



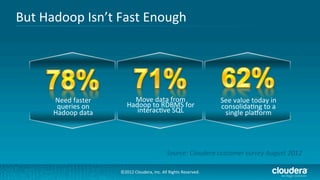

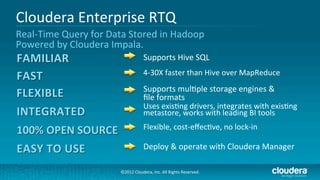



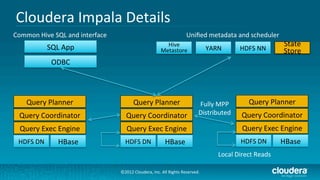
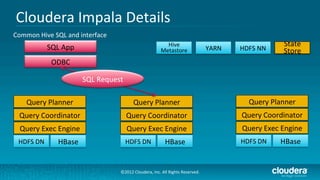
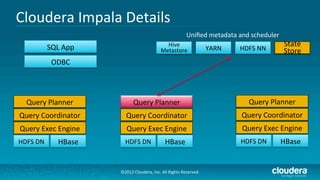
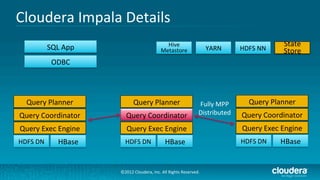
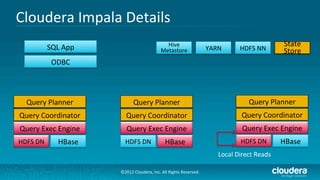
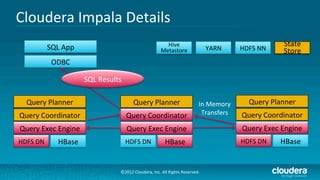







Cloudera's Impala enhances Hadoop's capabilities by providing real-time SQL query functionality, enabling users to perform interactive analytics directly on source data with improved speed and without the complexities of MapReduce. Impala supports various storage formats and integrates seamlessly with existing tools while maintaining a unified metadata architecture. The anticipated benefits include faster query responses, reduced data movement, and the ability to leverage existing employee skills for big data analysis.











































































































