



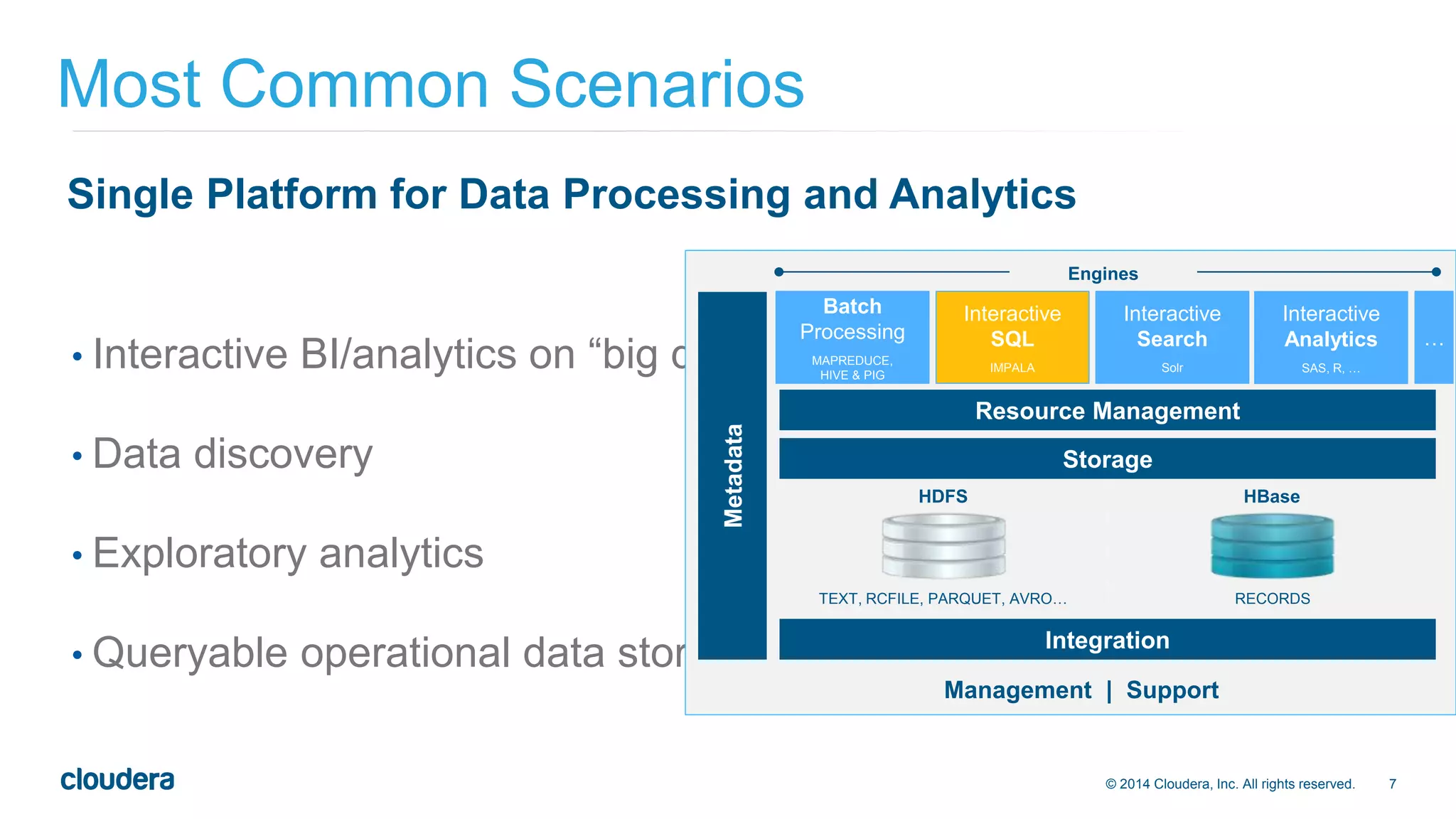




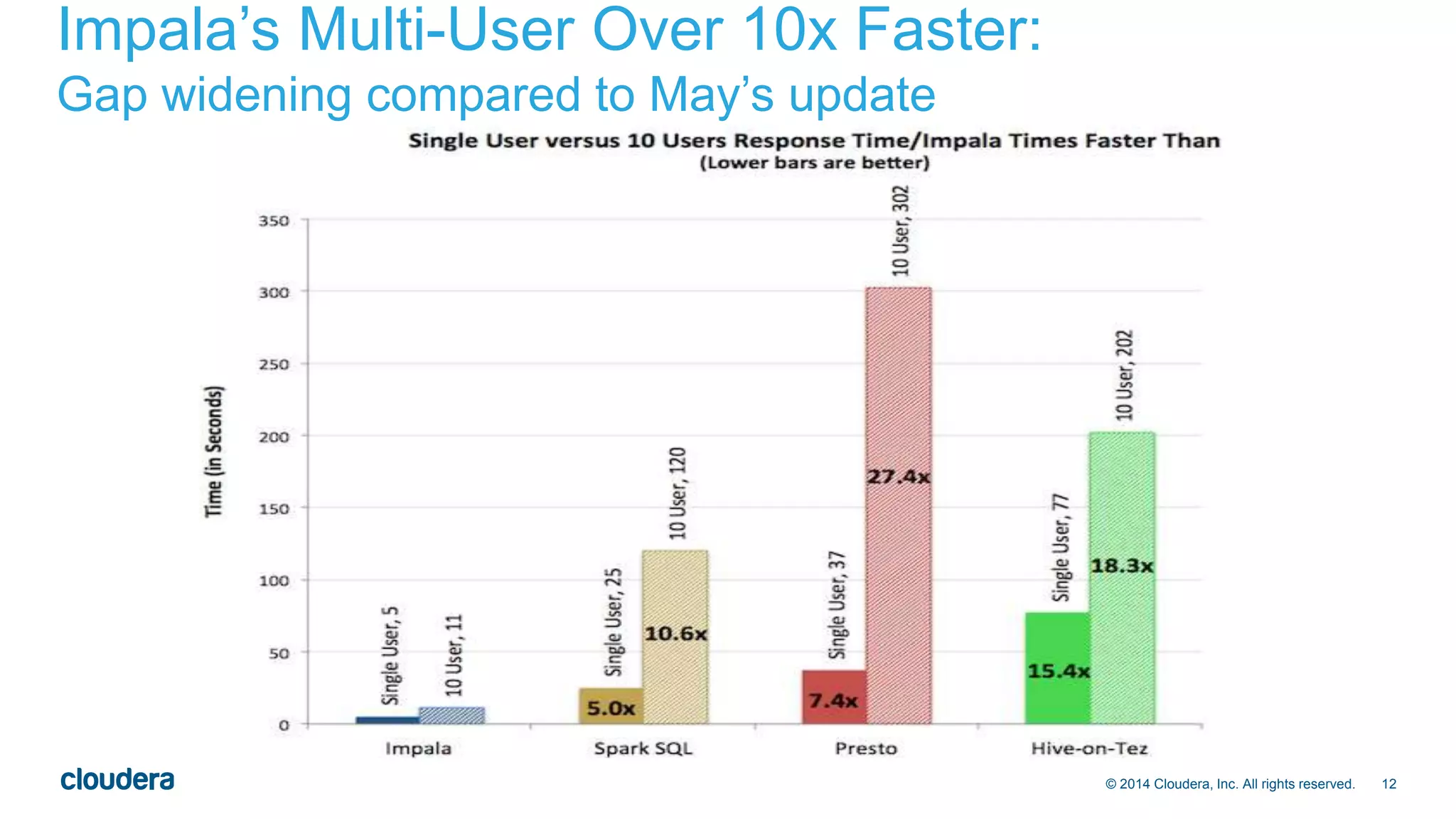
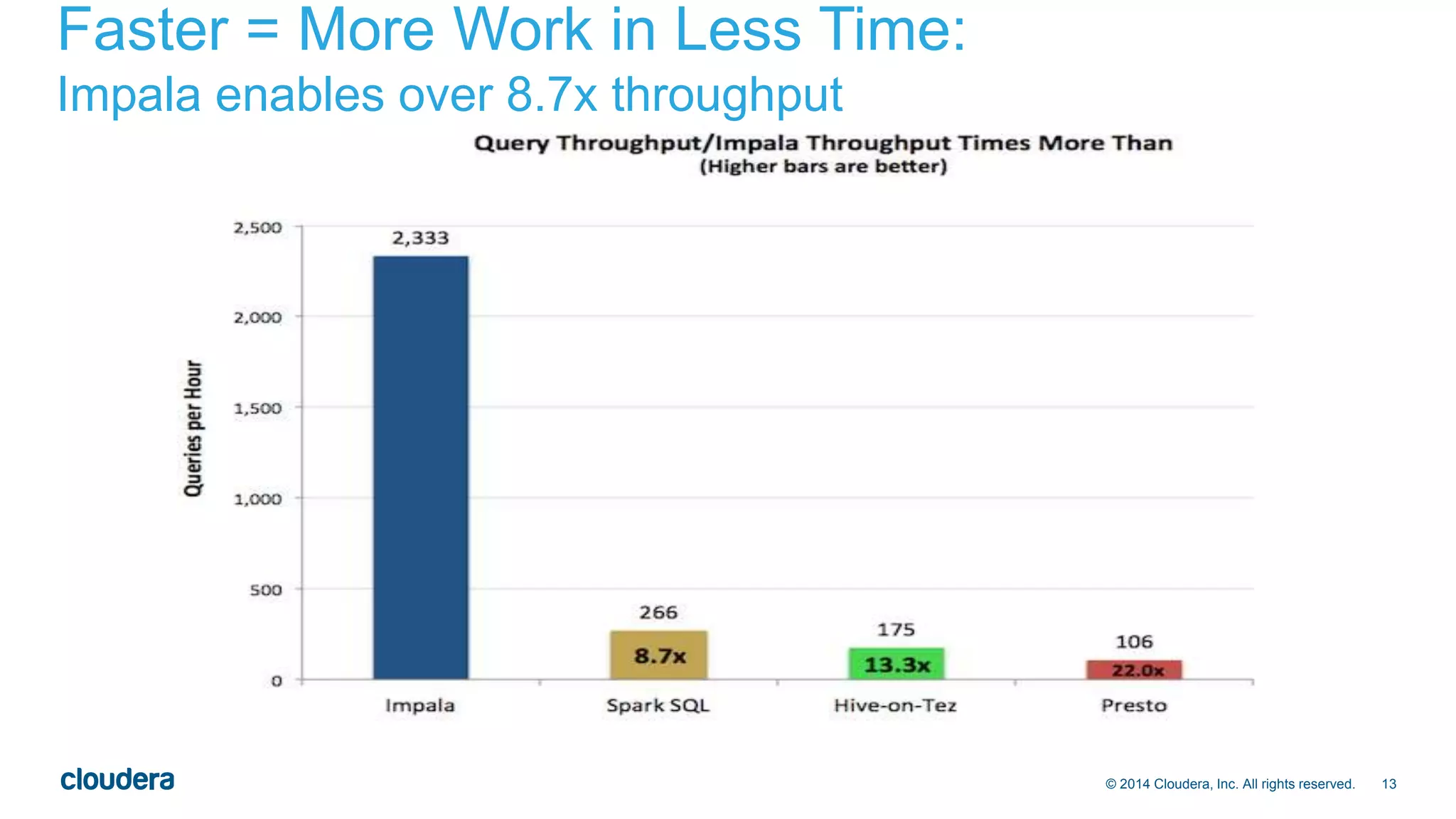




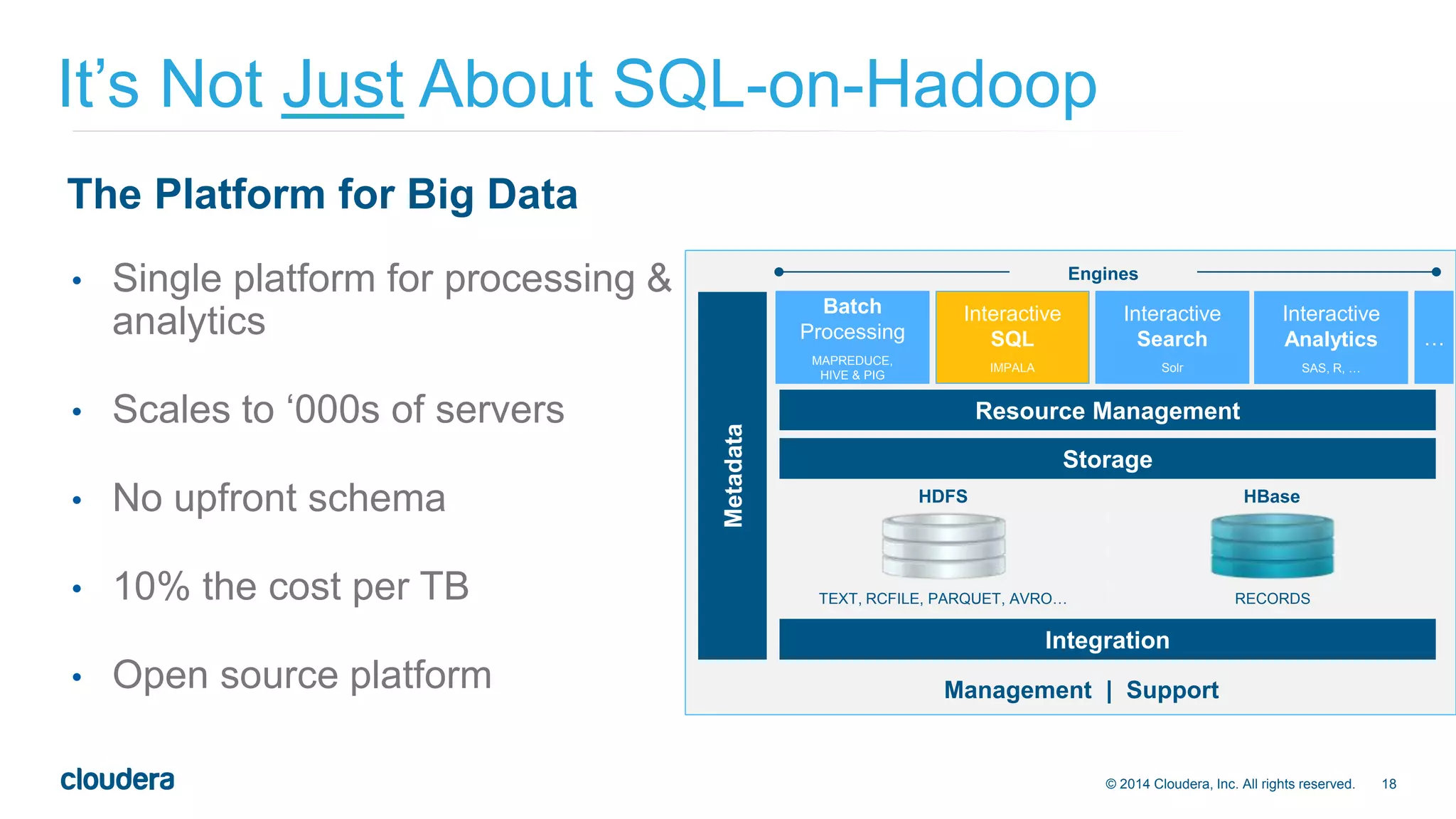



The document presents an overview of Impala 2.0, an analytic database for Hadoop developed by Cloudera, highlighting its features, performance advantages, and use cases such as data discovery and operational dashboards. It emphasizes Impala's compatibility with standard SQL, multi-user performance enhancements, and ability to handle large data workloads efficiently. Additionally, it outlines the evolution of Impala through various versions and discusses future developments in usability, compatibility, and multi-user performance.











































































































