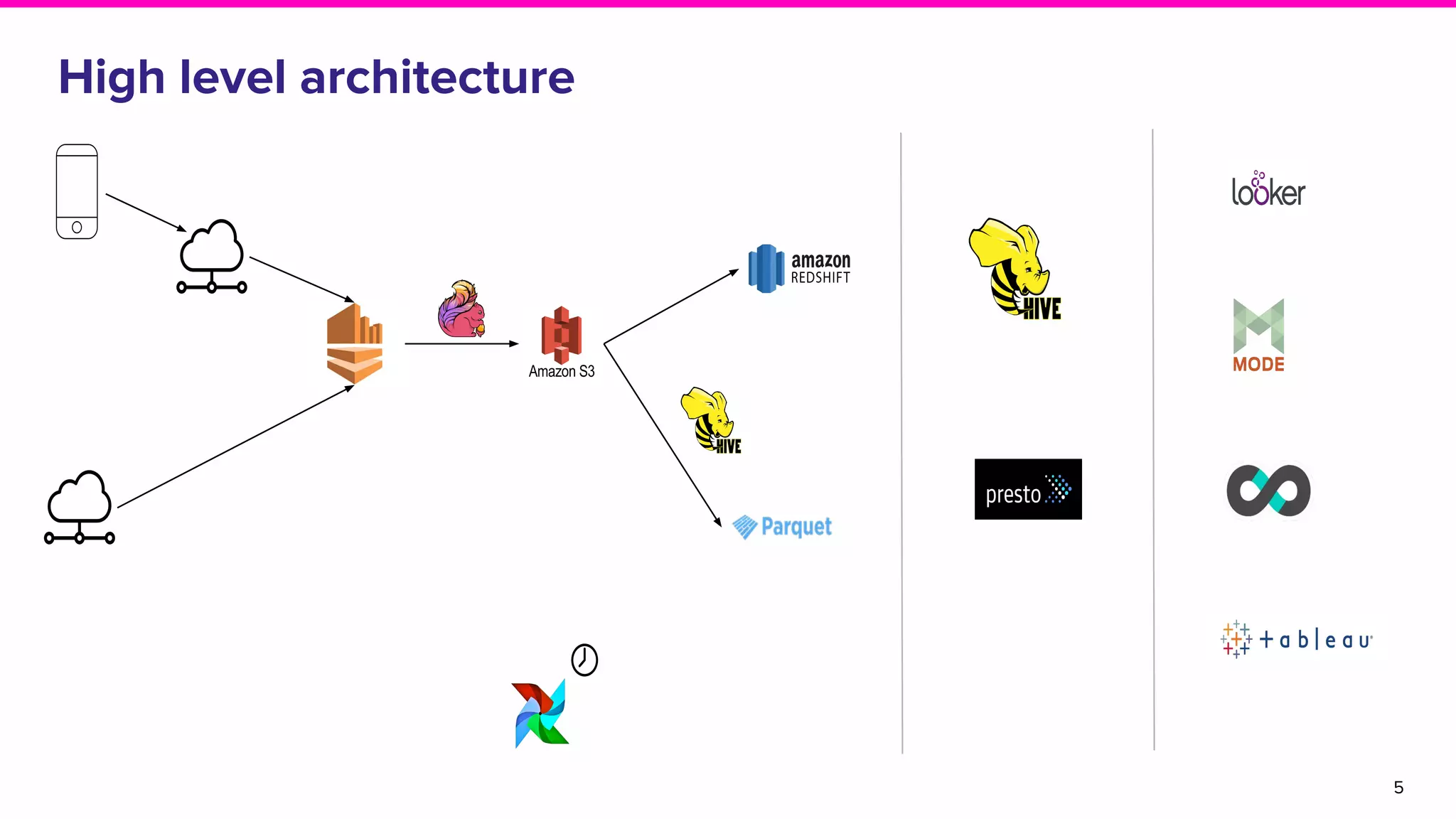
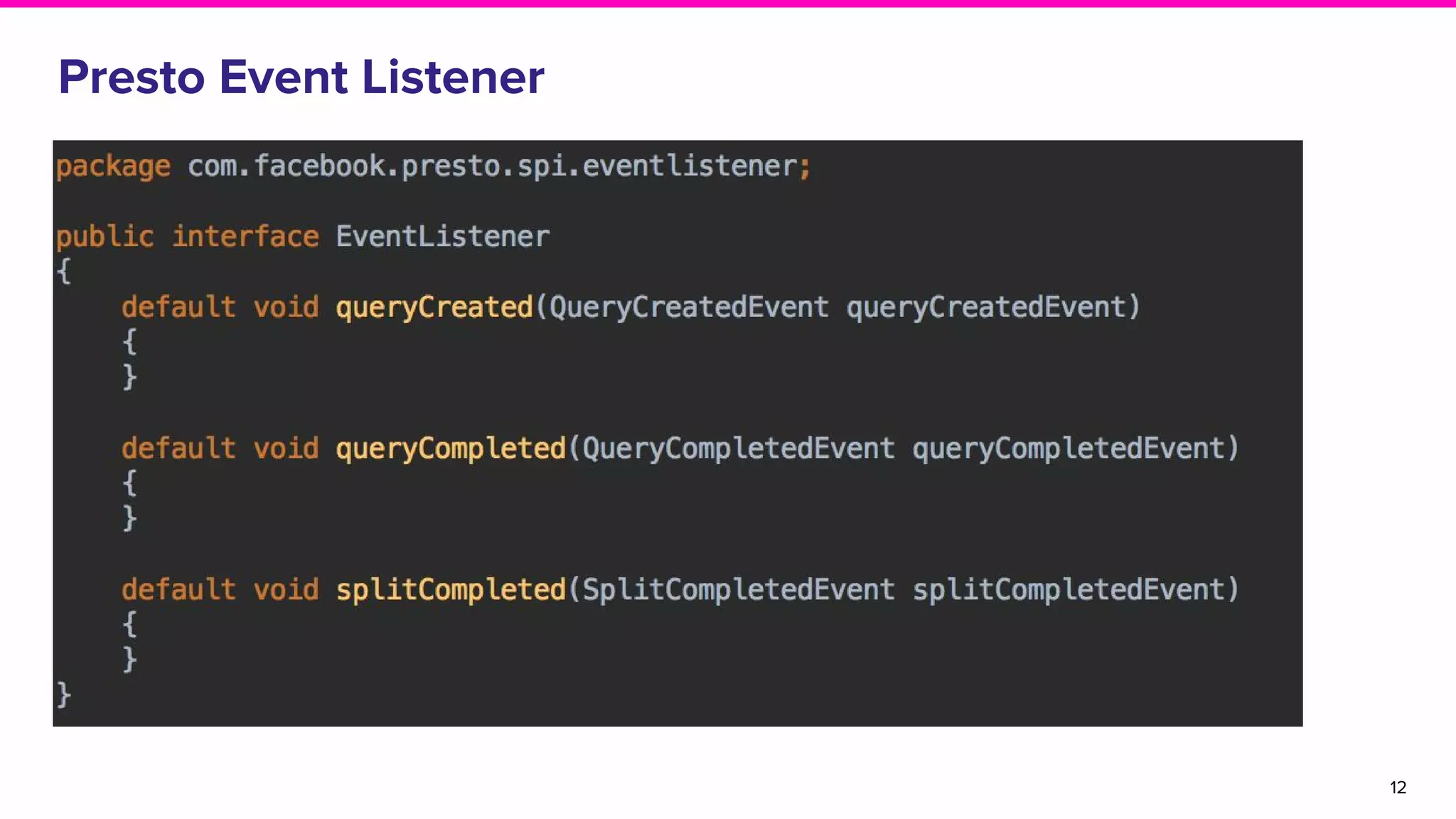
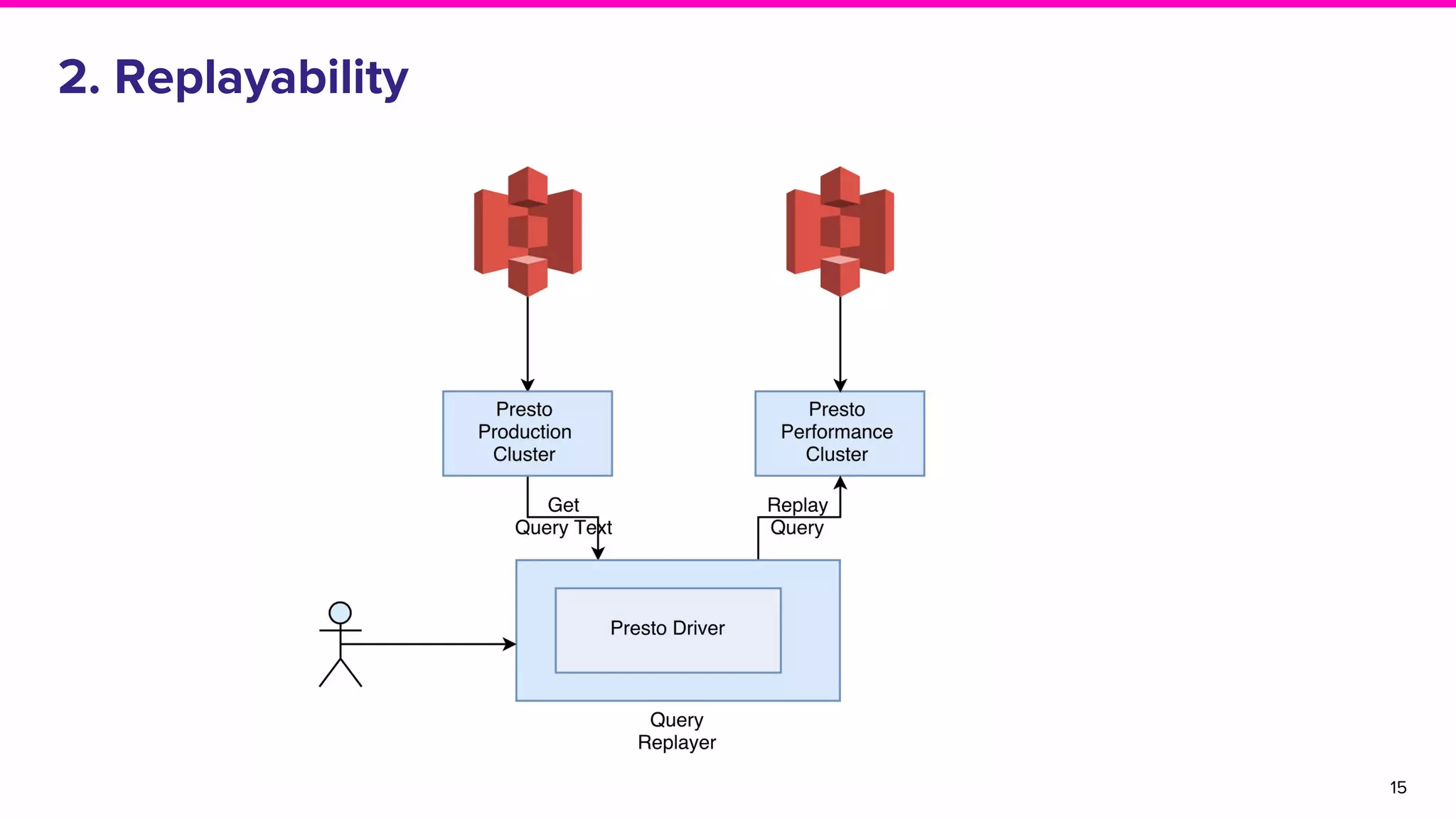
The document discusses the goals and architecture of Lyft’s data platform, emphasizing user roles including data modelers, analysts, and engineers. It highlights the importance of dogfooding the platform to analyze its usage and improve functionalities like auditing, replayability, error analysis, performance monitoring, and experimentation. The overall aim is to enhance the platform's effectiveness while engaging various users in the process.