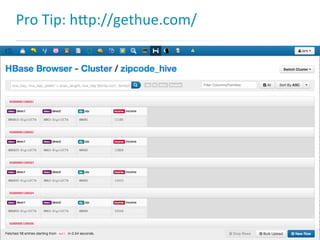
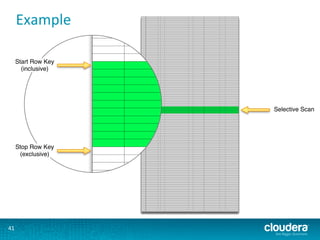
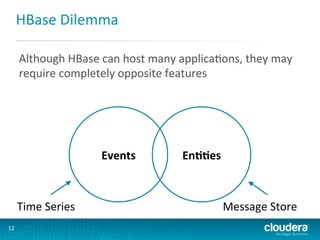
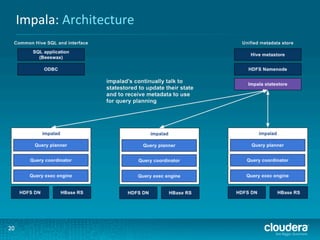
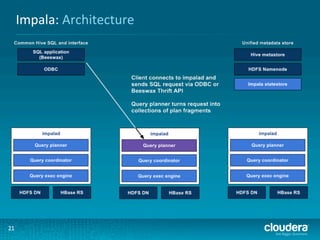
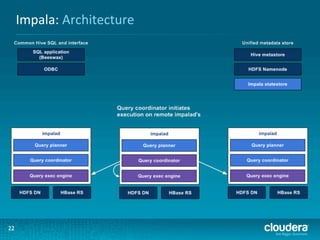
This document presents an overview of HBase and Impala, focusing on their architectures, strengths, and weaknesses, particularly in relation to fast SQL queries. It highlights important considerations for mapping schemas and query efficiency, emphasizing the need for proper design to optimize HBase's performance. The discussion includes use cases, schema mapping techniques, and future enhancements for better integration between HBase and SQL environments.






















![Mapping
OpGons
SERDE
ProperGes
to
map
columns
to
fields
• hbase.columns.mapping
•
•
•
•
•
hbase.table.default.storage.type
•
•
•
29
Matching
count
of
entries
required
(on
SQL
side
only)
Spaces
are
not
allowed
(as
they
are
valid
characters
in
HBase)
The
“:key”
mapping
is
a
special
one
for
the
HBase
row
key
Otherwise:
column-family-name:[column-name]
[#(binary|string)
Can
be
string
(the
default)
or
binary
Defines
the
default
type
Binary
means
data
treated
like
HBase
Bytes
class
does](https://image.slidesharecdn.com/hbase-20and-20impala-20notes-20-20lars-20george-20-20cloudera-20-20munich-20hug-20-2020131017-131018033327-phpapp01/85/HBase-and-Impala-Notes-Munich-HUG-20131017-29-320.jpg)


![HBase
Table
Scan
$ hbase shell
hbase(main):001:0> list
xyz
1 row(s) in 0.0530 seconds'
Table
was
created
hbase(main):002:0> describe "xyz"
DESCRIPTION
ENABLED
{NAME => 'xyz', FAMILIES => [{NAME => 'cf1', COMPRESSION => 'NONE',
VE true
RSIONS => '3', TTL => '2147483647', BLOCKSIZE => '65536', IN_MEMORY
=>
'false', BLOCKCACHE => 'true'}]}
1 row(s) in 0.0220 seconds
hbase(main):003:0> scan "xyz"
ROW
COLUMN+CELL
0 row(s) in 0.0060 seconds
32
Table
empty](https://image.slidesharecdn.com/hbase-20and-20impala-20notes-20-20lars-20george-20-20cloudera-20-20munich-20hug-20-2020131017-131018033327-phpapp01/85/HBase-and-Impala-Notes-Munich-HUG-20131017-32-320.jpg)