Downloaded 248 times











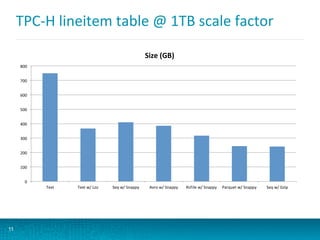
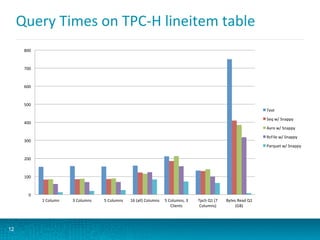
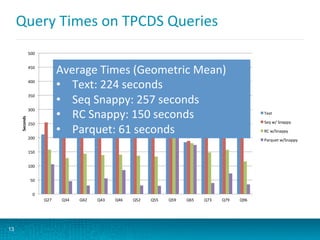

































The document discusses updates to Parquet file format and user-defined functions (UDFs) in Impala, highlighting performance benchmarks and new encodings in Parquet 2.0. It also covers query execution strategies, efficiency factors, and recommends best practices for optimizing Impala's performance through various methods including data partitioning and file formats. Additionally, it outlines the limitations of UDFs and introduces debugging options for monitoring query performance.


































































































