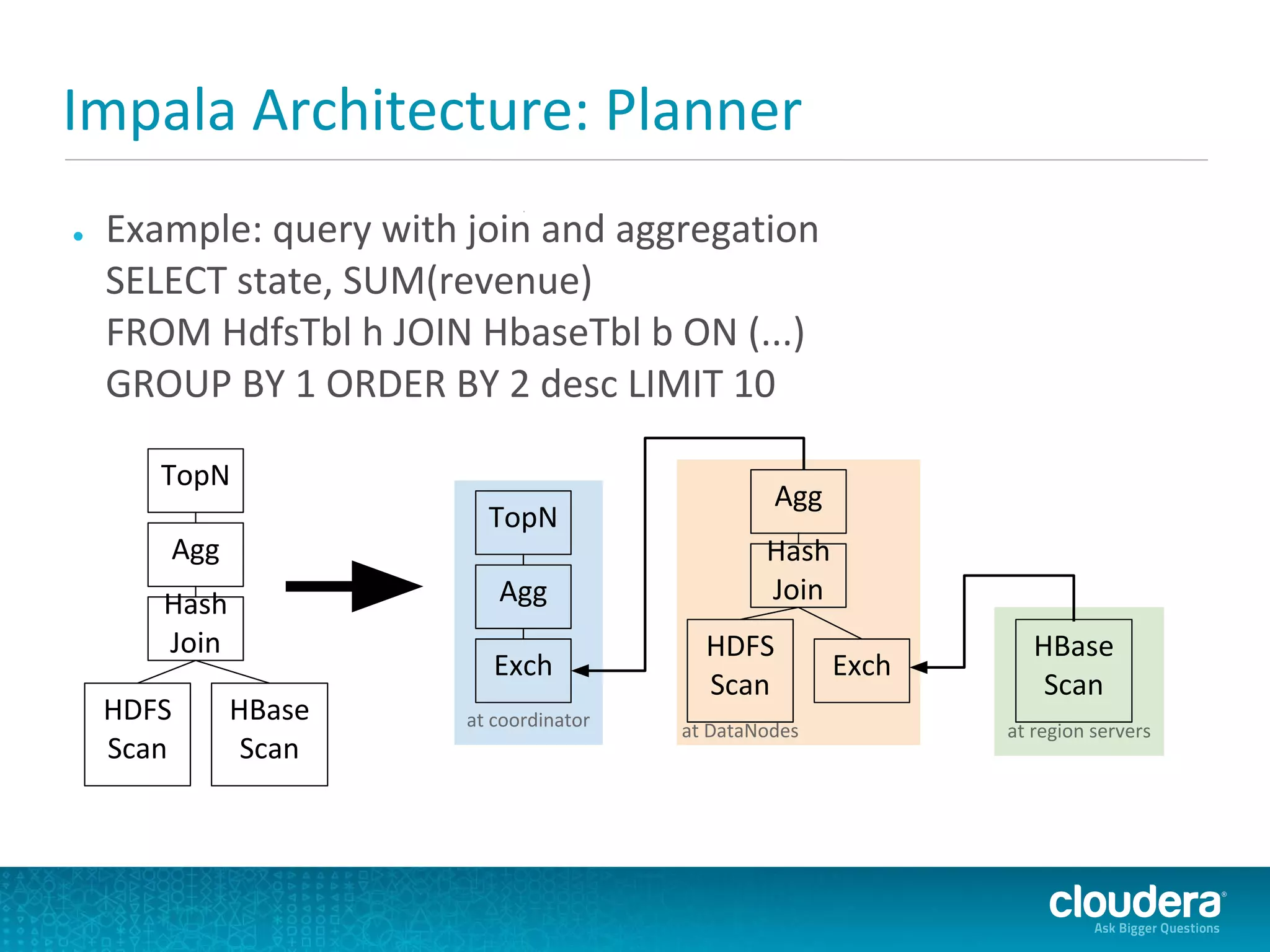
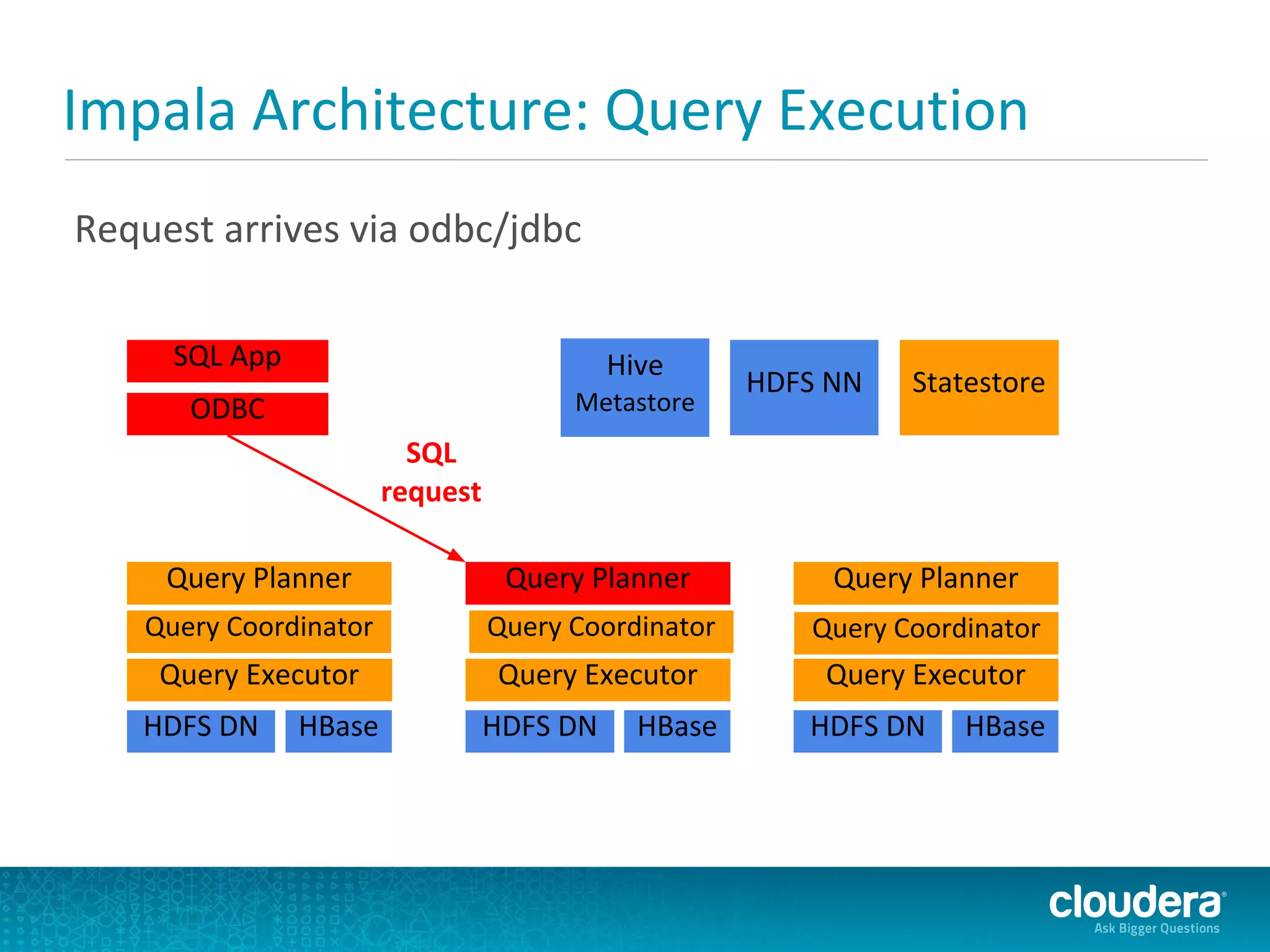
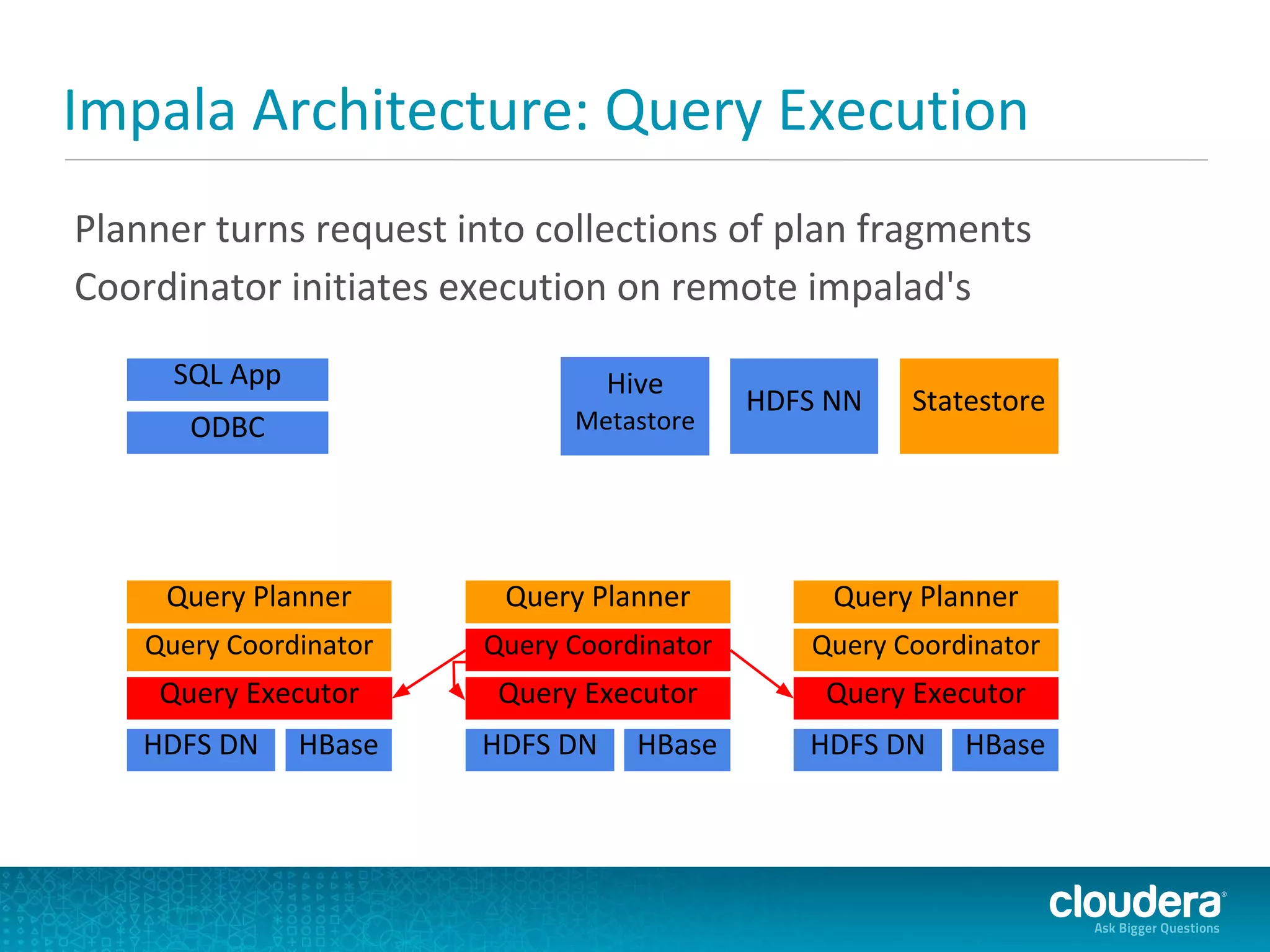
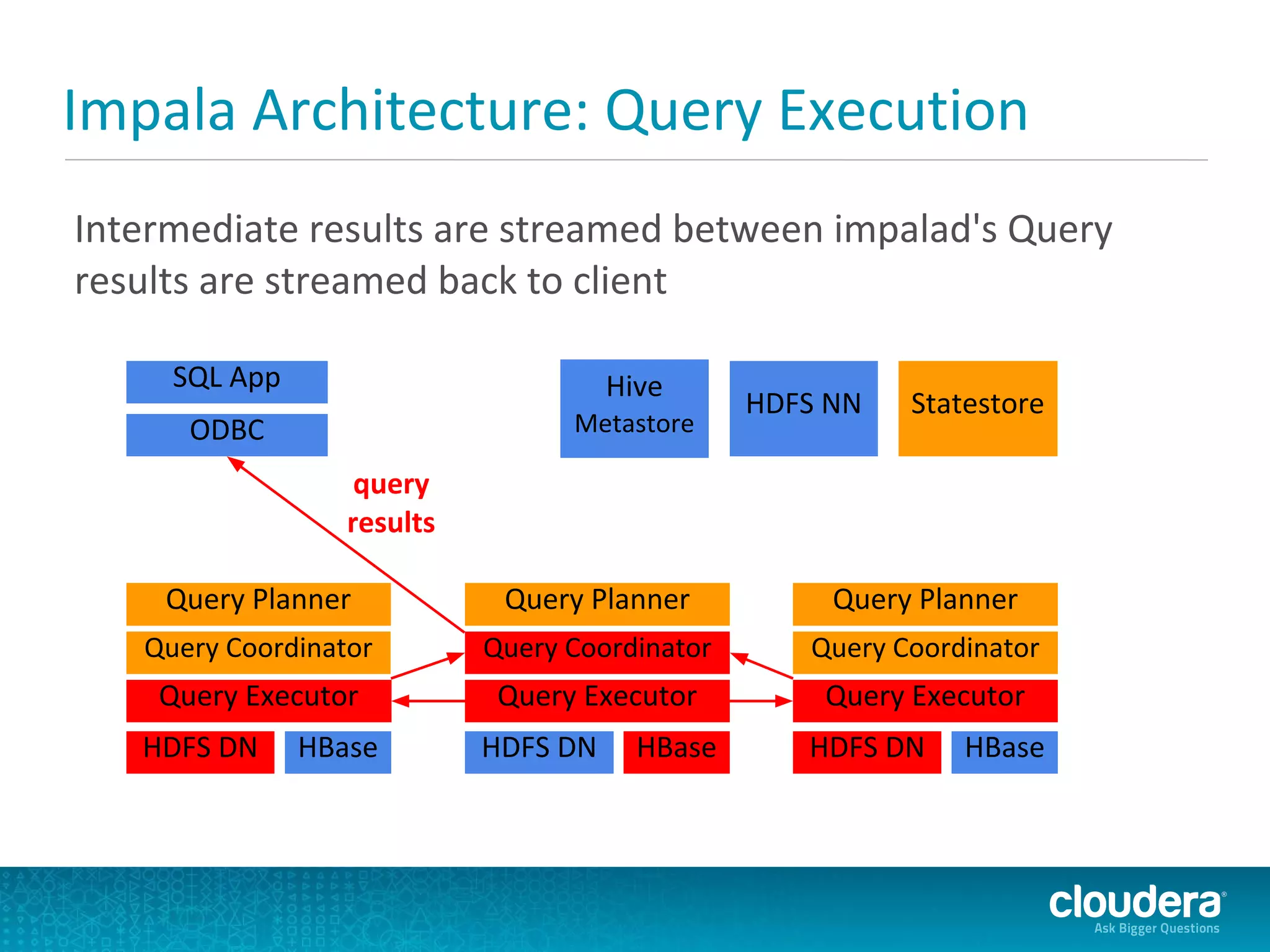
Cloudera Impala is a modern SQL engine for Apache Hadoop designed for real-time queries, with a beta version released in October 2012 and a general availability release expected in April 2013. It supports both analytical and transactional workloads, leveraging C++ for performance and an execution engine that runs directly within Hadoop. The architecture includes components for query execution, metadata handling through Hive's metastore, and comparisons with similar technologies like Dremel and Hive.