Downloaded 169 times




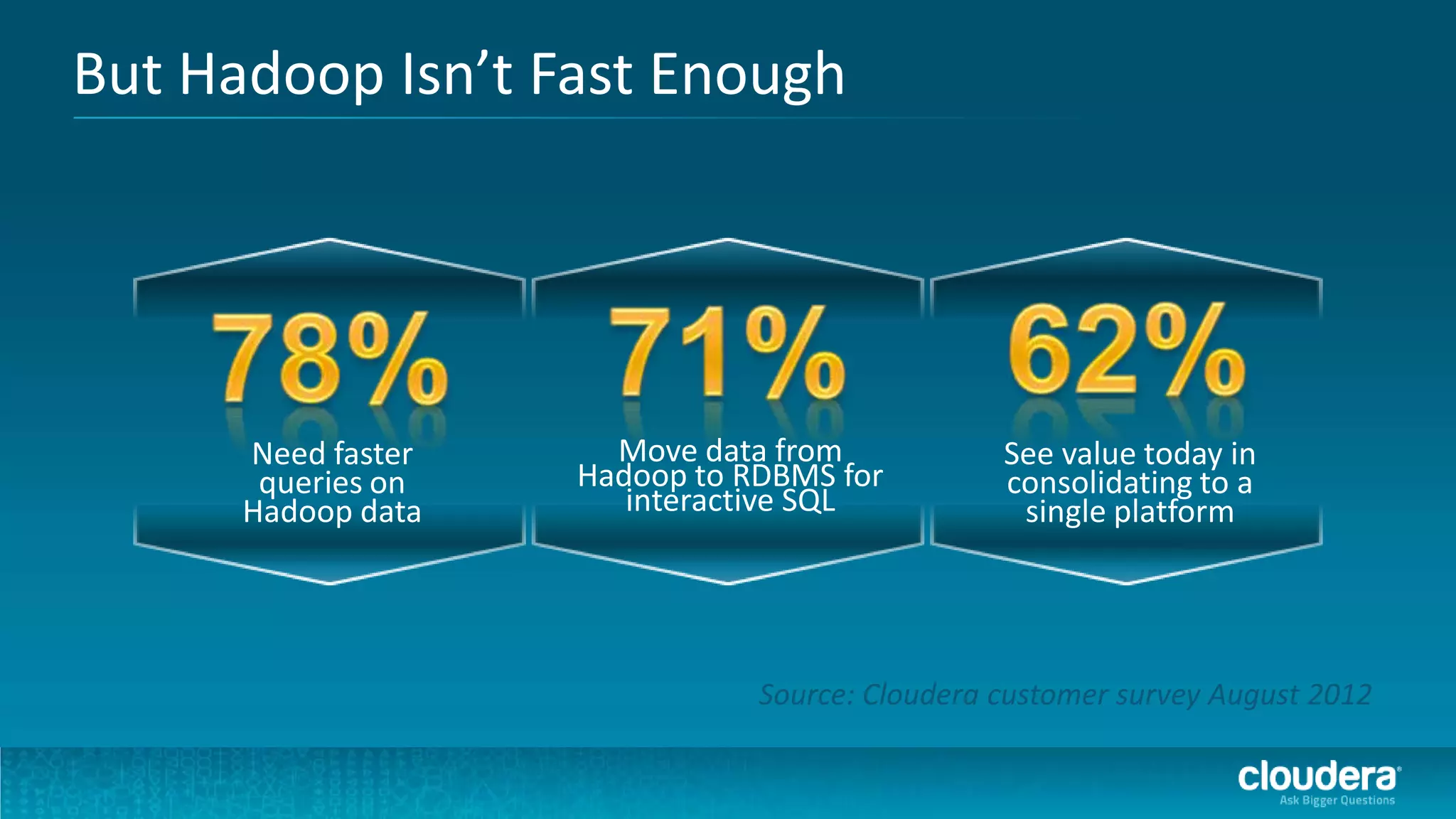

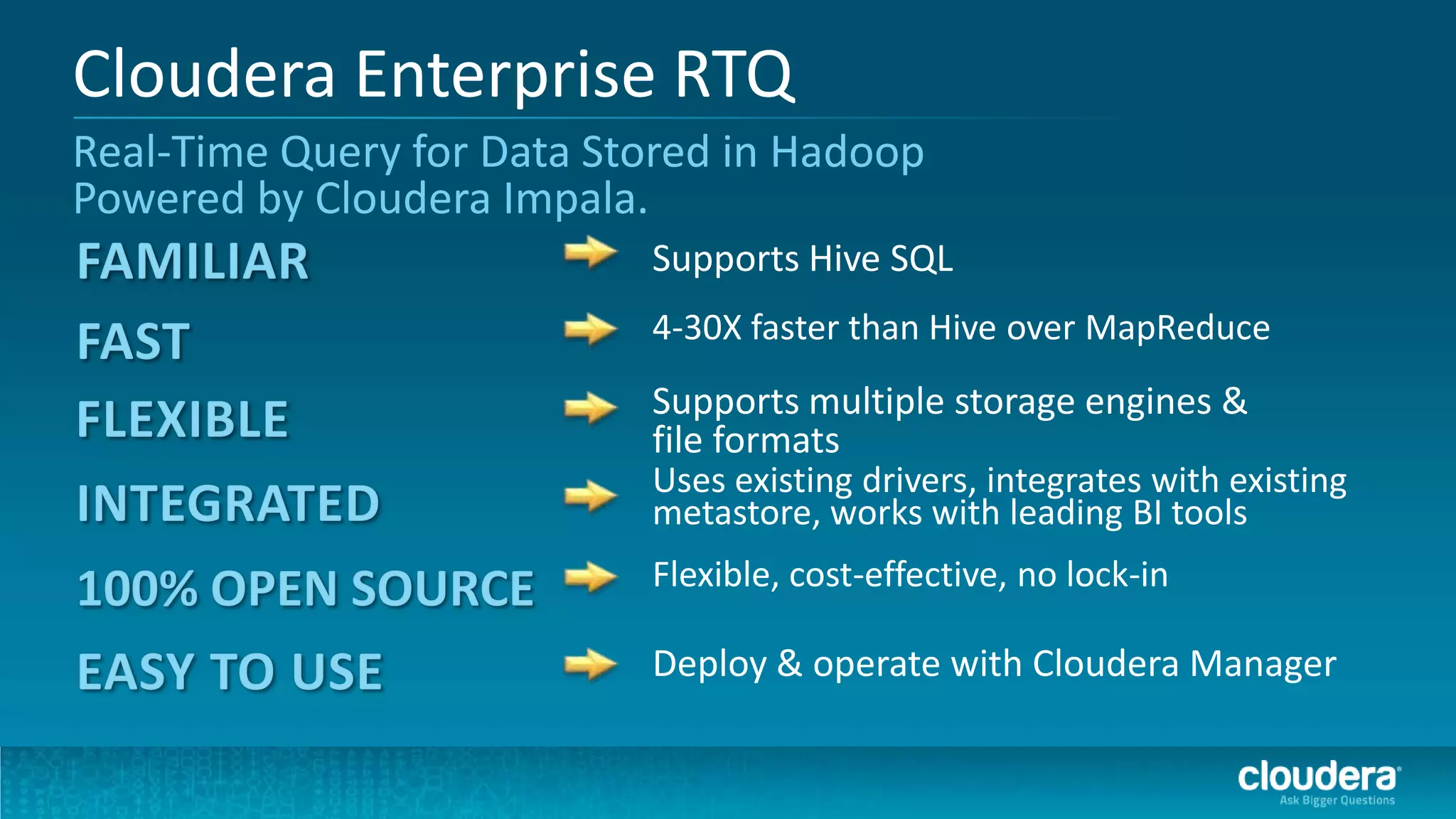

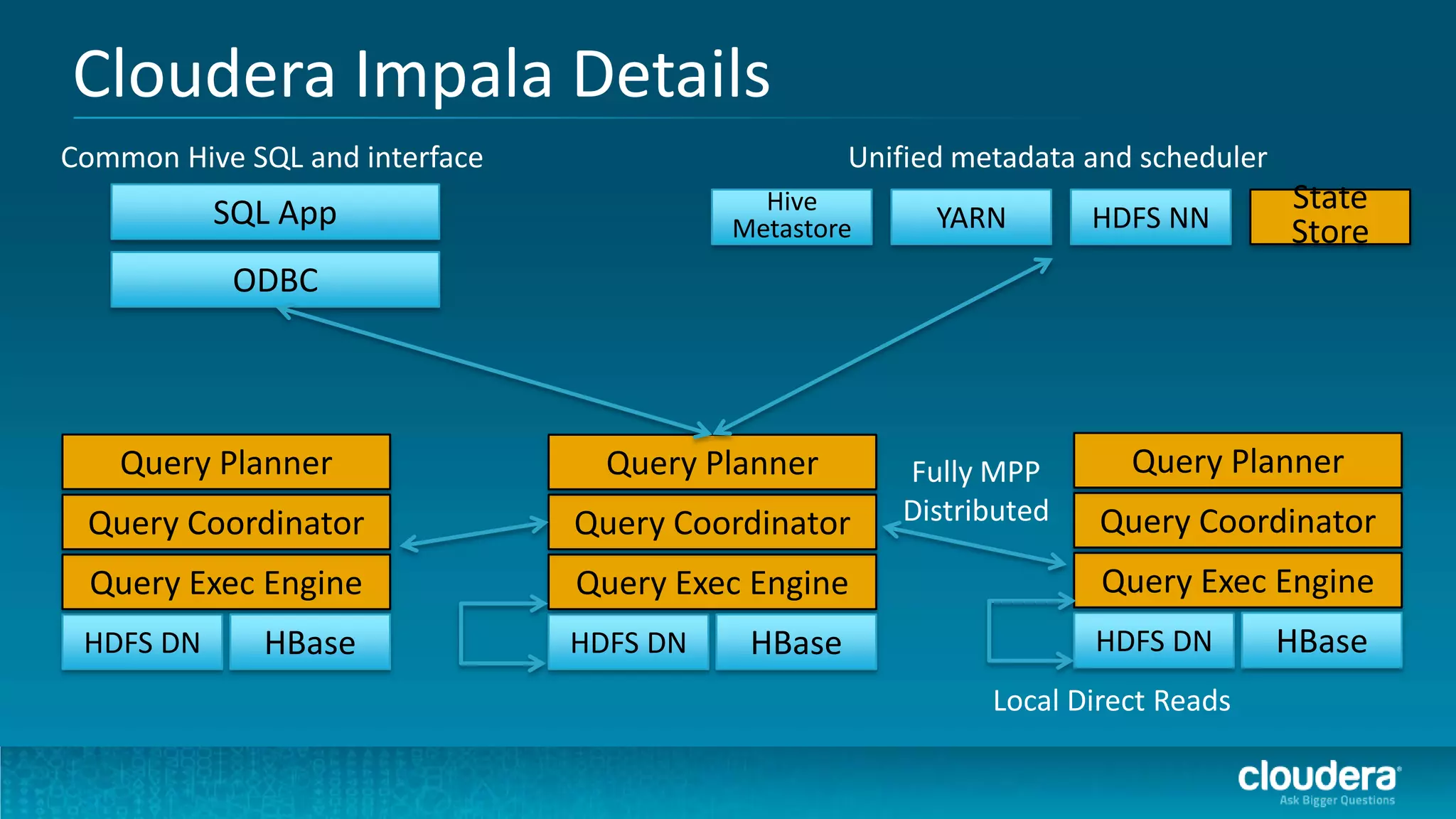
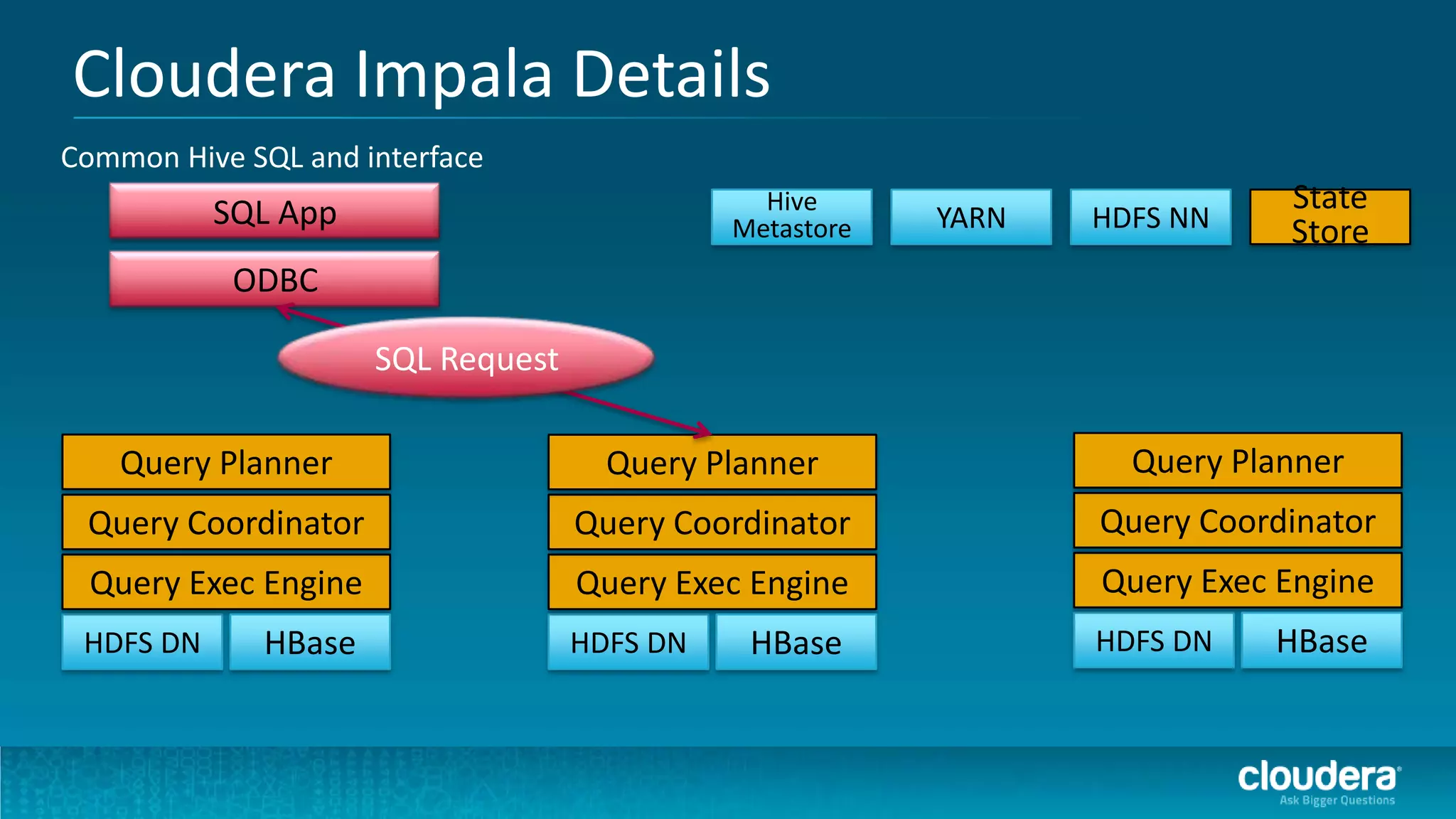
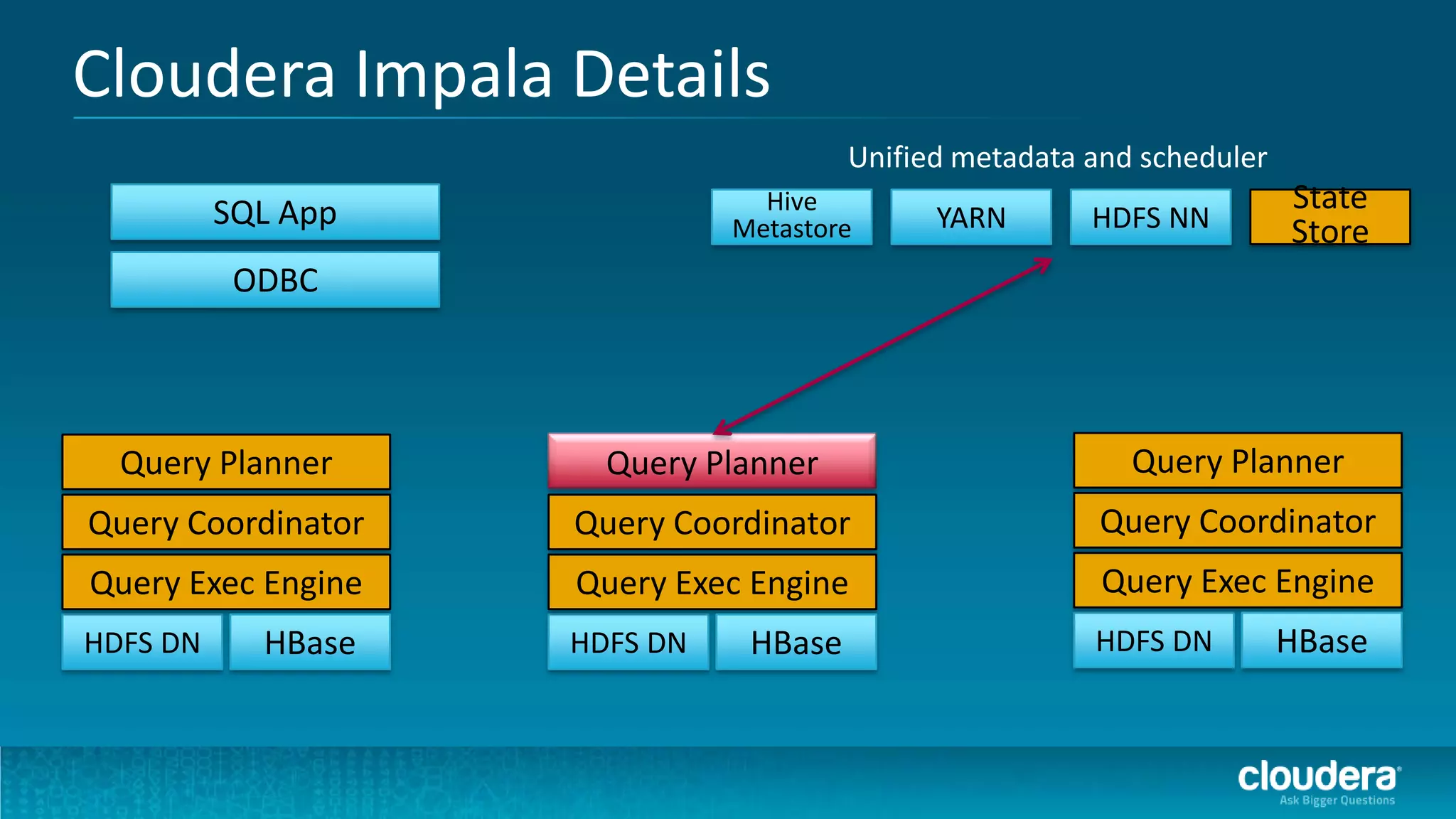
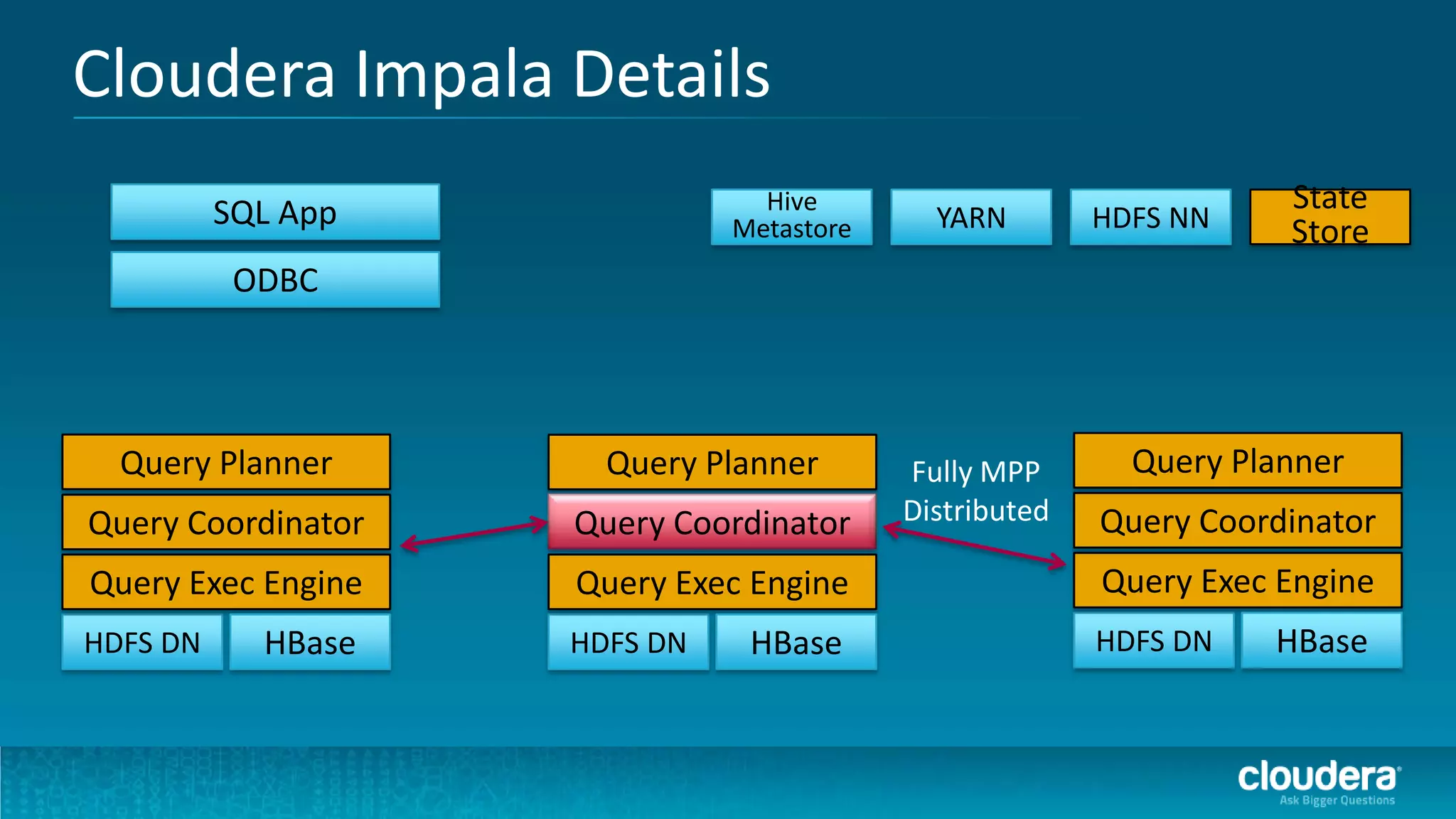
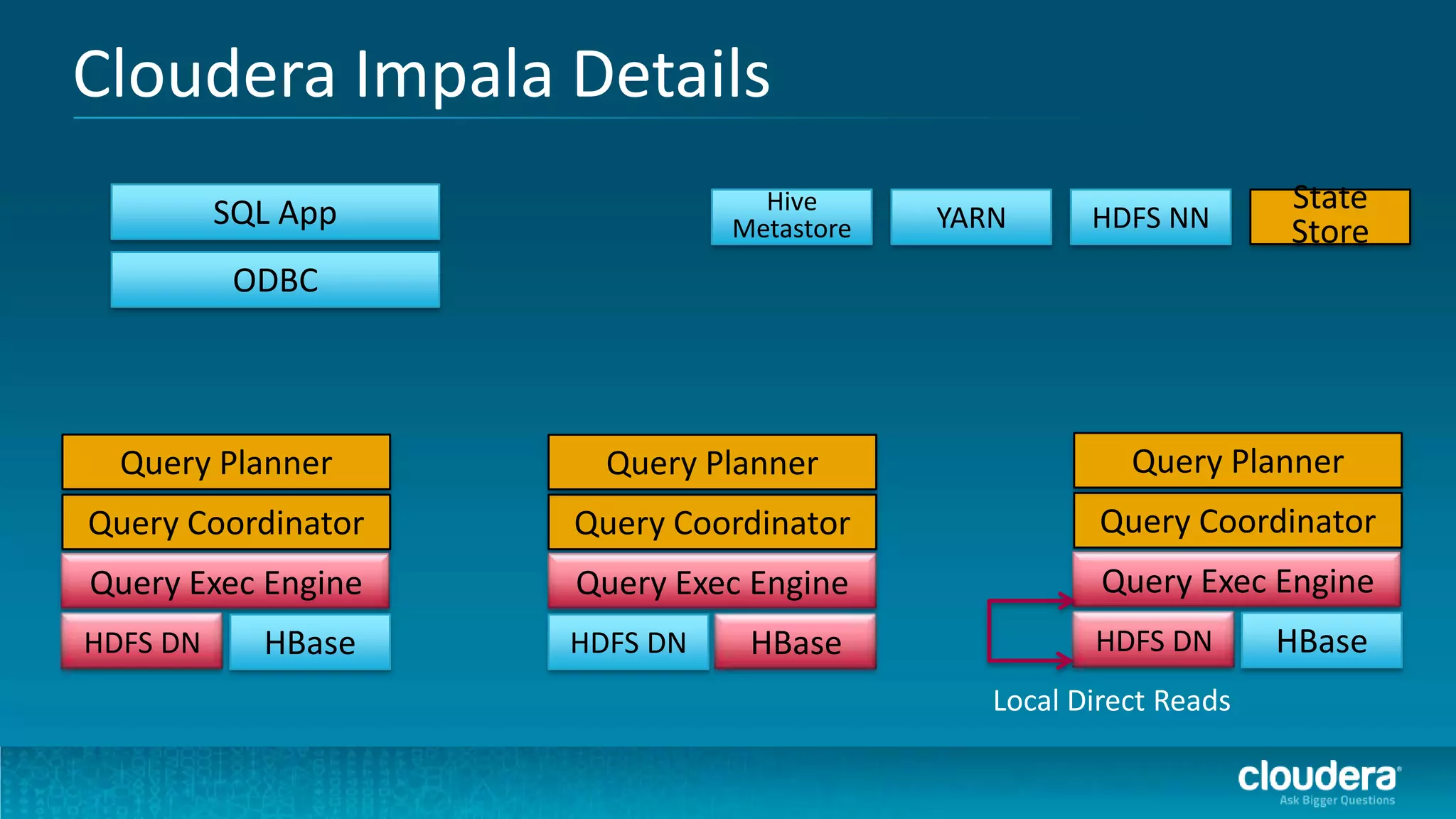
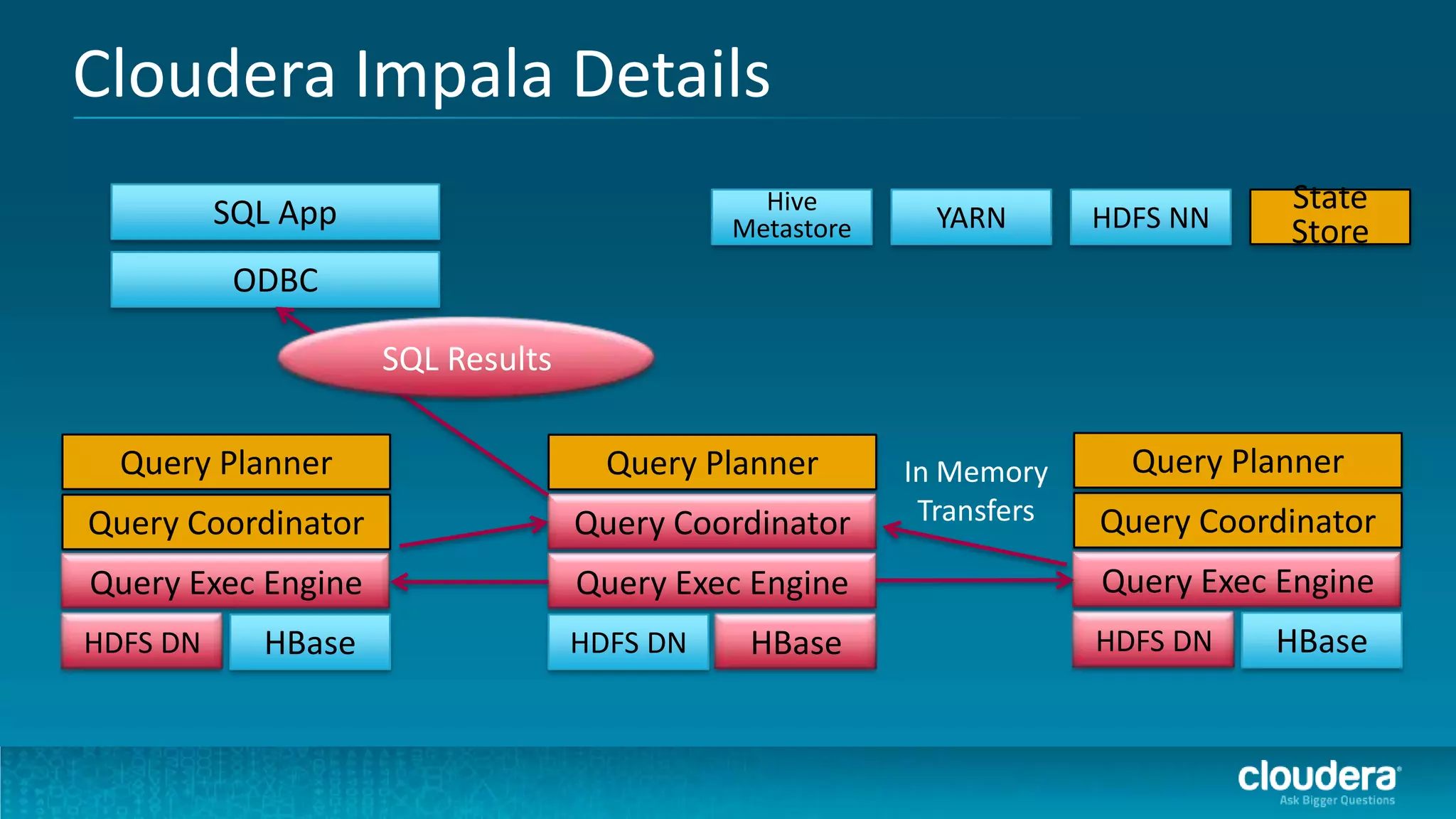
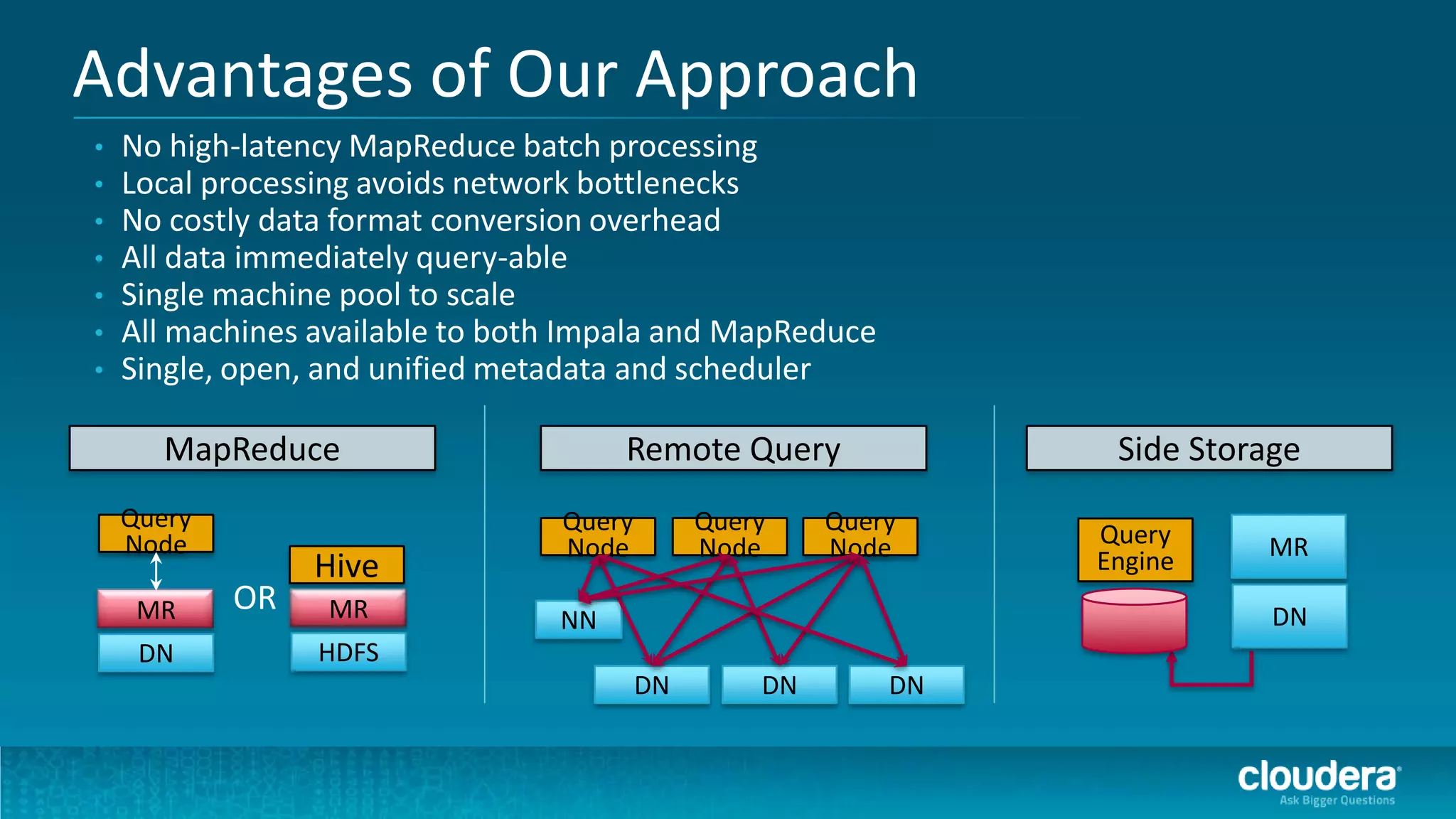






The document discusses how Cloudera Impala enhances data science productivity on Hadoop by providing real-time query capabilities, significantly faster performance, and a unified platform for big data analytics. It highlights the limitations of traditional Hadoop processing and the advantages of using Impala, including interactive analytics and reduced data silos. Additionally, the document presents a case study illustrating how Impala can help organizations like Expedia overcome challenges in processing large data sets for better insights.









































































