Downloaded 11 times





![Copyright © 2013 Cloudera Inc. All rights reserved.
New
Features
in
Impala
2.0
&
2.2
•Analytic
[window]
functions
•example:
SUM(revenue)
OVER
(PARTITION
BY
…
ORDER
BY
…)
•ranking
functions
(rank(),
row_number(),
lead/lag(),
first_/last_value())
•explicit
ROWS
window
•Subqueries:
•already
supported:
inline
views
with
arbitrary
levels
of
nesting
•in
2.0:
correlated
and
uncorrelated
subqueries
in
Where
clause
•Joins
and
aggregation
can
spill
to
disk:
•Partitioned
hash
table.
Can
spill
to
disk
individual
partitions
under
memory
pressure
•Support
for
S3-‐backed
tables
6](https://image.slidesharecdn.com/impala-tech-talk-cug-2015-dt-150804224300-lva1-app6891/75/Impala-tech-talk-by-Dimitris-Tsirogiannis-6-2048.jpg)



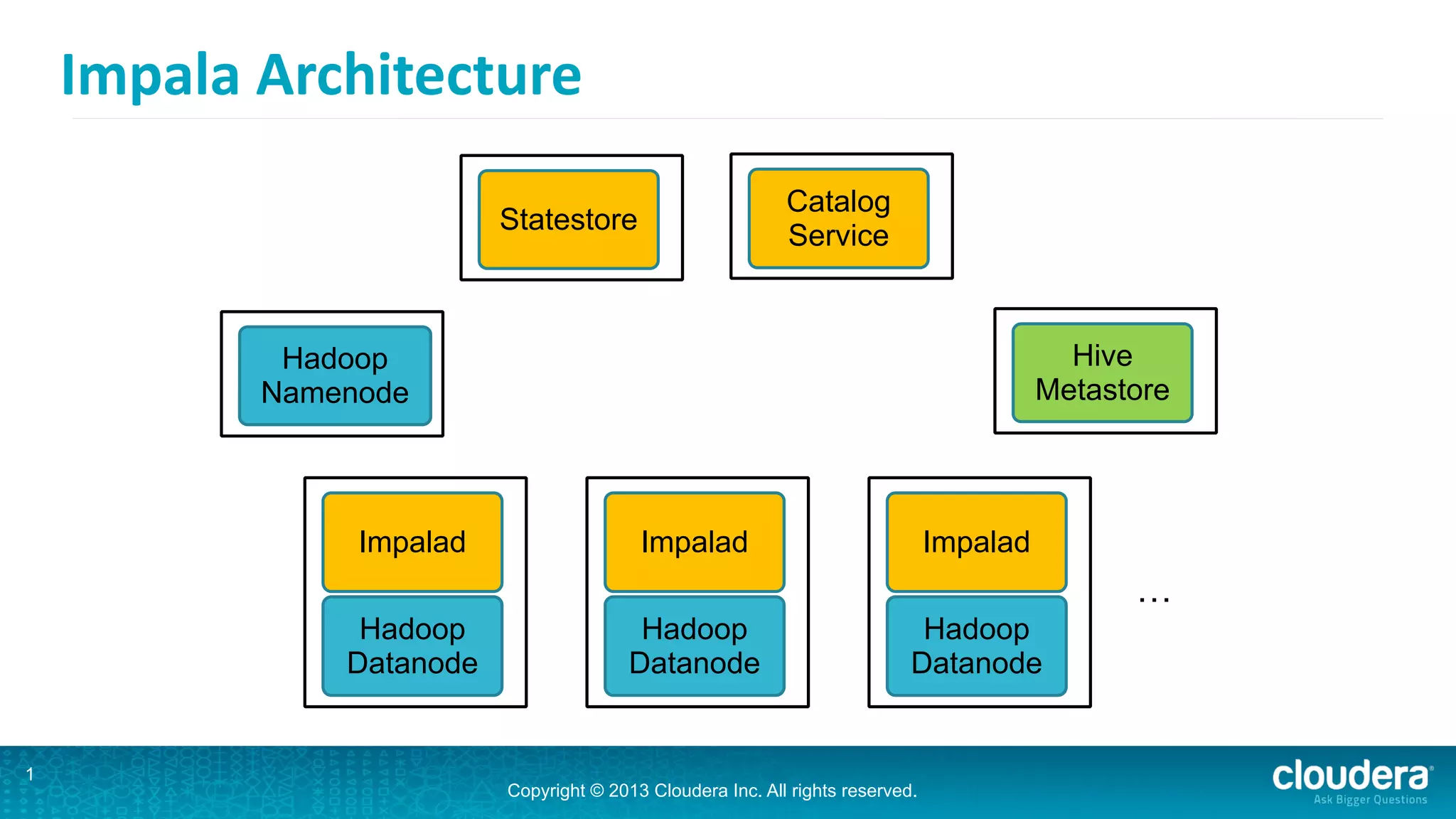




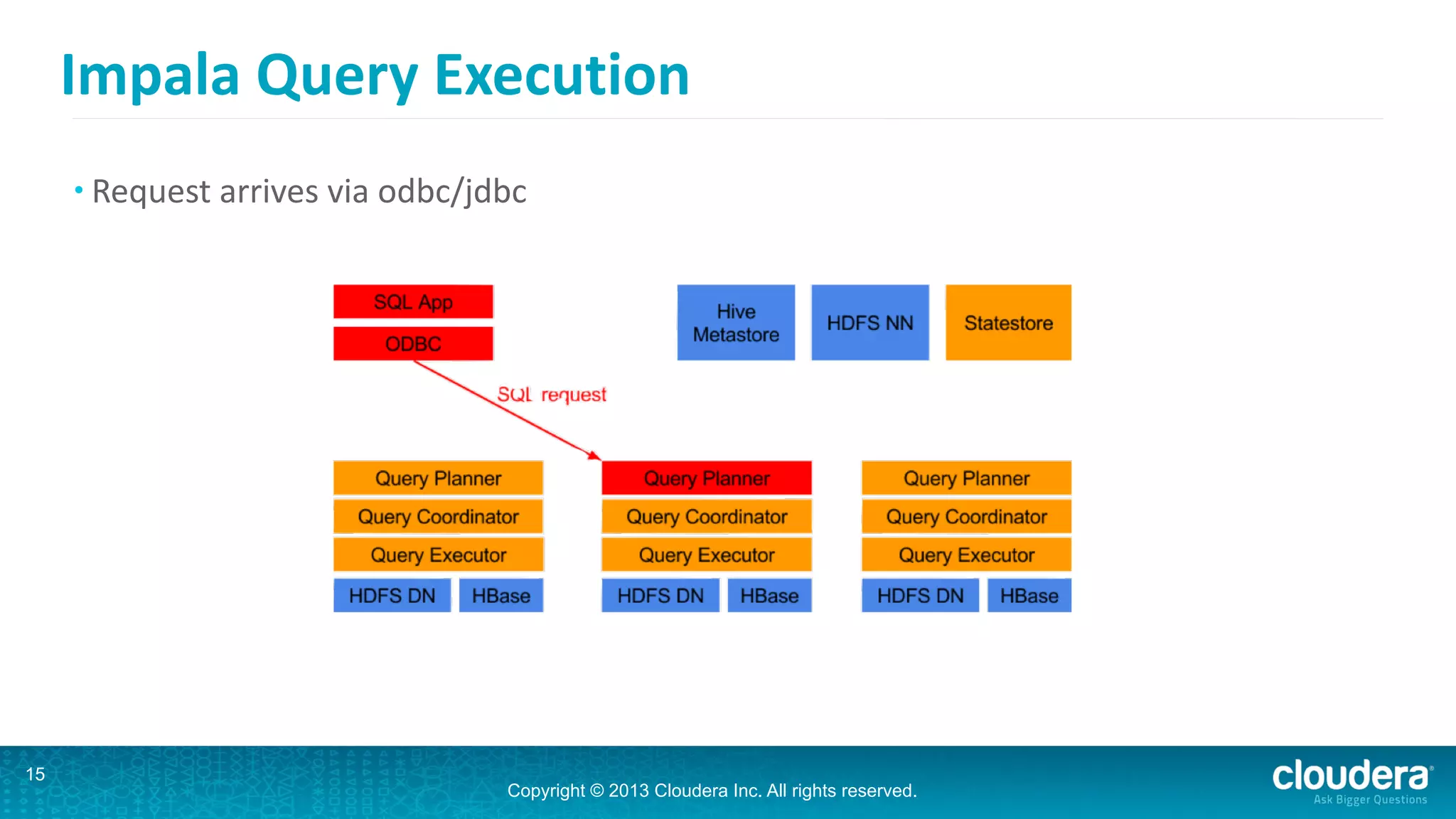
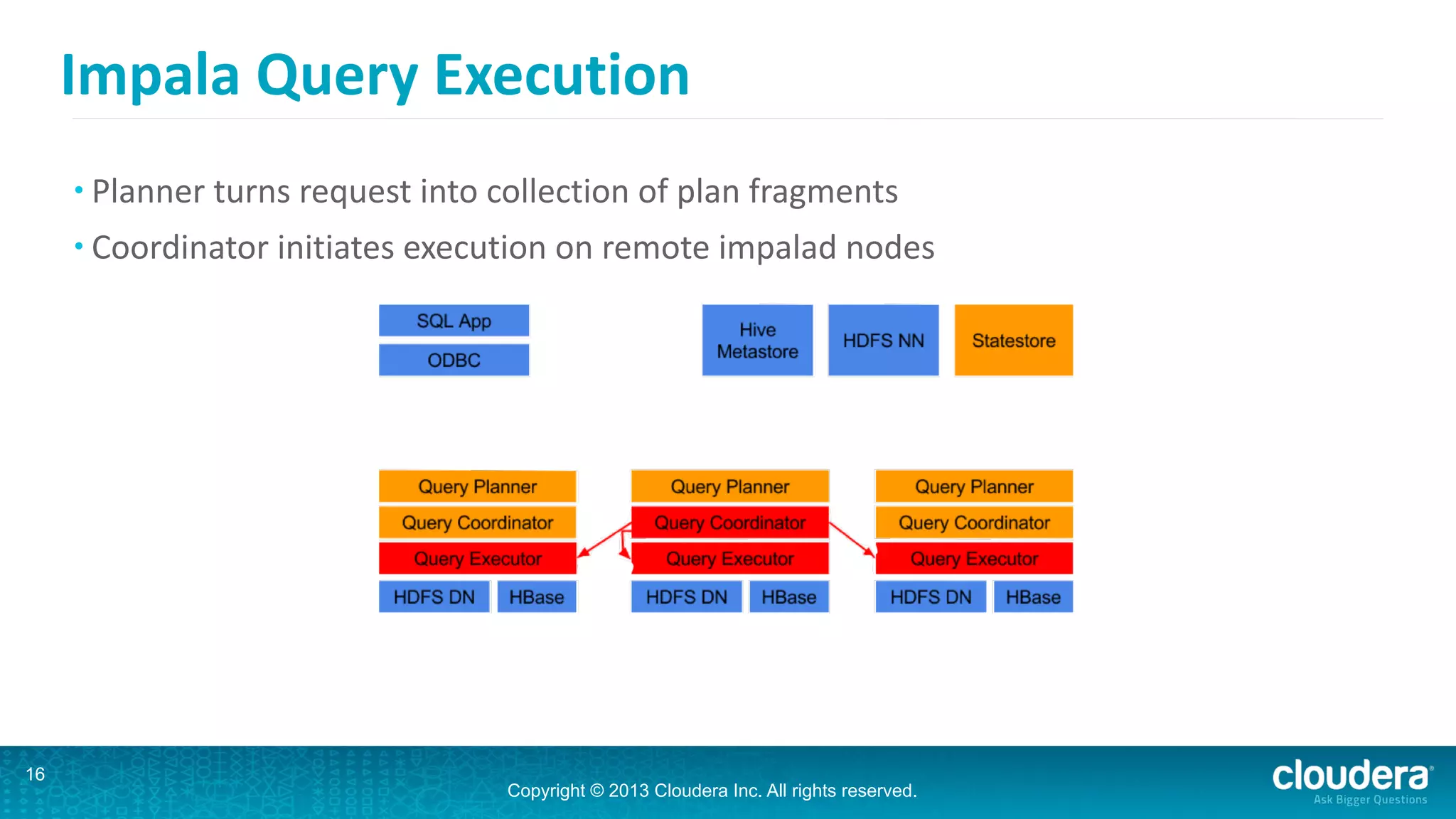
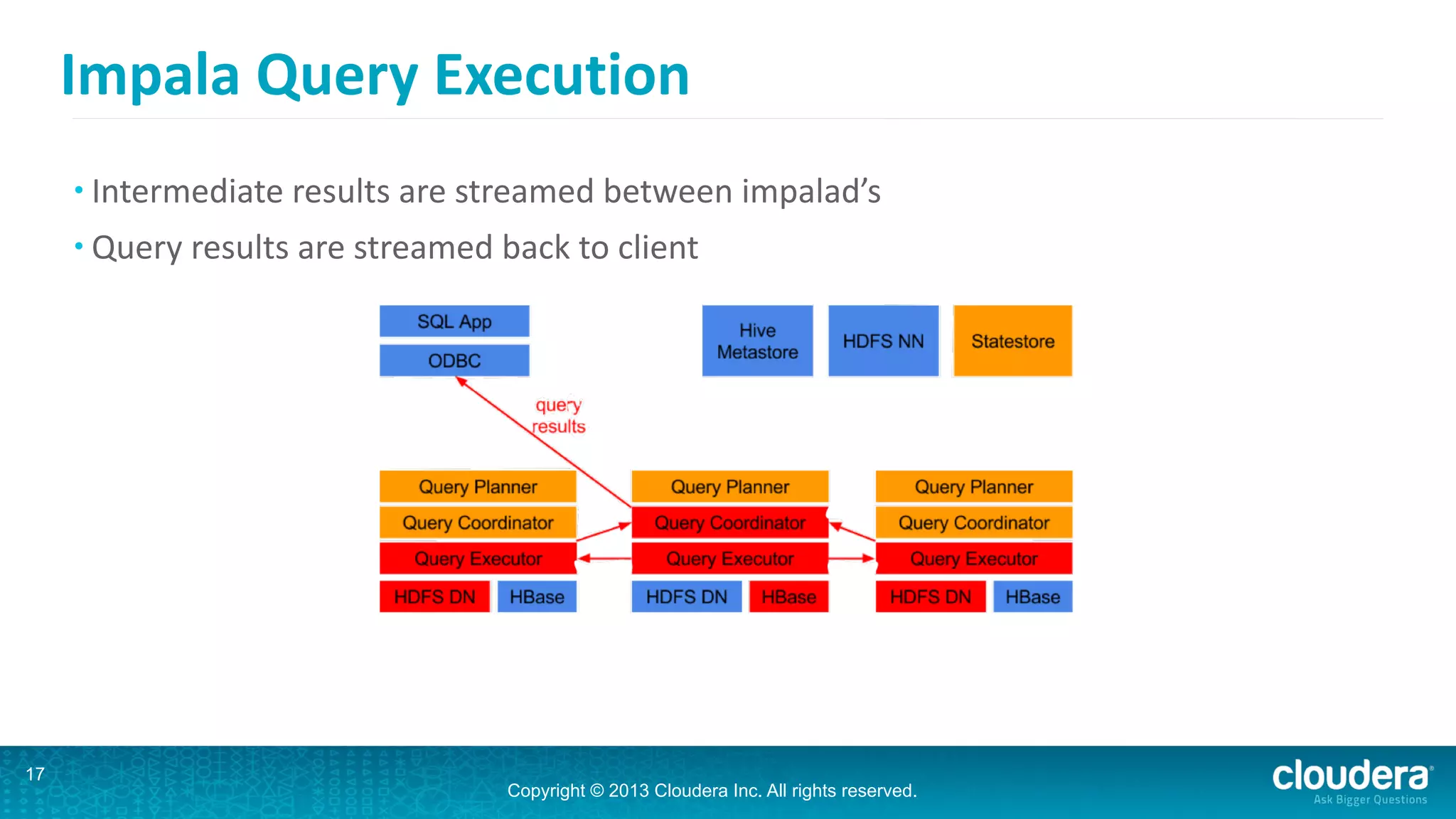





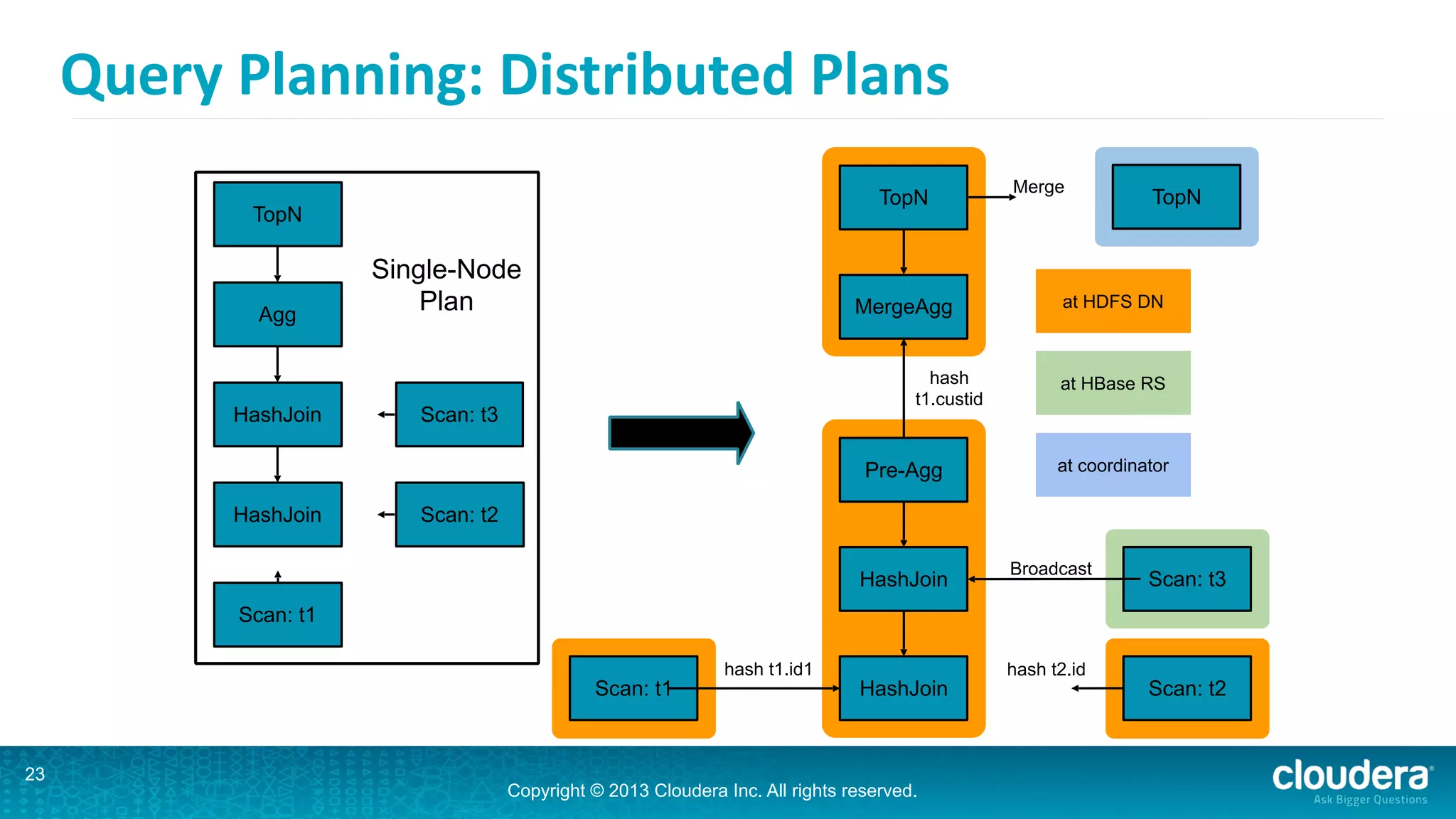



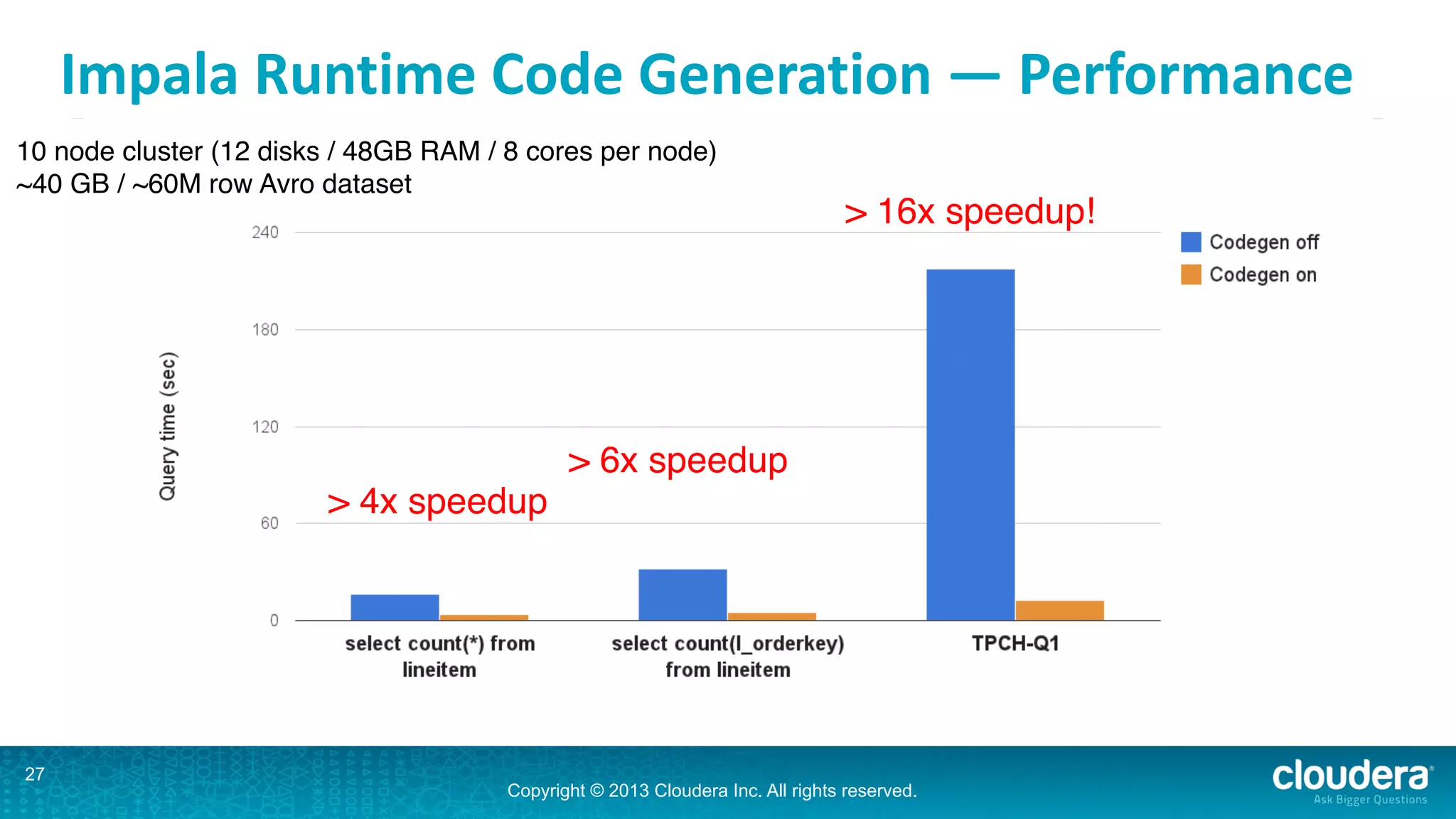







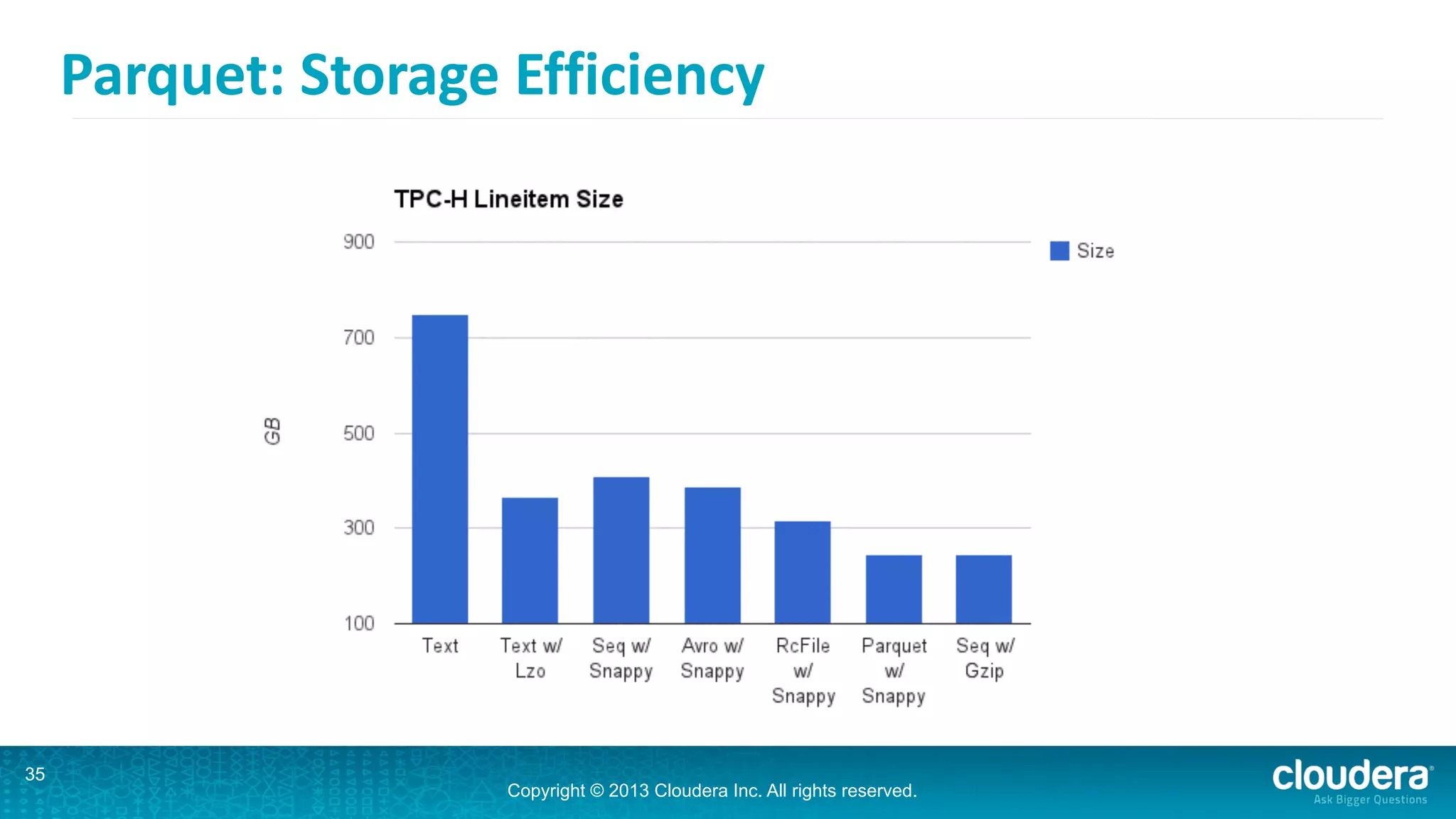
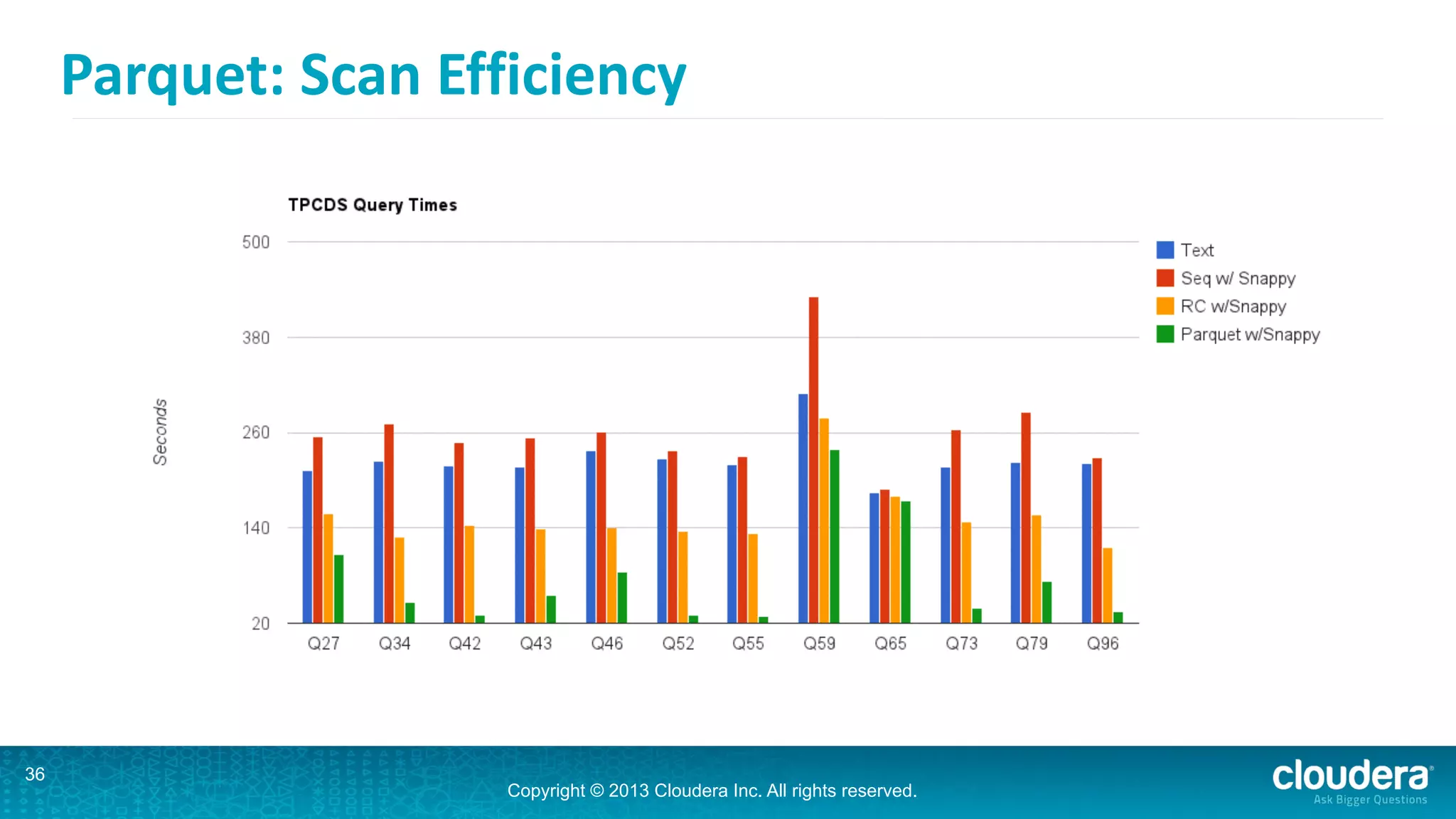


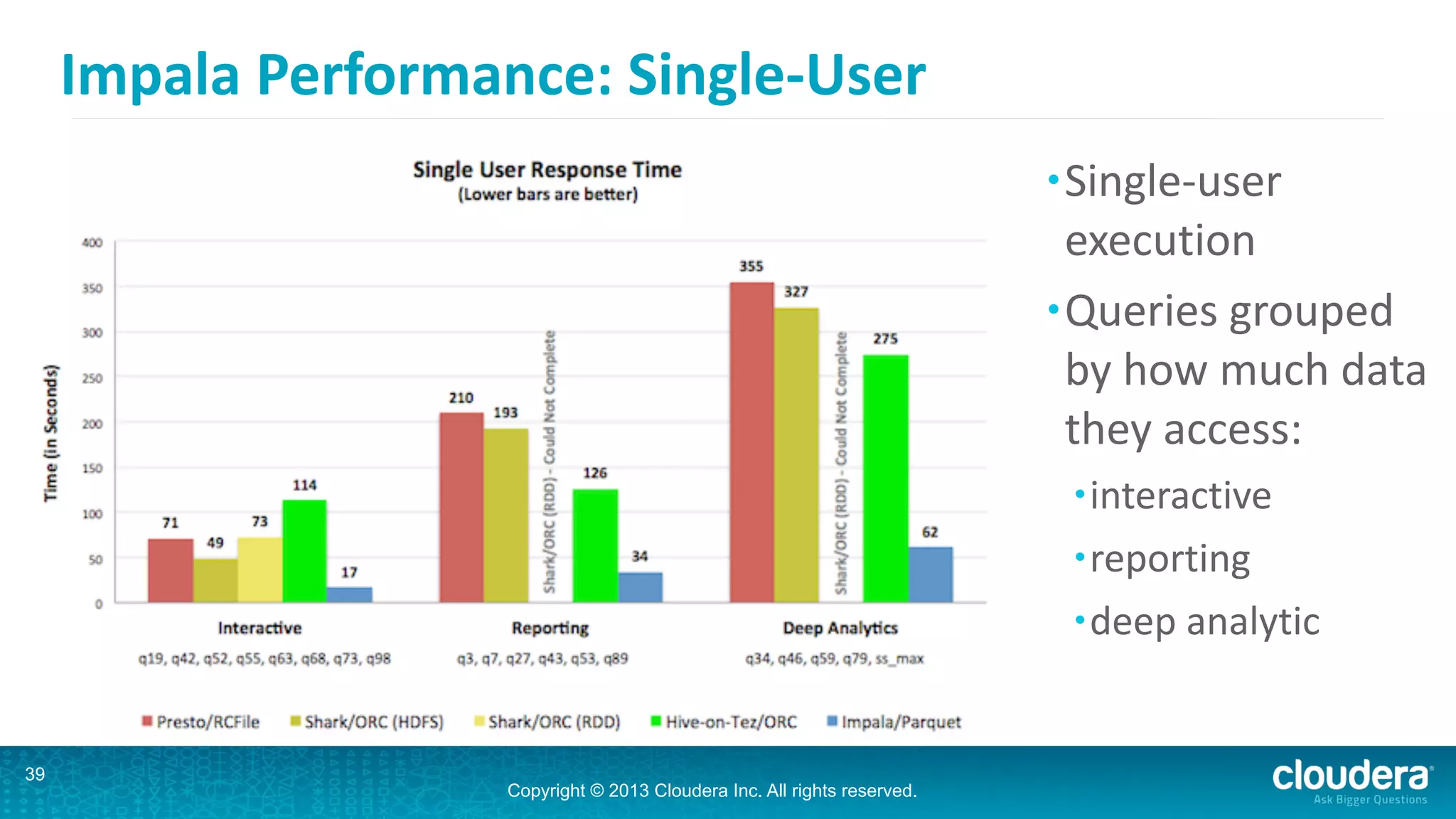
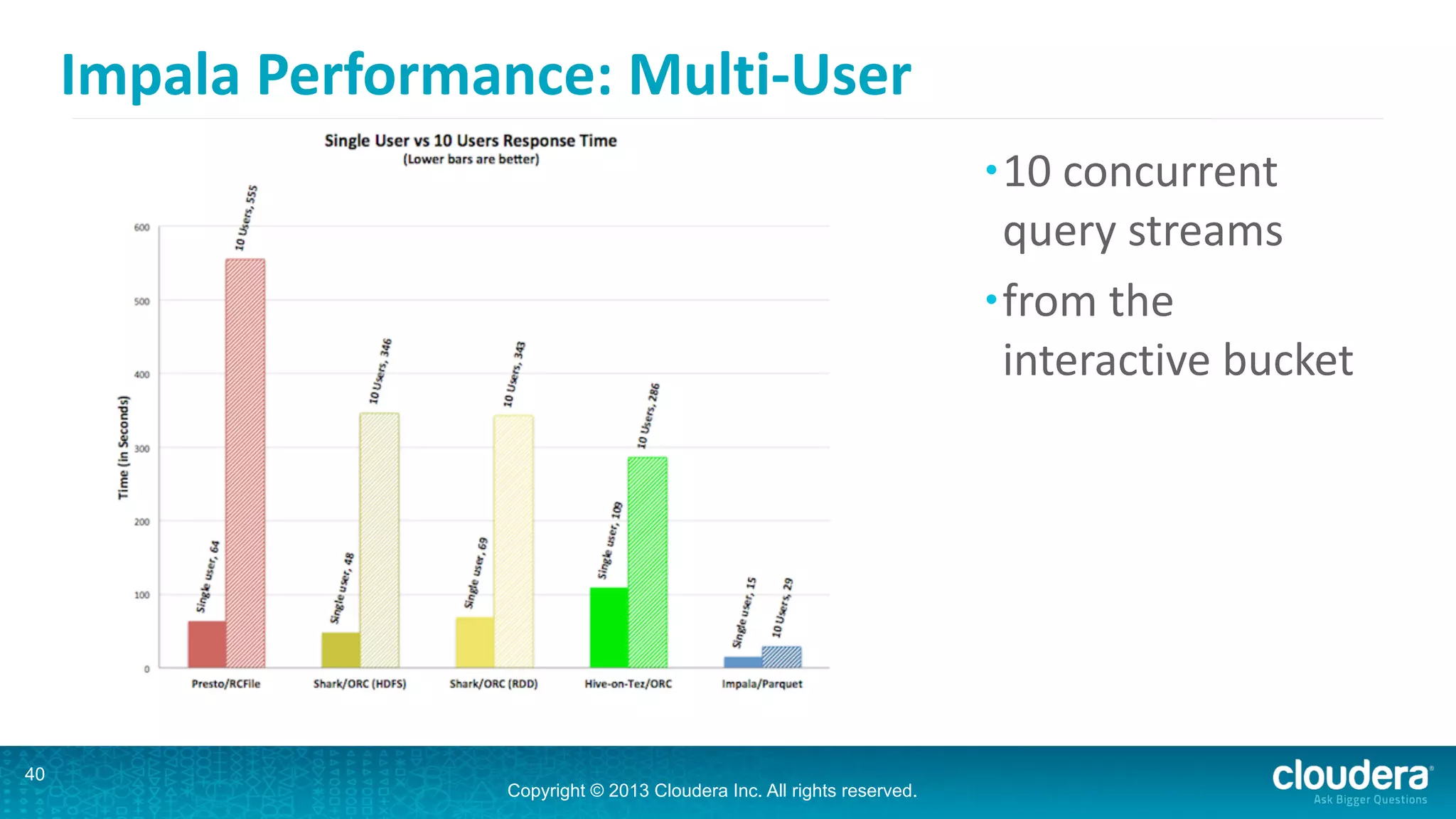
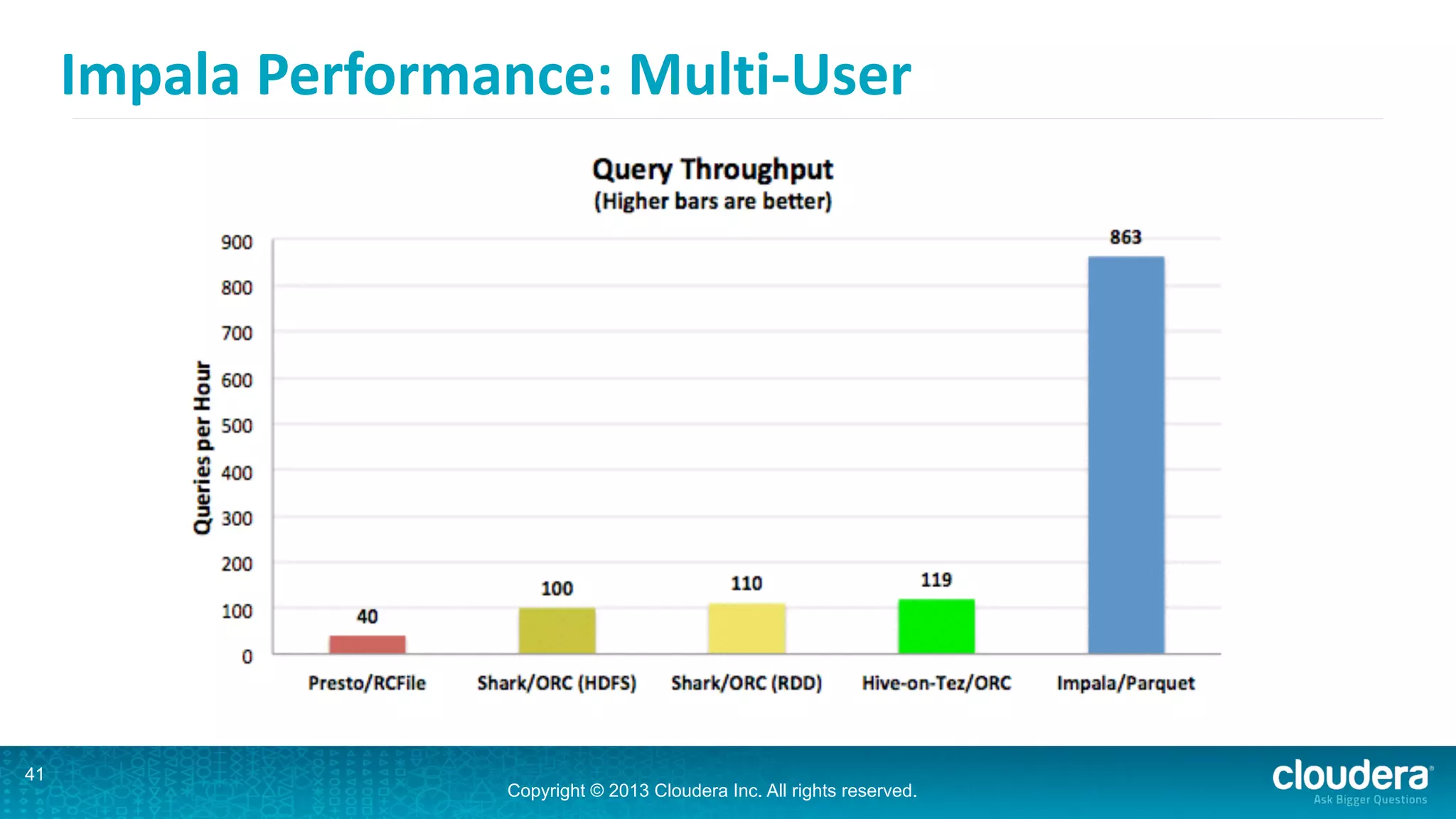
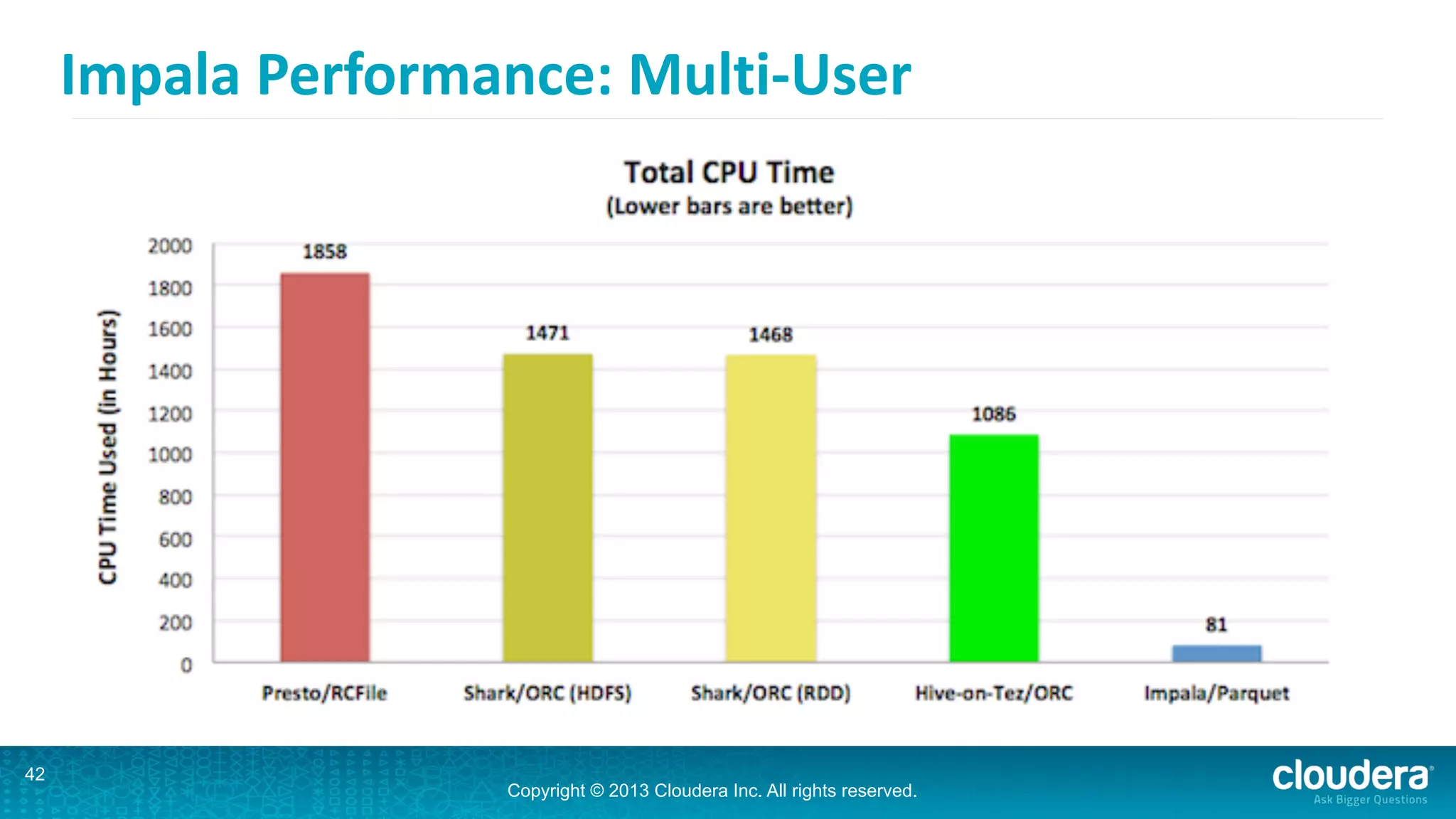
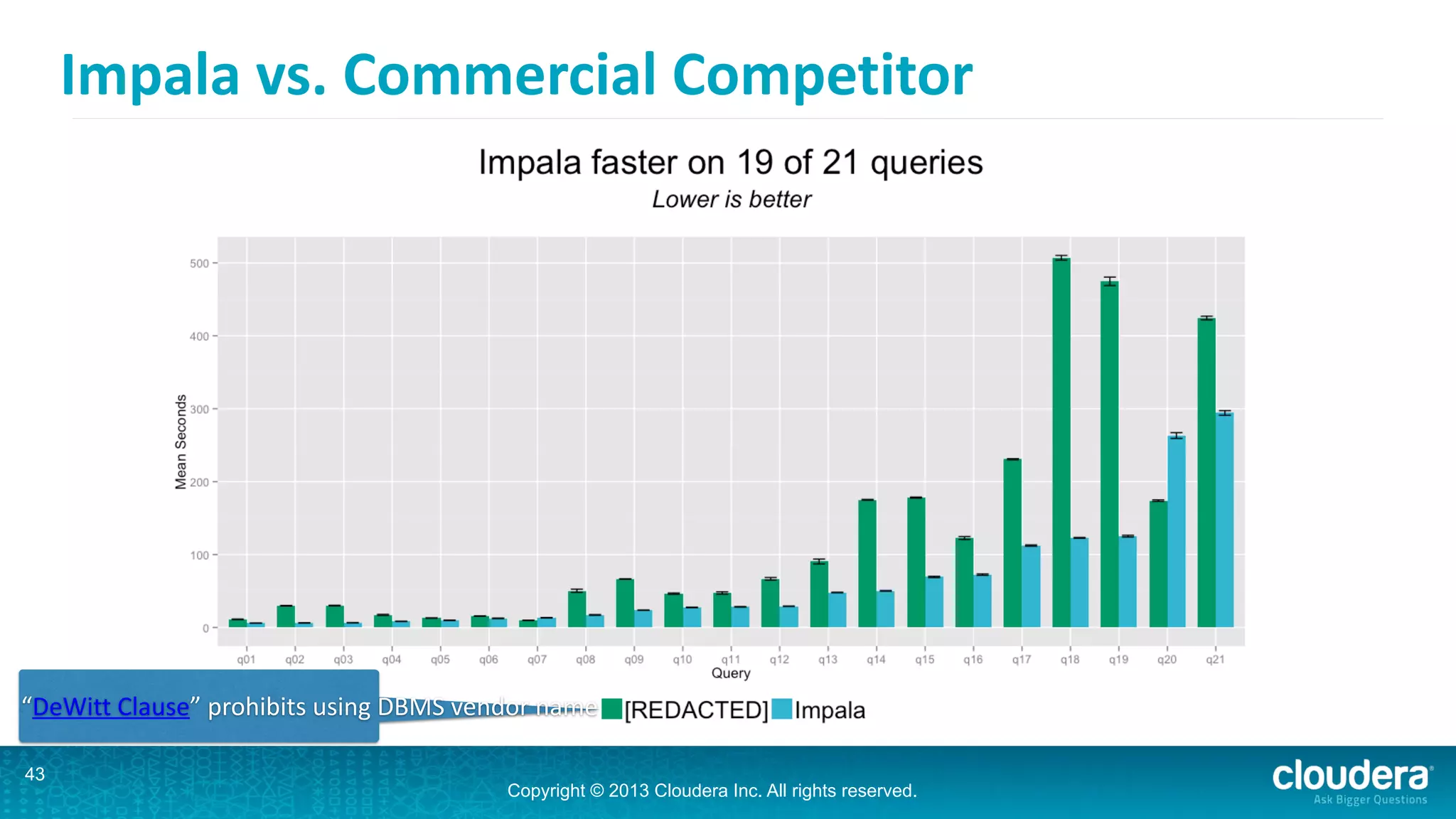


Impala is an open-source SQL query engine for Hadoop that is designed for performance. It utilizes standard Hadoop components like HDFS, HBase, and YARN. Impala allows users to issue SQL queries against data stored in HDFS and HBase and returns results very quickly. It exposes industry-standard interfaces that allow business intelligence tools to connect. Impala has added many new features in recent versions like analytic functions, subqueries, and support for joining and aggregating data that can spill to disk.
























































![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)






![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)






![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)




