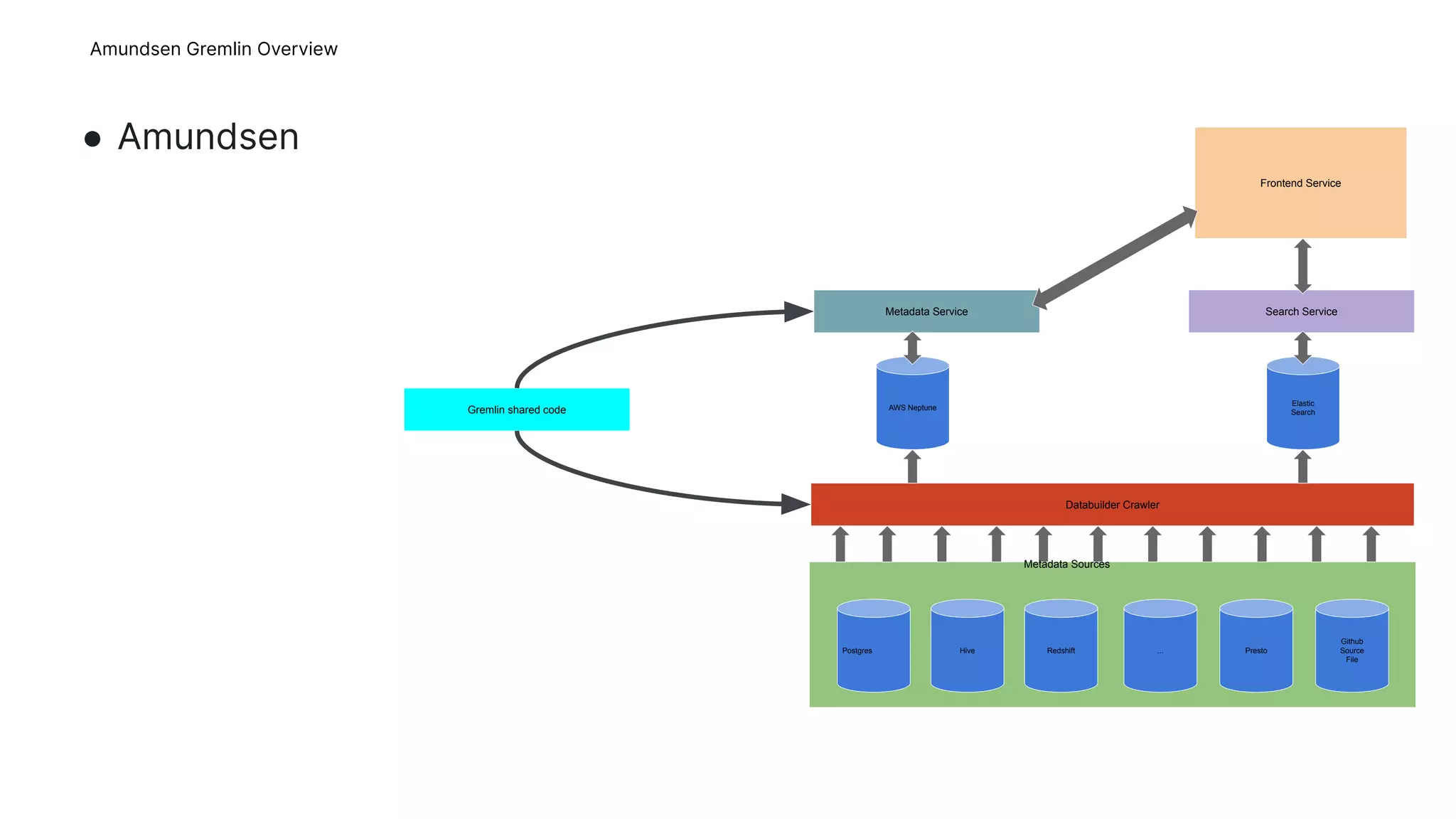
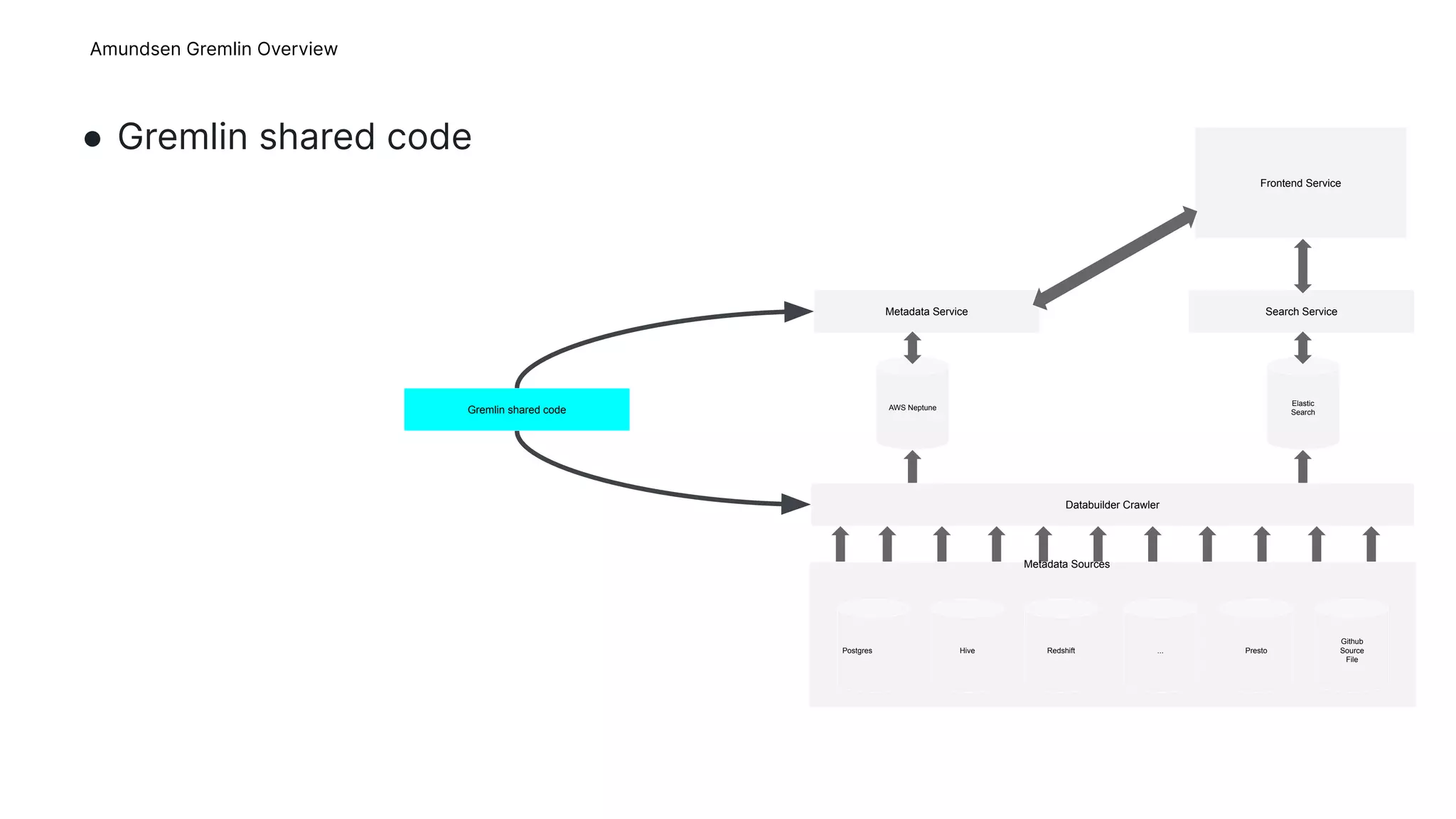
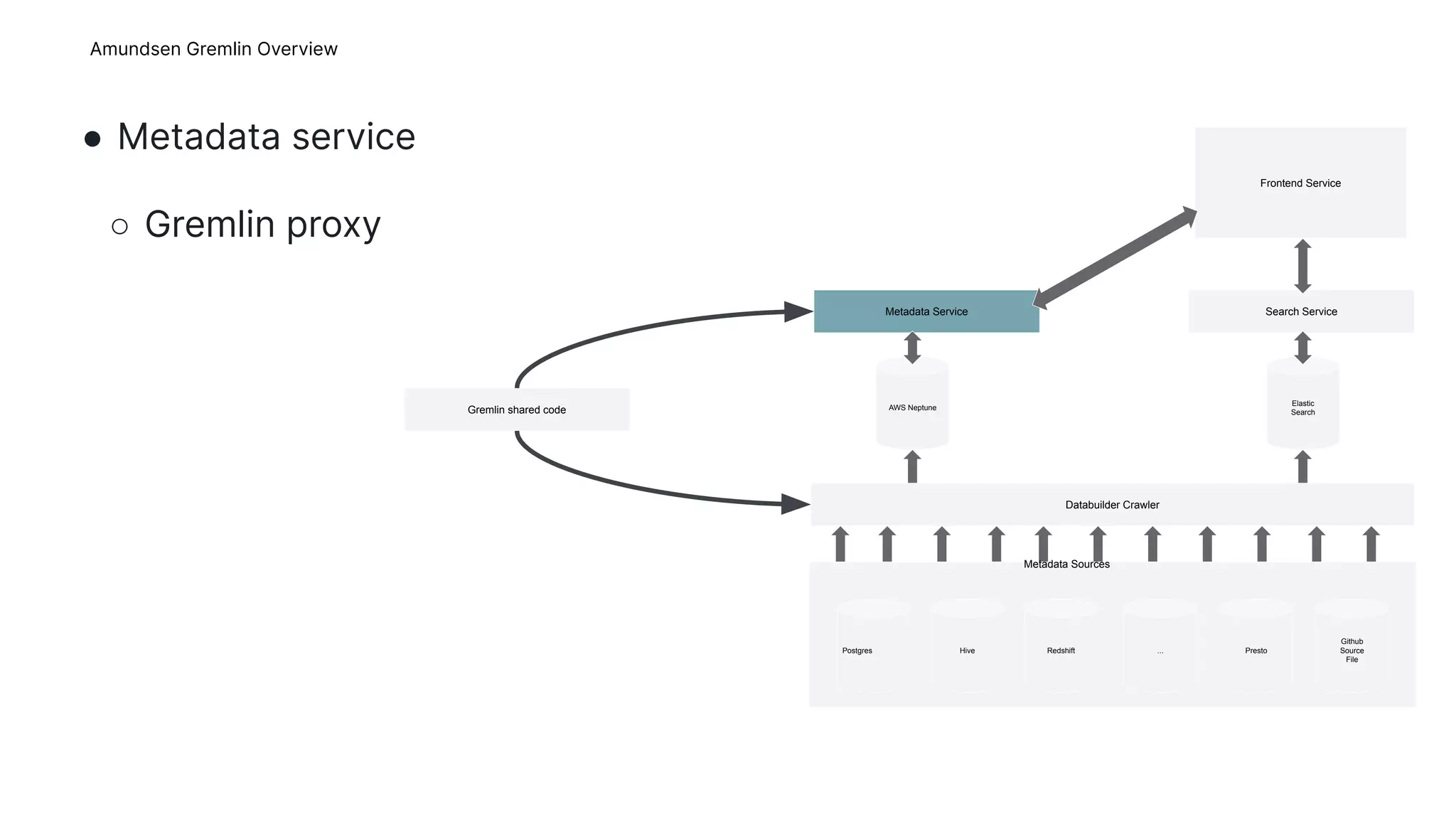
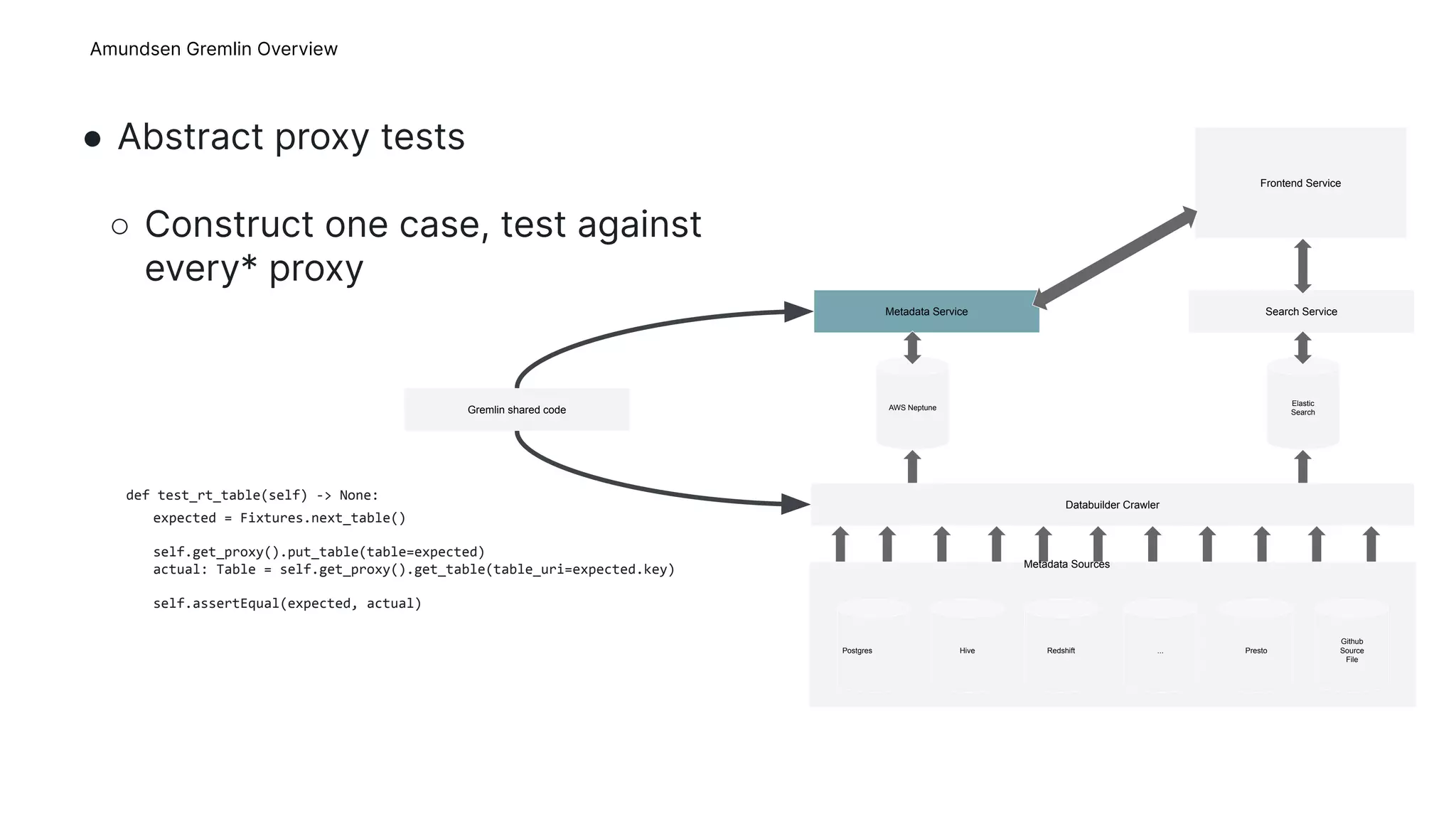
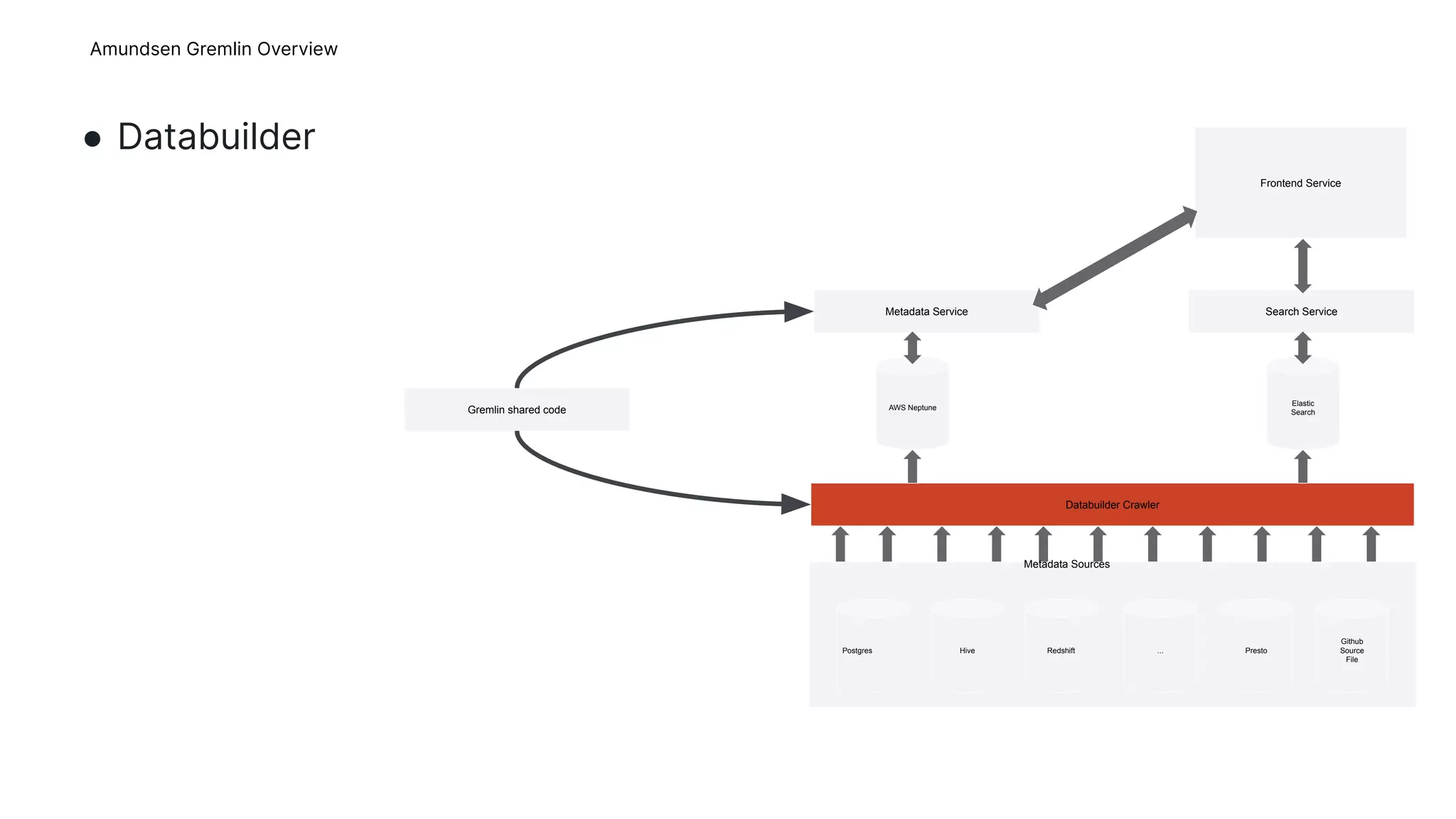
This document provides an overview of Gremlins for Amundsen, including introducing Gremlin, describing how Amundsen uses Gremlin, lessons learned, and the upstream plan. The Amundsen Gremlin overview explains how it uses a hosted graph database, online backups, and a platform-agnostic proxy. It also describes how the shared Gremlin code, metadata service, and databuilder fit into Amundsen's architecture. The lessons learned section discusses failed experiments with transactions and sessions. The upstream plan outlines refactoring the Gremlin code into a shared repository, improving stability, publishing to Amundsen, and removing Square-specific code.




![● Sample queries
g.V().hasLabel('airport').has('code','DFW')
g.V().has(Table, ‘key’, table_uri)
.outE().inV().hasLabel(Column).as_('column')
● Curious to know more? See
Practical Gremlin
Gremlin Introduction
● Cypher equivalent
MATCH (Airport {code: DFW})
MATCH (Table {key: $table_uri})
-[:COLUMN]->(column:Column)
5](https://image.slidesharecdn.com/amundsengremlinproxypresentation-200820003441/75/Amundsen-gremlin-proxy-design-5-2048.jpg)