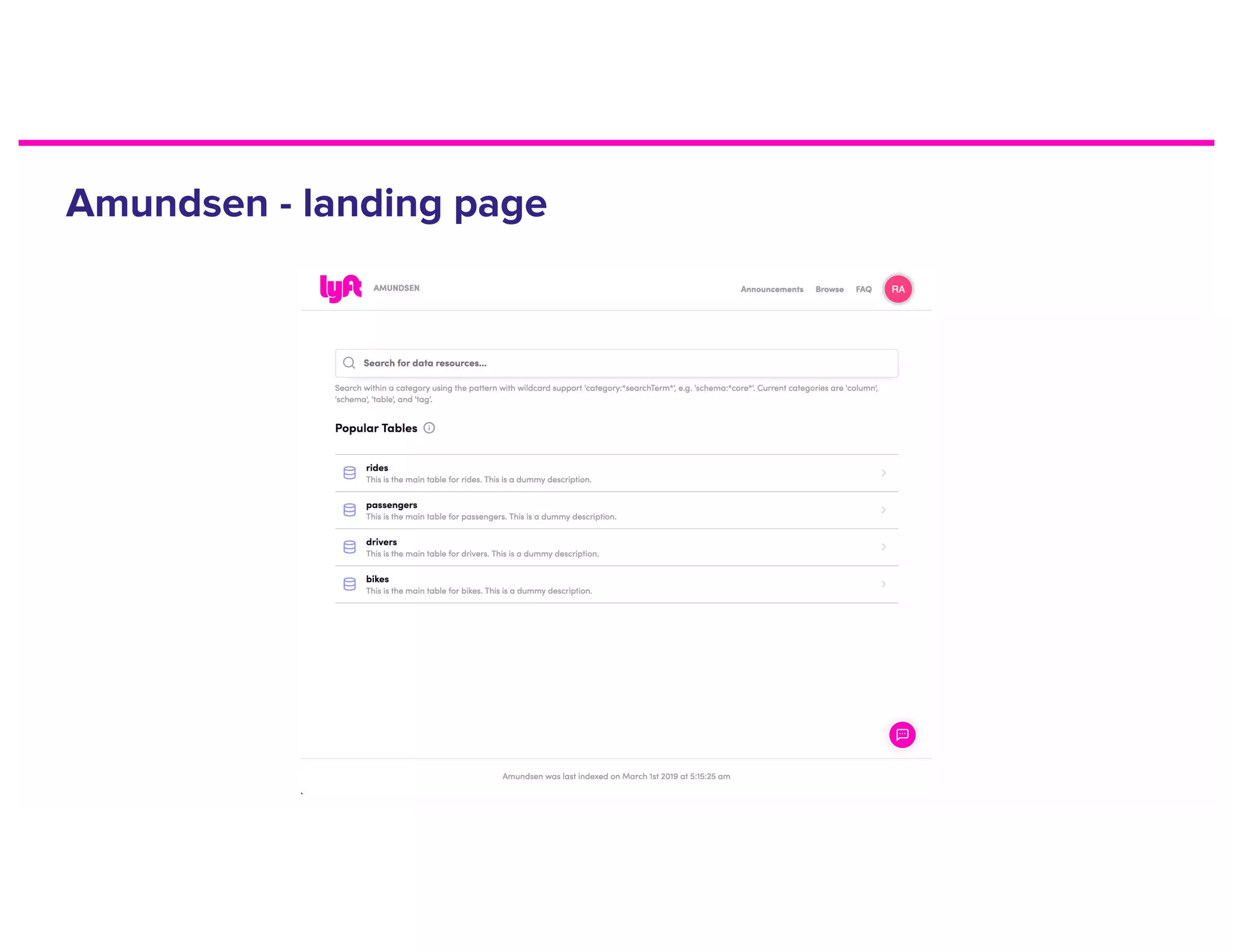
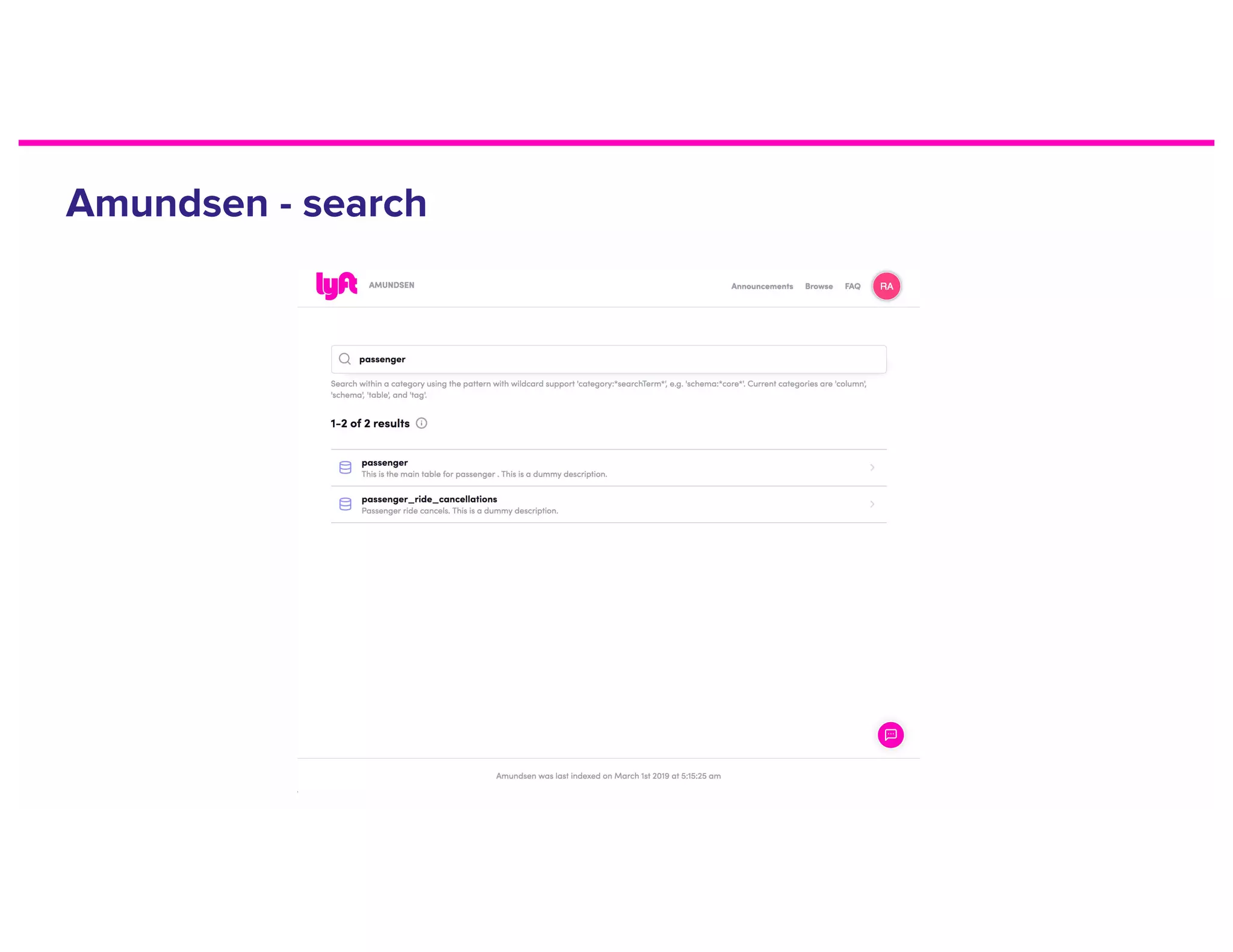
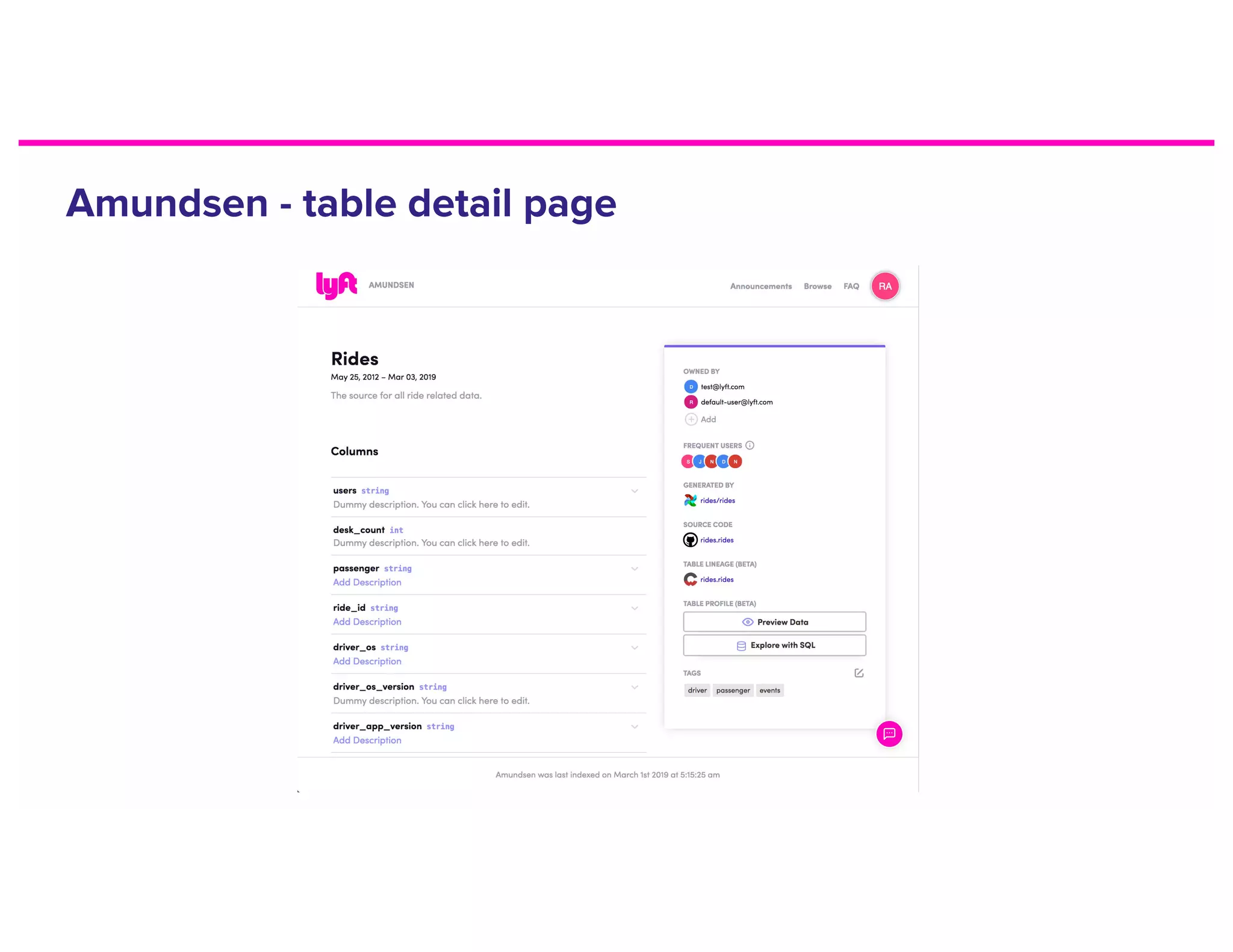
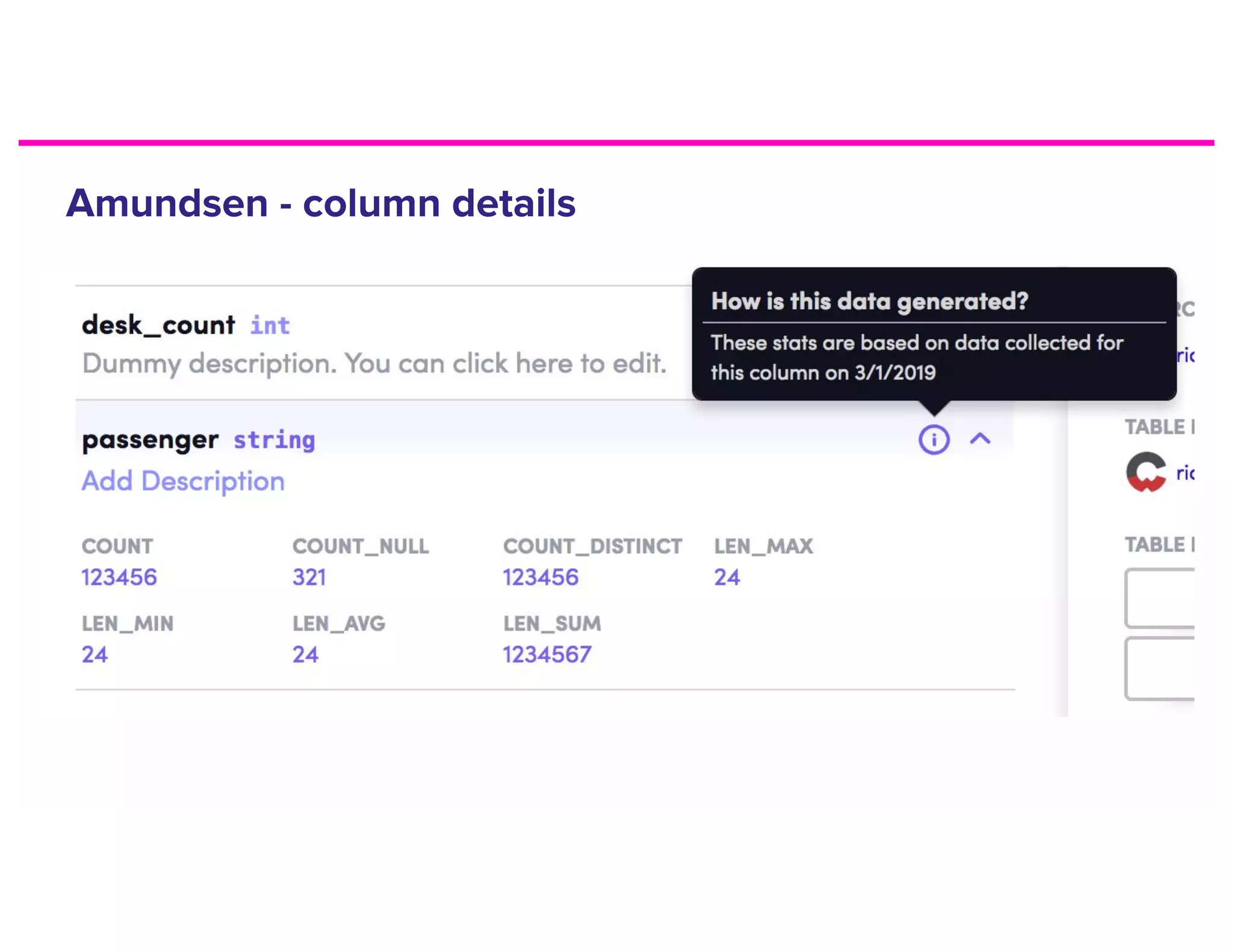
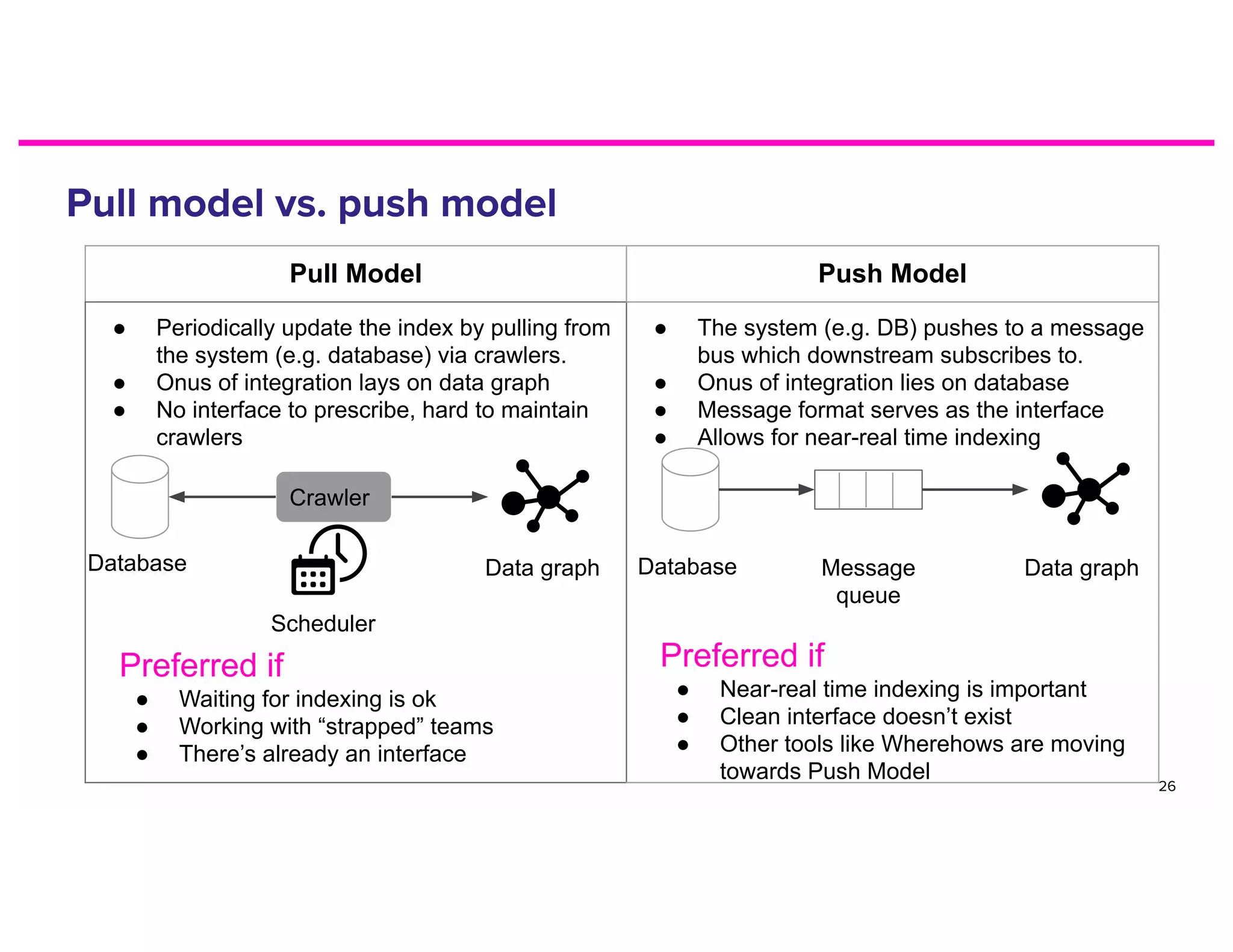
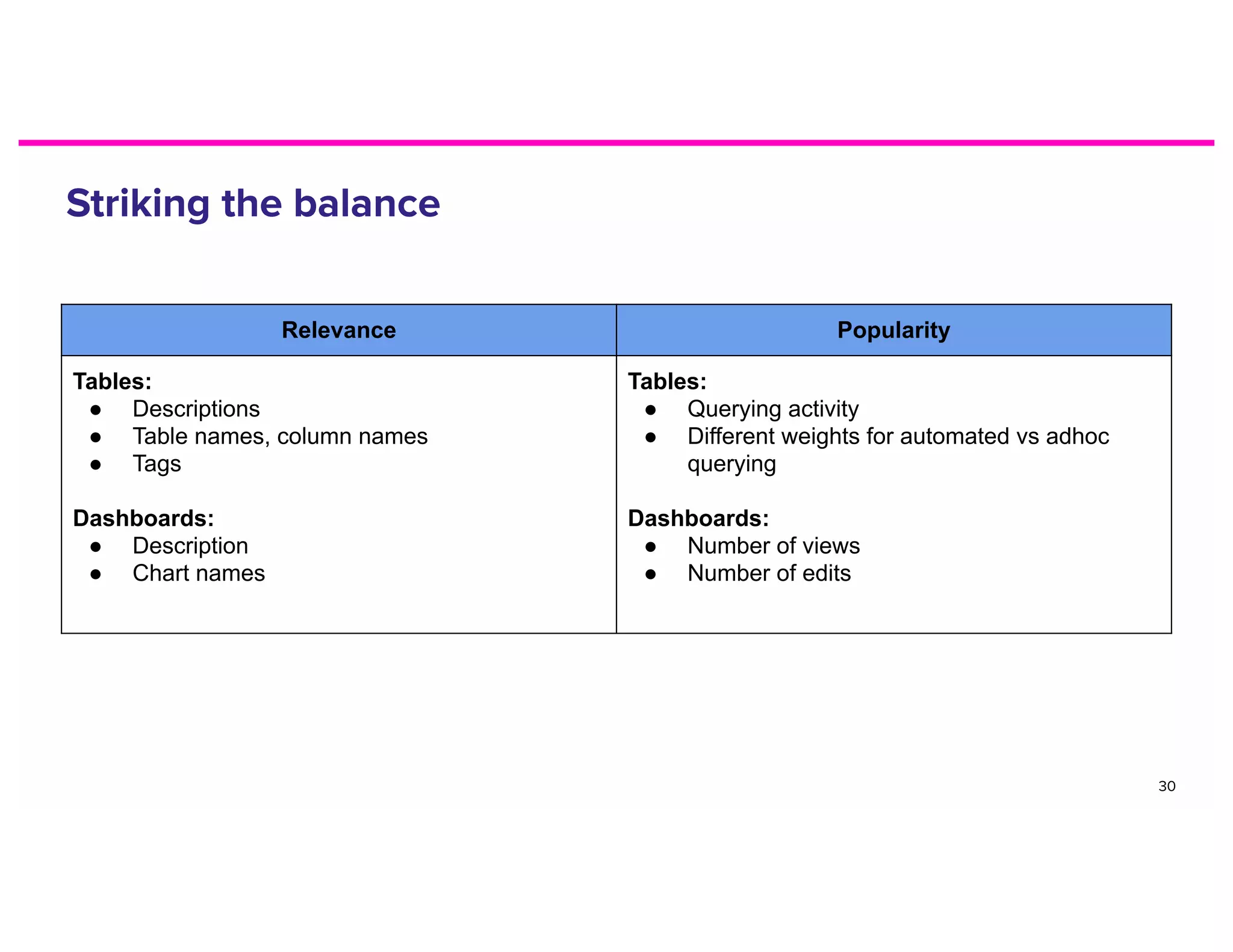
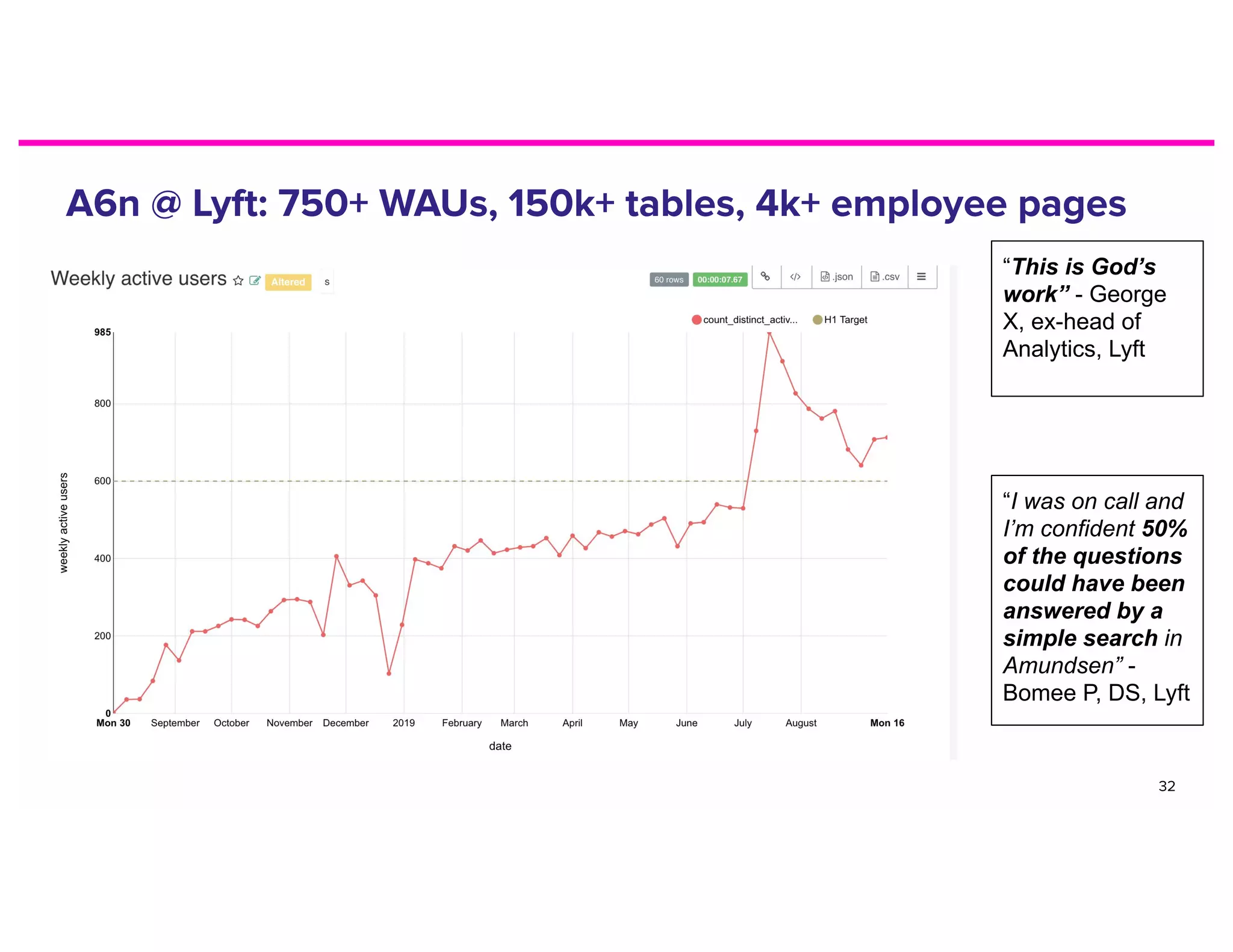
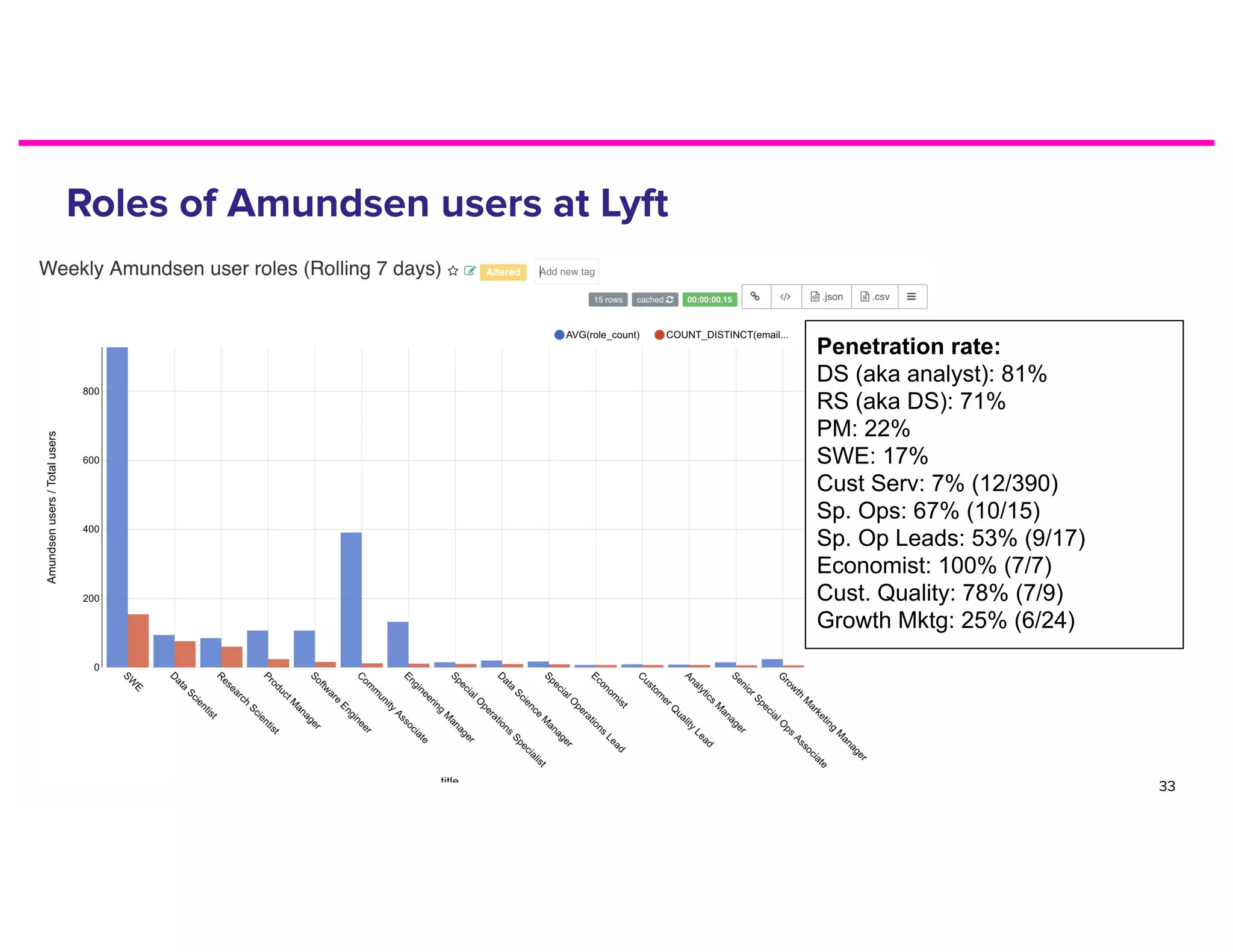
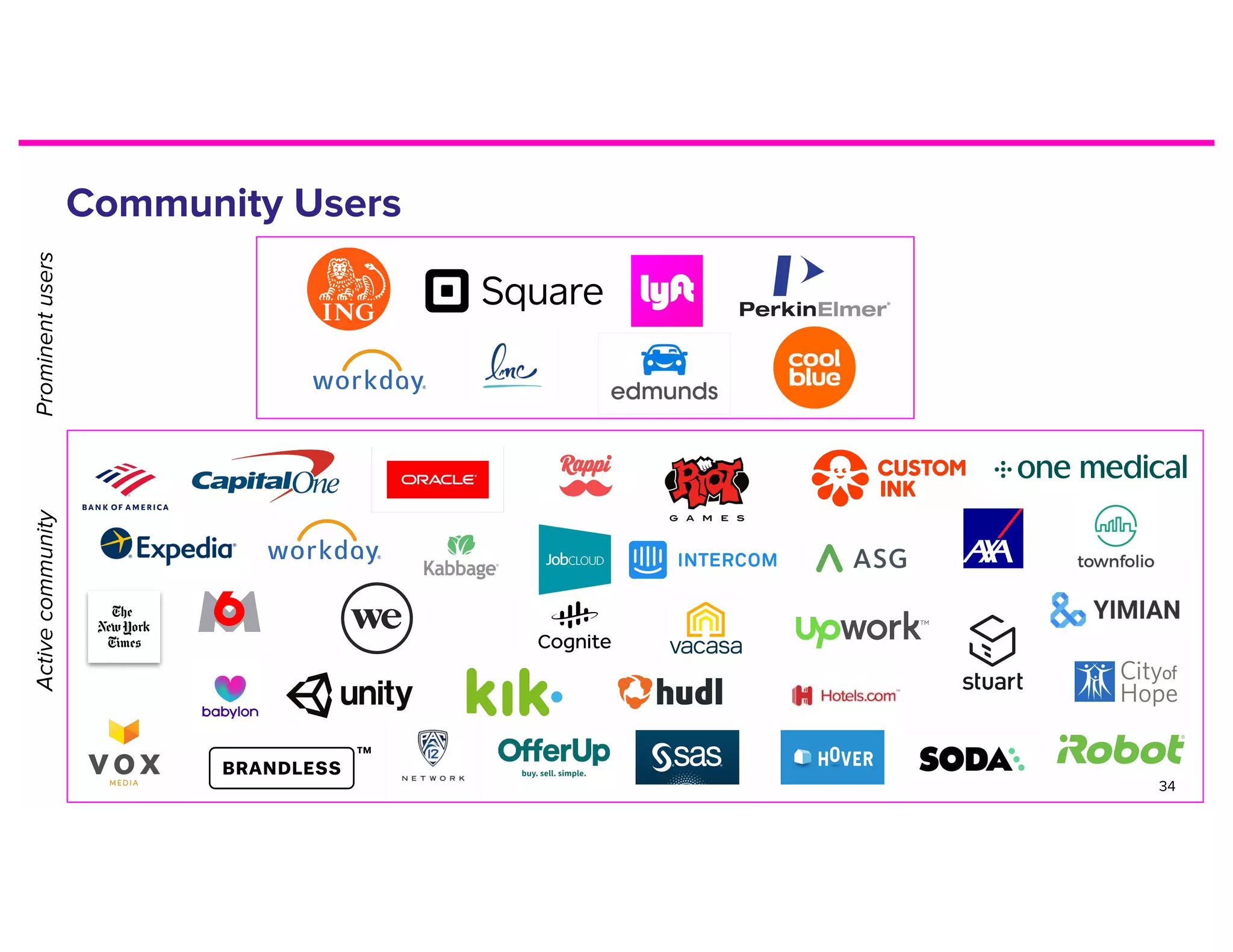
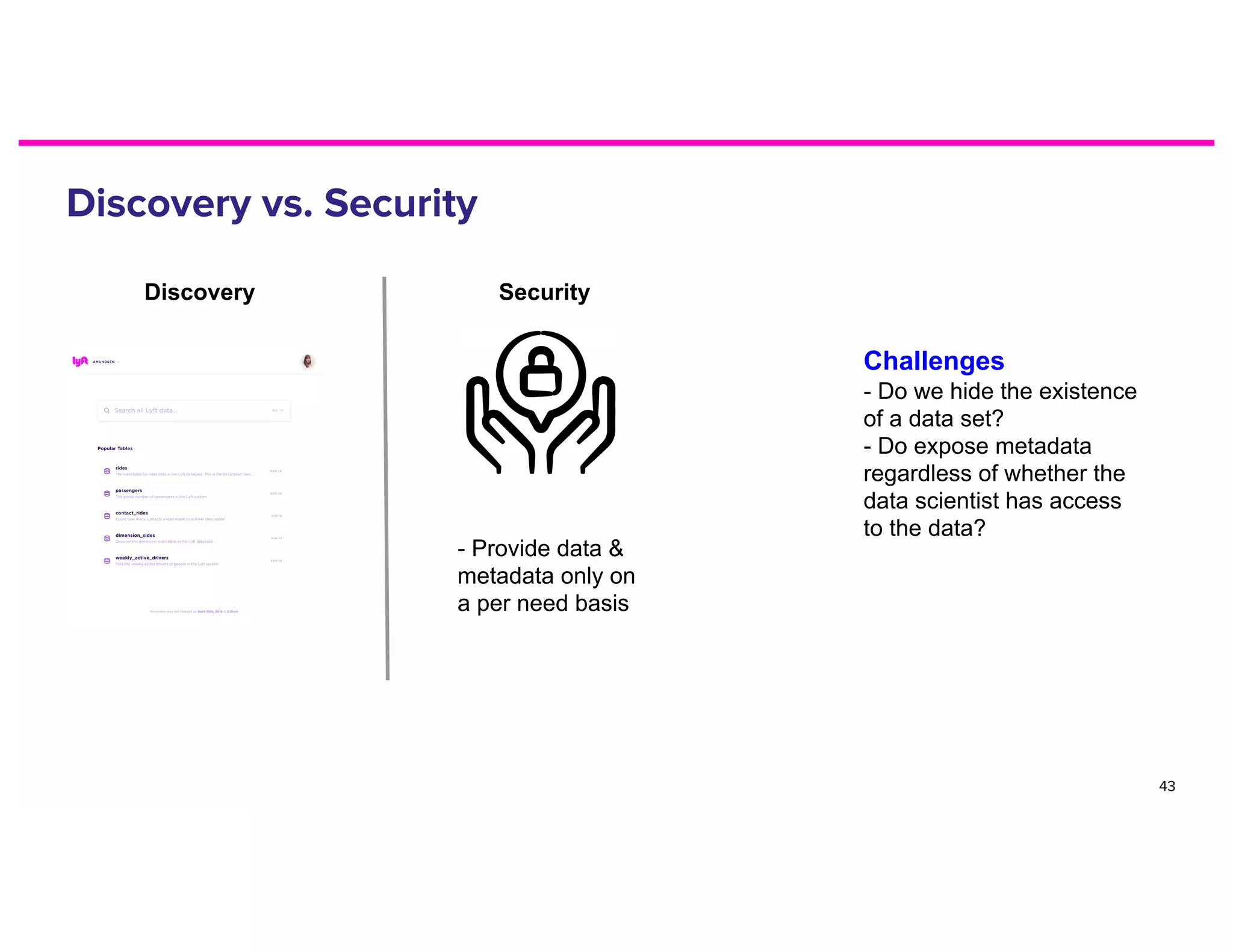
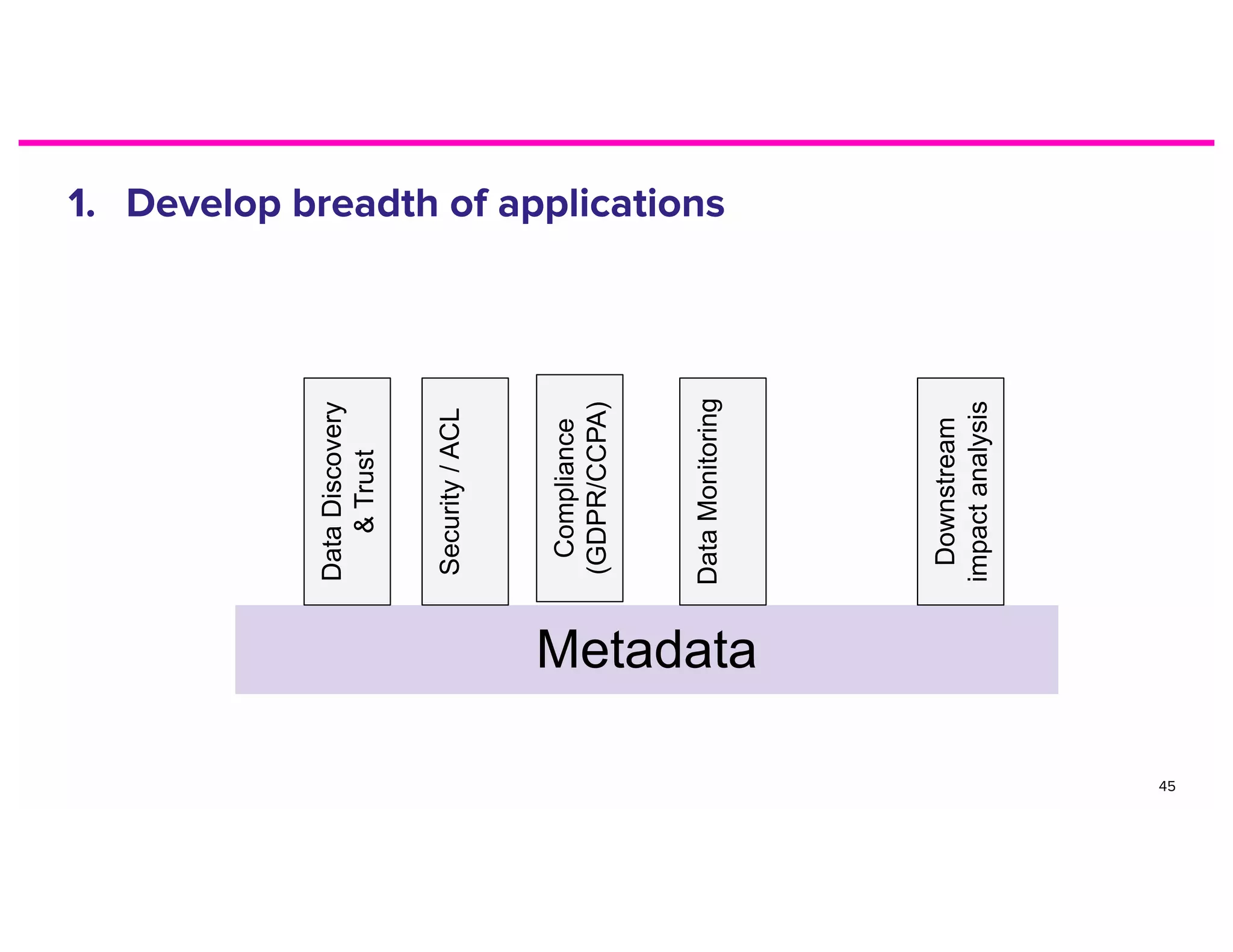
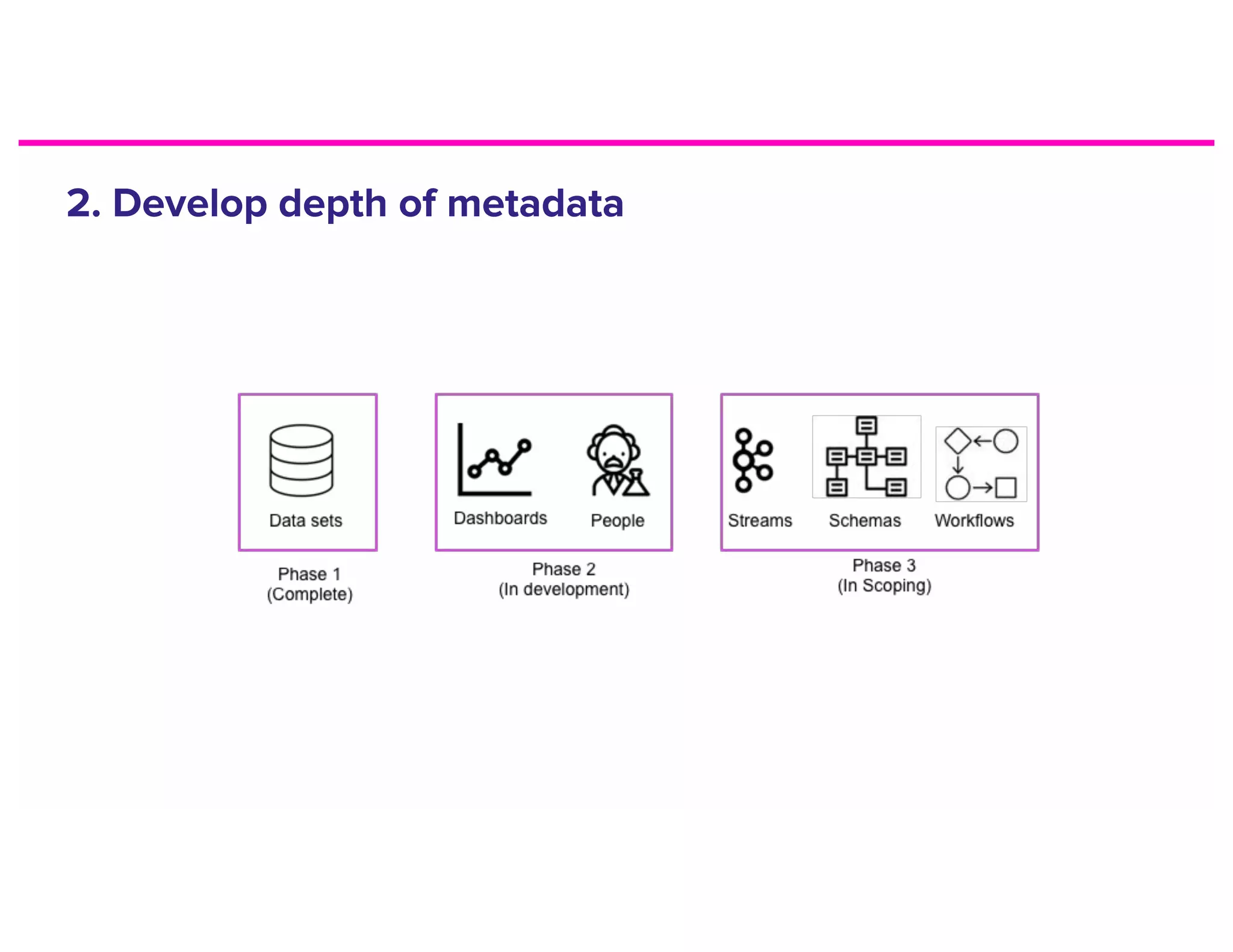
The document discusses metadata and the need for a metadata discovery tool. It provides an overview of metadata, describes different types of users and their needs related to finding and understanding data. It also evaluates different architectural approaches for a metadata graph and considerations for security, guidelines, and other challenges in building such a tool.




























































![The Evolution of Metadata: LinkedIn's Story [Strata NYC 2019]](https://cdn.slidesharecdn.com/ss_thumbnails/metadatajourneylinkedinstratapublic-190930045839-thumbnail.jpg?width=640&height=640&fit=bounds)








































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)












