- Lyft has grown significantly in recent years, providing over 1 billion rides to 30.7 million riders through 1.9 million drivers in 2018 across North America.
- Data is core to Lyft's business decisions, from pricing and driver matching to analyzing performance and informing investments.
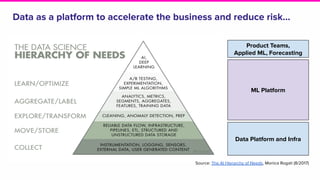
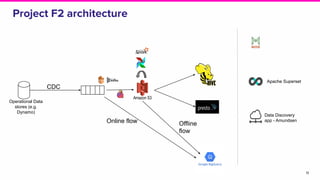
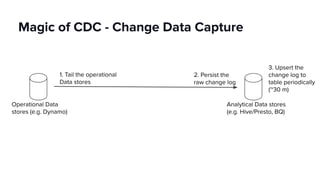
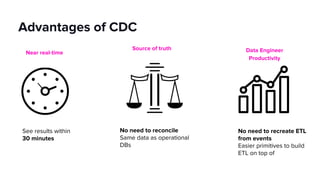
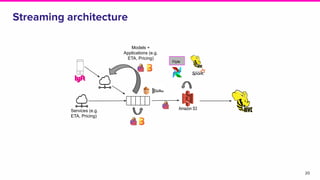
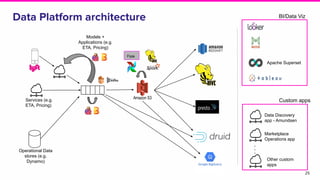
- Lyft's data platform supports data scientists, analysts, engineers and others through tools like Apache Superset, change data capture from operational stores, and streaming frameworks.
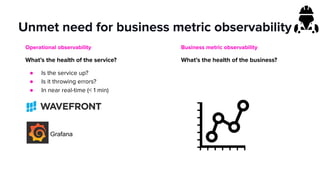
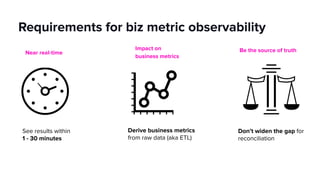
- Key focuses for the platform include business metric observability, streaming applications, and machine learning while addressing challenges of reliability, integration and scale.












































![[QCon.ai 2019] People You May Know: Fast Recommendations Over Massive Data](https://cdn.slidesharecdn.com/ss_thumbnails/qconaisf2019-pymk-190424130904-thumbnail.jpg?width=640&height=640&fit=bounds)

































































