Downloaded 44 times






















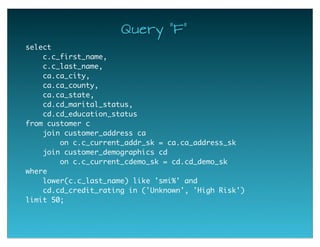



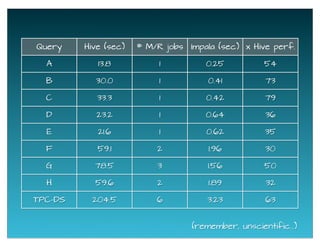


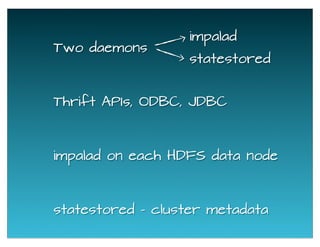
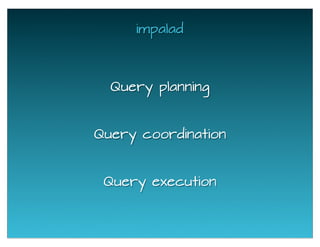
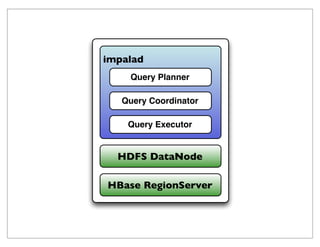




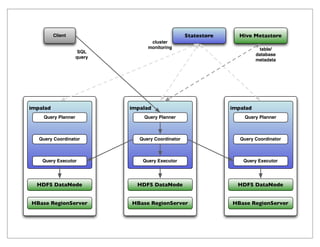

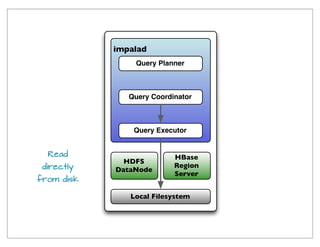
















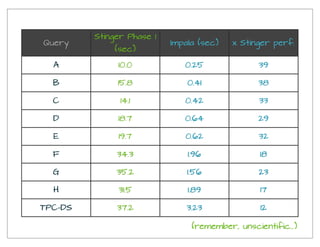





The document provides a historical overview of data query technologies, focusing on Cloudera's Impala, an in-memory SQL query engine designed for low-latency data analysis on Hadoop. It highlights Impala's advantages over Hive, including faster performance and integration with existing systems, while noting its limitations such as lack of fault tolerance and advanced query optimization features. Comparisons are made with other systems like Dremel and Apache Drill, outlining differences in performance, architecture, and use cases.

























































































