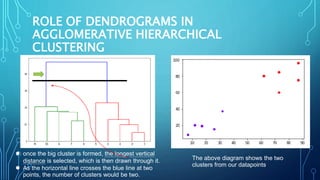
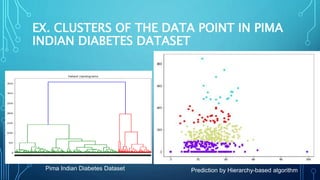
This document discusses hierarchical clustering algorithms. It describes hierarchical clustering as a method that forms clusters based on a hierarchical (tree-like) structure, with new clusters being formed from previously established clusters. There are two main approaches: agglomerative, which is a bottom-up approach that treats each data point as an individual cluster initially, and divisive, which is a top-down approach that treats all data points as one cluster initially. The document provides examples of hierarchical clustering algorithms and discusses key aspects like linkage criteria and interpreting dendrograms.