Downloaded 76 times


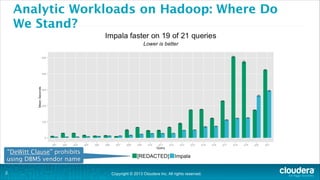







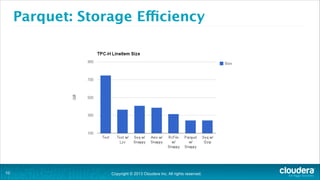
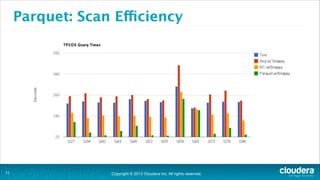





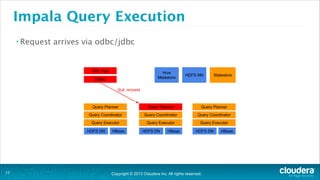

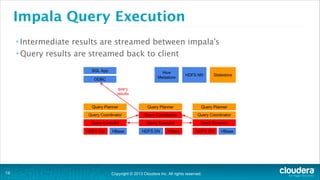



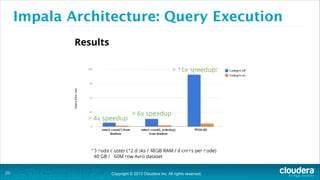

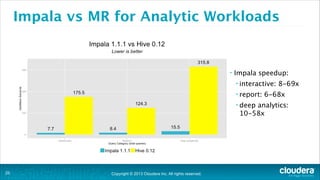

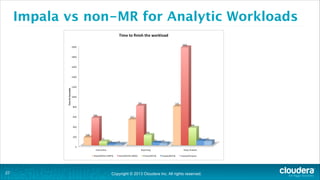
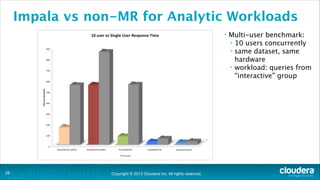
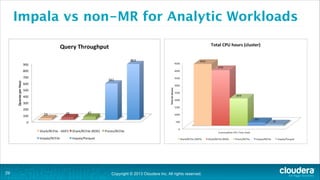


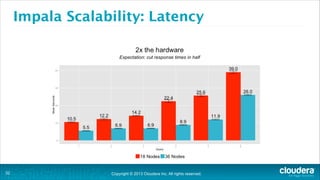
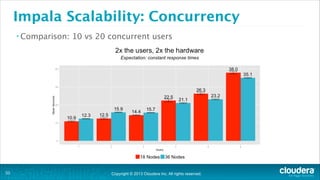
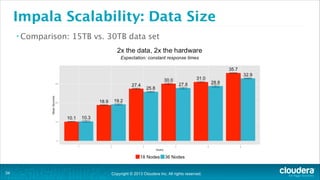




The document is a presentation about using Hadoop for analytic workloads. It discusses how Hadoop has traditionally been used for batch processing but can now also be used for interactive queries and business intelligence workloads using tools like Impala, Parquet, and HDFS. It summarizes performance tests showing Impala can outperform MapReduce for queries and scales linearly with additional nodes. The presentation argues Hadoop provides an effective solution for certain data warehouse workloads while maintaining flexibility, ease of scaling, and cost effectiveness.






























































































