Download as PDF, PPTX





















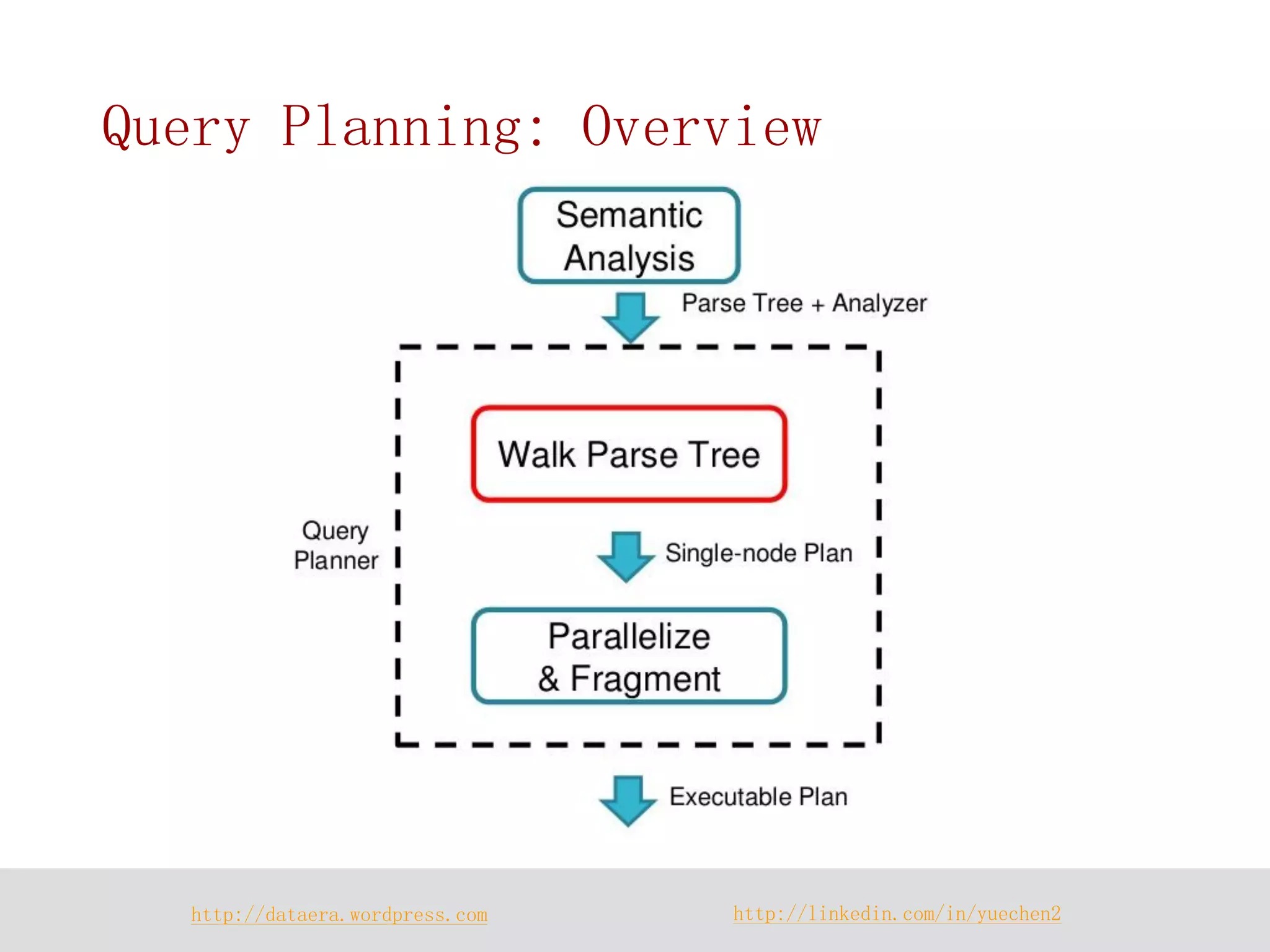

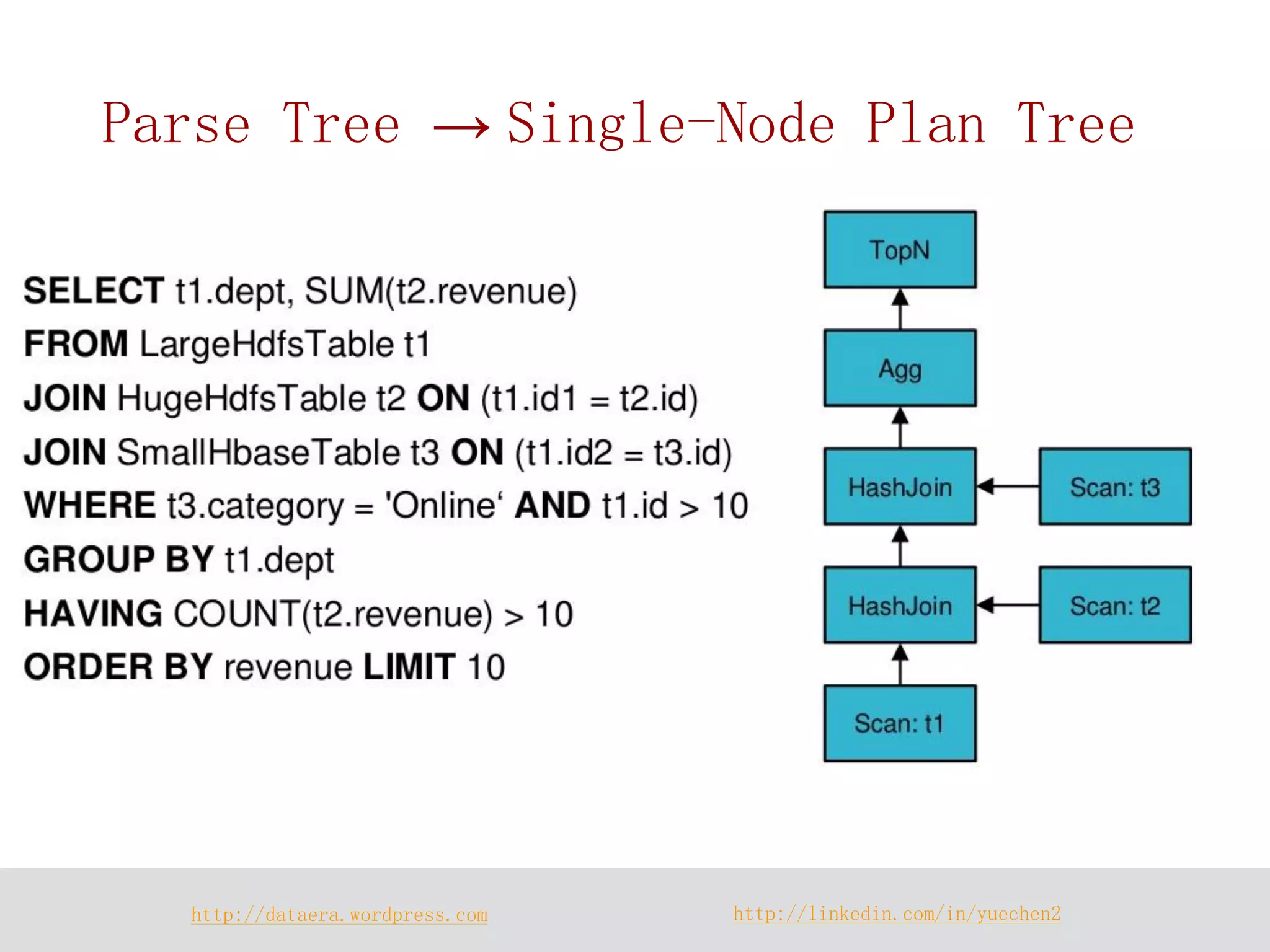
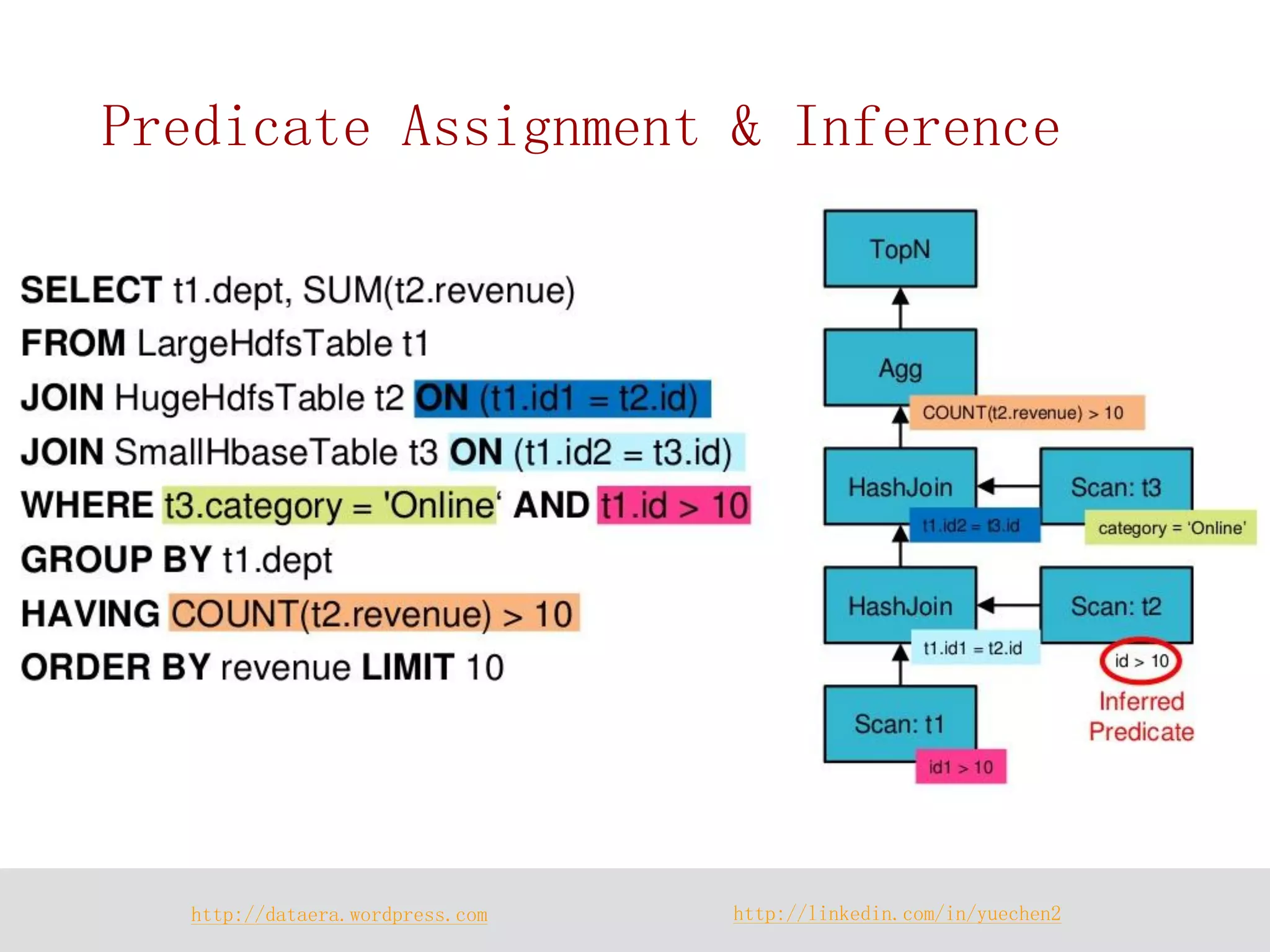


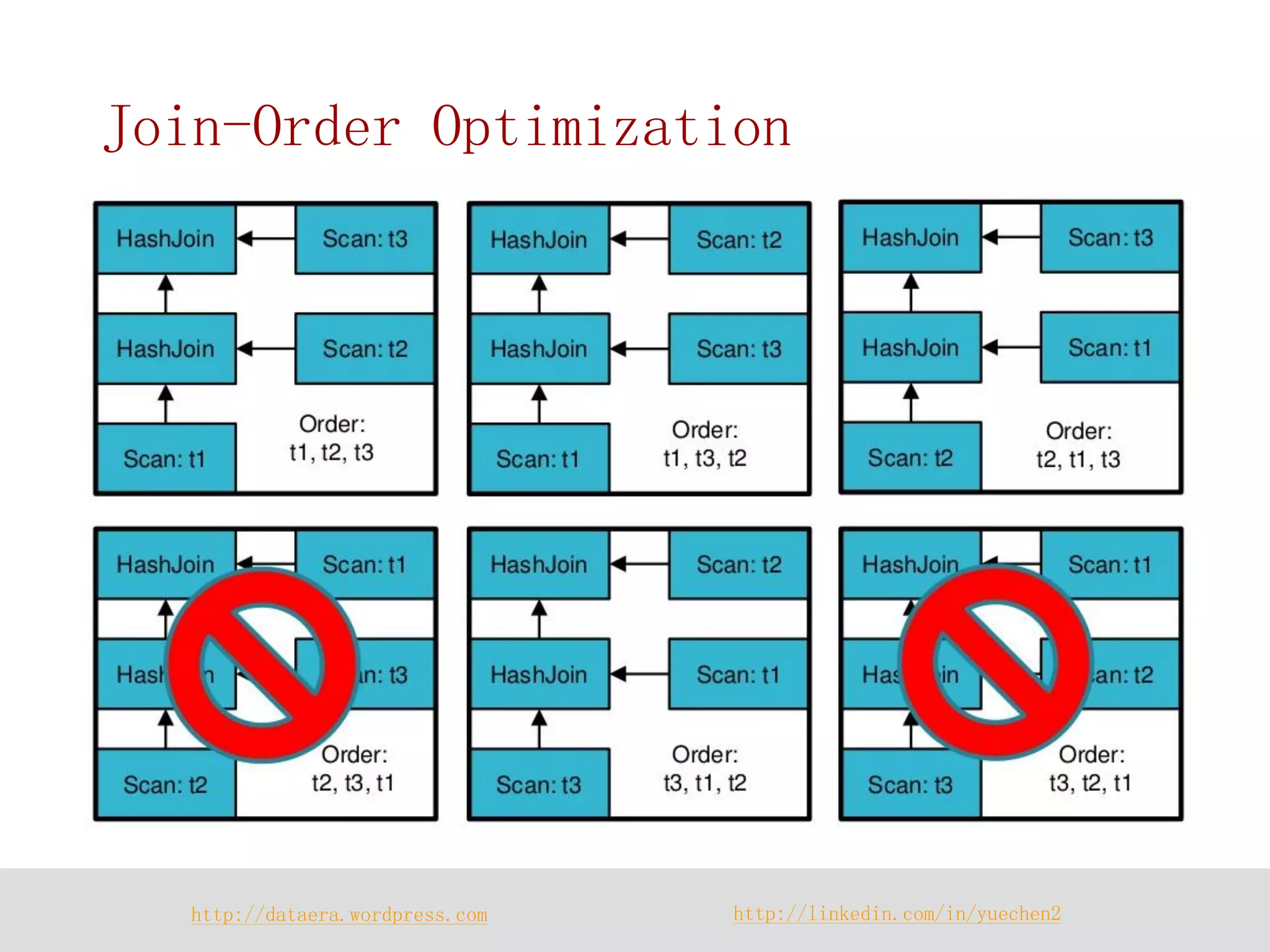

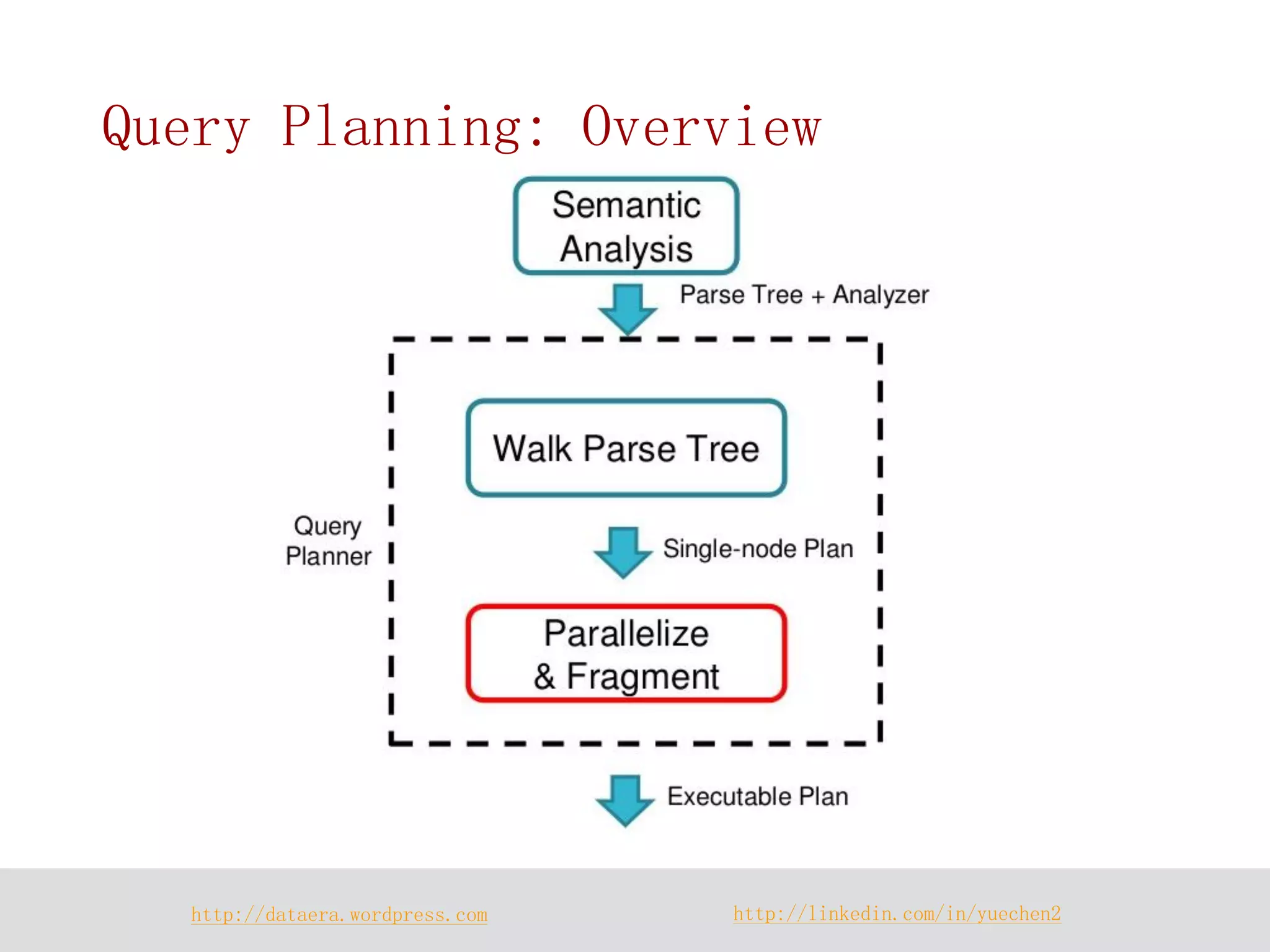



![http://dataera.wordpress.com
http://linkedin.com/in/yuechen2
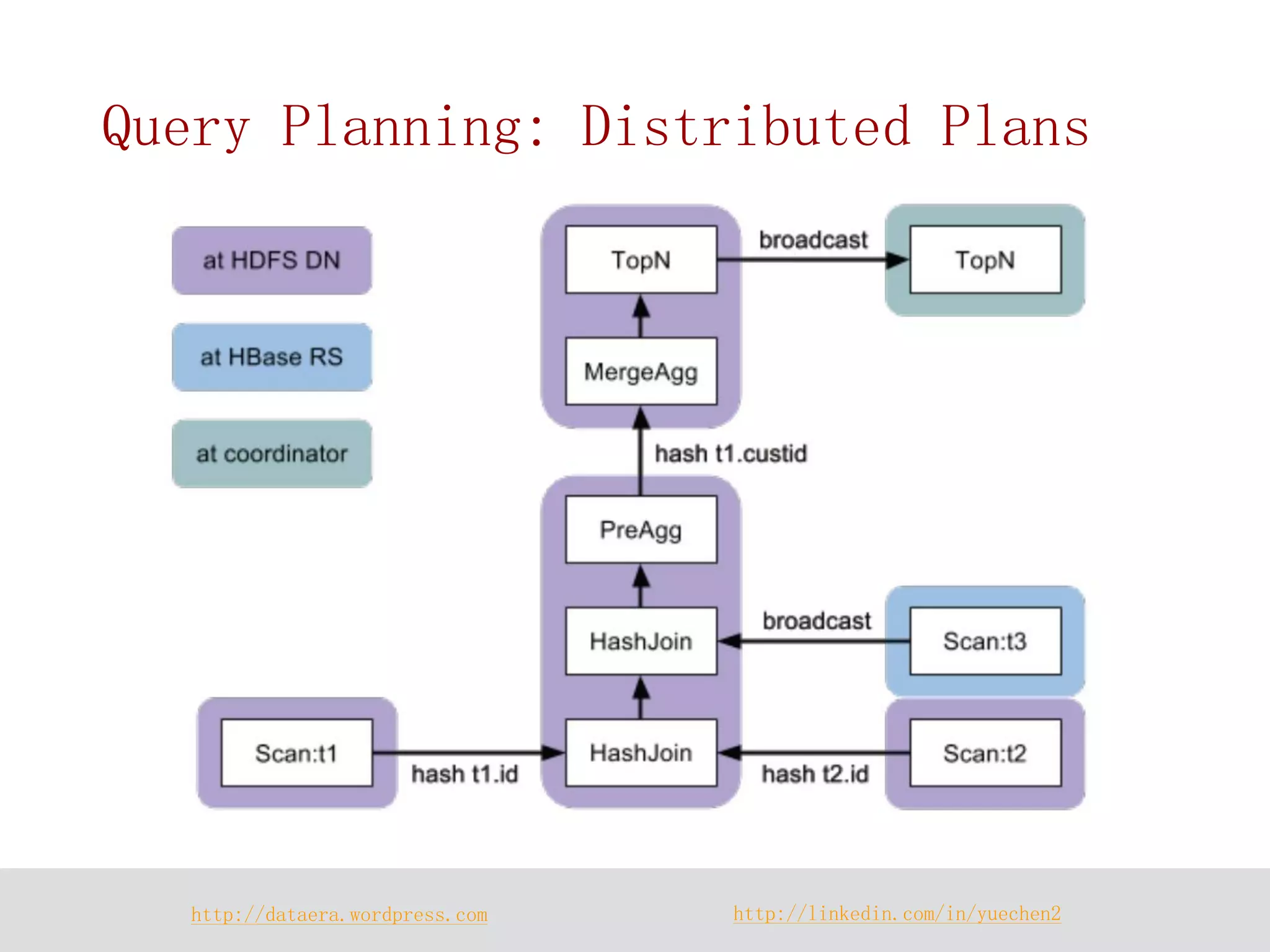
Join Hint
select …
from large_table
join [broadcast] small_table
select …
from large_table
join [shuffle] large_table](https://image.slidesharecdn.com/howimpalaworks-140902012319-phpapp01/75/How-Impala-Works-42-2048.jpg)










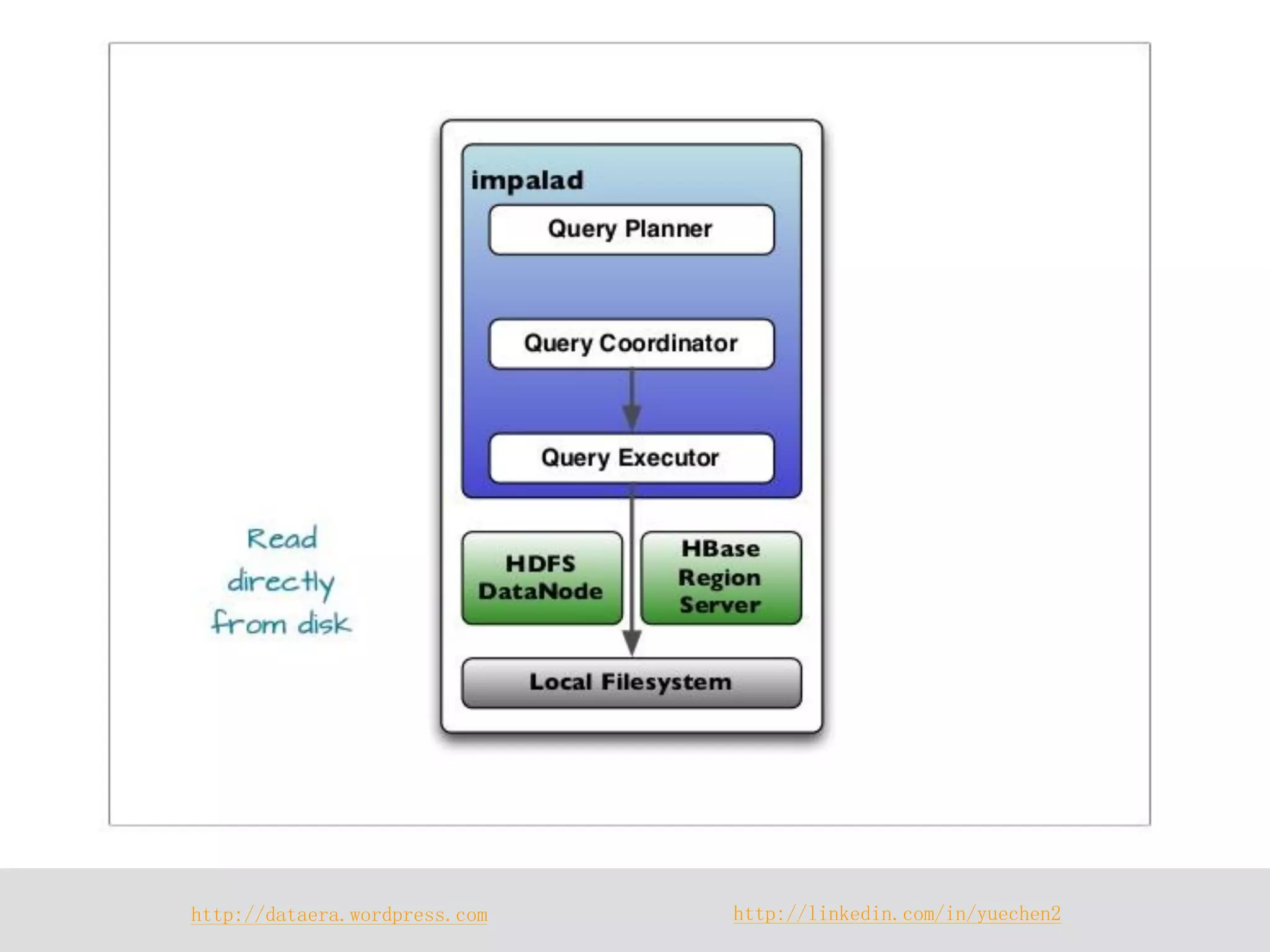









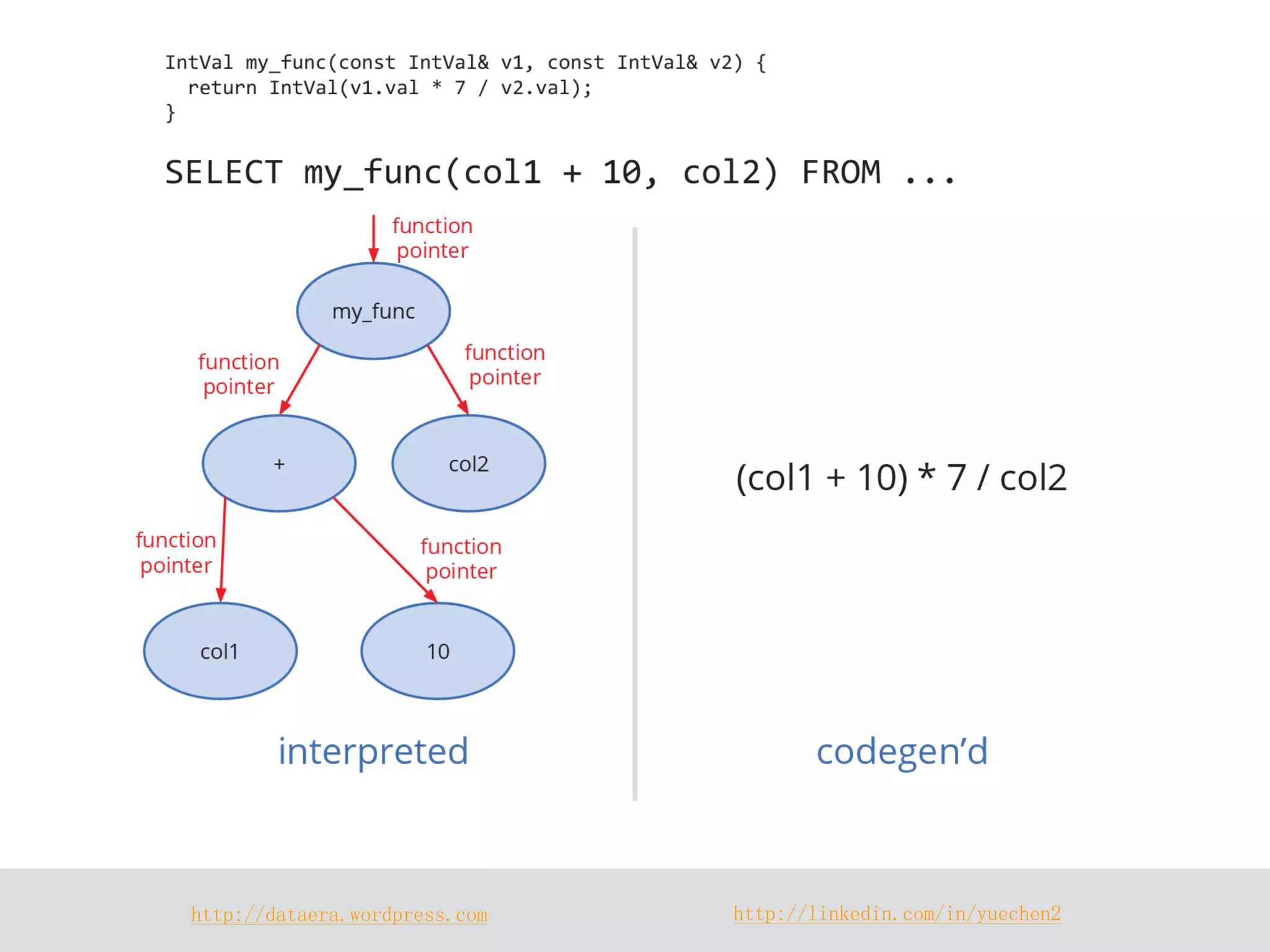
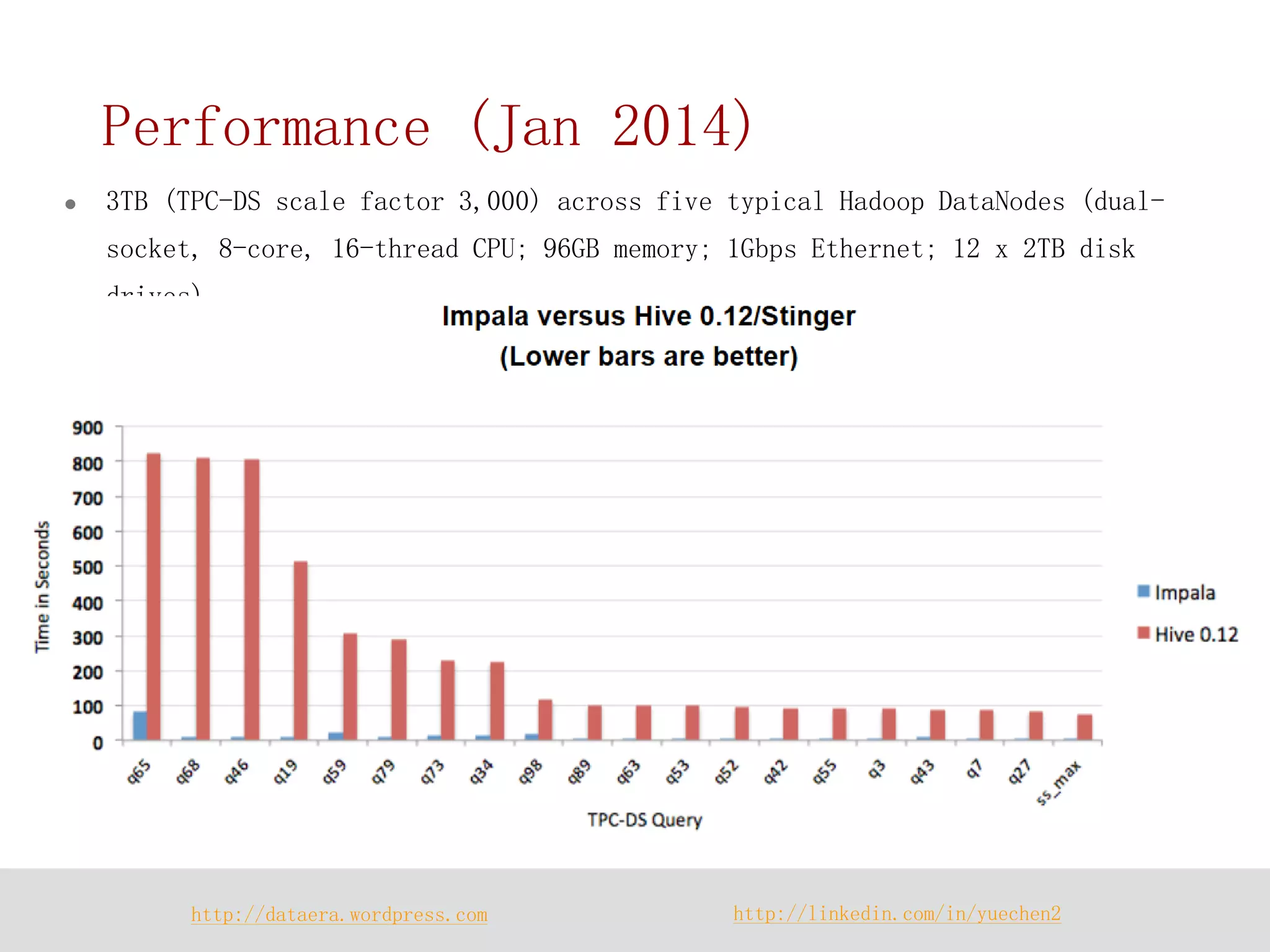
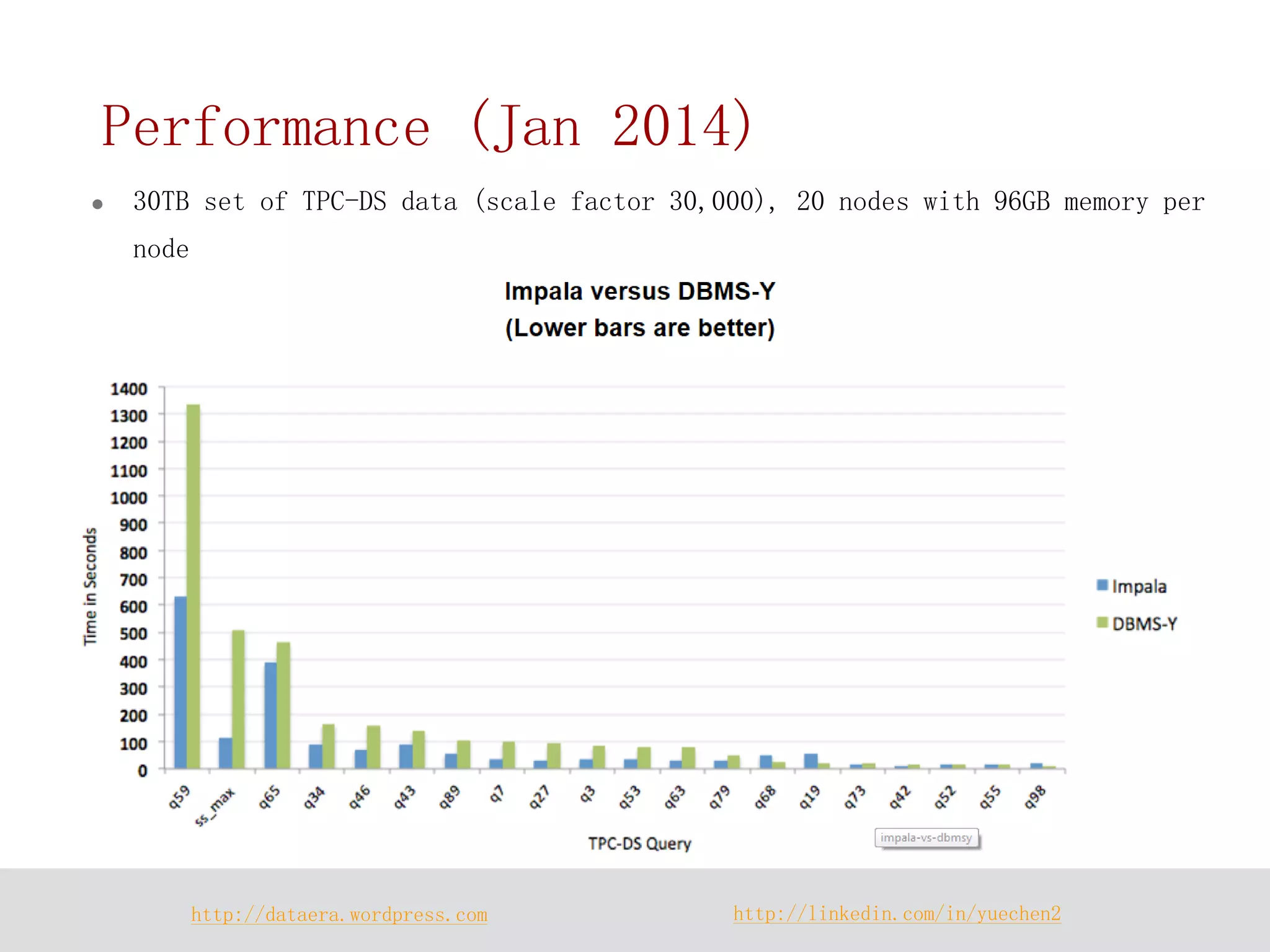



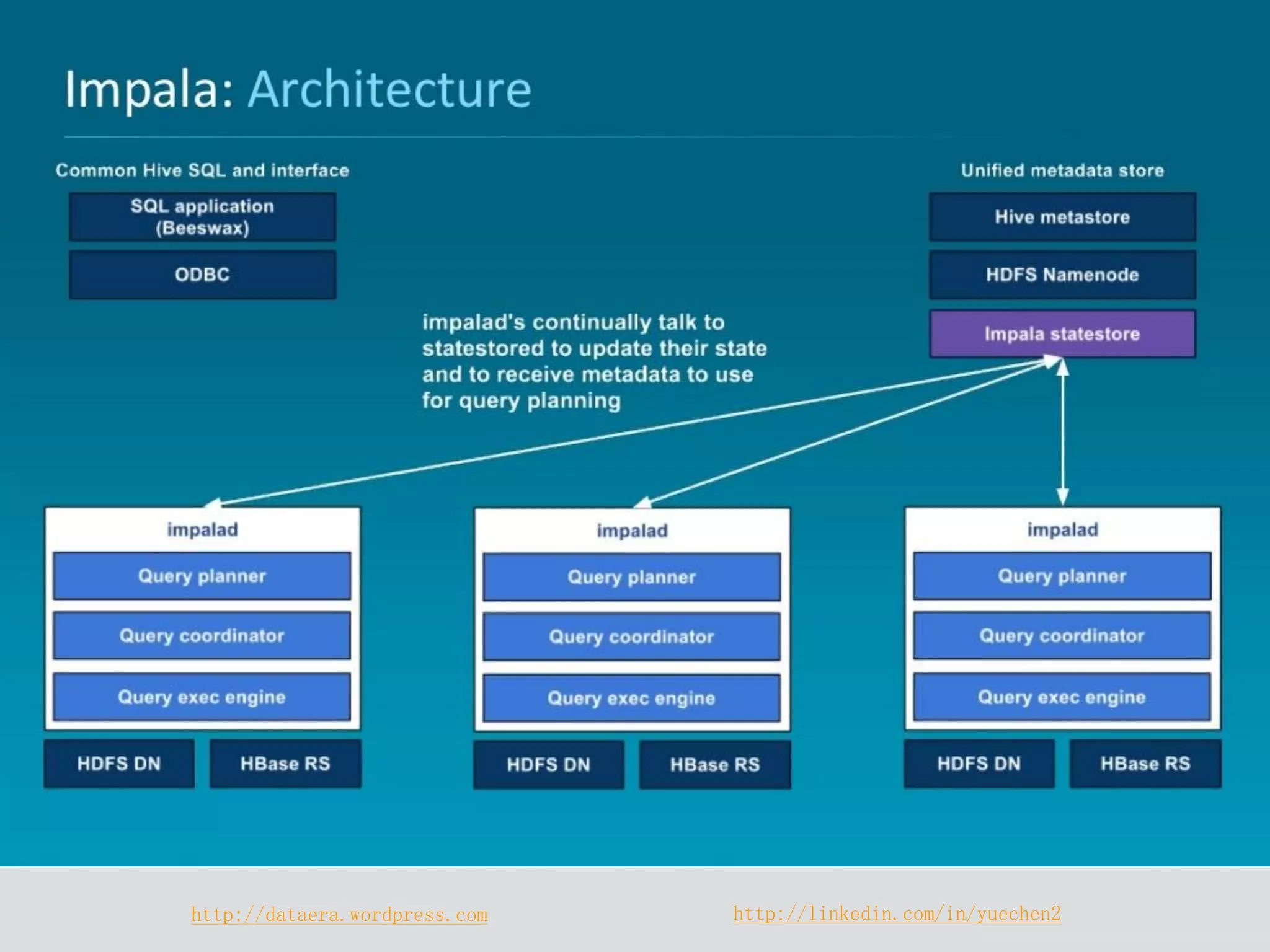
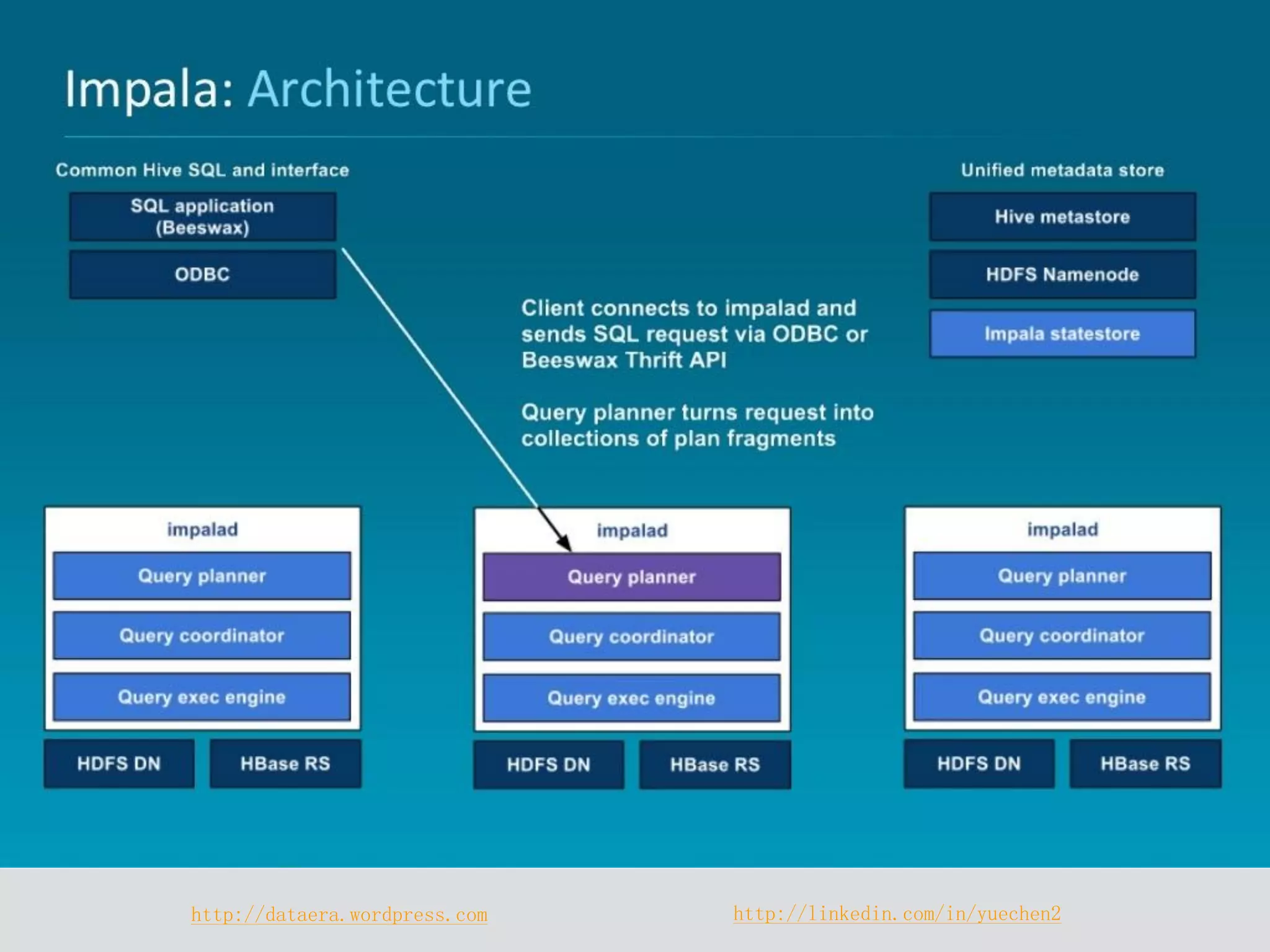
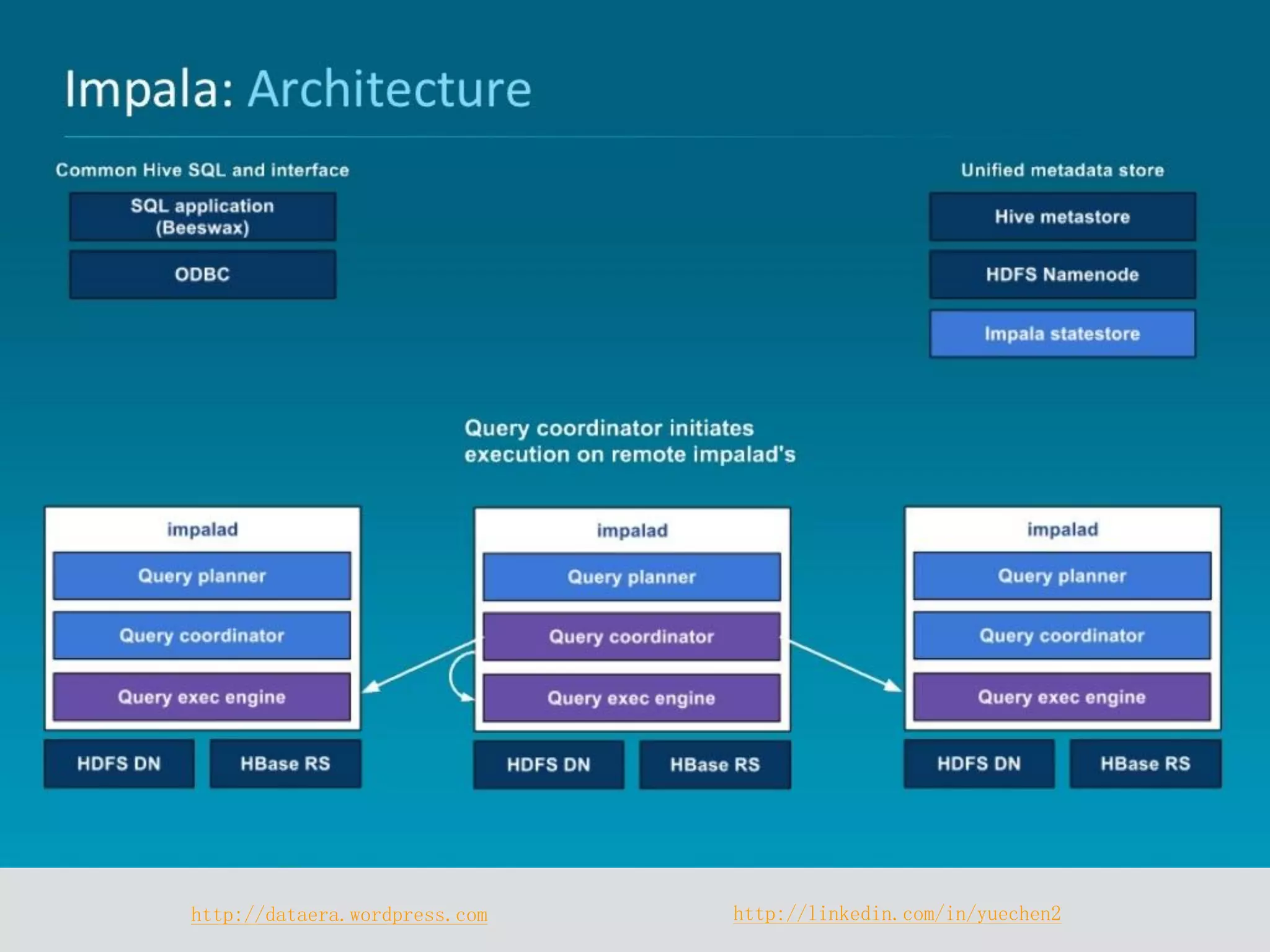
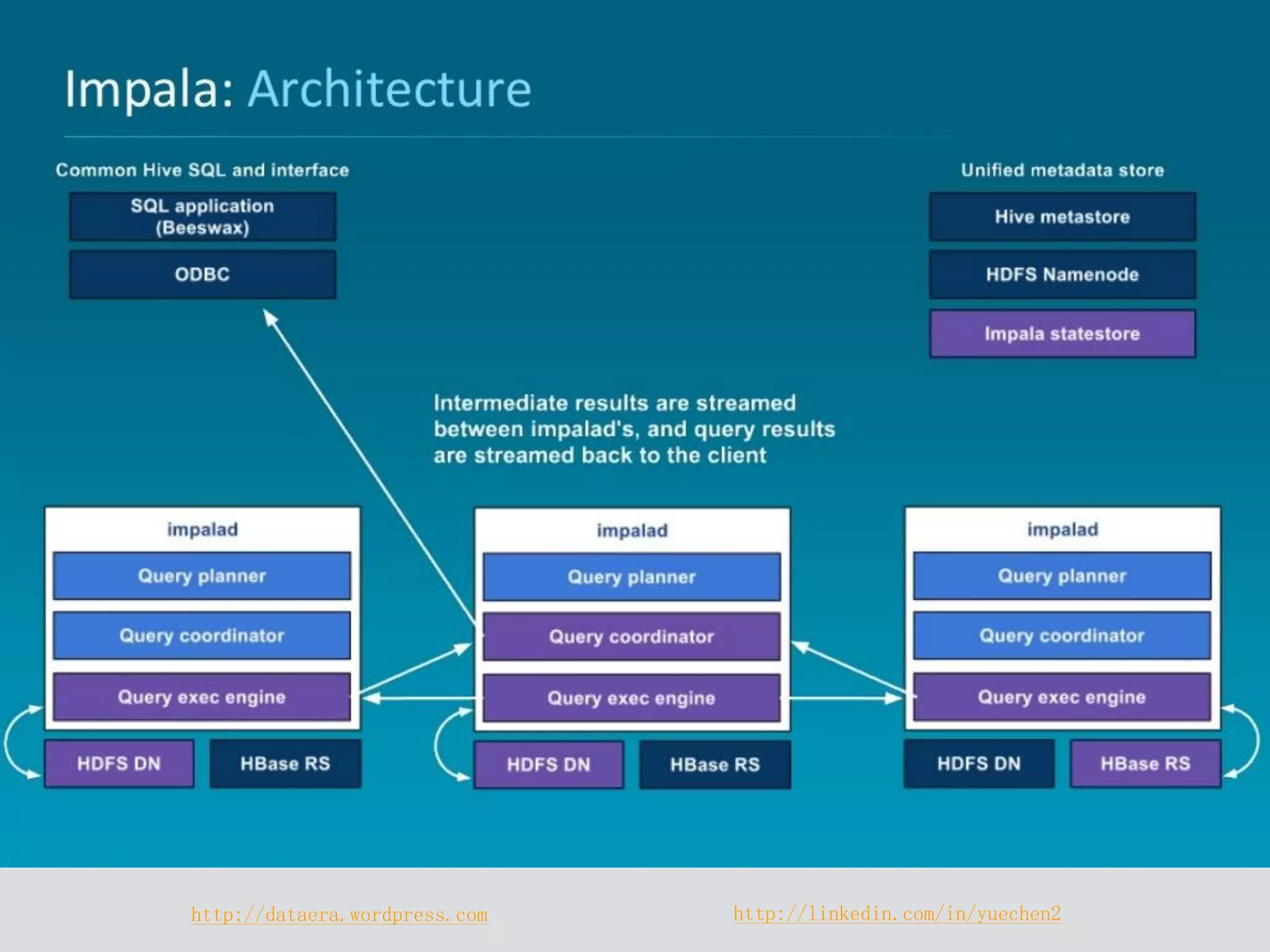
Impala is a distributed SQL query engine designed for real-time interactive queries, built on HDFS and HBase, and written in C++. It operates without using MapReduce, providing fast performance and utilizing a cluster architecture with components like `impalad`, `statestored`, and a Hive metastore for metadata management. While it excels at query execution and optimization, it has limitations, including immutable data and high memory usage.













































































