



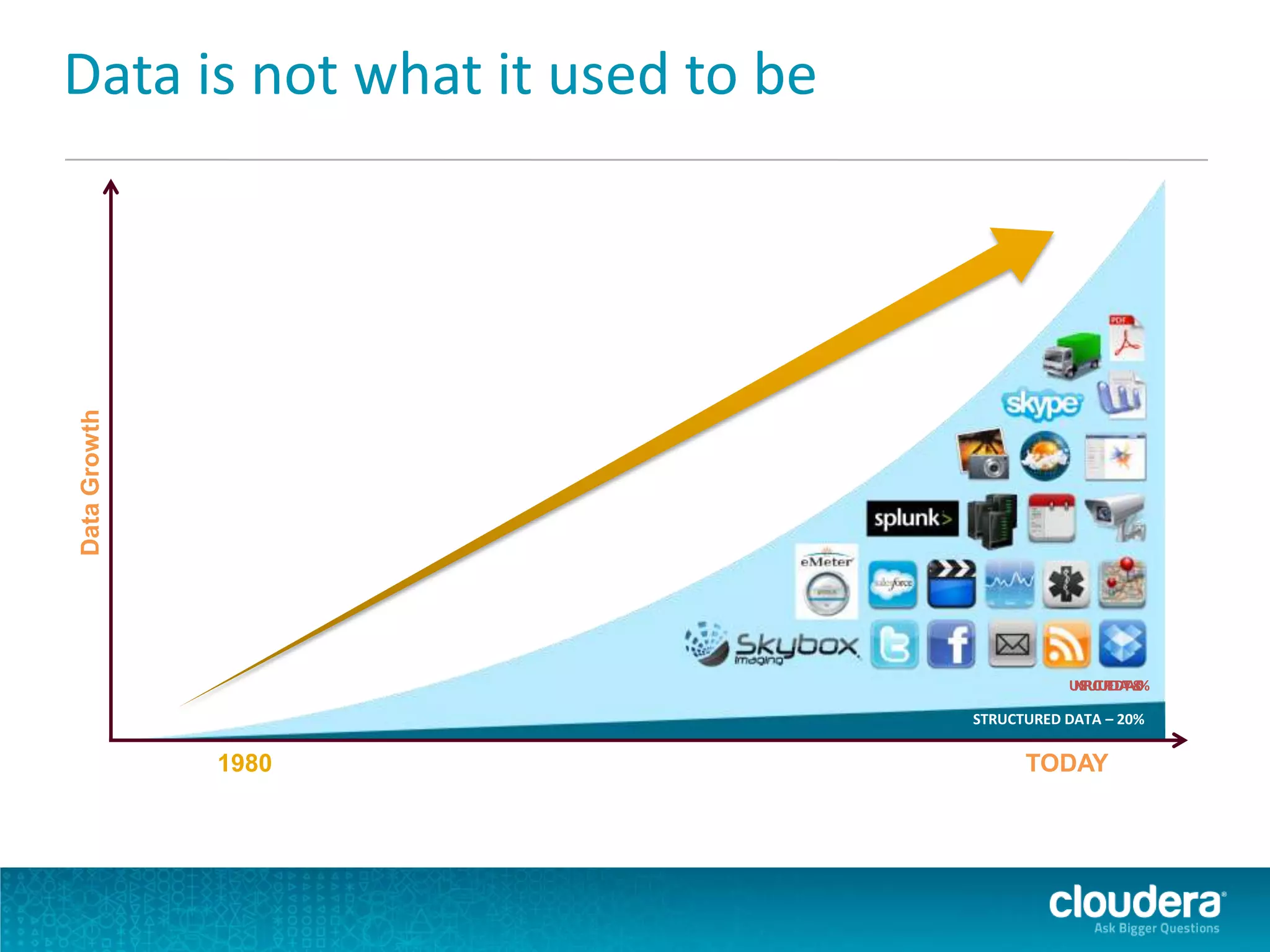















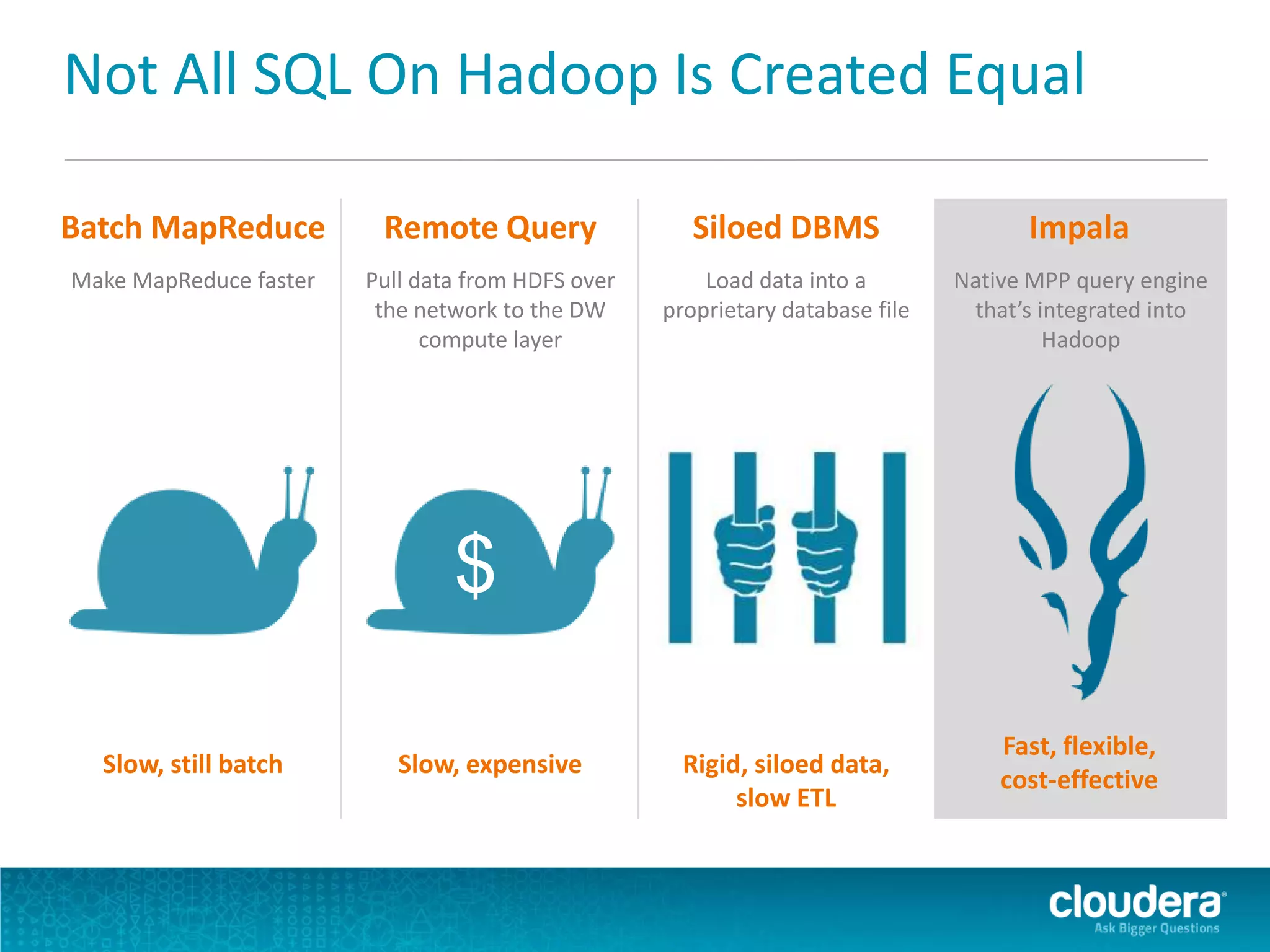
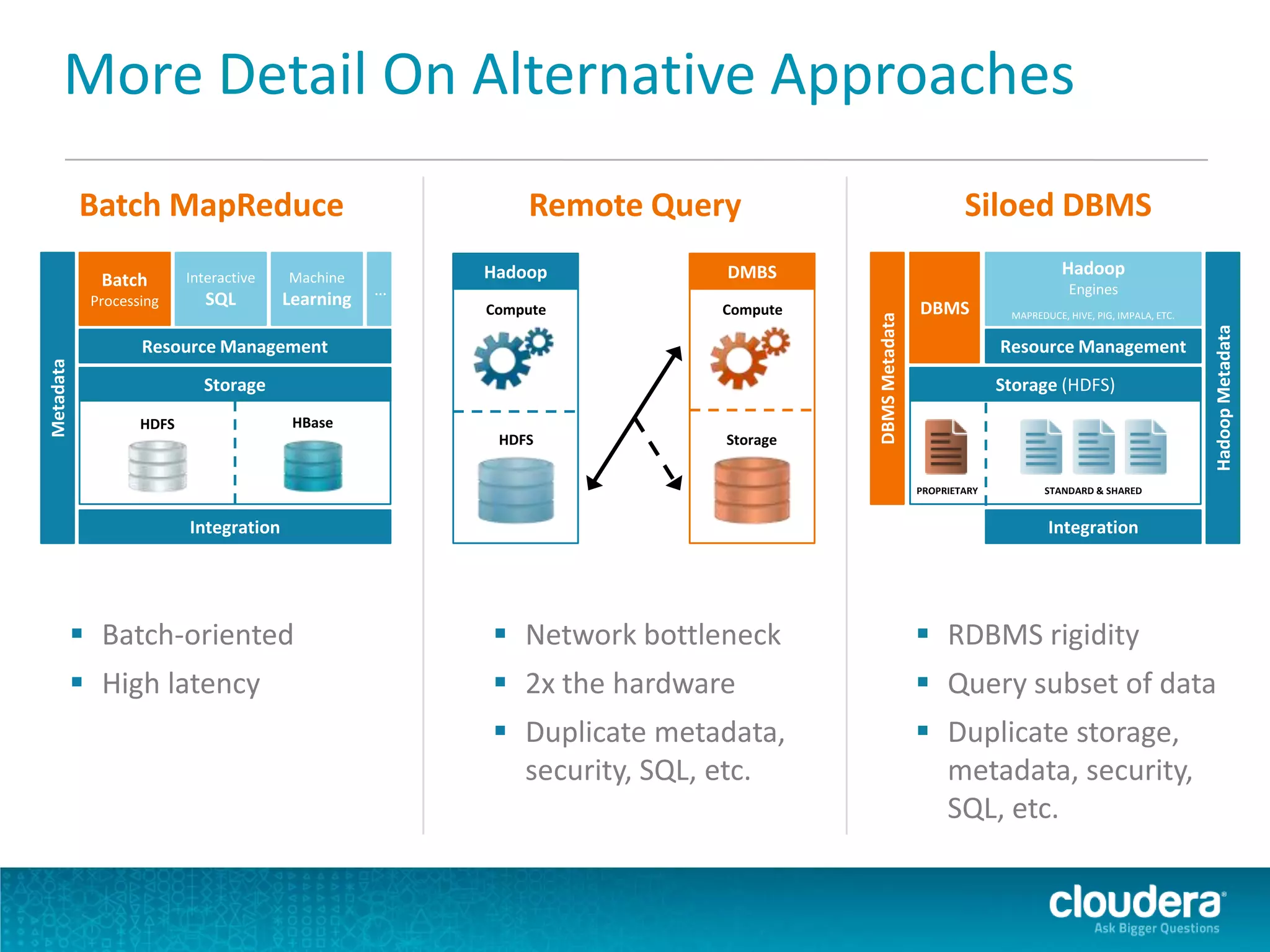







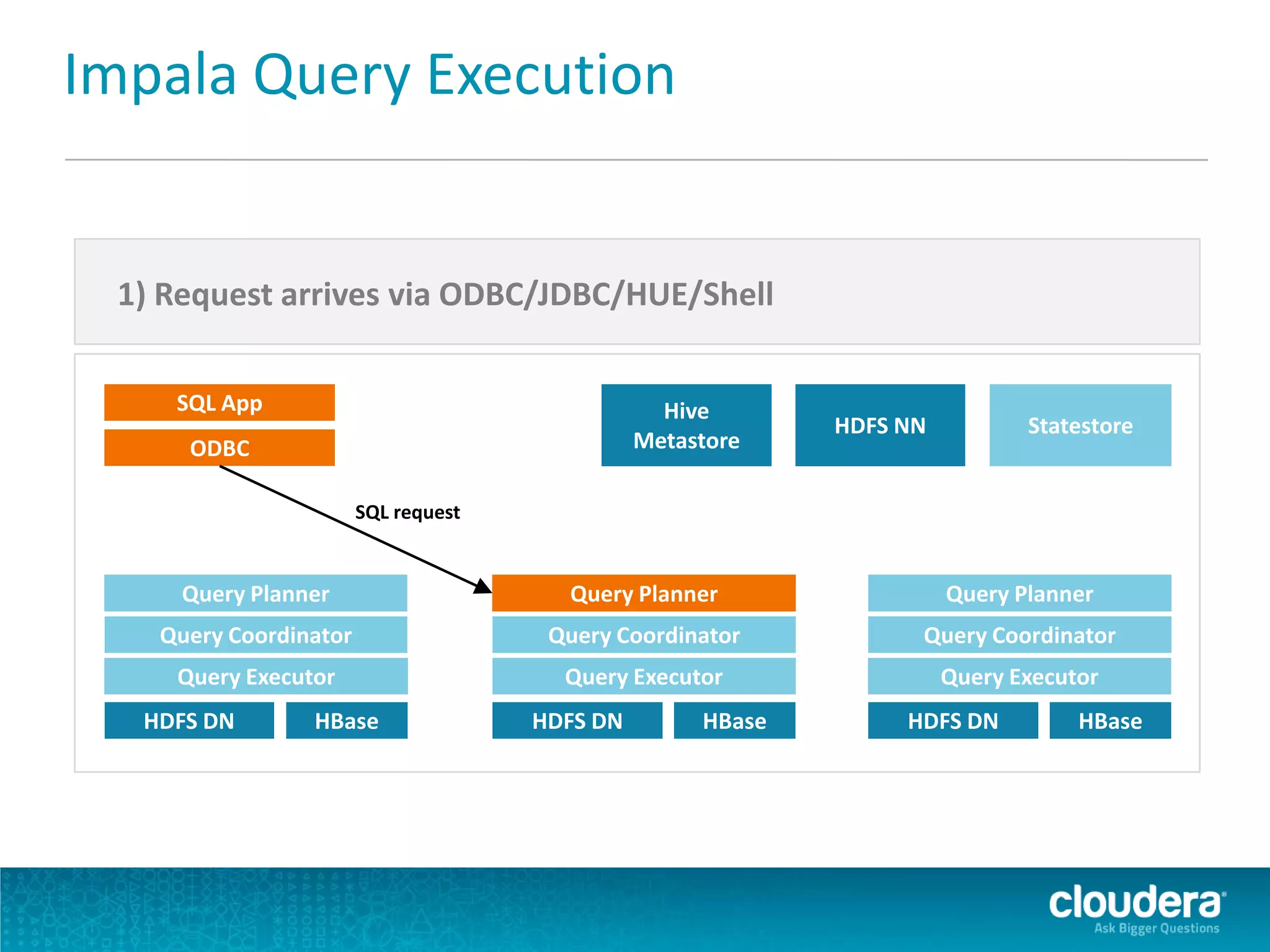
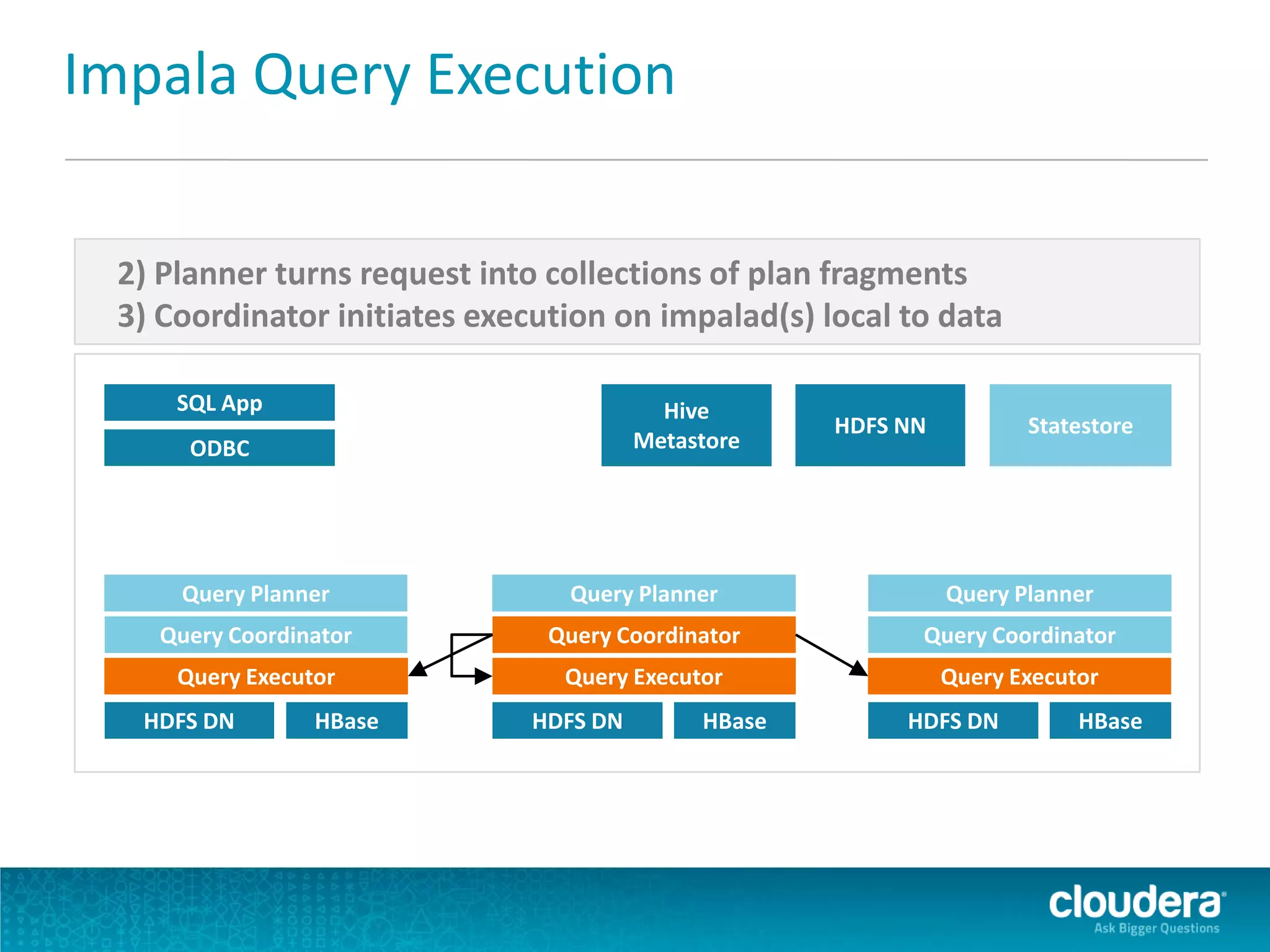
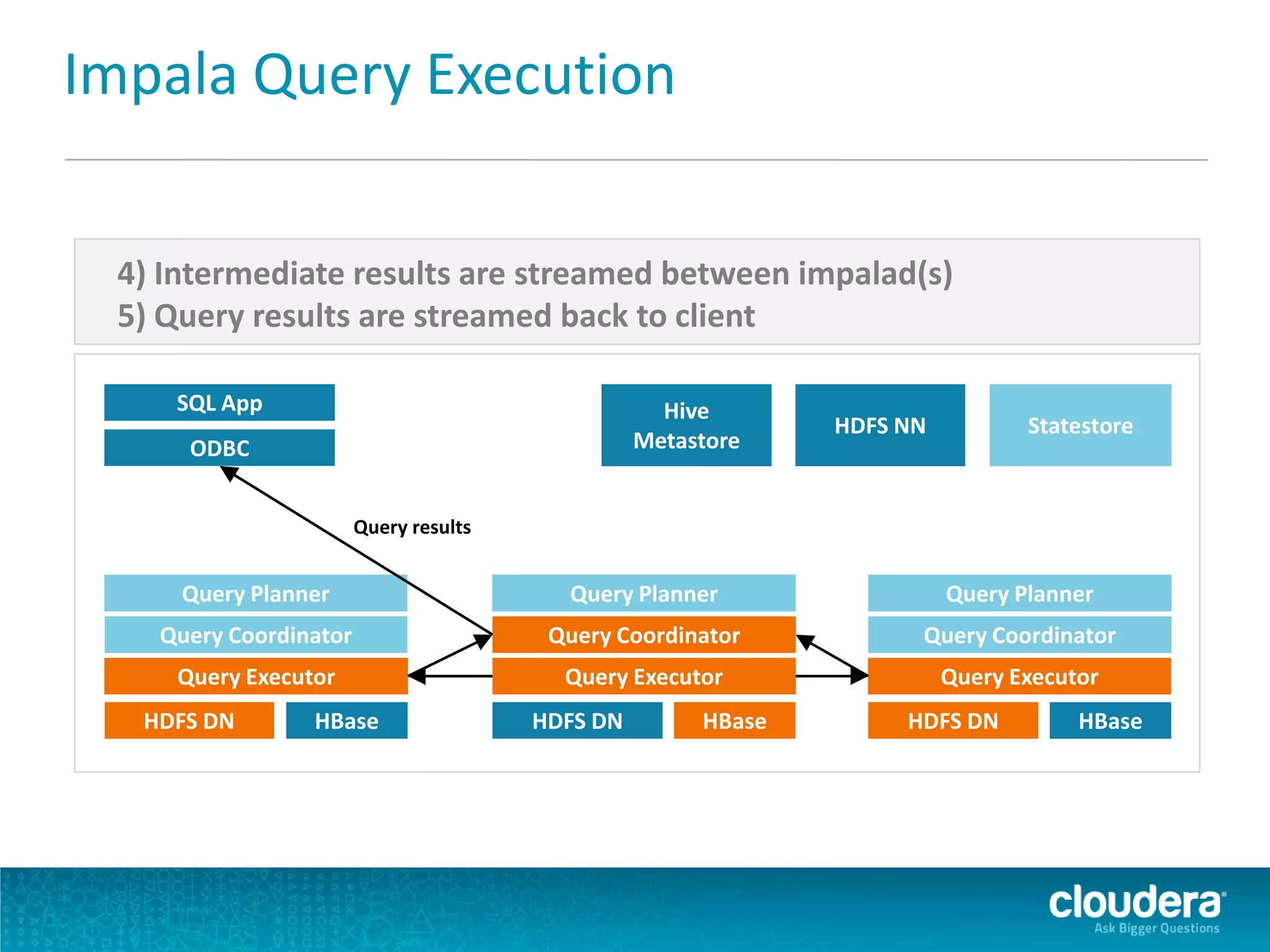



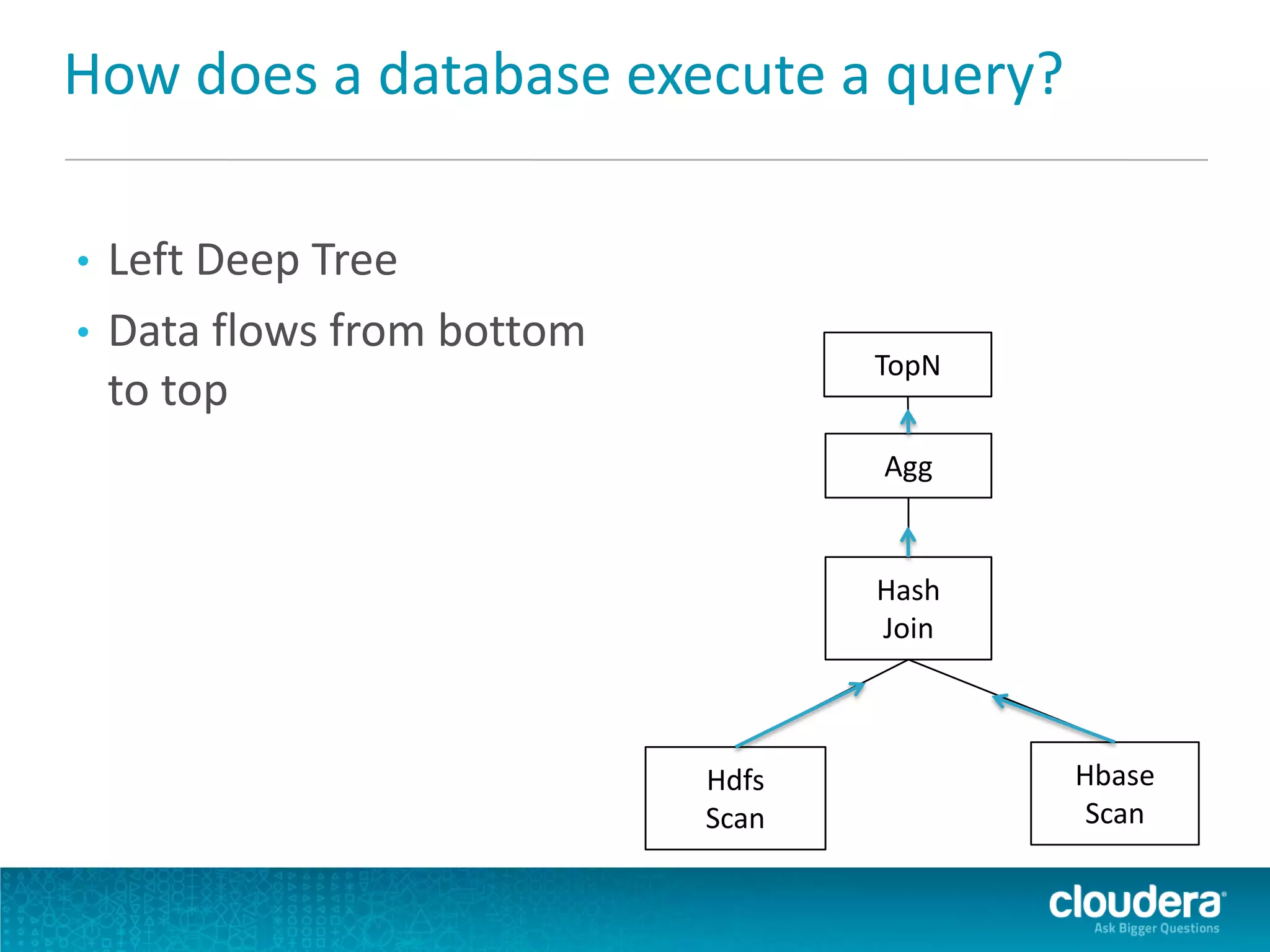

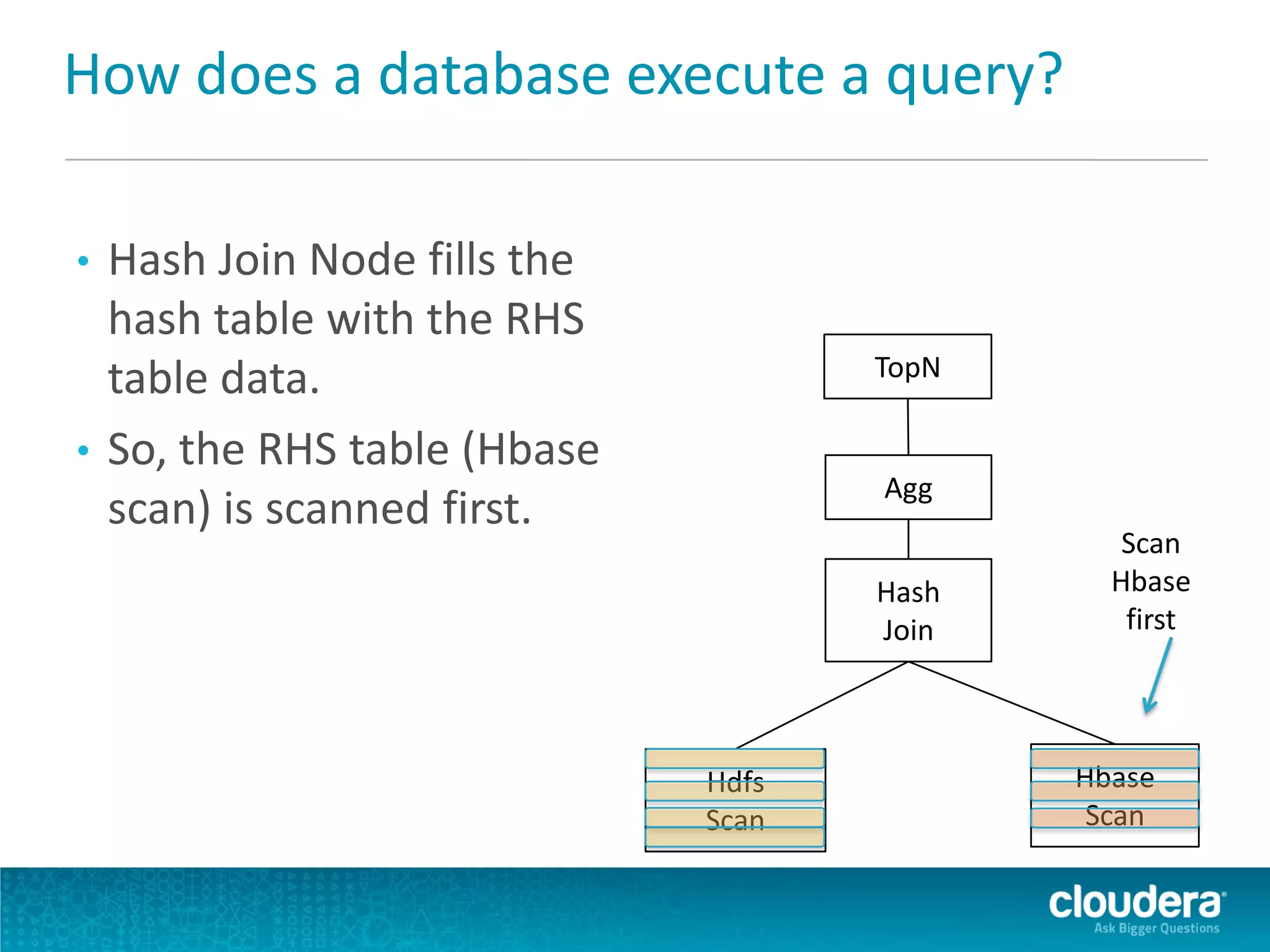

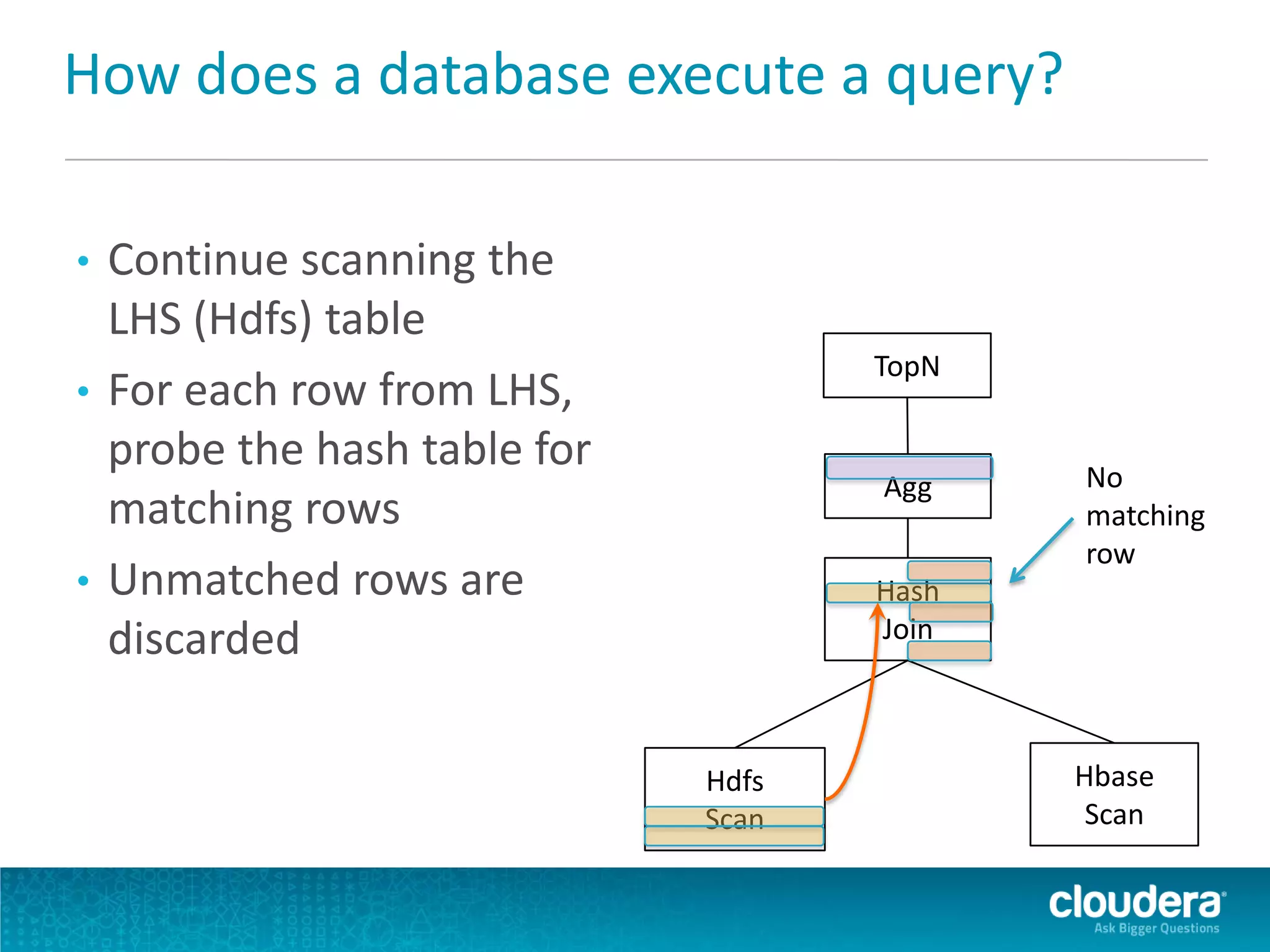
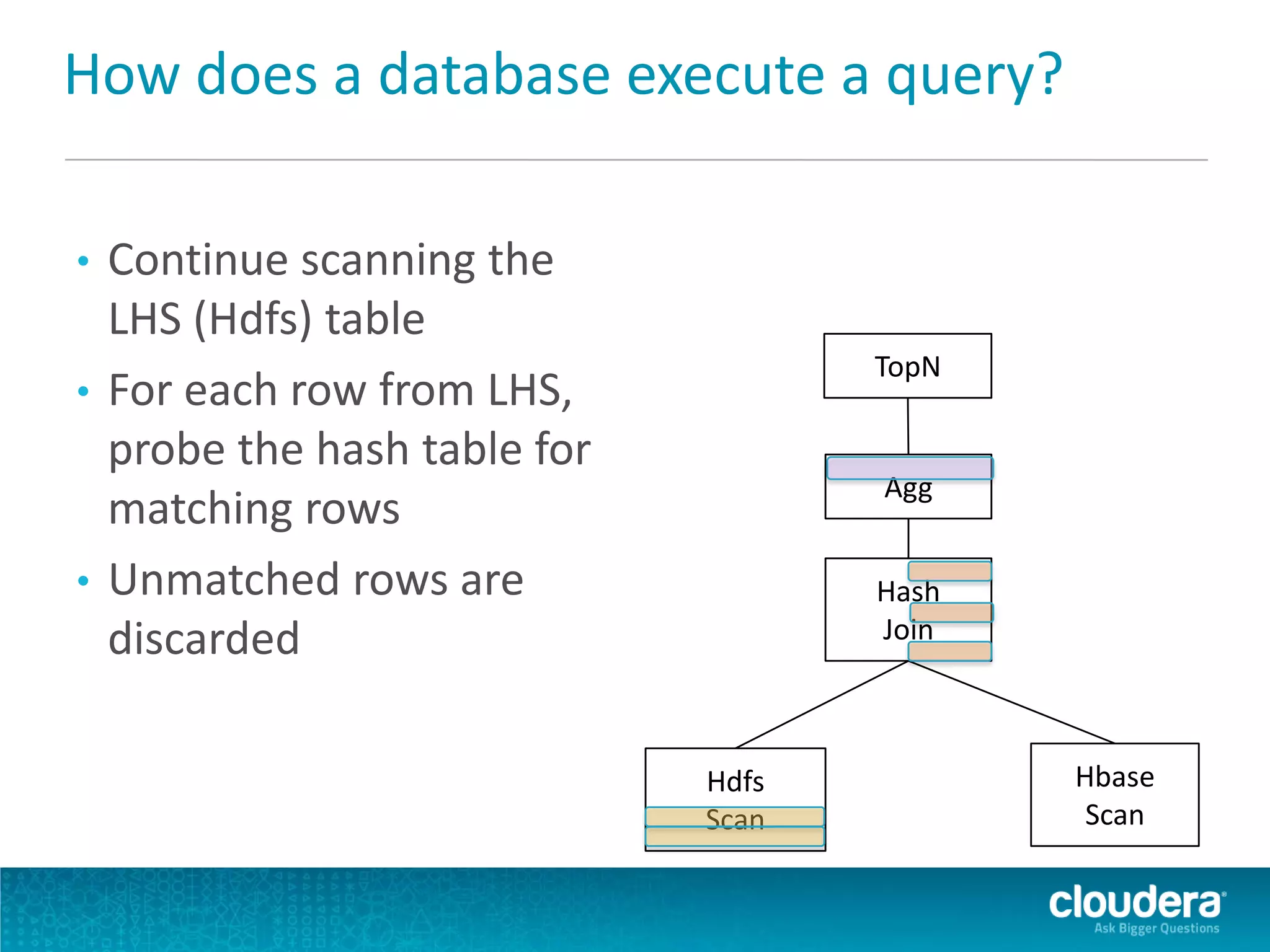
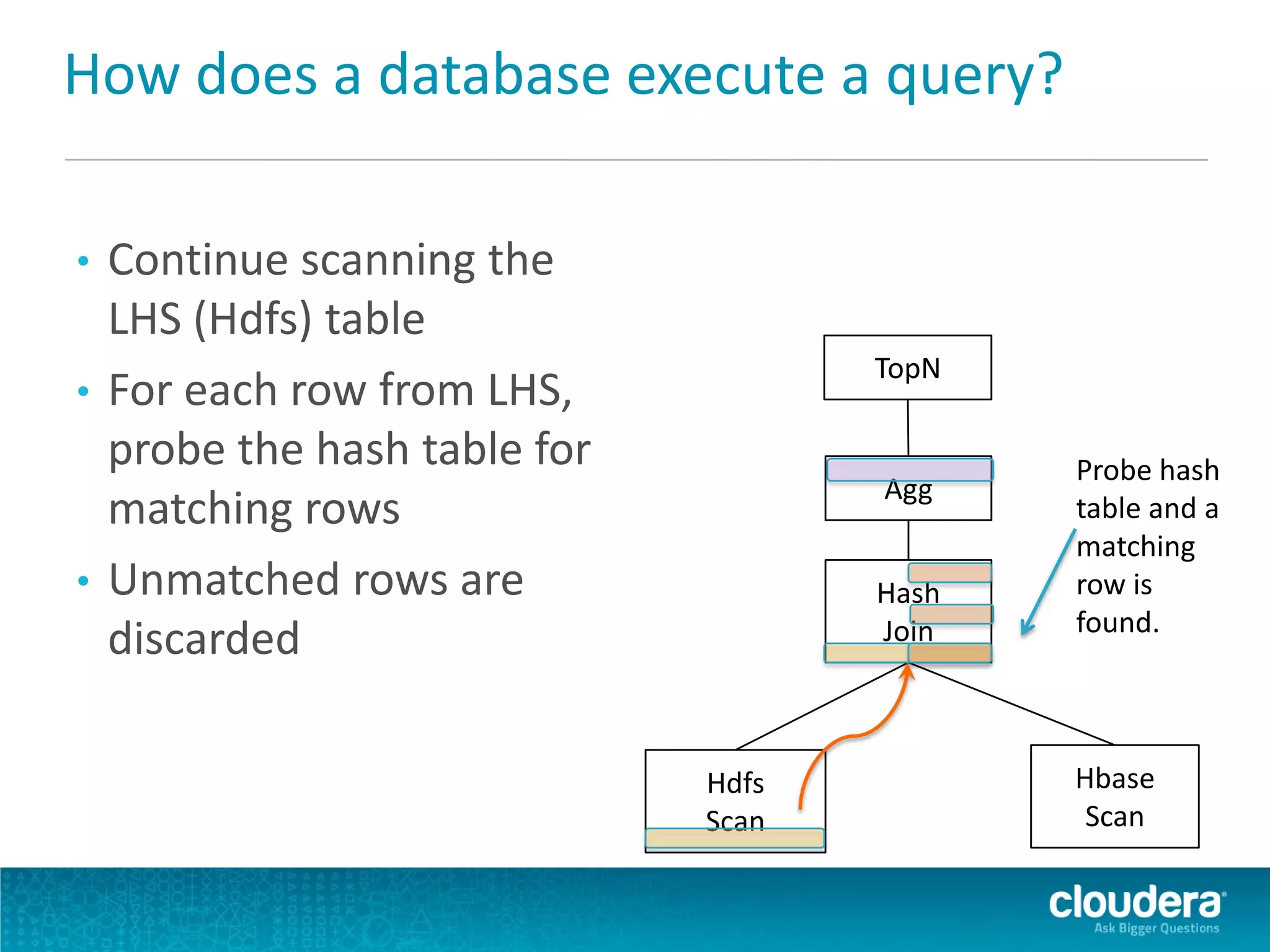
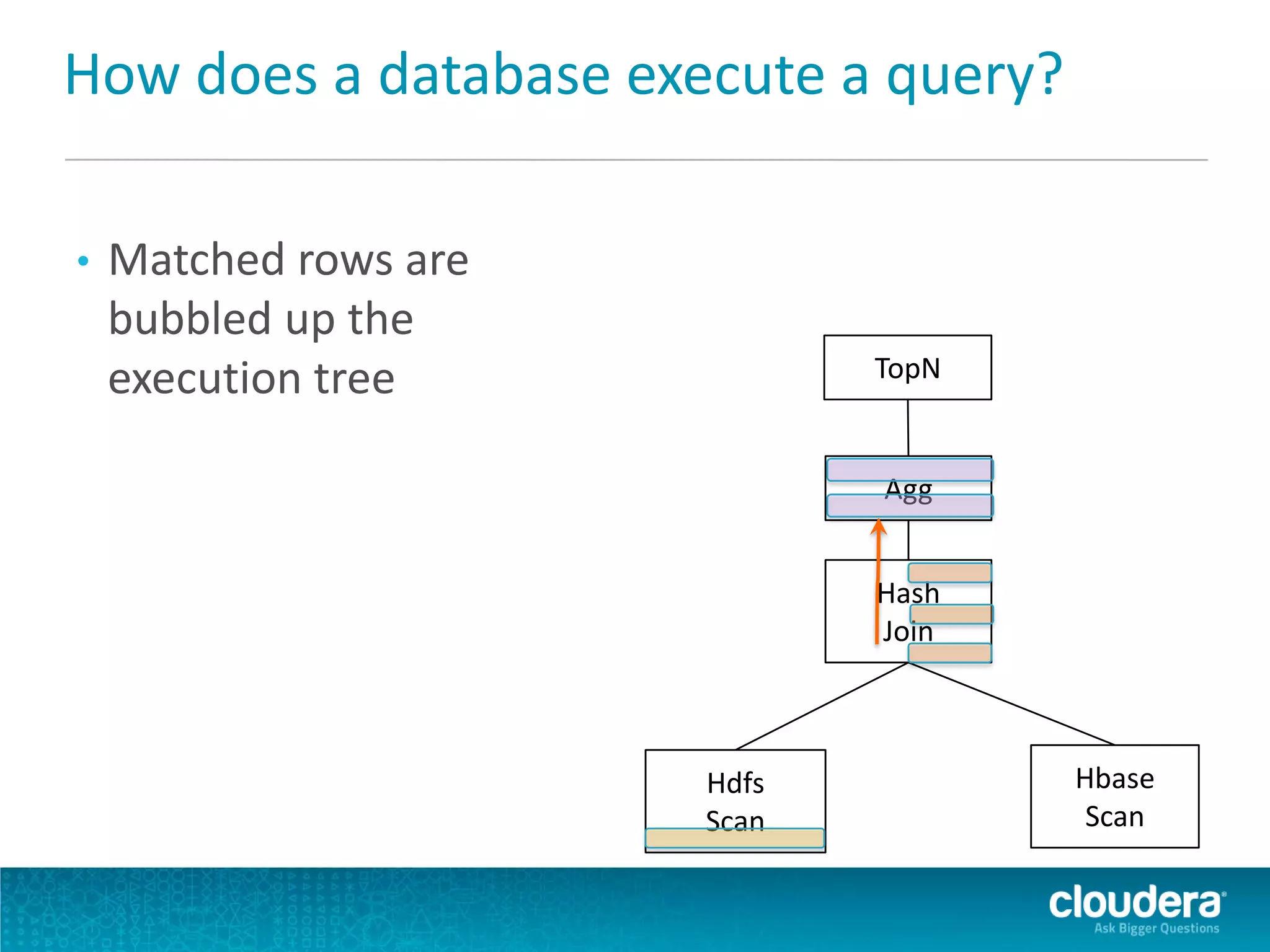
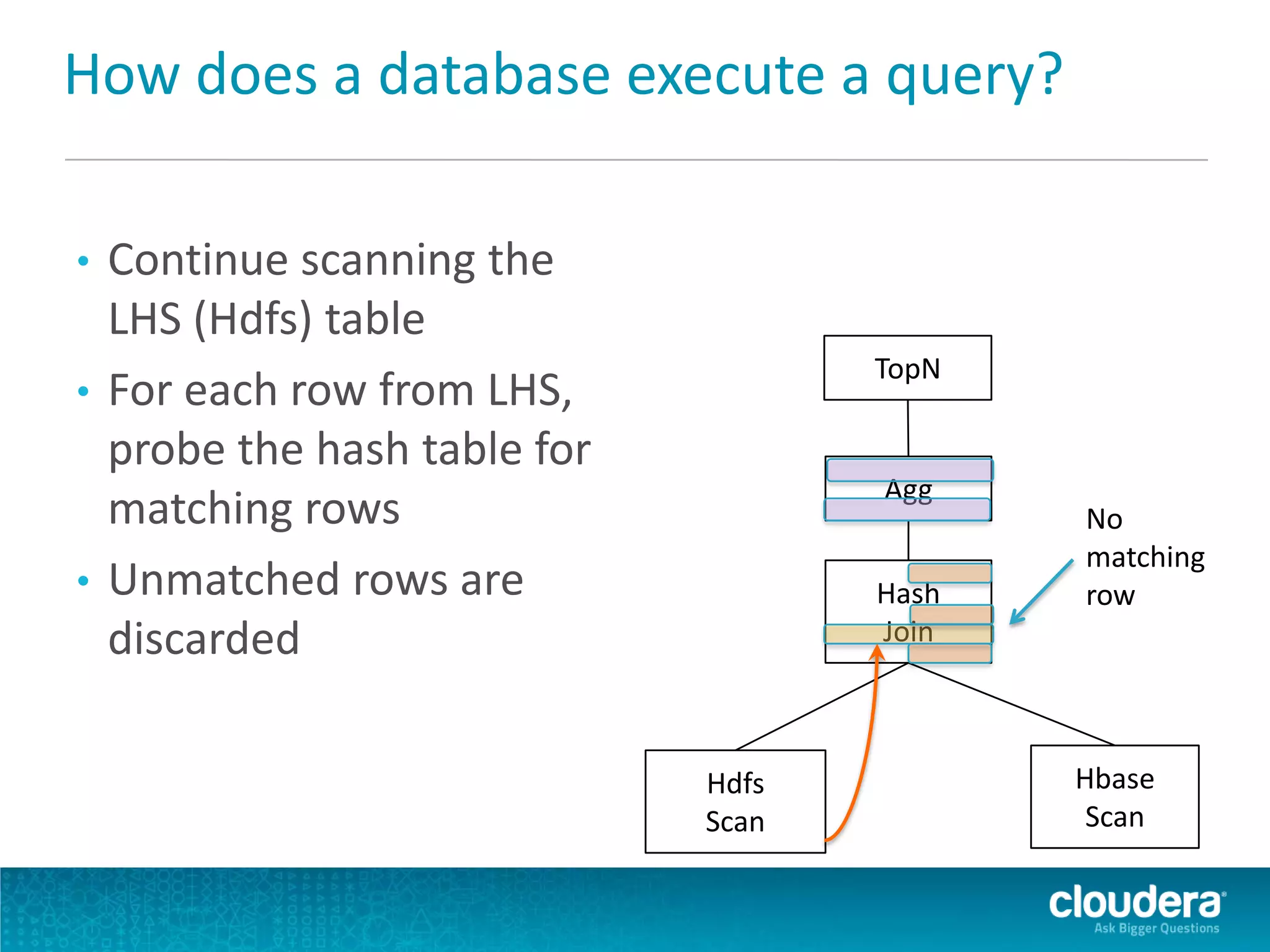
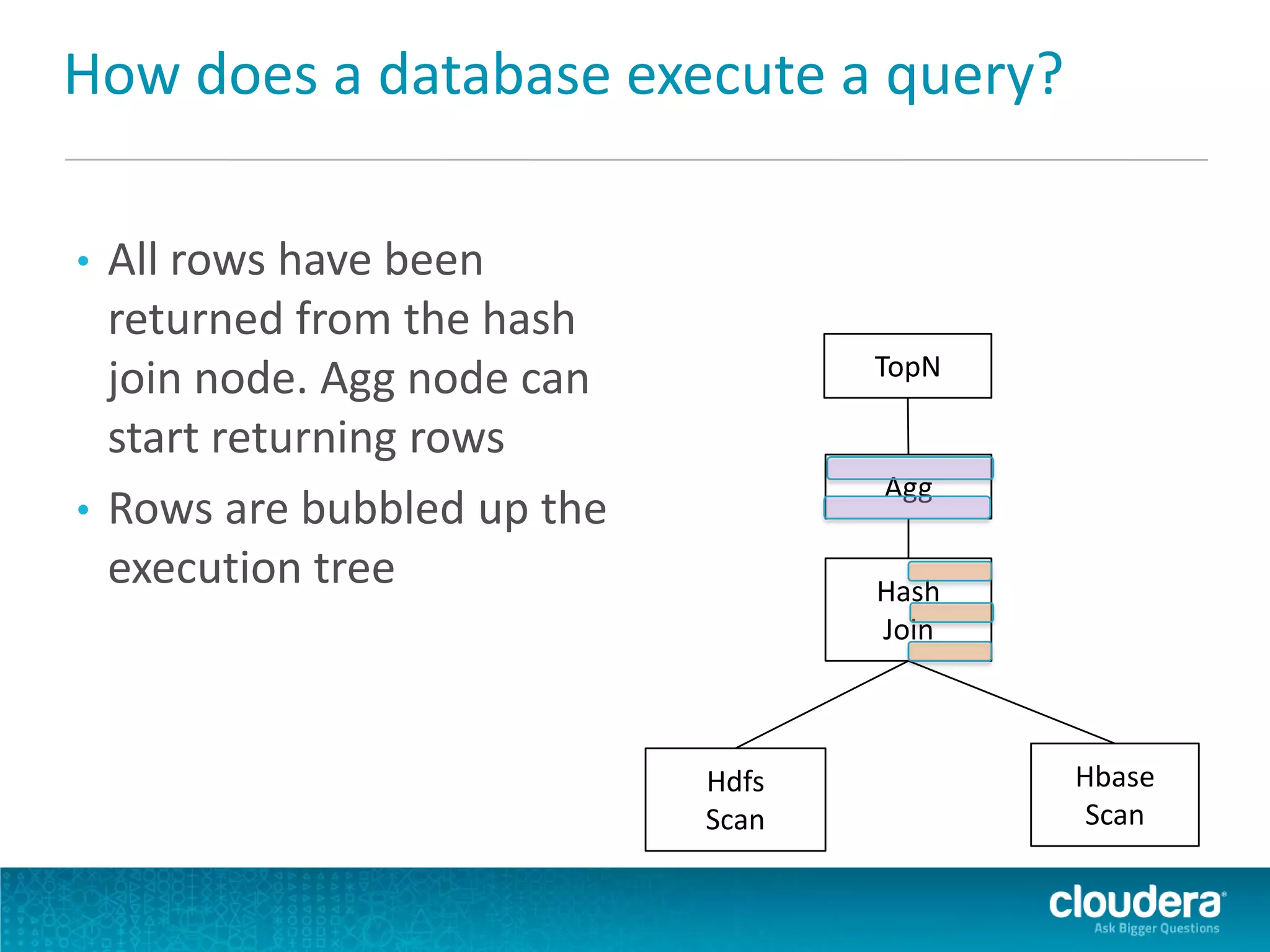
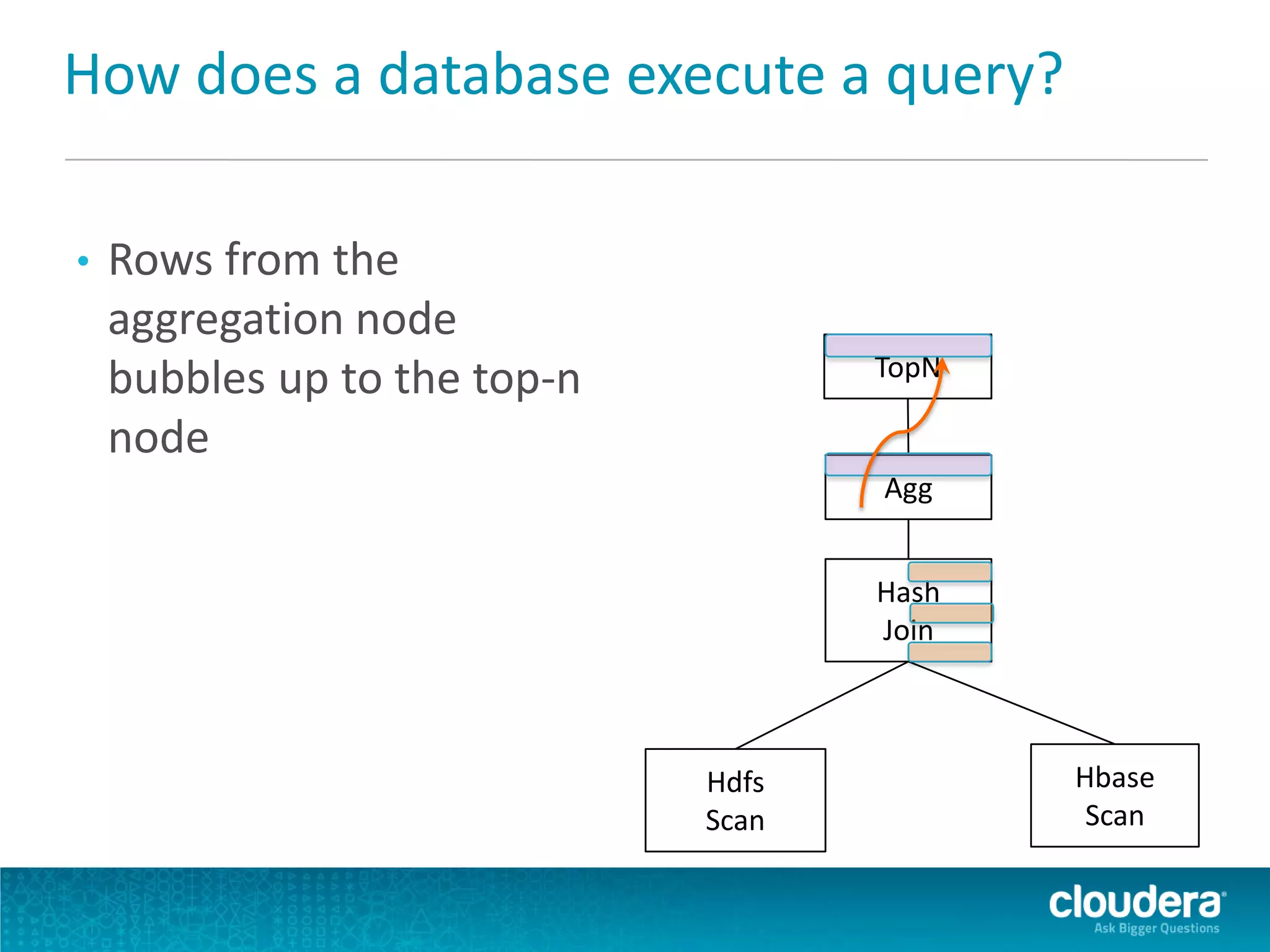
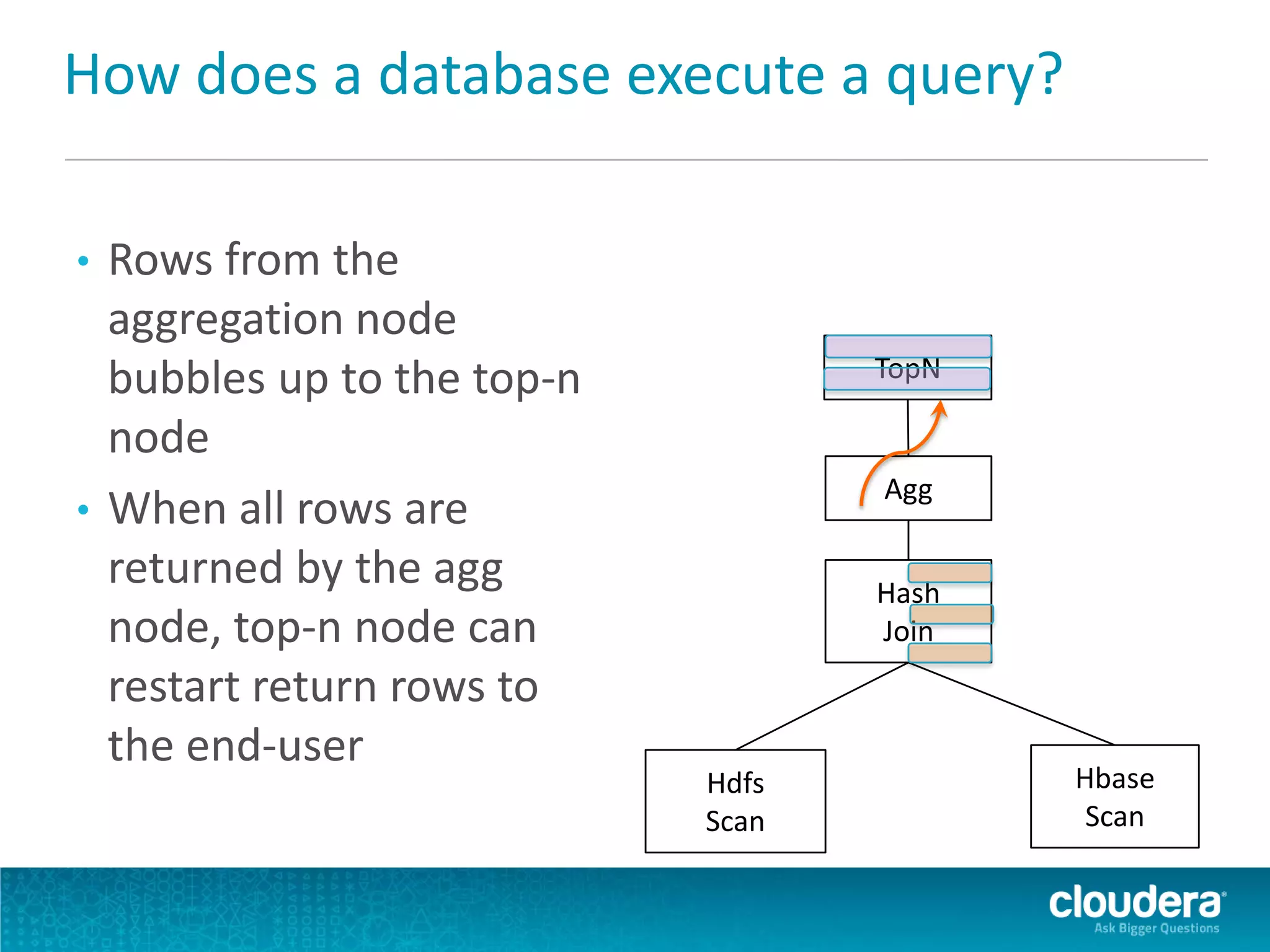


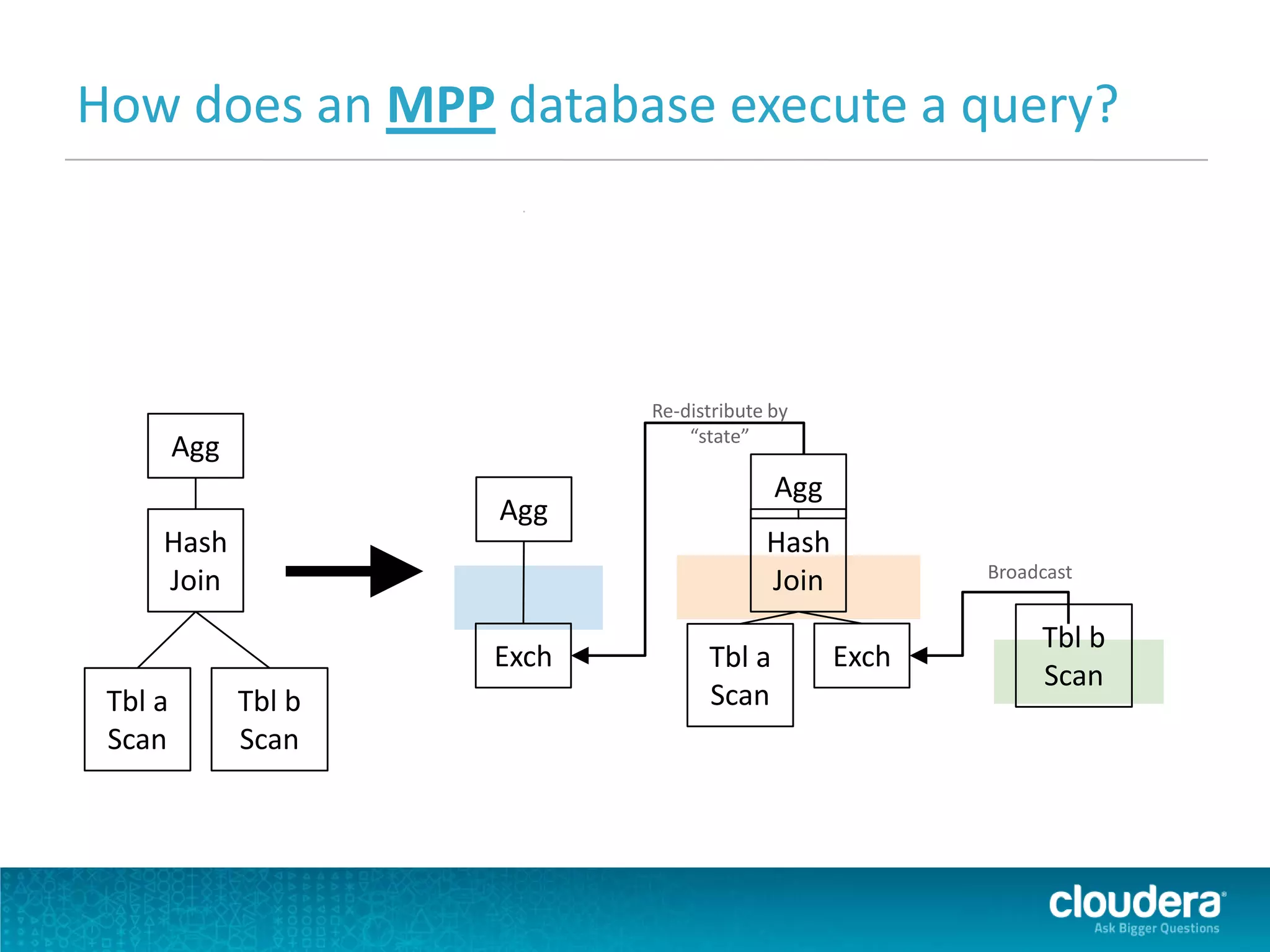
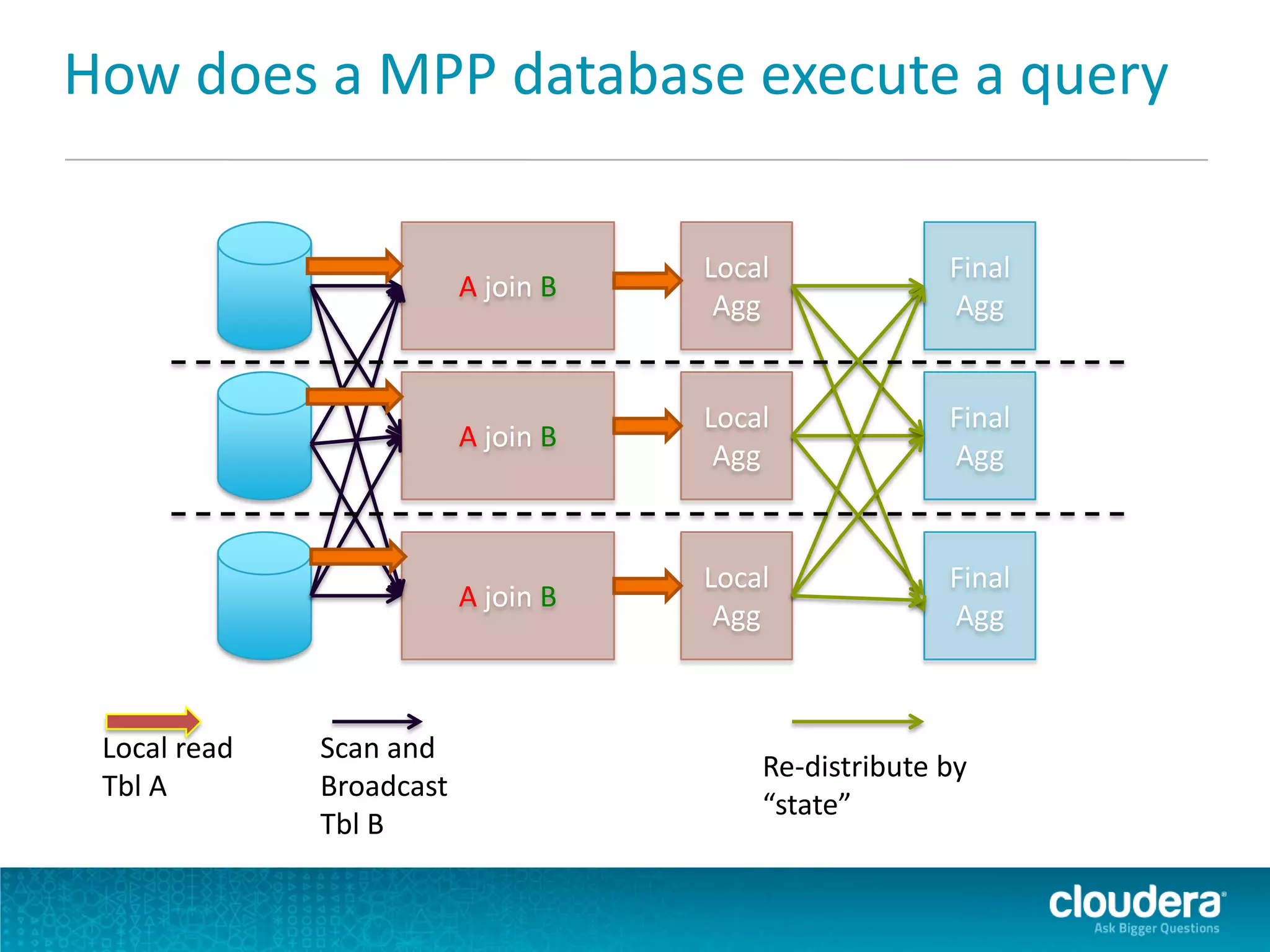


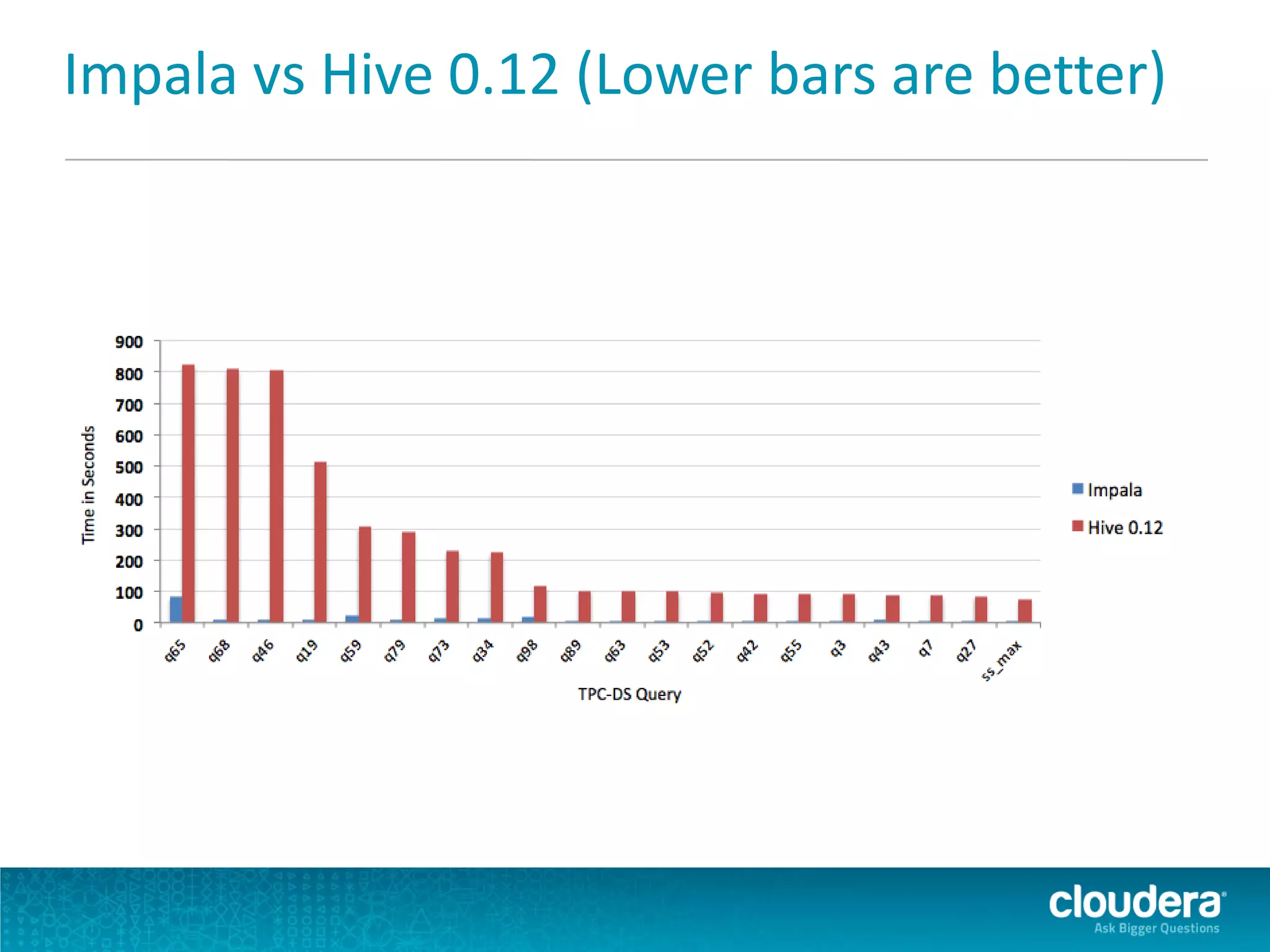
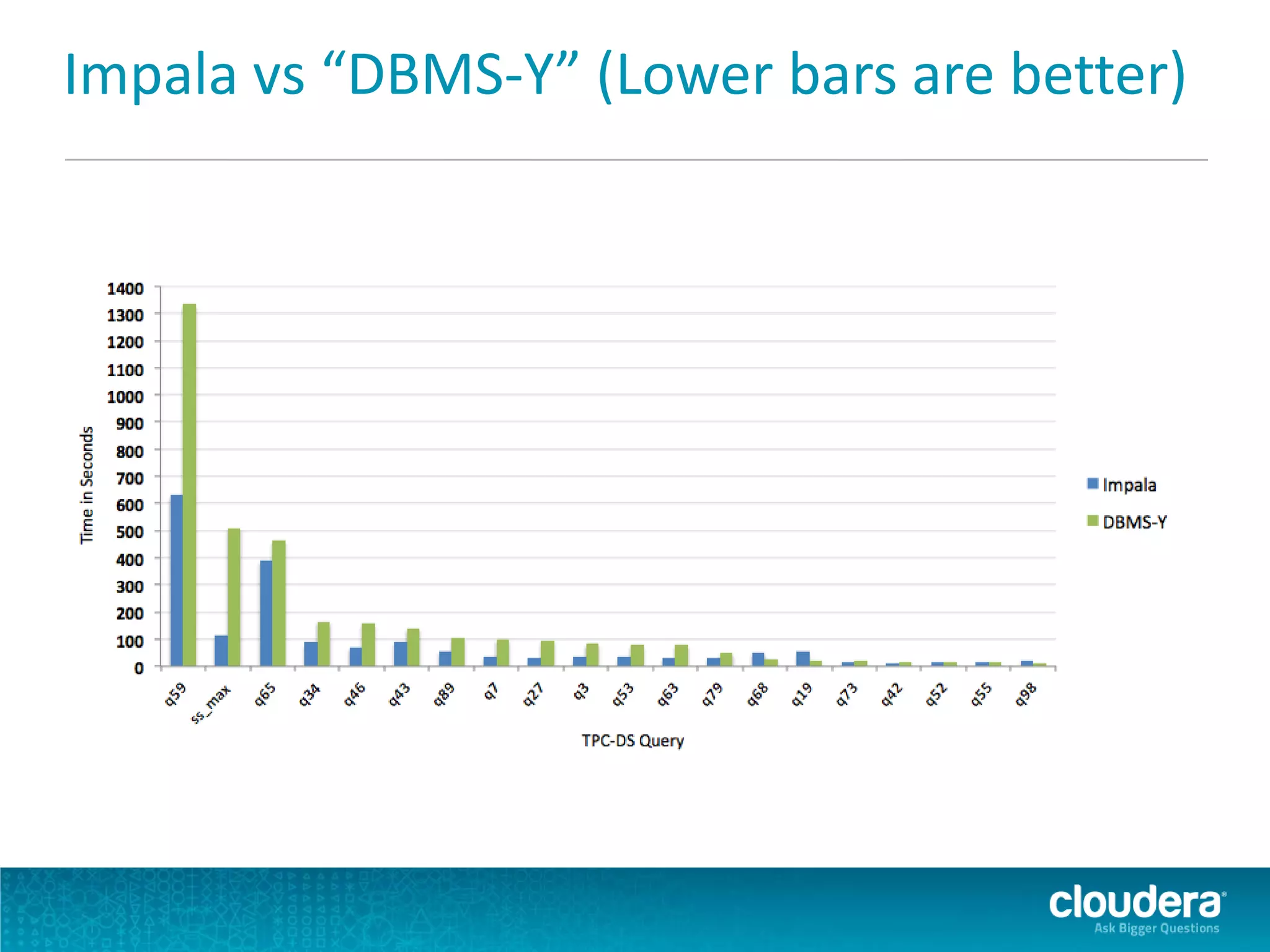
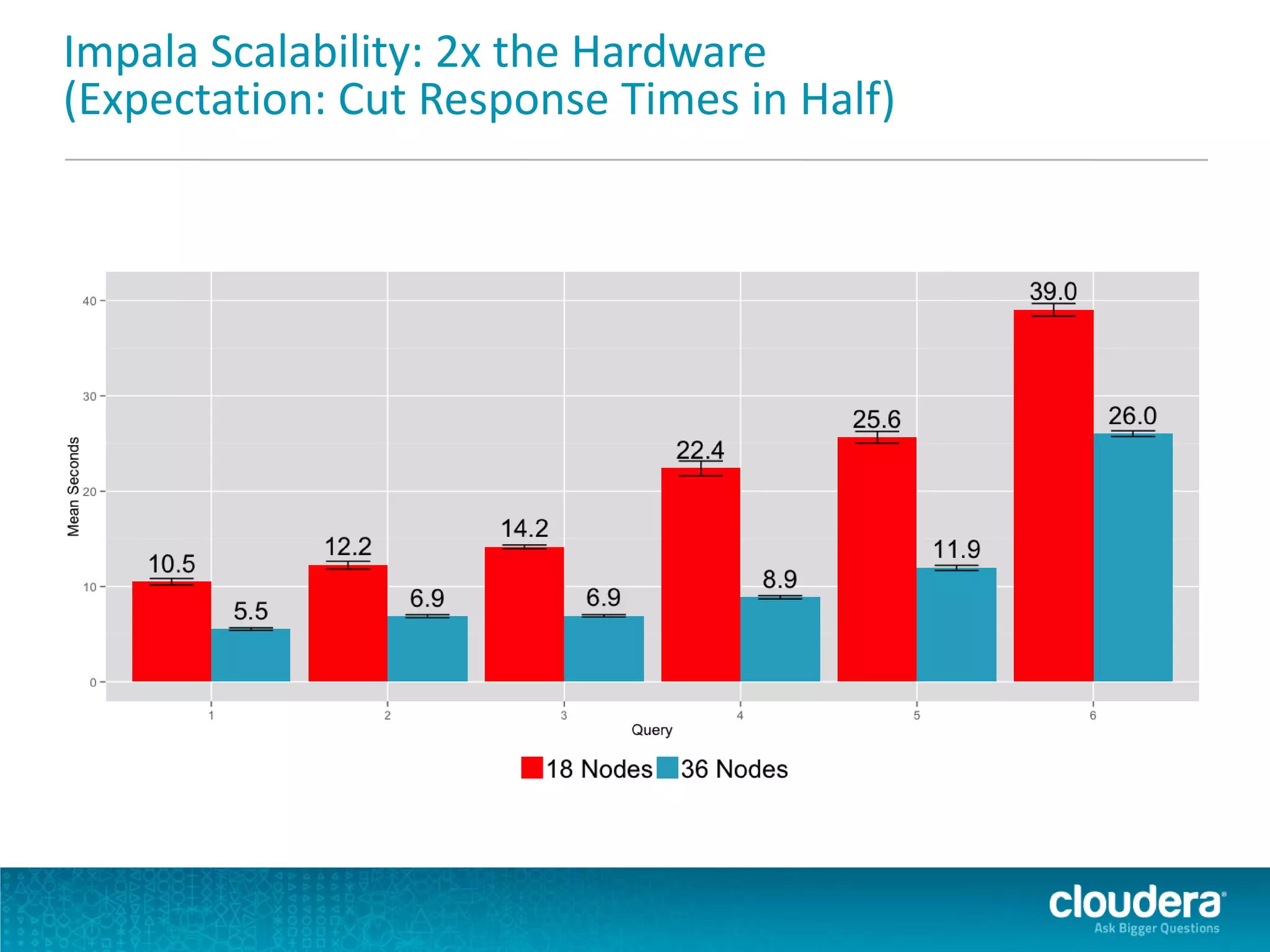
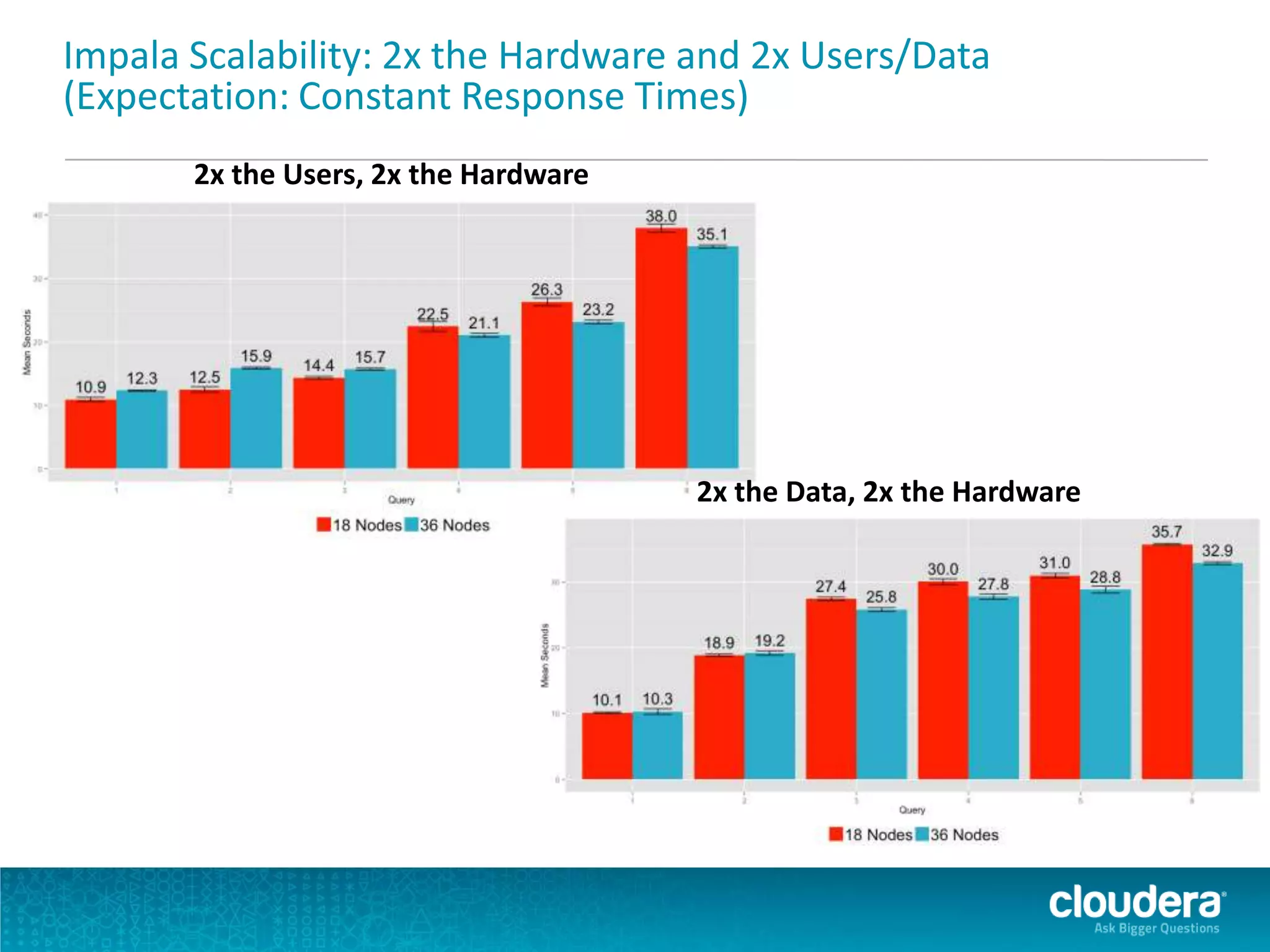





Impala is an open-source SQL query engine for Apache Hadoop that allows for fast, interactive queries directly against data stored in HDFS and other data storage systems. It provides low-latency queries in seconds by using a custom query engine instead of MapReduce. Impala allows users to interact with data using standard SQL and business intelligence tools while leveraging existing metadata in Hadoop. It is designed to be integrated with the Hadoop ecosystem for distributed, fault-tolerant and scalable data processing and analytics.























































































