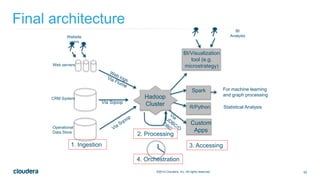
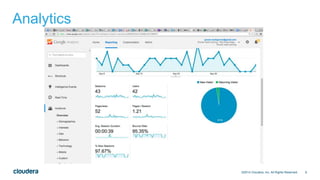
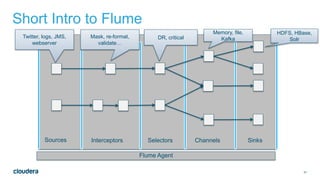
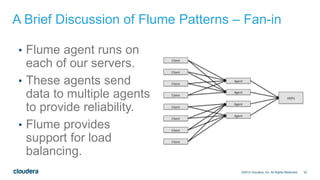
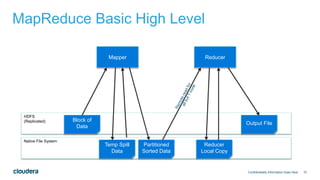
The document discusses architectural considerations for implementing clickstream analytics using Hadoop. It covers choices for data storage layers like HDFS vs HBase, data modeling including file formats and partitioning, data ingestion methods like Flume and Sqoop, available processing engines like MapReduce, Hive, Spark and Impala, and the need to sessionize clickstream data to analyze metrics like bounce rates and attribution.






![7
Web Logs – Combined Log Format
©2014 Cloudera, Inc. All Rights Reserved.
244.157.45.12 - - [17/Oct/2014:21:08:30 ] "GET /seatposts HTTP/1.0"
200 4463 "http://bestcyclingreviews.com/top_online_shops"
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/36.0.1944.0 Safari/537.36”
244.157.45.12 - - [17/Oct/2014:21:59:59 ] "GET
/Store/cart.jsp?productID=1023 HTTP/1.0" 200 3757
"http://www.casualcyclist.com" "Mozilla/5.0 (Linux; U; Android
2.3.5; en-us; HTC Vision Build/GRI40) AppleWebKit/533.1 (KHTML, like
Gecko) Version/4.0 Mobile Safari/533.1”](https://image.slidesharecdn.com/datadayseattle-150625230037-lva1-app6891/85/Architecting-Applications-with-Hadoop-7-320.jpg)
![8
Clickstream Analytics
©2014 Cloudera, Inc. All Rights Reserved.
244.157.45.12 - -
[17/Oct/2014:21:08:30 ] "GET
/seatposts HTTP/1.0" 200 4463
"http://bestcyclingreviews.com/top
_online_shops" "Mozilla/5.0
(Macintosh; Intel Mac OS X 10_9_2)
AppleWebKit/537.36 (KHTML, like
Gecko) Chrome/36.0.1944.0
Safari/537.36”](https://image.slidesharecdn.com/datadayseattle-150625230037-lva1-app6891/85/Architecting-Applications-with-Hadoop-8-320.jpg)




































![48
#1 – Which clicks are from same user?
©2014 Cloudera, Inc. All Rights Reserved.
244.157.45.12 - - [17/Oct/2014:21:08:30 ] "GET /seatposts HTTP/1.0" 200 4463
"http://bestcyclingreviews.com/top_online_shops" "Mozilla/5.0 (Macintosh; Intel Mac OS X
10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1944.0 Safari/537.36”
244.157.45.12 - - [17/Oct/2014:21:59:59 ] "GET /Store/cart.jsp?productID=1023 HTTP/1.0"
200 3757 "http://www.casualcyclist.com" "Mozilla/5.0 (Linux; U; Android 2.3.5; en-us; HTC
Vision Build/GRI40) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile
Safari/533.1”](https://image.slidesharecdn.com/datadayseattle-150625230037-lva1-app6891/85/Architecting-Applications-with-Hadoop-48-320.jpg)
![49
#2 – Which clicks part of the same session?
©2014 Cloudera, Inc. All Rights Reserved.
244.157.45.12 - - [17/Oct/2014:21:08:30 ] "GET /seatposts HTTP/1.0" 200 4463
"http://bestcyclingreviews.com/top_online_shops" "Mozilla/5.0 (Macintosh; Intel Mac OS X
10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1944.0 Safari/537.36”
244.157.45.12 - - [17/Oct/2014:21:59:59 ] "GET /Store/cart.jsp?productID=1023 HTTP/1.0"
200 3757 "http://www.casualcyclist.com" "Mozilla/5.0 (Linux; U; Android 2.3.5; en-us; HTC
Vision Build/GRI40) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile
Safari/533.1”
> 30 mins apart = different
sessions](https://image.slidesharecdn.com/datadayseattle-150625230037-lva1-app6891/85/Architecting-Applications-with-Hadoop-49-320.jpg)

![51
Filtering – filter out incomplete records
©2014 Cloudera, Inc. All Rights Reserved.
244.157.45.12 - - [17/Oct/2014:21:08:30 ] "GET /seatposts HTTP/1.0" 200 4463
"http://bestcyclingreviews.com/top_online_shops" "Mozilla/5.0 (Macintosh; Intel Mac OS X
10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1944.0 Safari/537.36”
244.157.45.12 - - [17/Oct/2014:21:59:59 ] "GET /Store/cart.jsp?productID=1023 HTTP/1.0"
200 3757 "http://www.casualcyclist.com" "Mozilla/5.0 (Linux; U…](https://image.slidesharecdn.com/datadayseattle-150625230037-lva1-app6891/85/Architecting-Applications-with-Hadoop-51-320.jpg)
![52
Filtering – filter out records from bots/spiders
©2014 Cloudera, Inc. All Rights Reserved.
244.157.45.12 - - [17/Oct/2014:21:08:30 ] "GET /seatposts HTTP/1.0" 200 4463
"http://bestcyclingreviews.com/top_online_shops" "Mozilla/5.0 (Macintosh; Intel Mac OS X
10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1944.0 Safari/537.36”
209.85.238.11 - - [17/Oct/2014:21:59:59 ] "GET /Store/cart.jsp?productID=1023 HTTP/1.0"
200 3757 "http://www.casualcyclist.com" "Mozilla/5.0 (Linux; U; Android 2.3.5; en-us; HTC
Vision Build/GRI40) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile
Safari/533.1”
Google spider IP address](https://image.slidesharecdn.com/datadayseattle-150625230037-lva1-app6891/85/Architecting-Applications-with-Hadoop-52-320.jpg)

![54
Deduplication – remove duplicate records
©2014 Cloudera, Inc. All Rights Reserved.
244.157.45.12 - - [17/Oct/2014:21:08:30 ] "GET /seatposts HTTP/1.0" 200 4463
"http://bestcyclingreviews.com/top_online_shops" "Mozilla/5.0 (Macintosh; Intel Mac OS X
10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1944.0 Safari/537.36”
244.157.45.12 - - [17/Oct/2014:21:08:30 ] "GET /seatposts HTTP/1.0" 200 4463
"http://bestcyclingreviews.com/top_online_shops" "Mozilla/5.0 (Macintosh; Intel Mac OS X
10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1944.0 Safari/537.36”](https://image.slidesharecdn.com/datadayseattle-150625230037-lva1-app6891/85/Architecting-Applications-with-Hadoop-54-320.jpg)