Download as PDF, PPTX



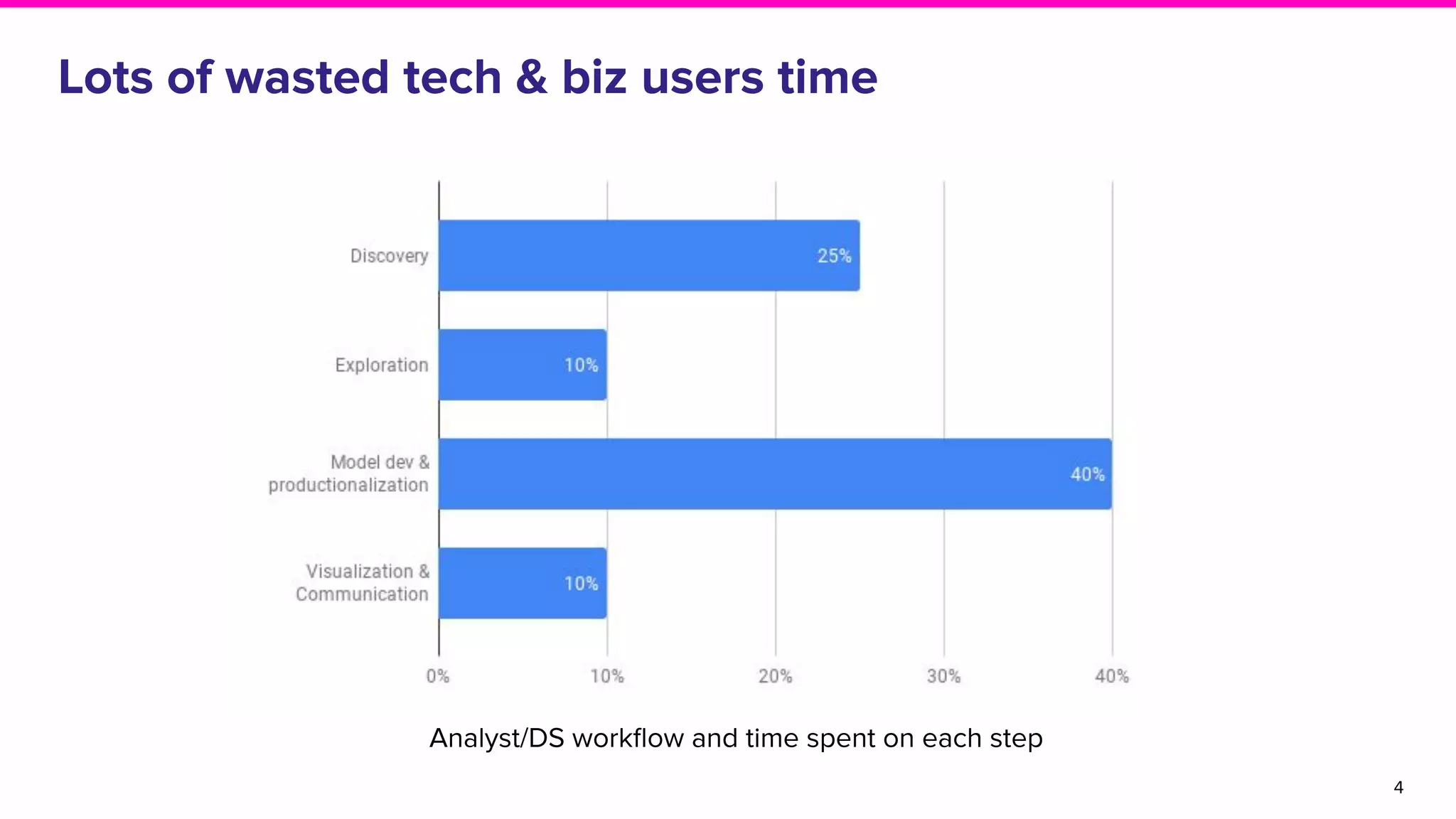

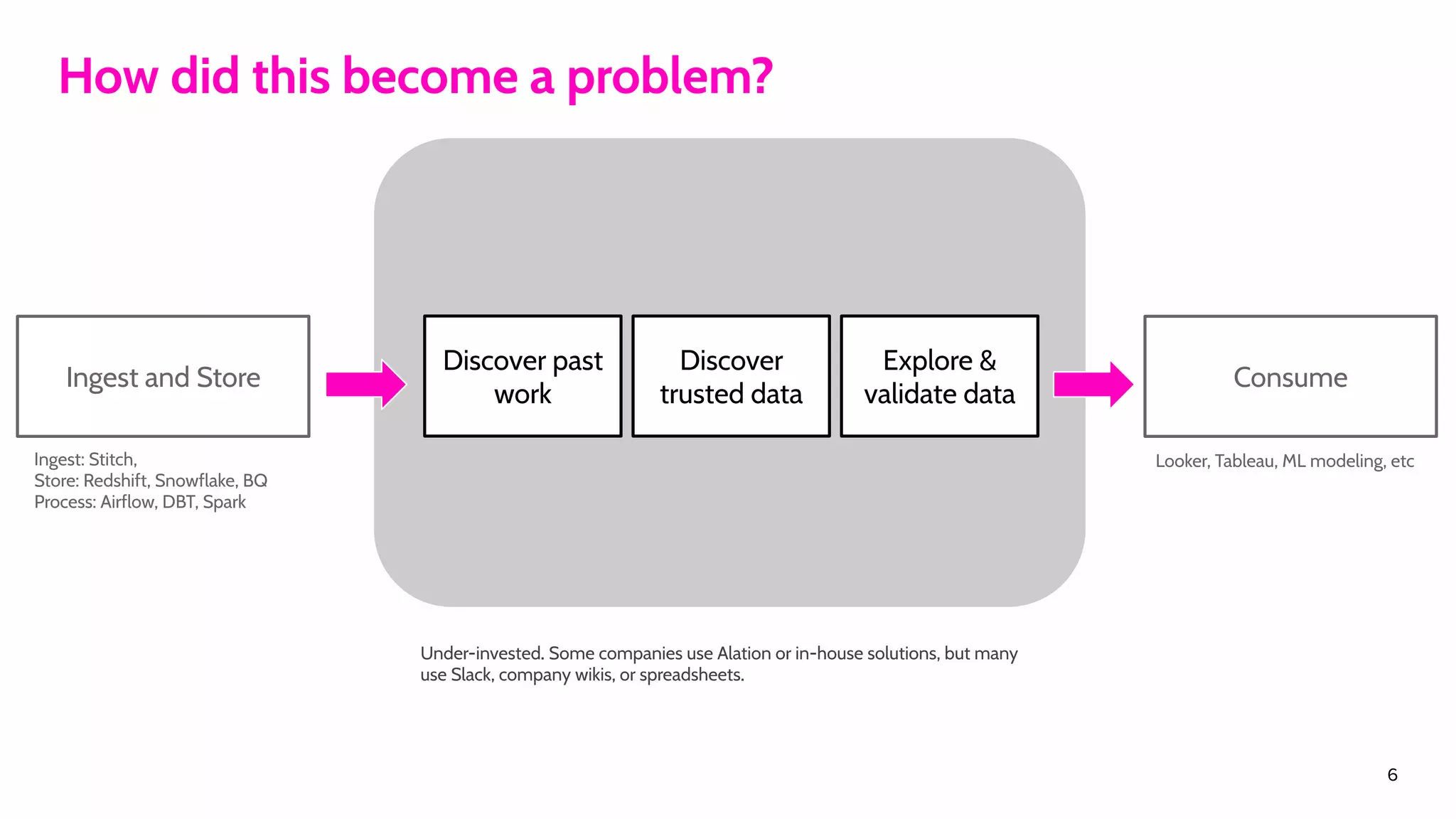


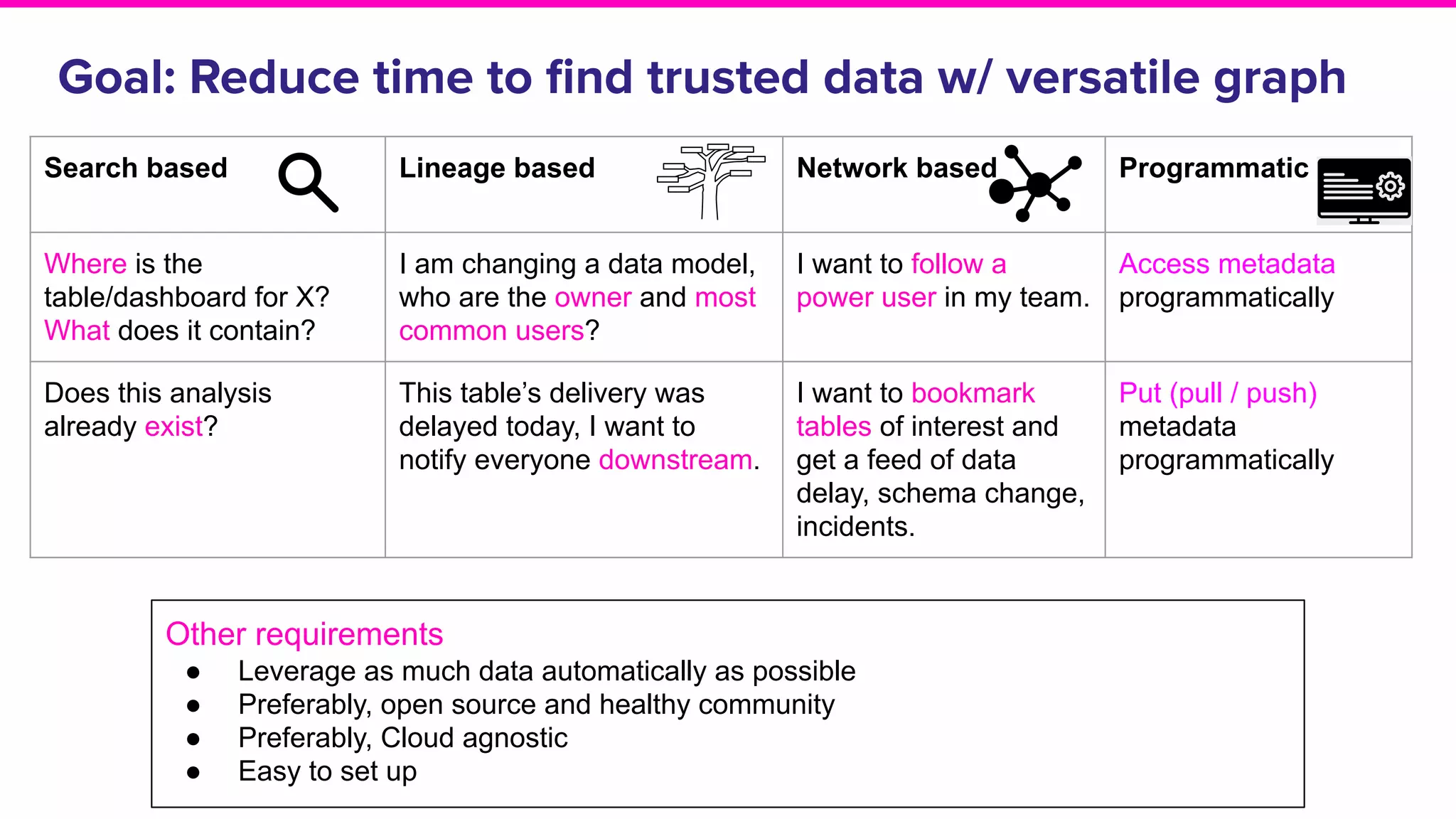


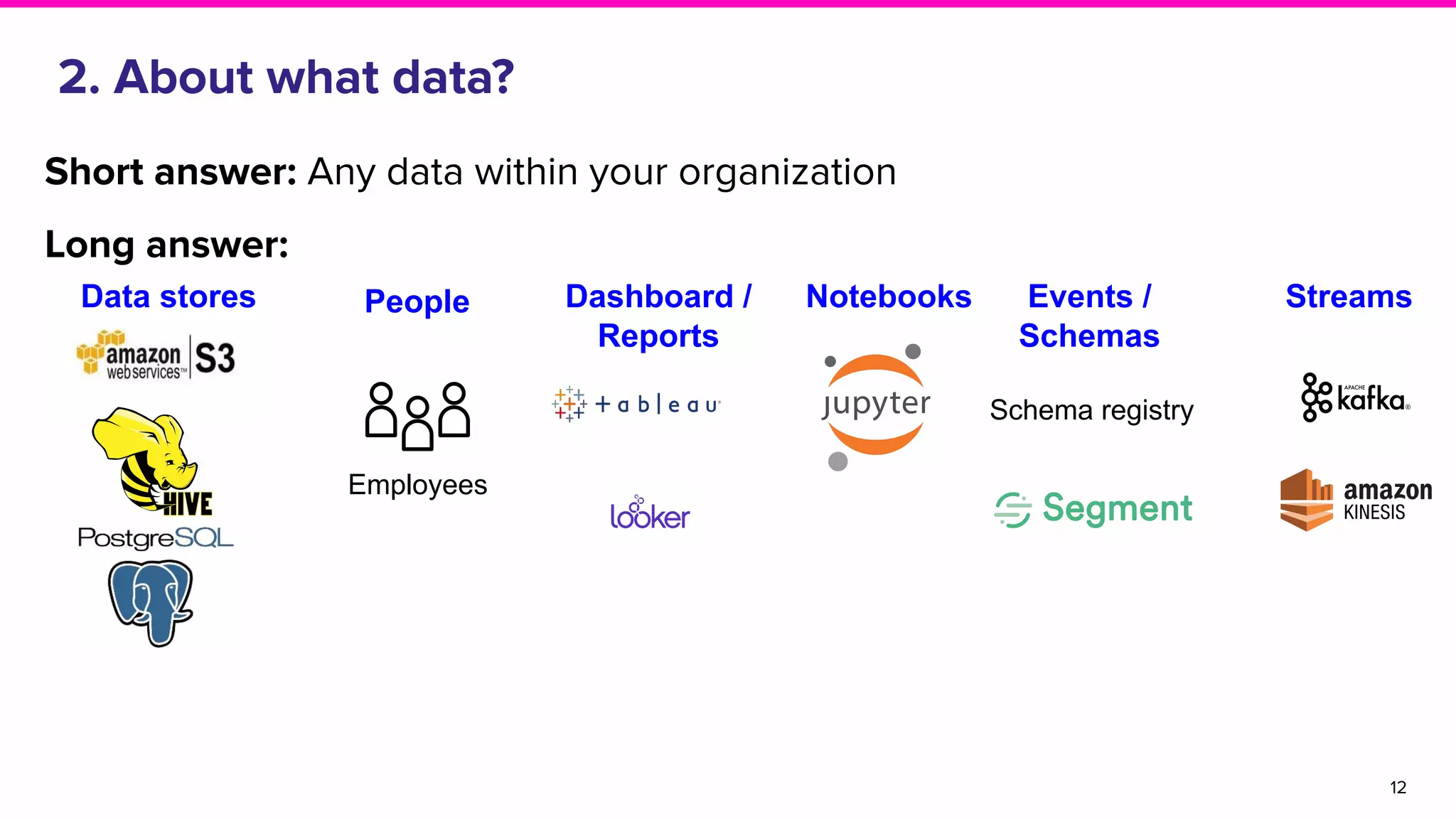
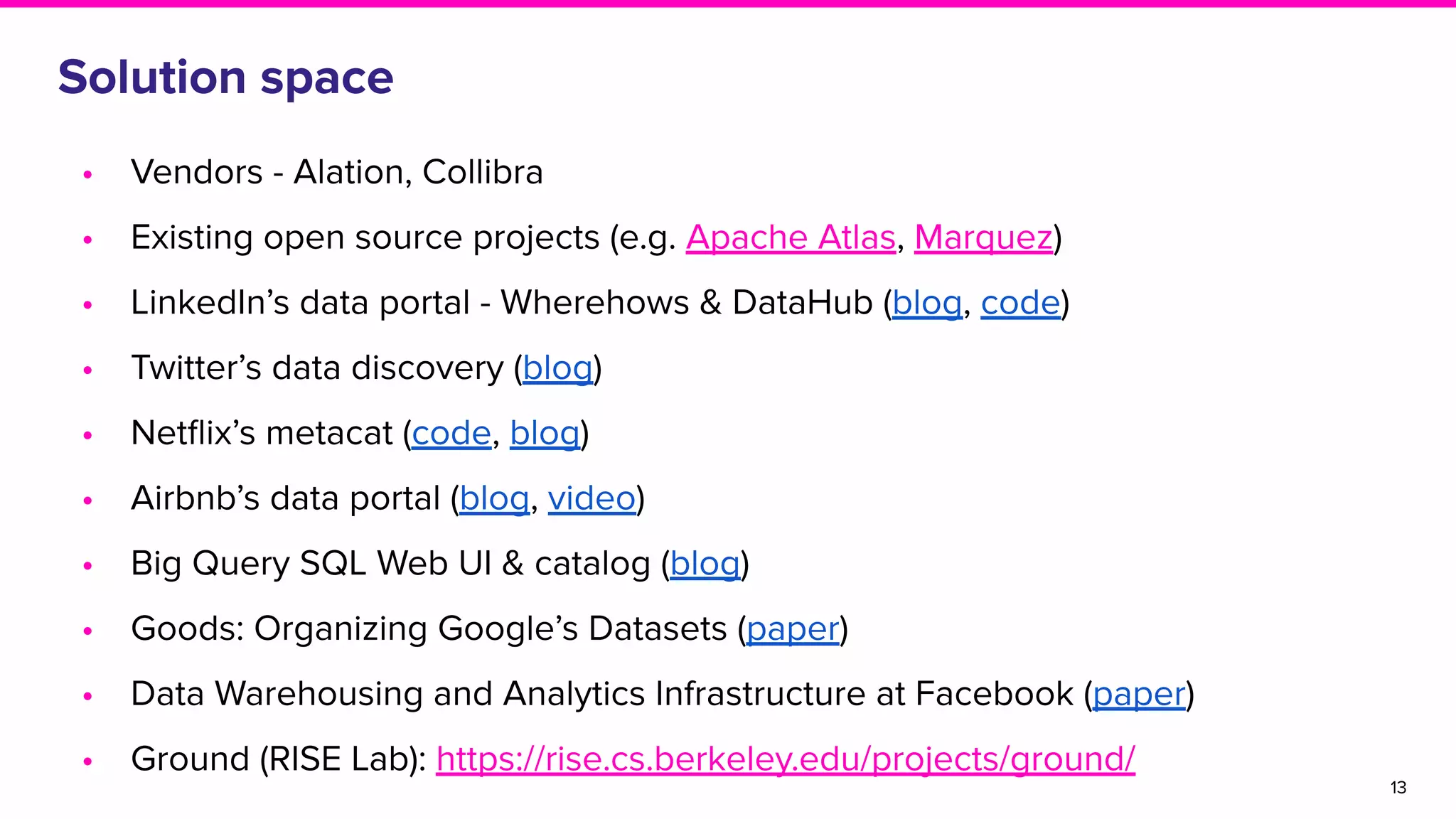
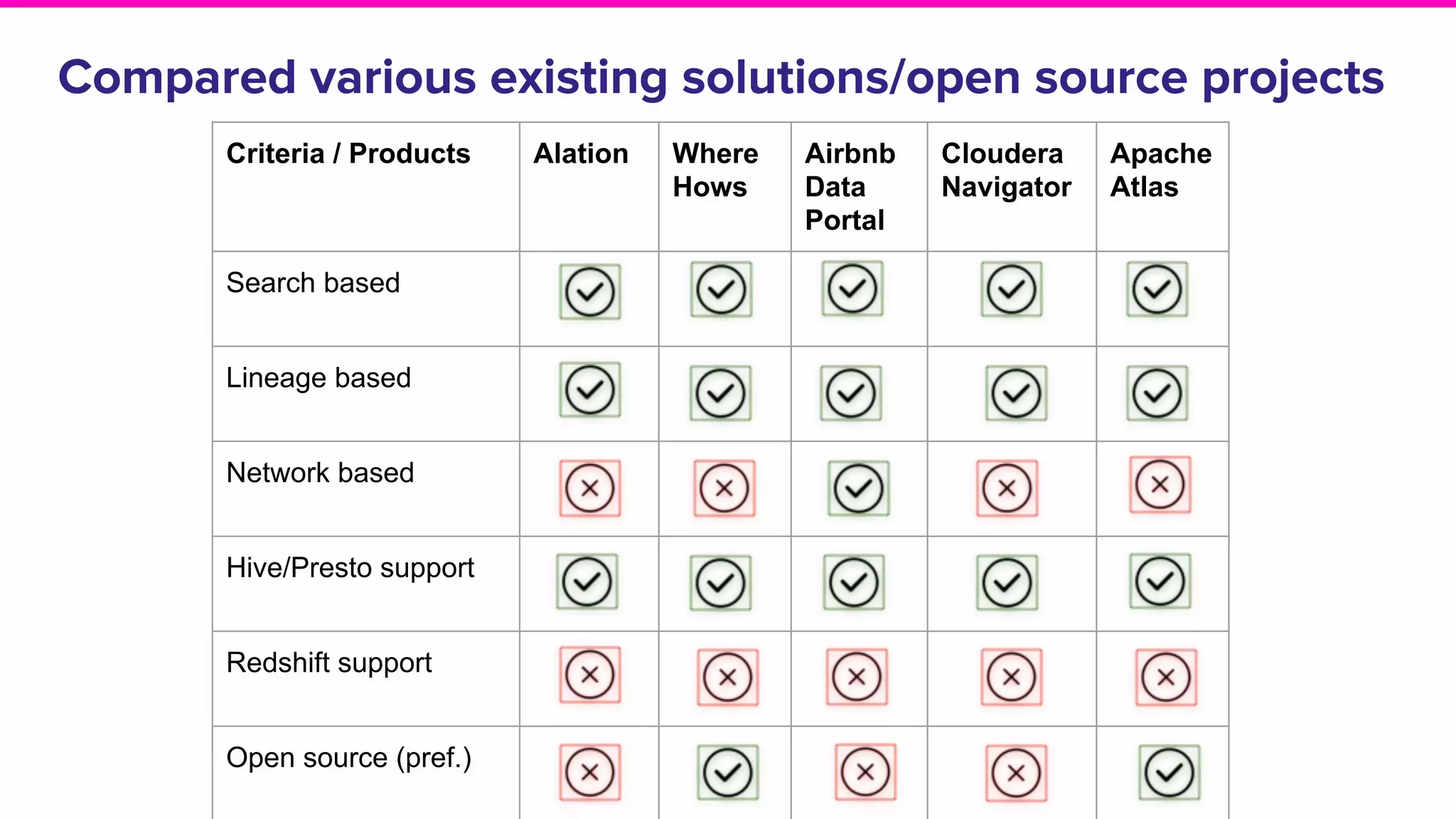

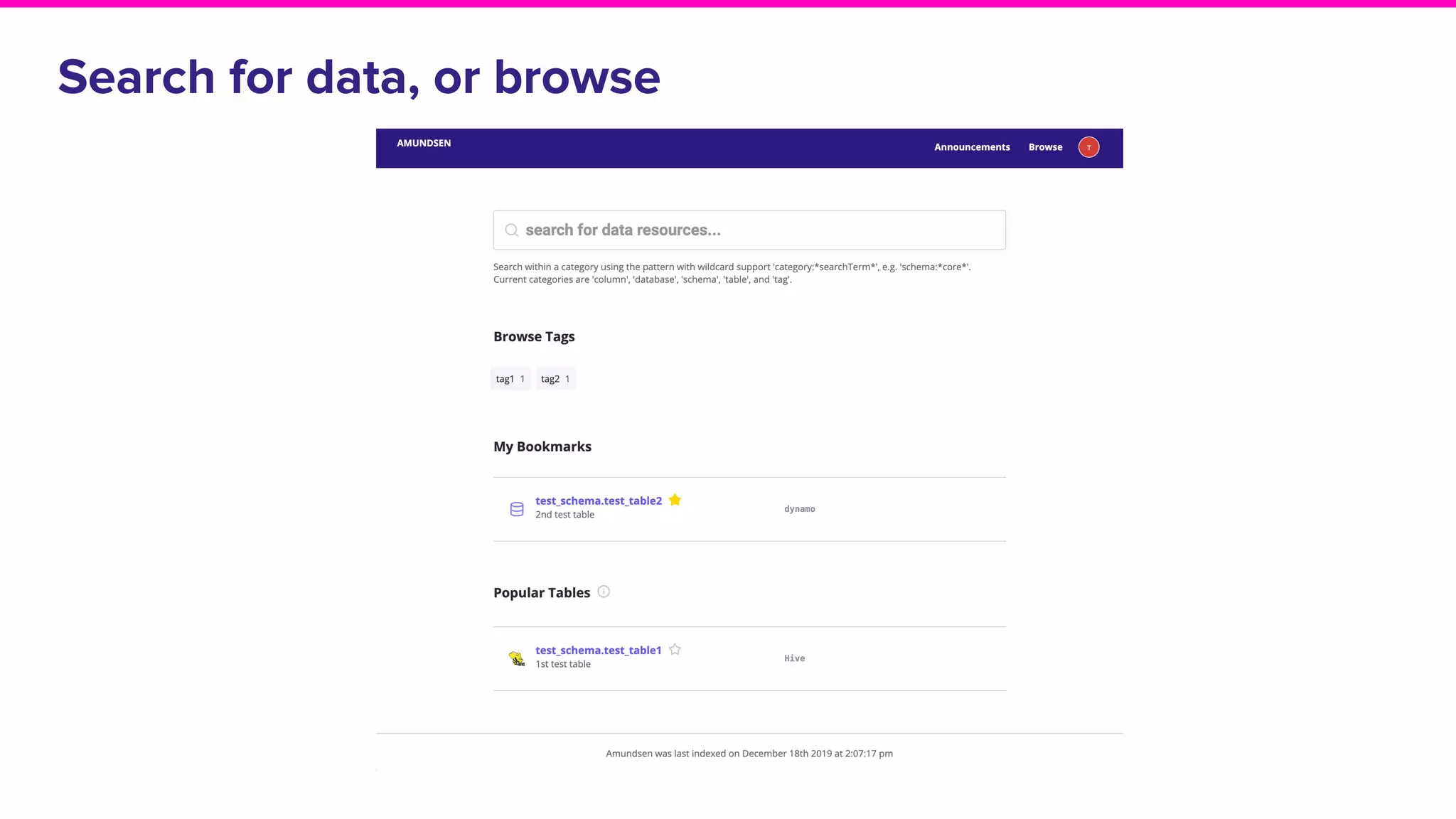
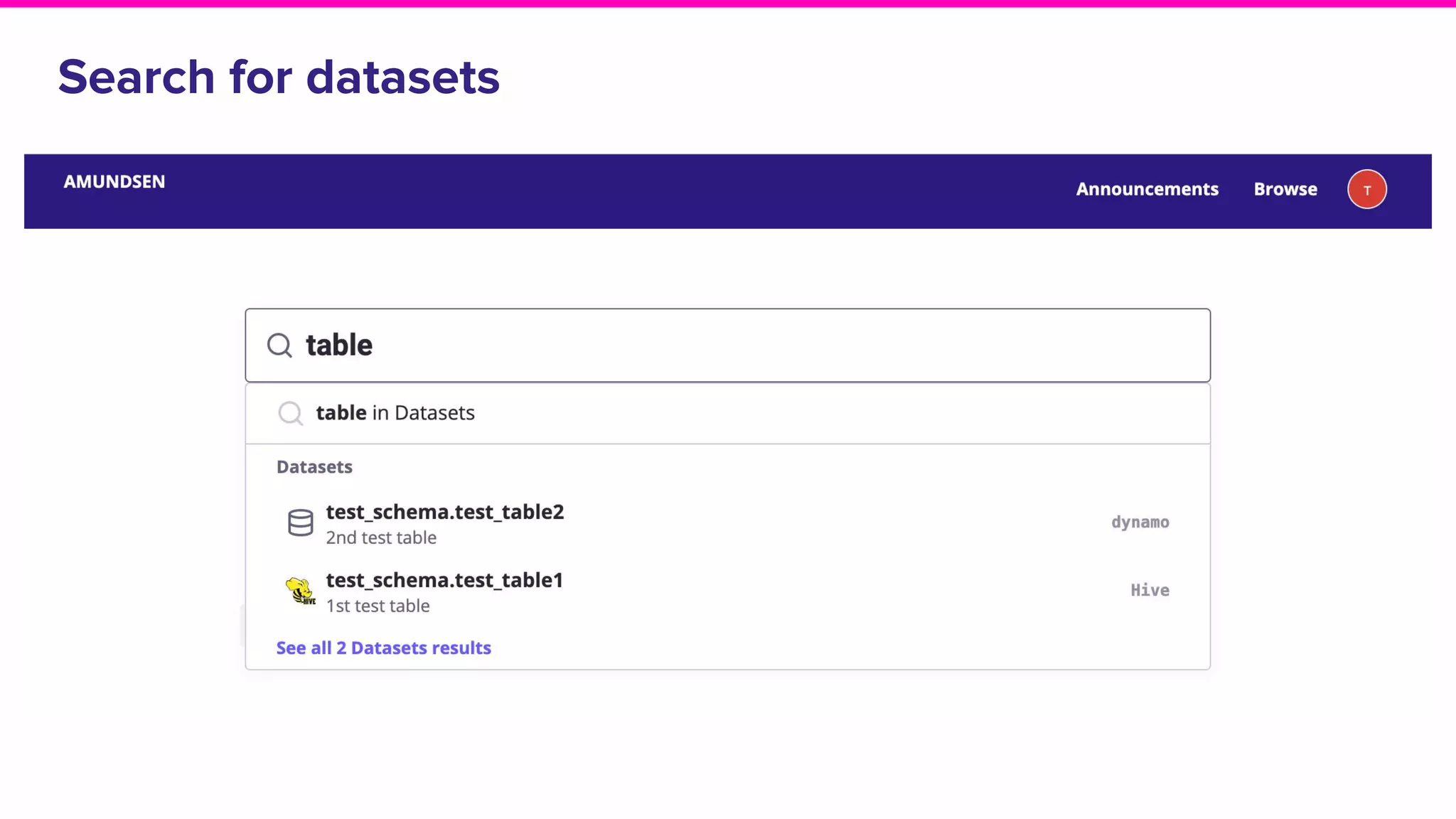
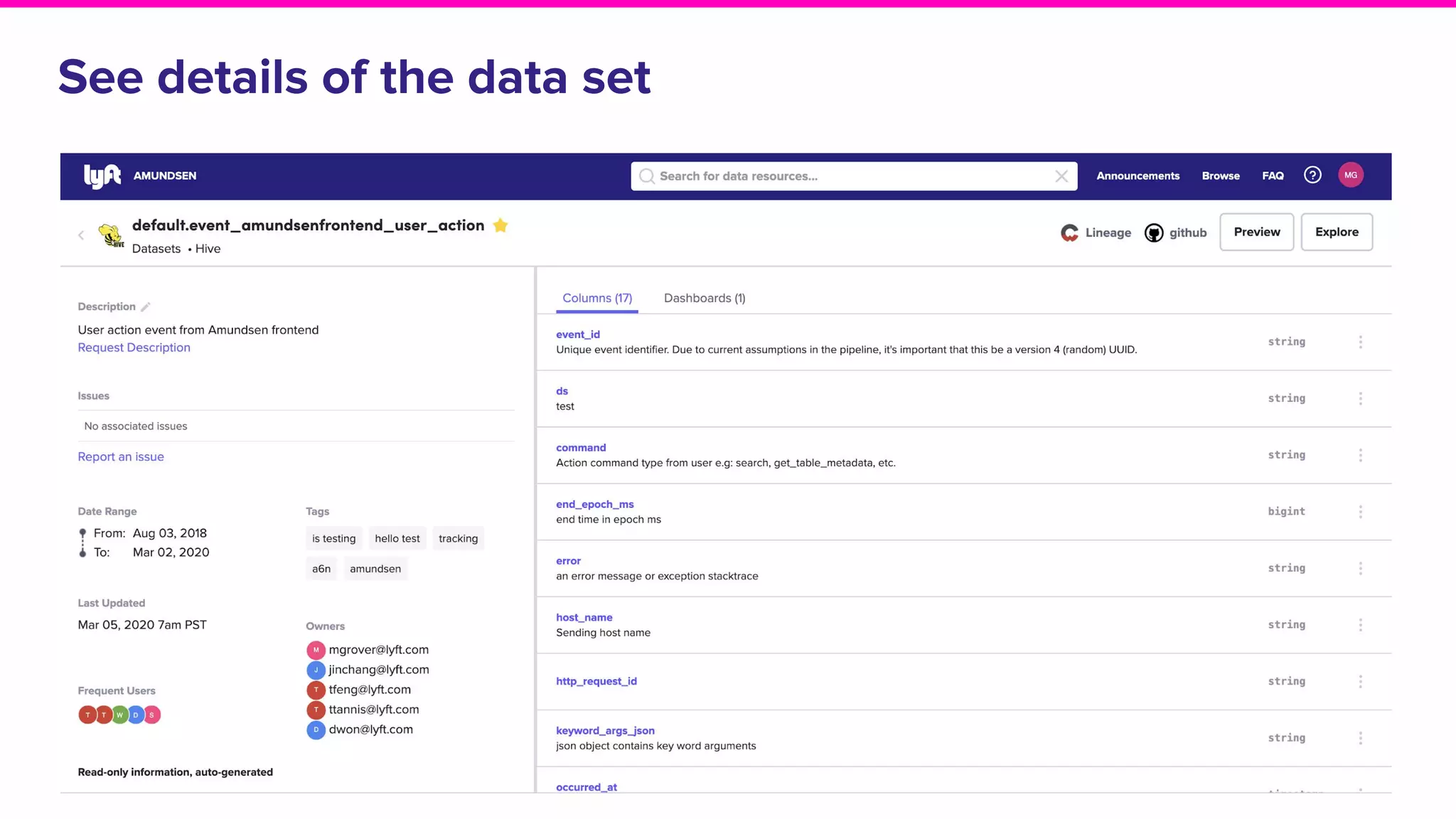

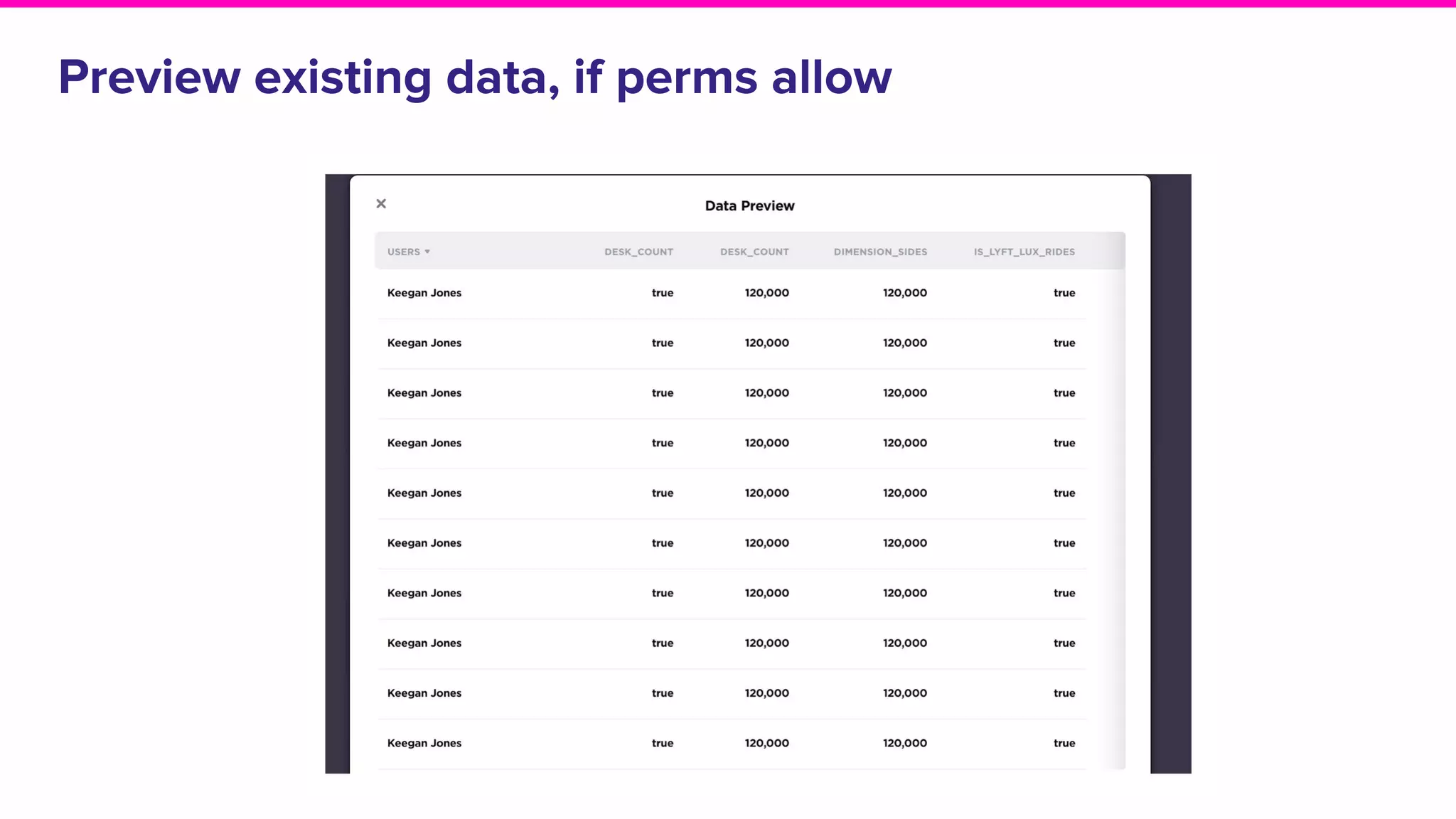
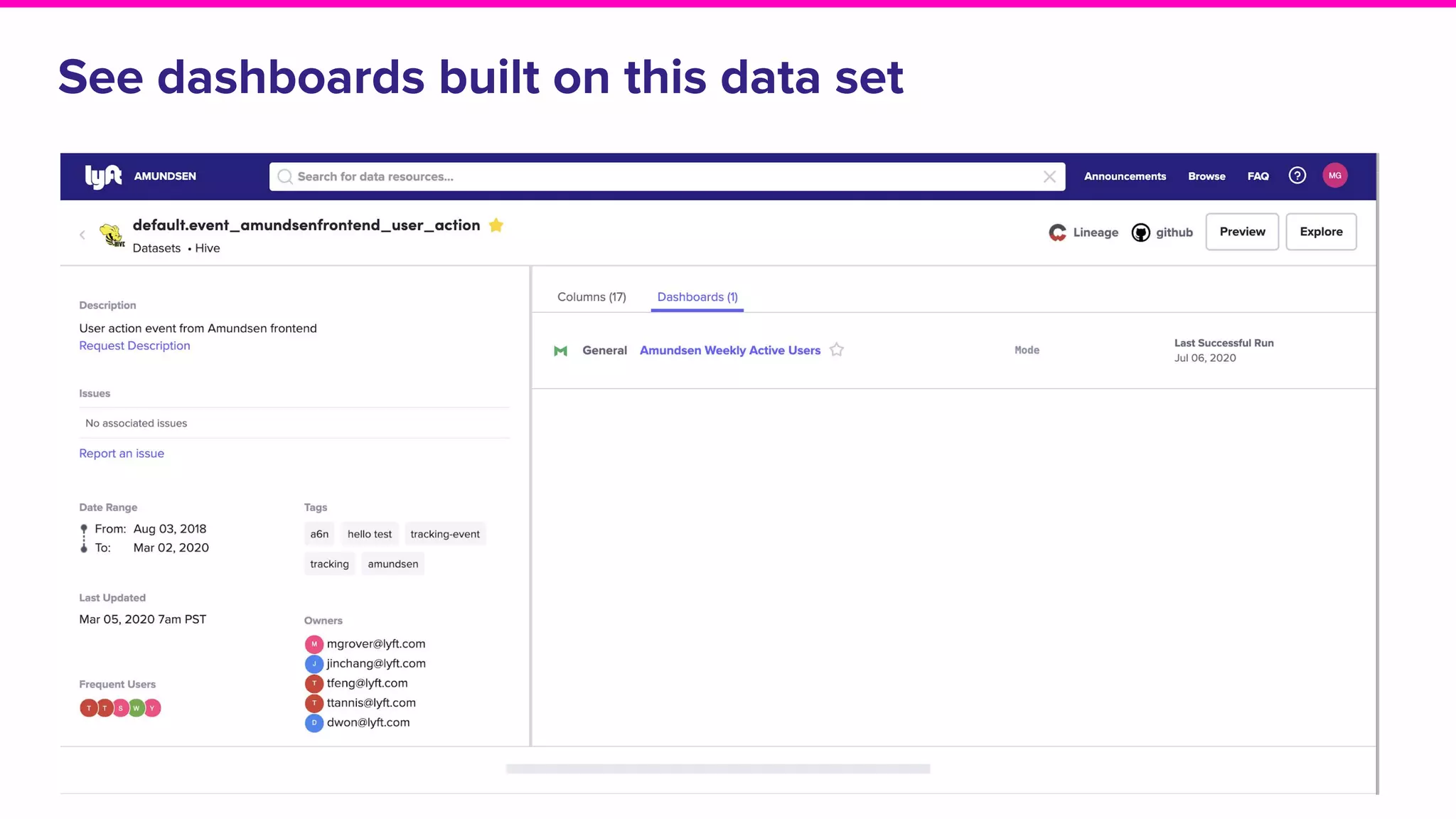
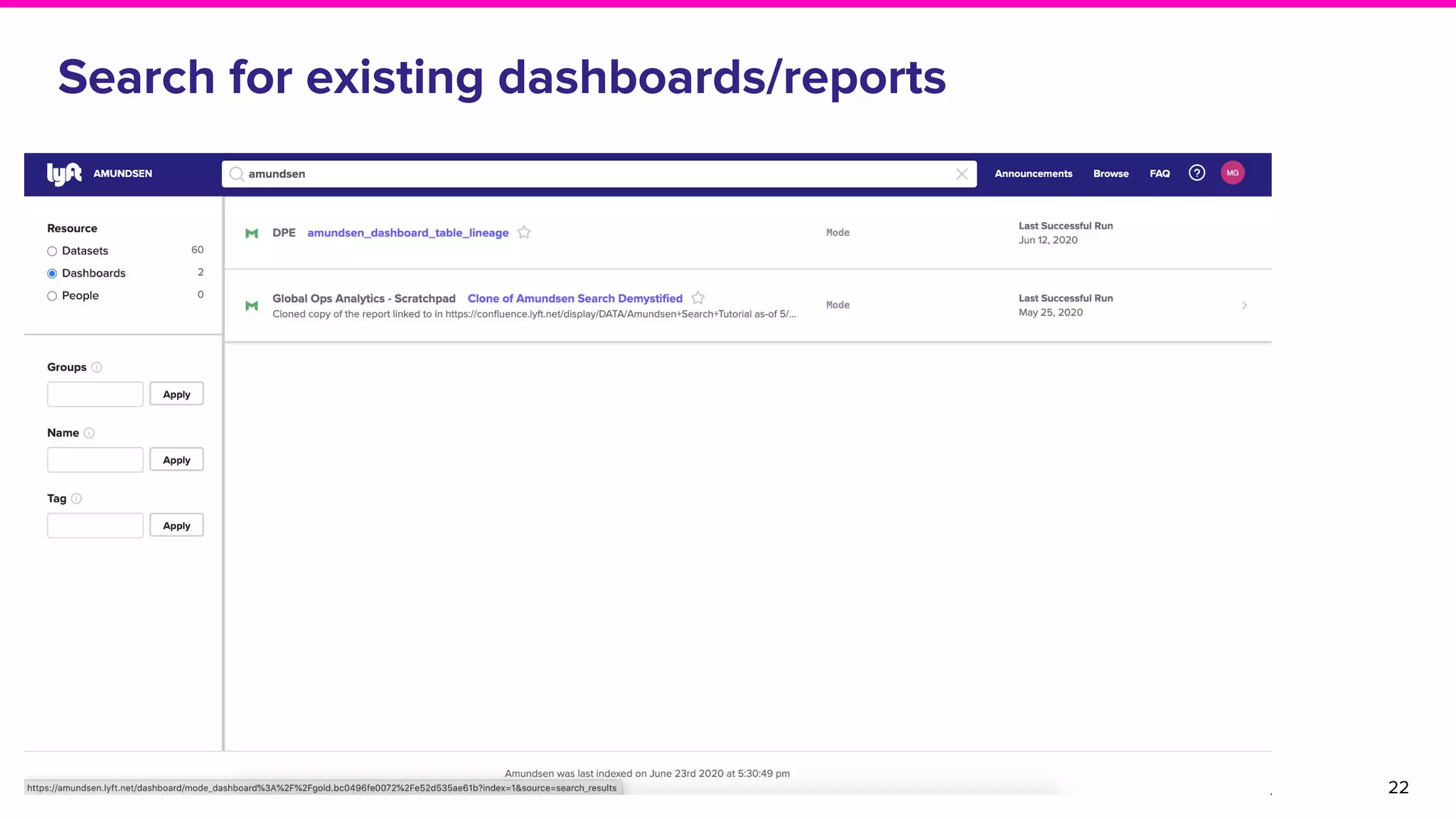
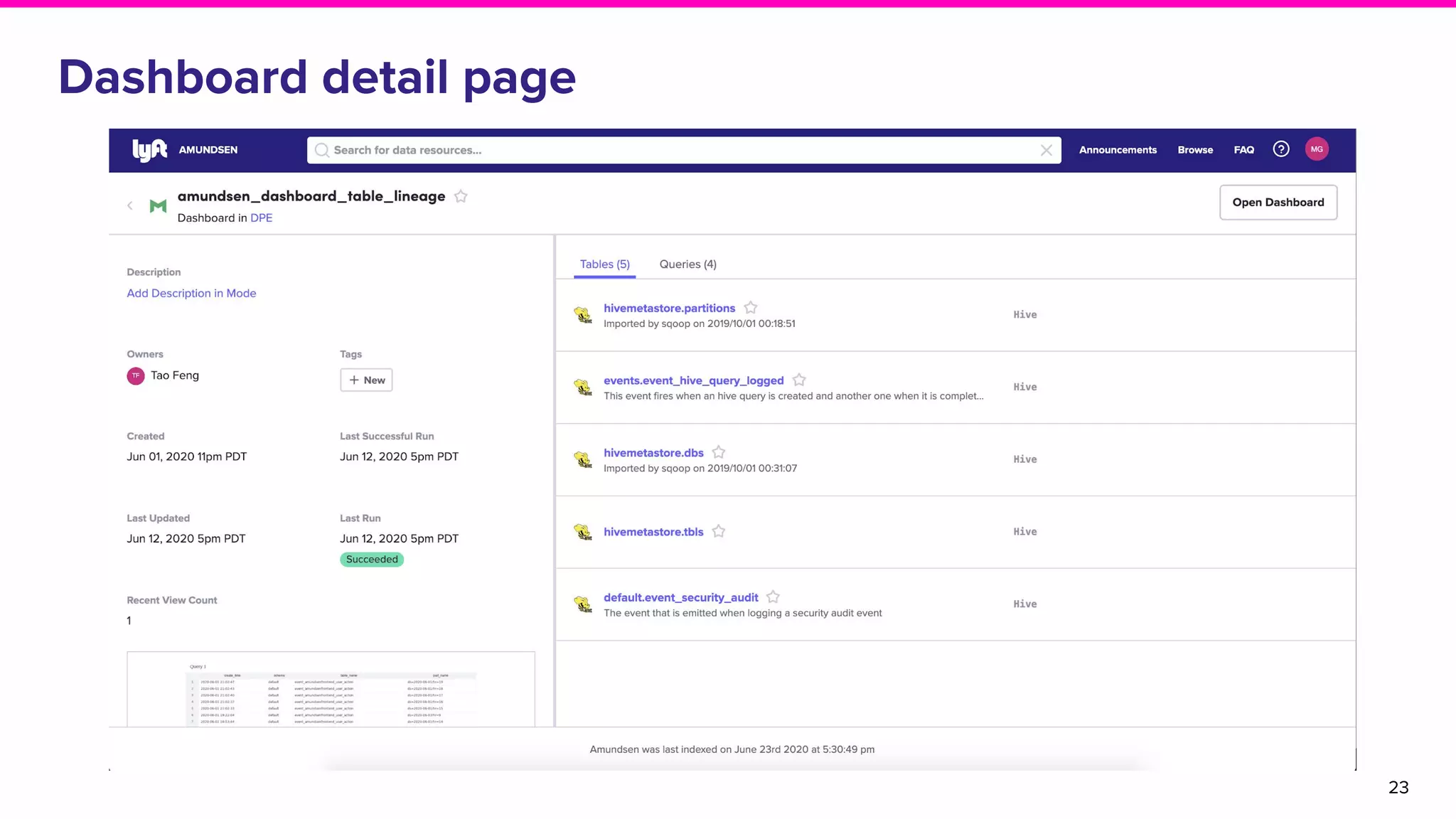
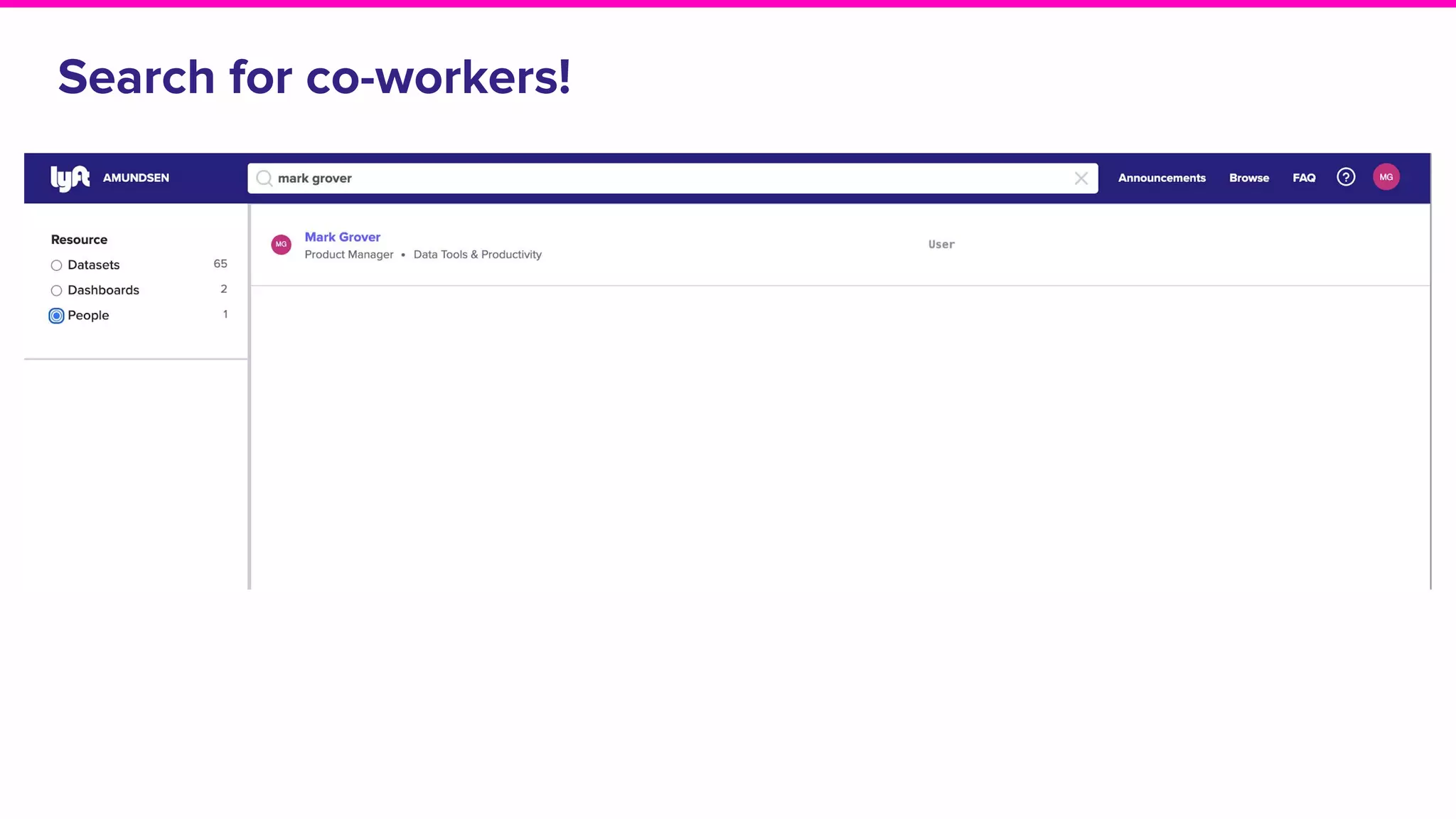
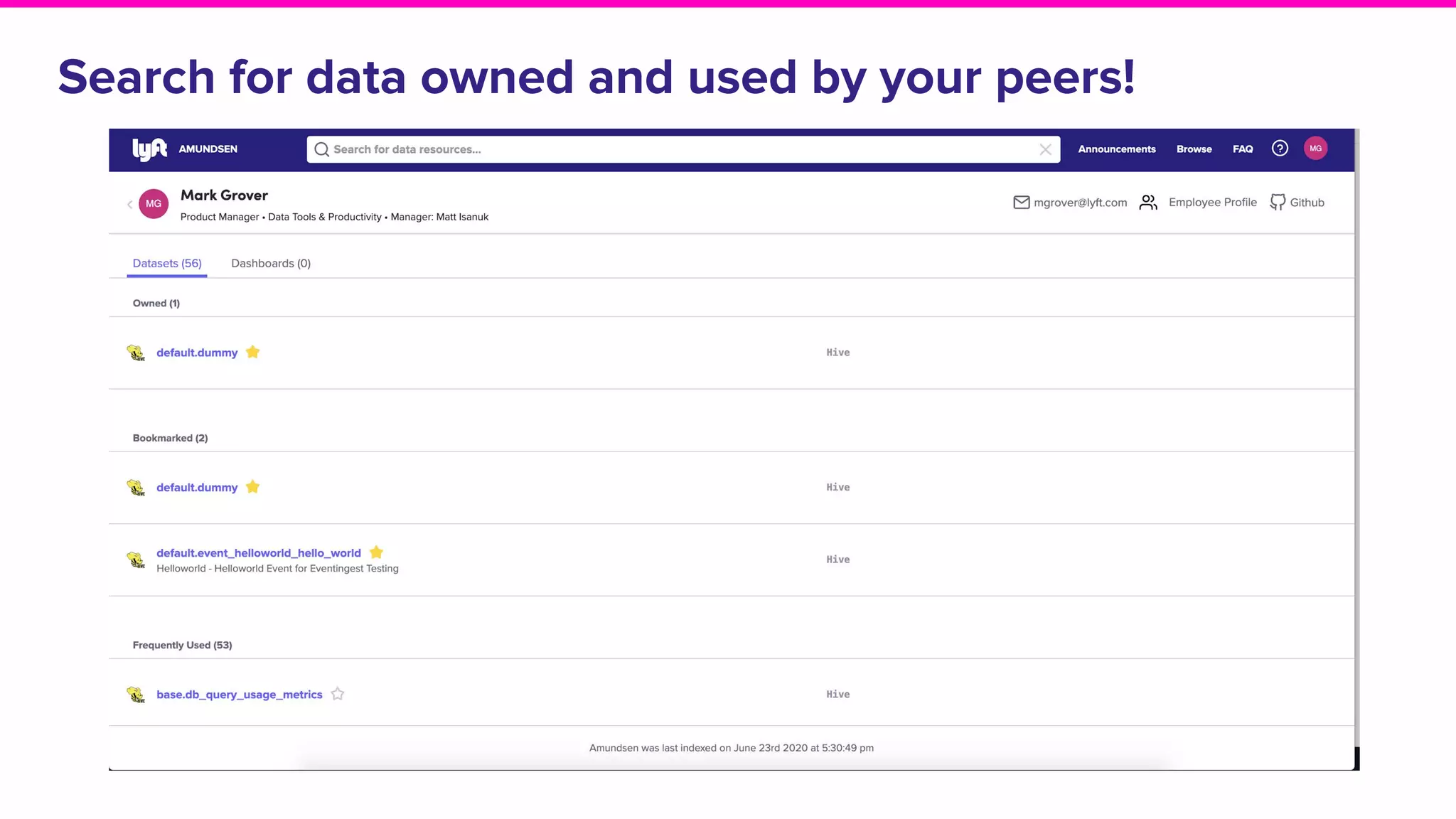

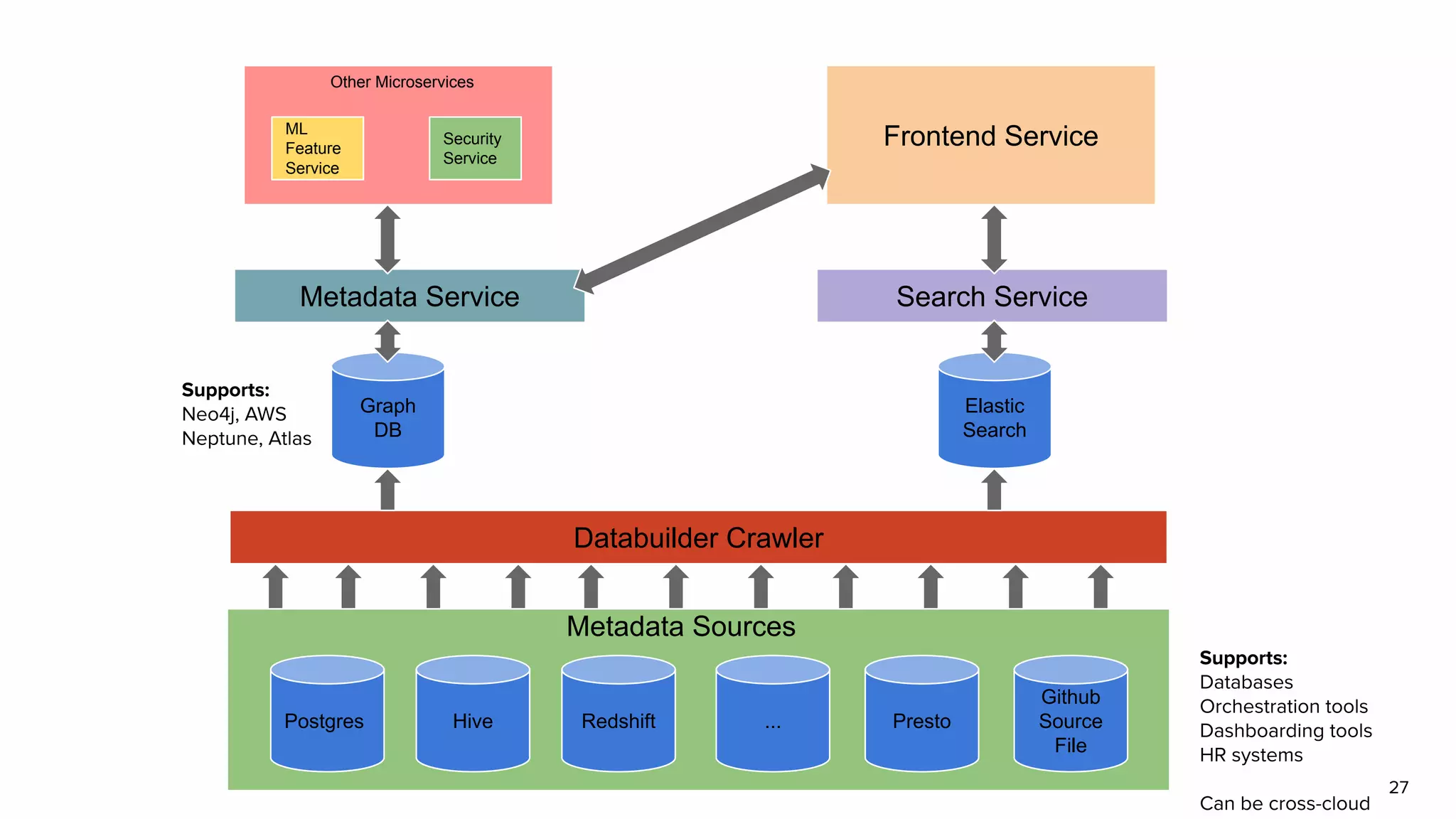
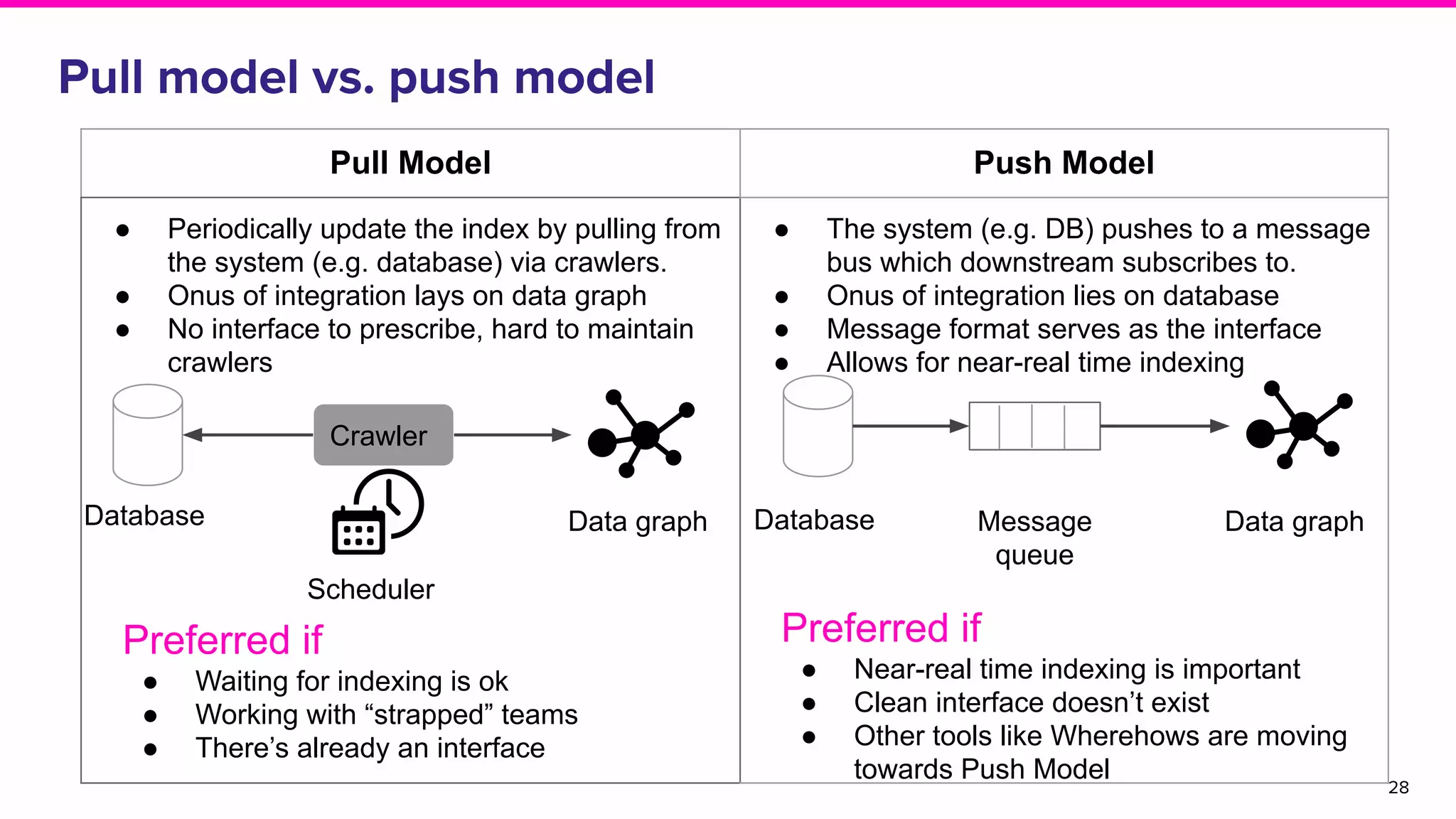



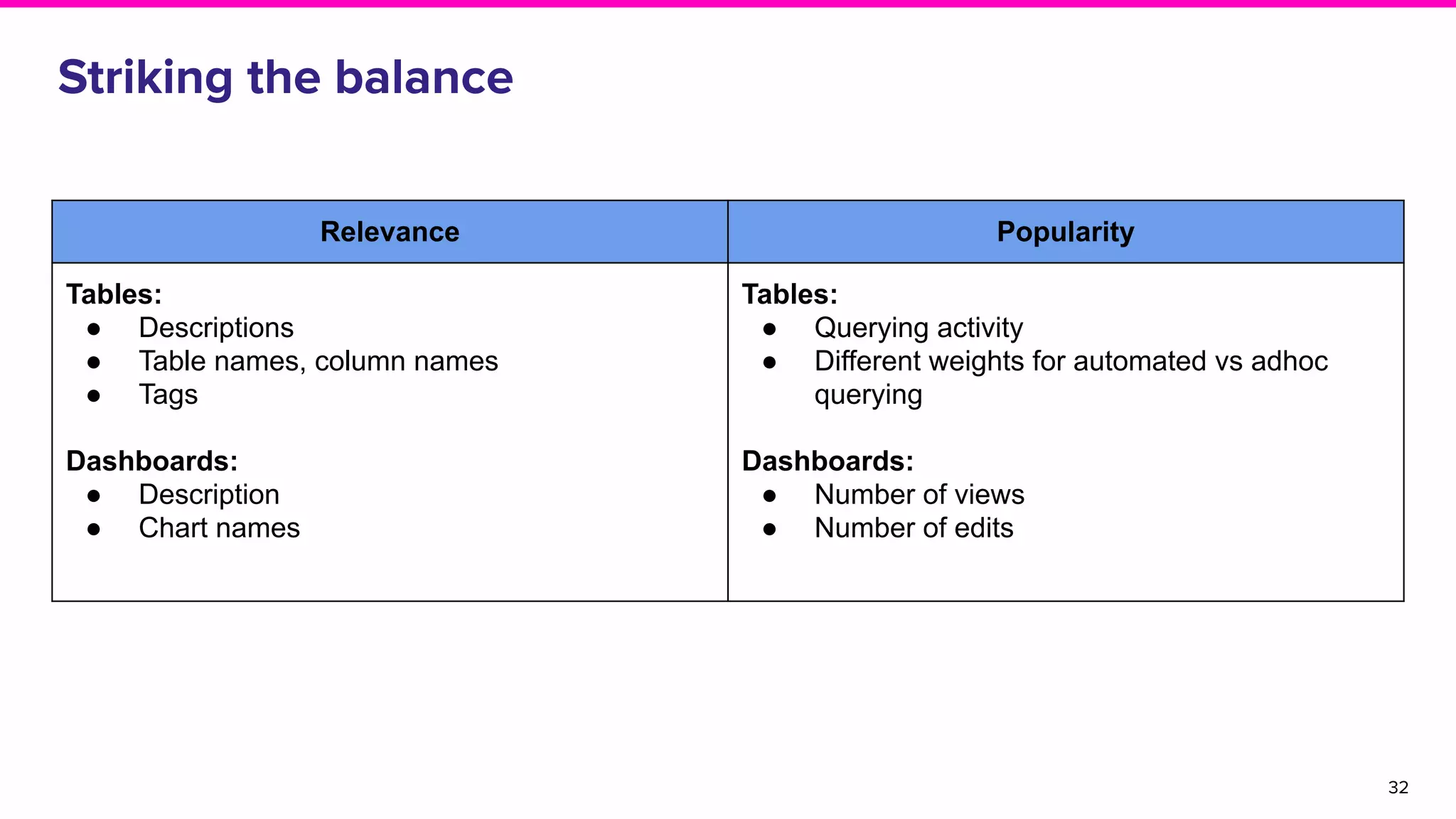



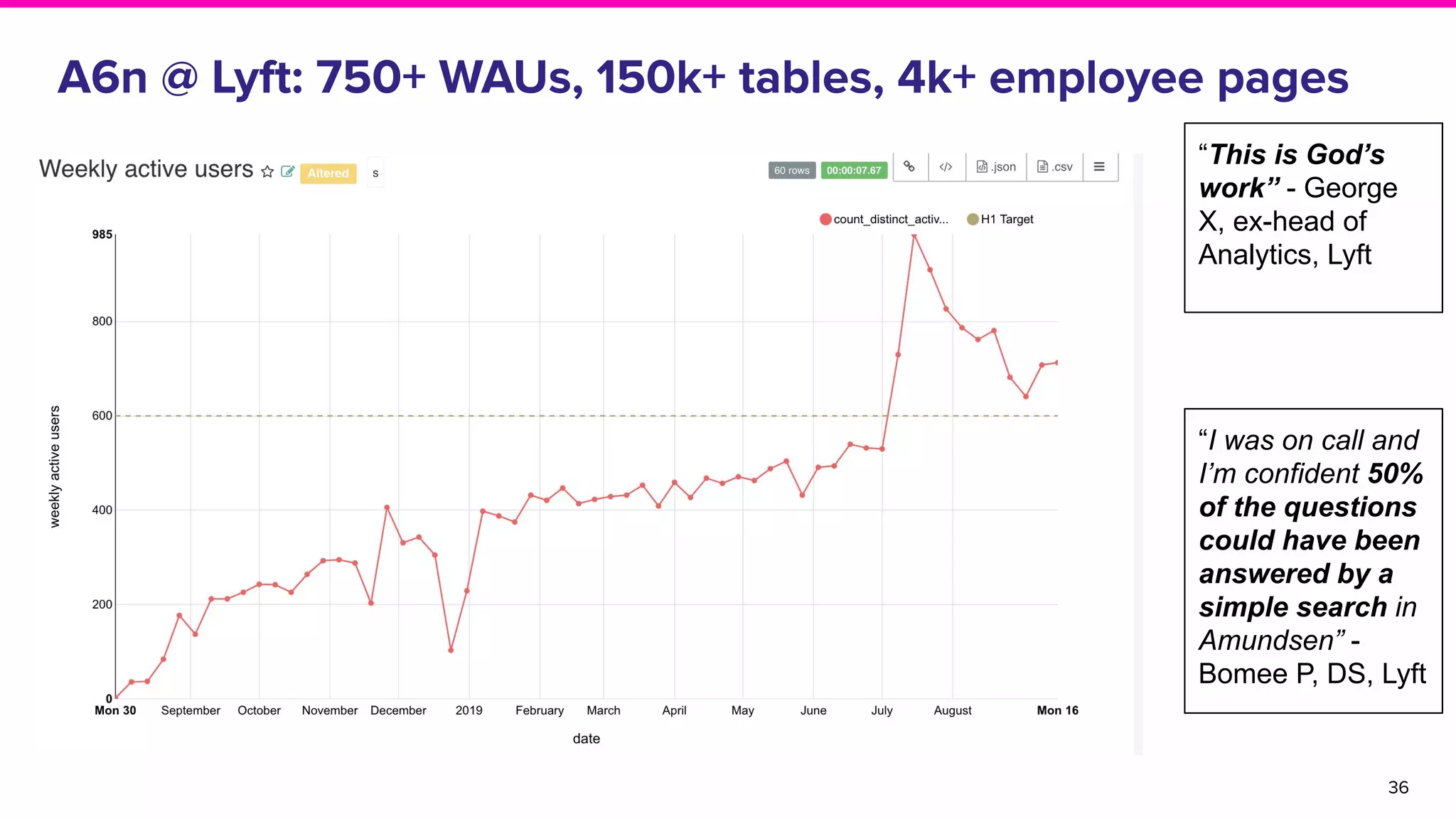
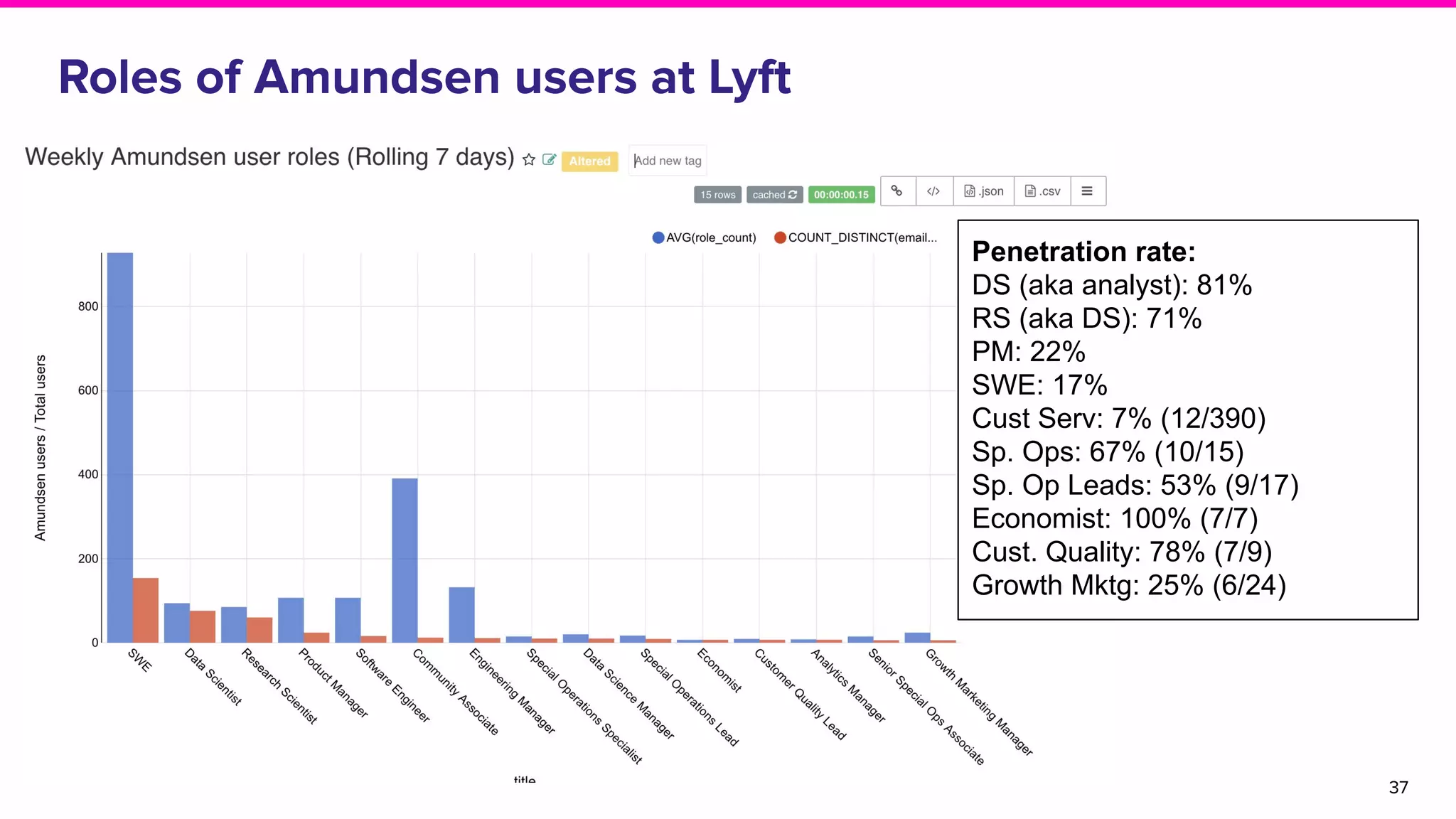





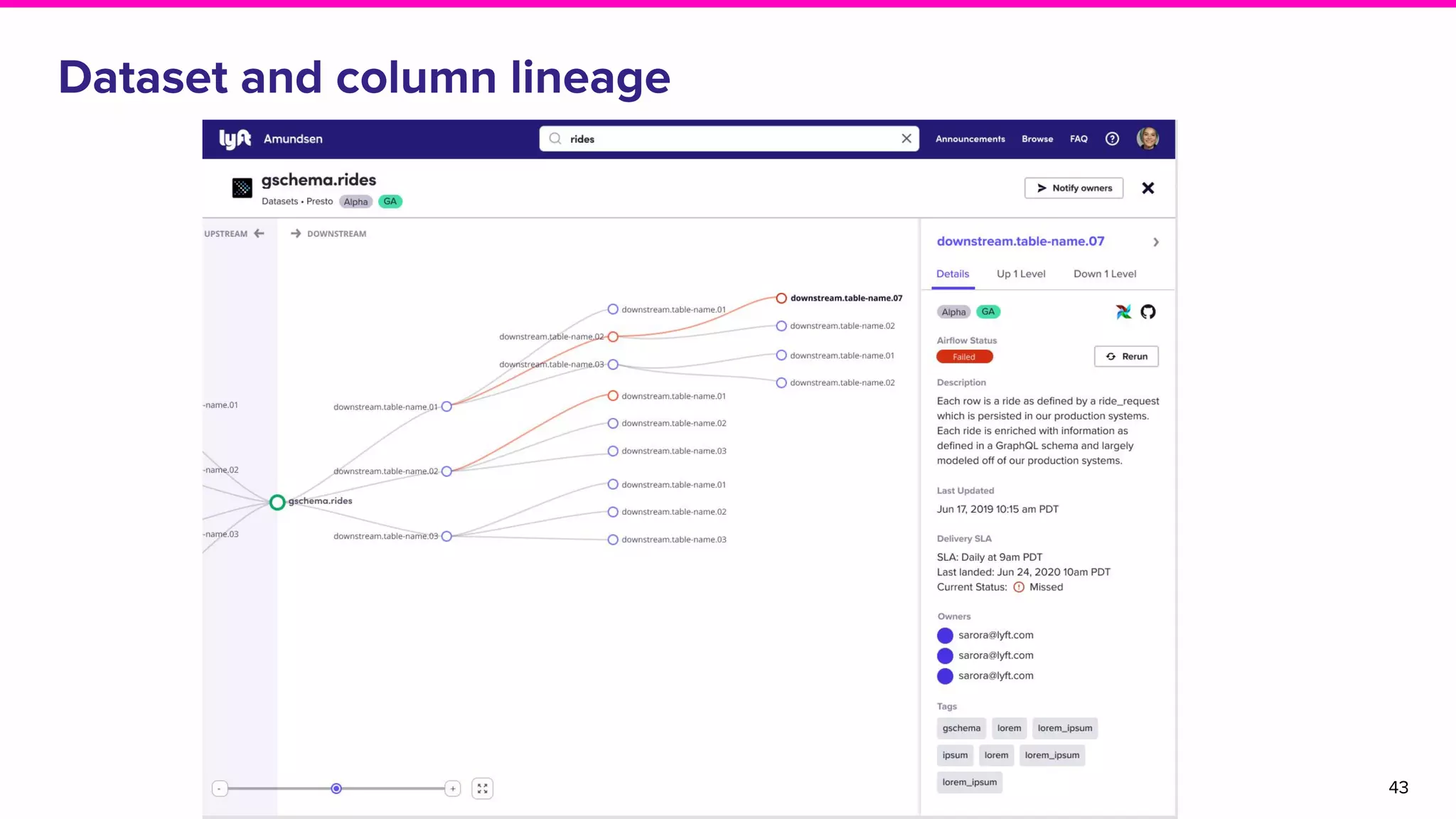
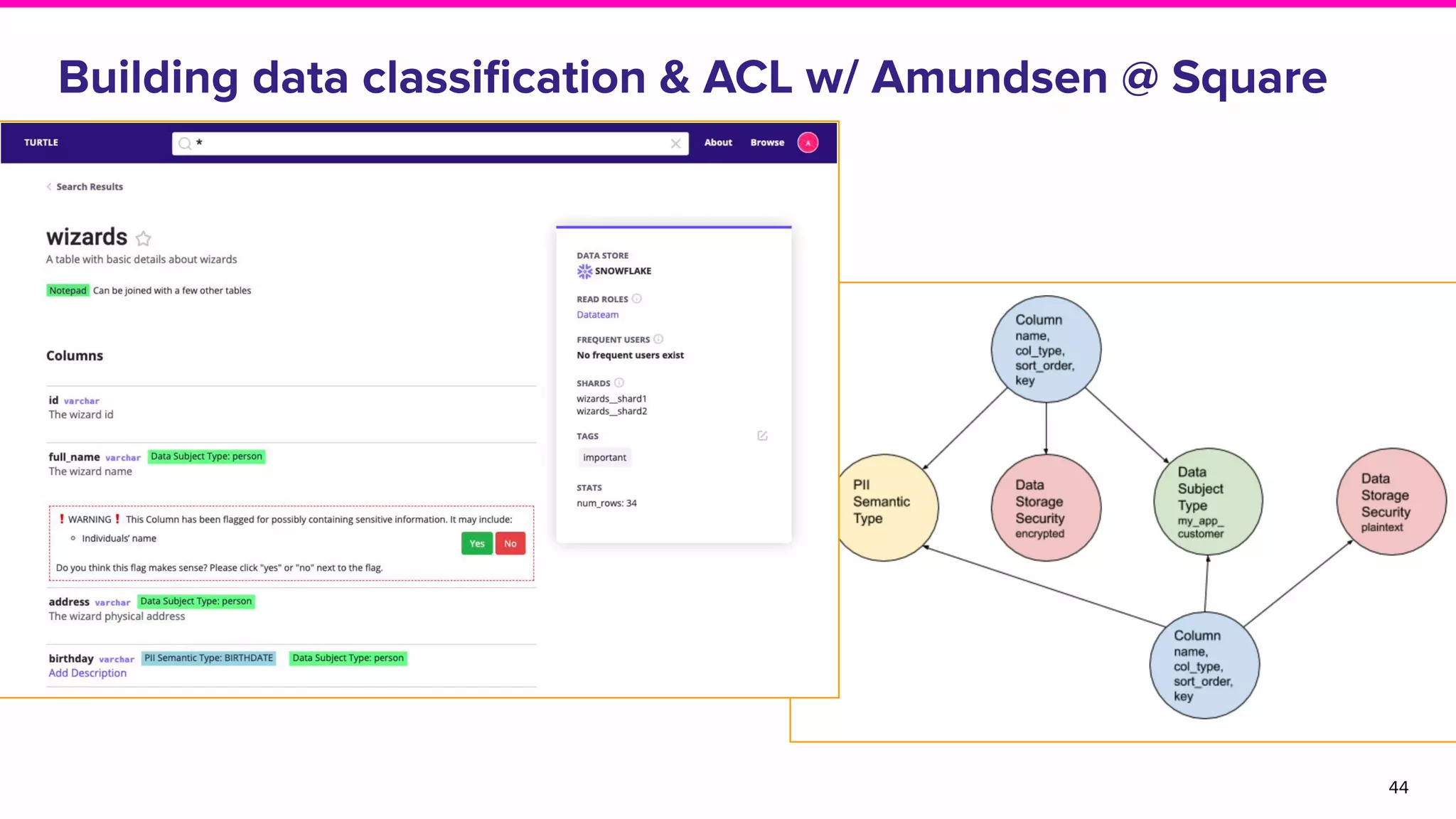
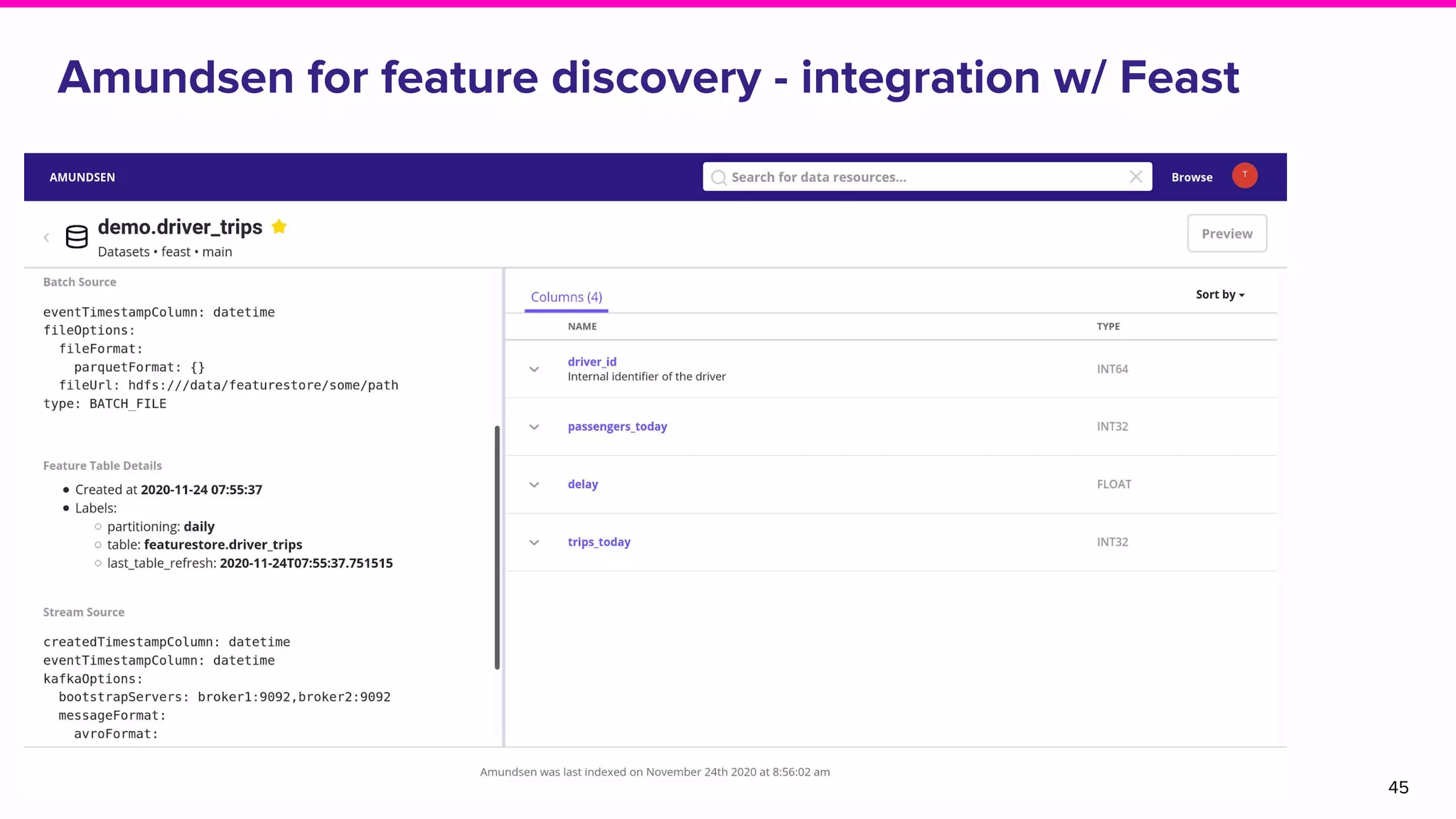
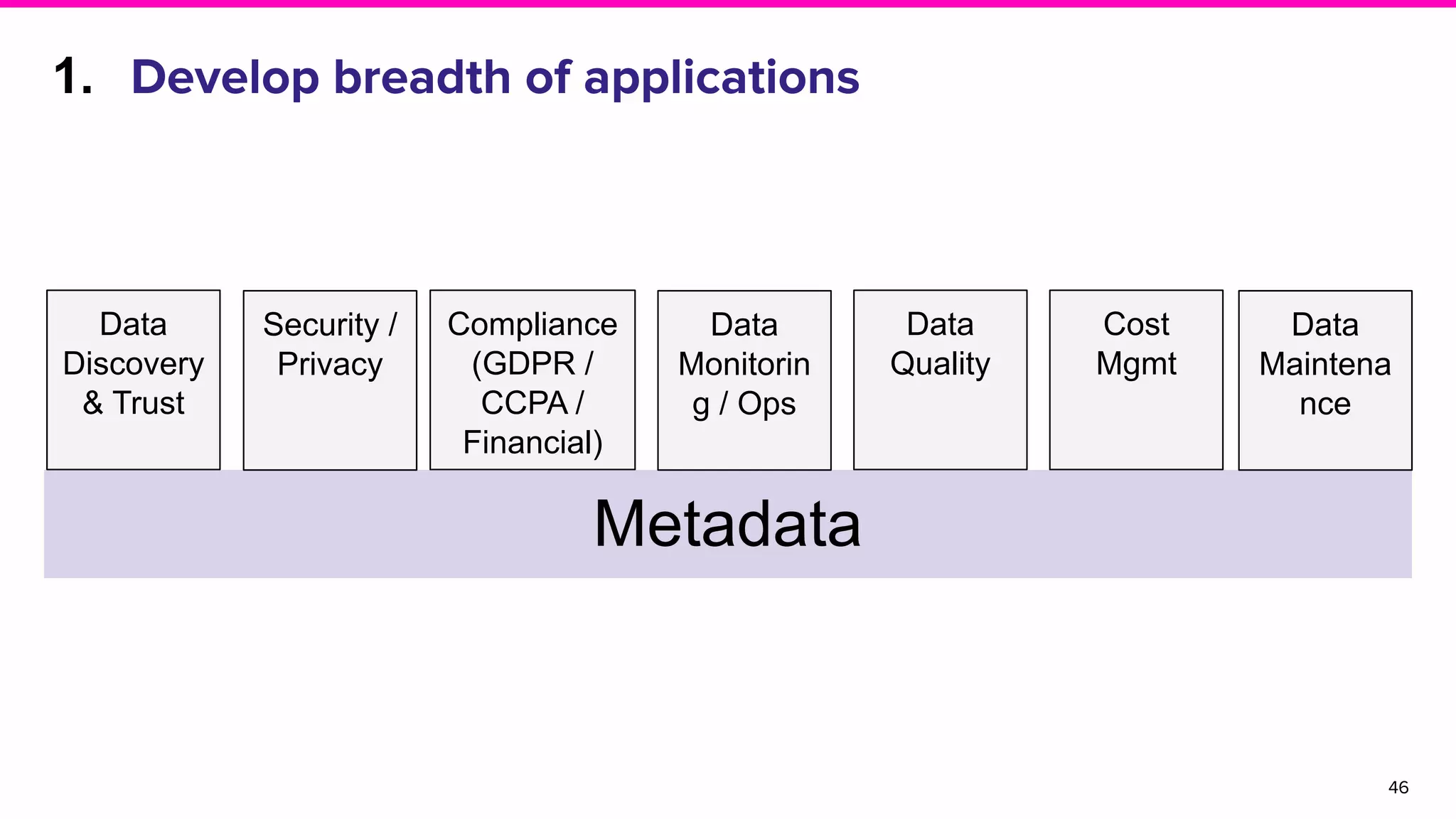
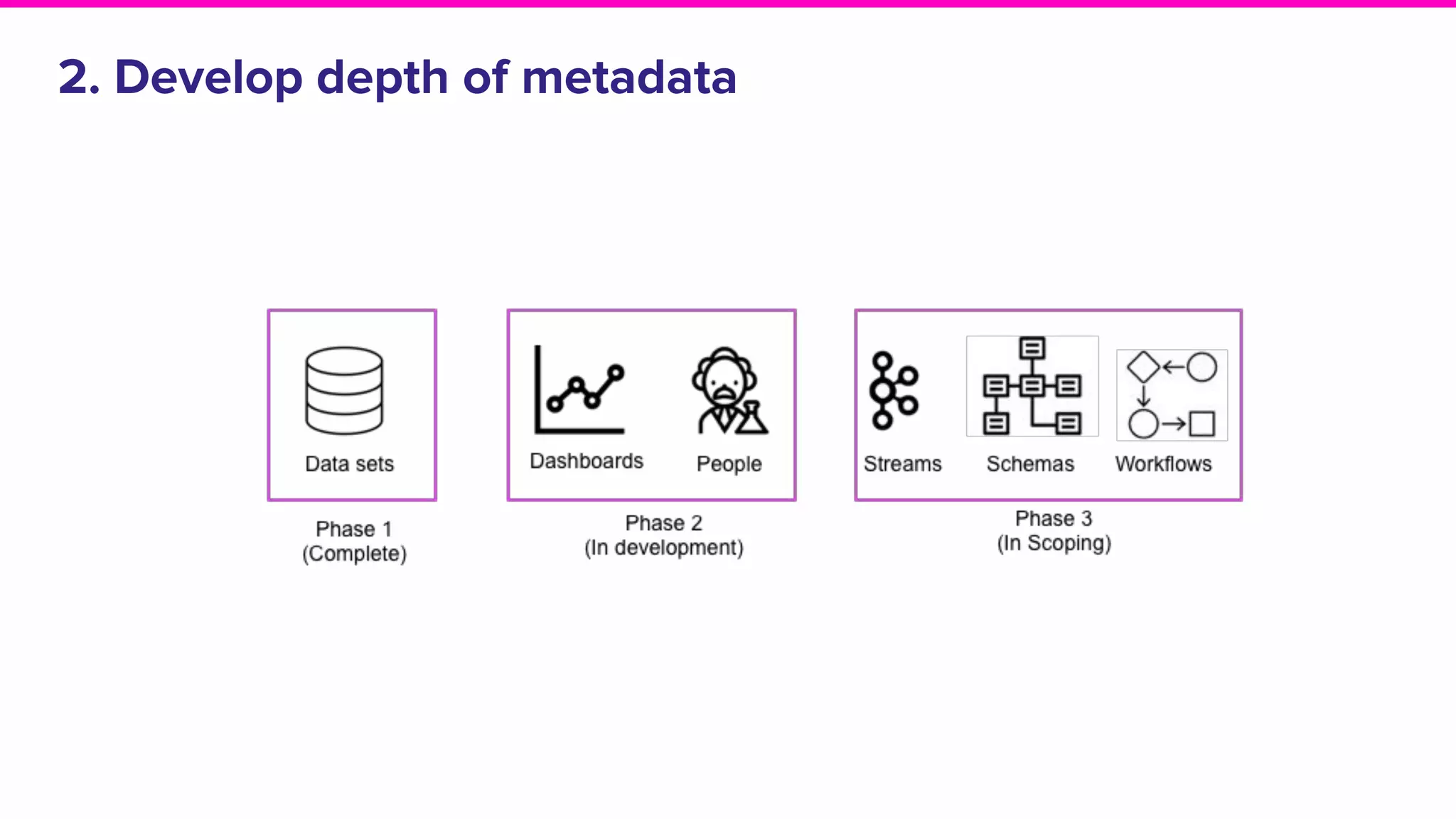


The document outlines the challenges and solutions associated with data discovery and management, emphasizing the need for automated metadata capturing and user-friendly access. It discusses various methods for indexing metadata, including pull and push models, and the importance of real-time updates for effective data governance. Additionally, it highlights the potential benefits of open-source solutions in creating a reliable source of truth for data usage across organizations.







































![[DSC DACH 24] Ship data faster with dbt - Sean McIntyre](https://cdn.slidesharecdn.com/ss_thumbnails/seanmcintyre-240921155005-f23c4e8e-thumbnail.jpg?width=640&height=640&fit=bounds)





























![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)

















