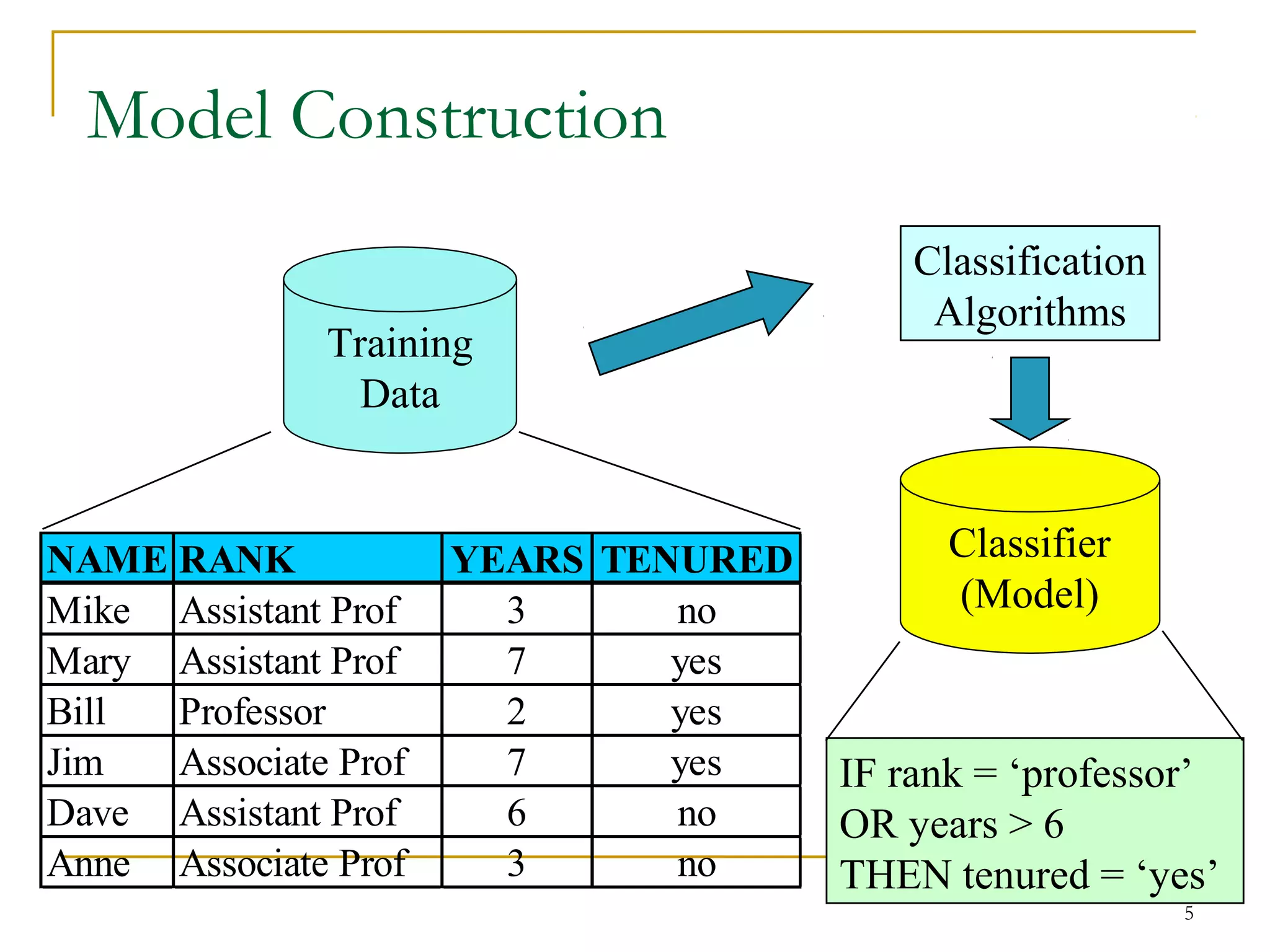
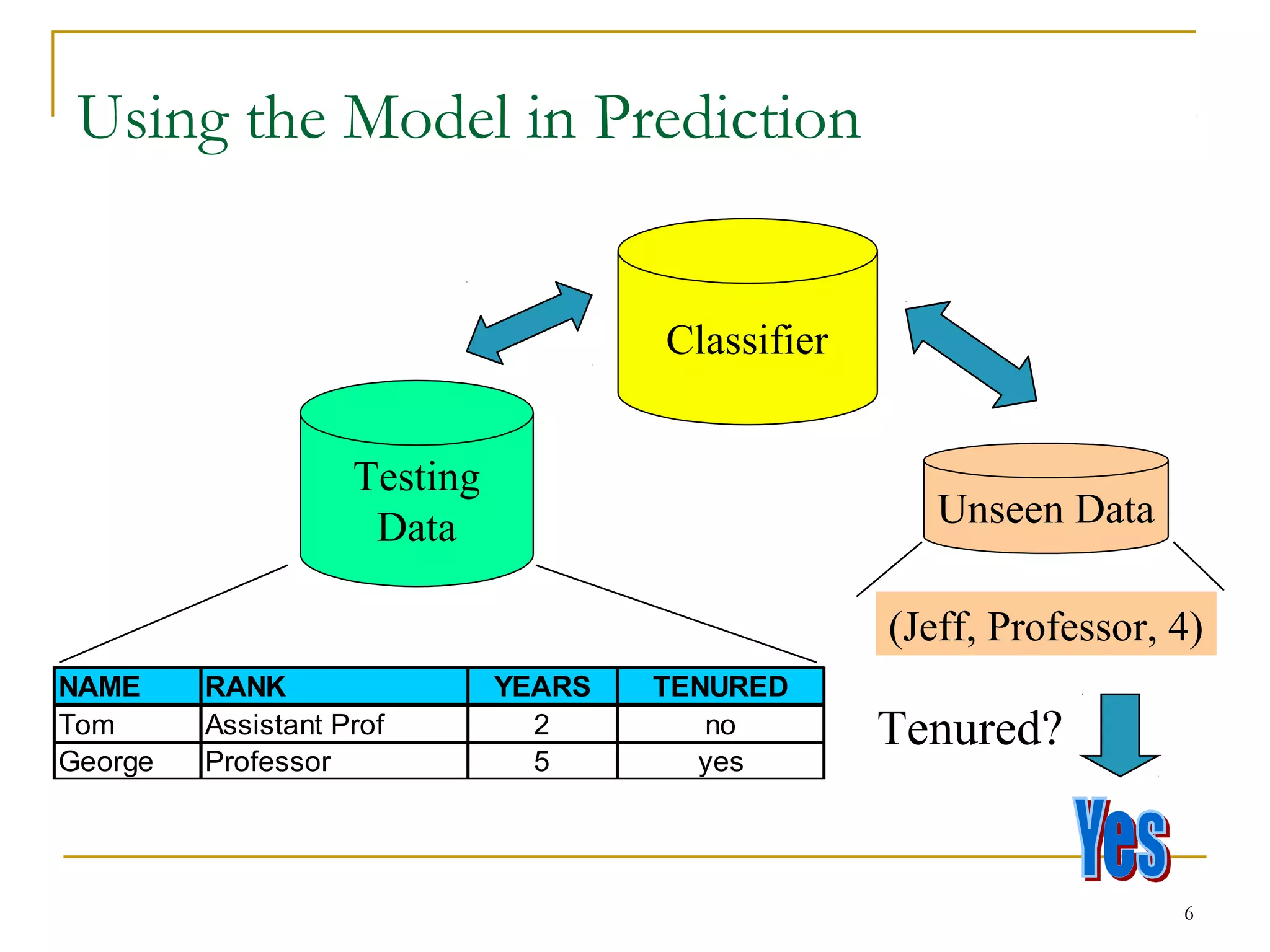
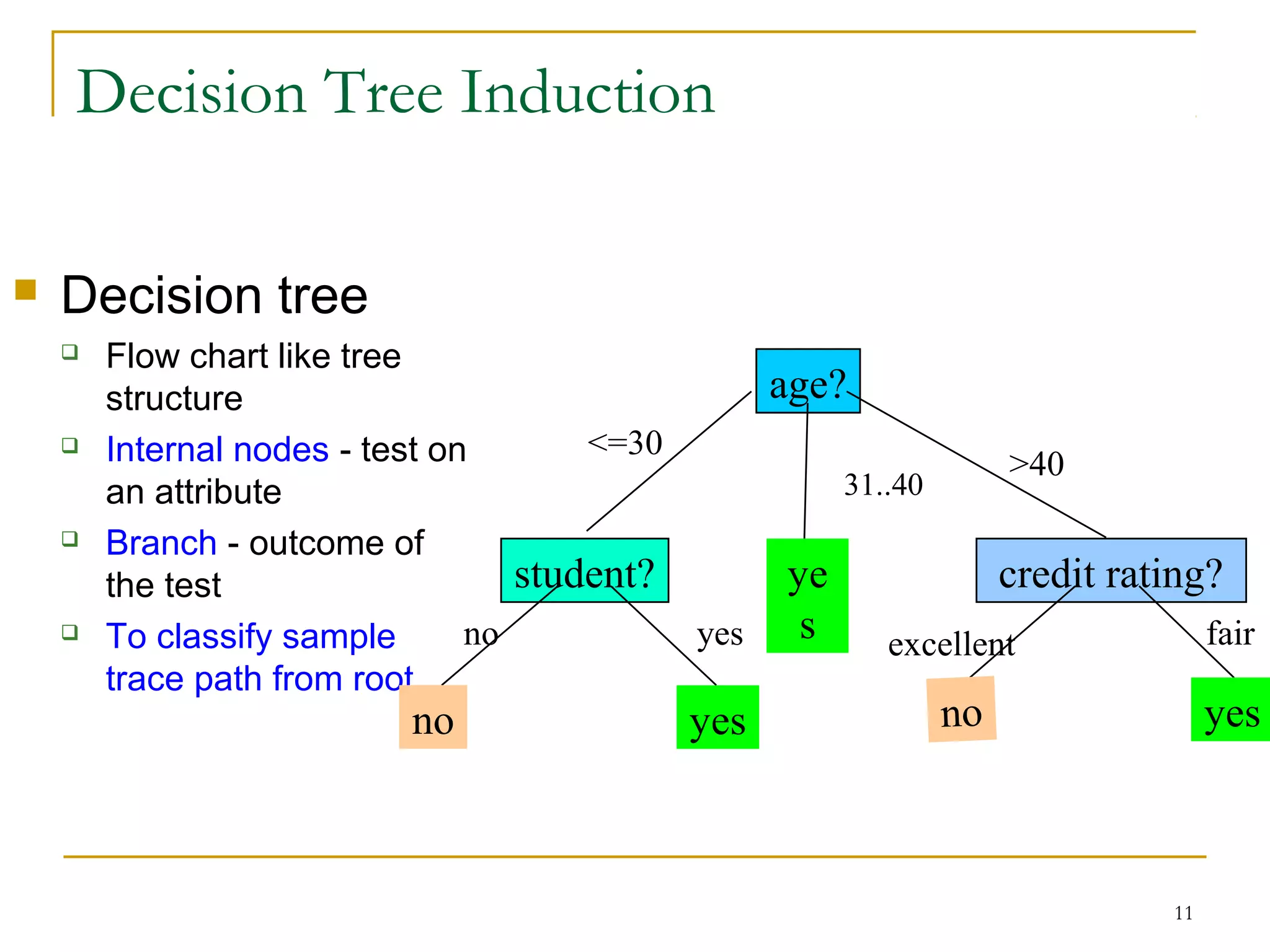
This document discusses classification and decision trees. It defines classification as predicting categorical class labels using a model constructed from a training set. Decision trees are a popular classification method that operate in a top-down recursive manner, splitting the data into purer subsets based on attribute values. The algorithm selects the optimal splitting attribute using an evaluation metric like information gain at each step until it reaches a leaf node containing only one class.