Download as PDF, PPTX











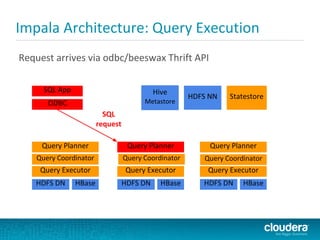
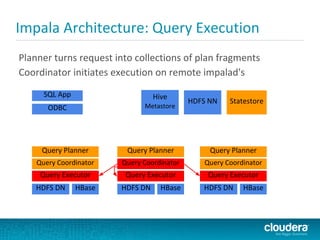
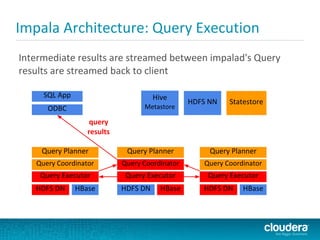













Impala is a SQL query engine for Apache Hadoop that allows for interactive queries on large datasets. It uses a distributed architecture where each node runs an Impala daemon and queries are distributed across nodes. Impala aims to provide general-purpose SQL with high performance by using C++ instead of Java and avoiding MapReduce execution. It runs directly on Hadoop storage systems and supports common file formats like Parquet and Avro.





















































































