Download as PDF, PPTX











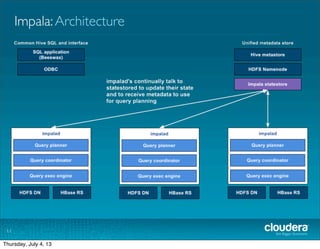
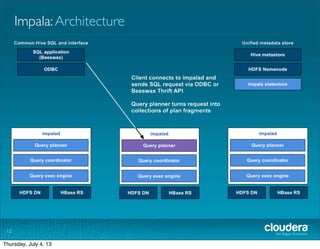
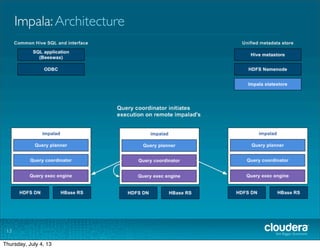
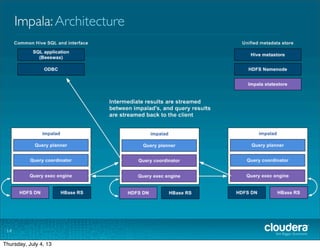





The document discusses Cloudera's Impala, a real-time SQL query engine designed for Hadoop that provides high-performance, low-latency access to data stored in HDFS and HBase. Impala supports various SQL query operations and is optimized for both analytical and transactional workloads, achieving significant speed improvements over traditional MapReduce, particularly for queries involving large datasets. The architecture includes a distributed processing model with high disk throughput, although it has some current limitations such as the absence of User Defined Functions and certain optimizations.