Download as PDF, PPTX




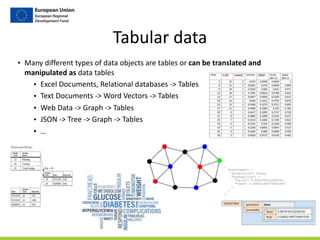



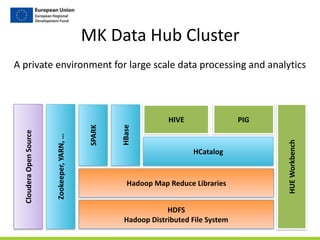







![Step
1/4
-‐
Generate
Term
Vectors
gutenberg_docs
doc_id text
Gutenberg-‐1 …
Gutenberg-‐2 …
Gutenberg-‐3 …
…
gutenberg_terms
doc_id position word
Gutenberg-‐1 0 note[VBP]
Gutenberg-‐1 1 file[NN]
Gutenberg-‐1 2 combine[VBZ]
…
Natural
Language
Processing
task:
-‐ Remove
common
words
(the,
of,
for,
…)
-‐ Part
of
Speech
tagging
(Verb,
Noun,
…)
-‐ Stemming
(going
-‐>
go)
-‐ Abstract
(12,
1.000,
20%
-‐>
<NUMBER>)
Lookup
book
Gutenberg-‐11800
as
follows:
http://www.gutenberg.org/ebooks/11800](https://image.slidesharecdn.com/dataworkshop-largetables-public-180612154218/85/CityLABS-Workshop-Working-with-large-tables-19-320.jpg)
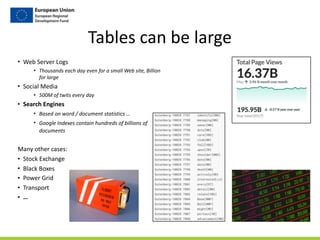
![Step
2/4
Compute
Terms
Frequency
(TF)
gutenberg_terms
doc_id position WORD
Gutenberg-‐1 0 note[VBP]
Gutenberg-‐1 1 file[NN]
Gutenberg-‐1 2 combine[VBZ]
…
Gutenberg-‐1 5425 note[VBP]
doc_word_counts
doc_id word num_doc_wrd_usages
Gutenberg-‐1 call[VB] 2
Gutenberg-‐1 world[NN] 22
Gutenberg-‐1 combine[VBZ] 2
…
usage_bag
+ doc_size
+ 2377270
+ 2377270
2377270
term_freqs
doc_id term term_freq
Gutenberg-‐1 call[VB] 1.791697274828445E-‐5
Gutenberg-‐1 world[NN] 1.791697274828445E-‐5
Gutenberg-‐1 combine[VBZ] 8.958486374142224E-‐6
…
tf(t,d)
=
count(t,d)
/
len(d)
count(t,d)
len(d) count(t,d)
/
len(d)
…
for
each
term
in
each
doc
…](https://image.slidesharecdn.com/dataworkshop-largetables-public-180612154218/85/CityLABS-Workshop-Working-with-large-tables-20-320.jpg)
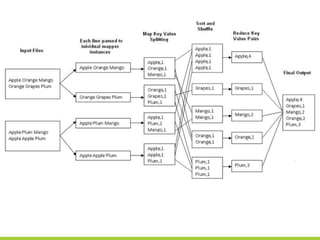
![Step
3/4
Compute
Inverse
Document
Frequency
(IDF)
term_usages
+ num_docs_with_term
+ 1234
+ 1234
1234
term_freqs
doc_id term term_freq
Gutenberg-‐1 call[VB] 1.791697274828445E-‐5
Gutenberg-‐1 world[NN] 1.791697274828445E-‐5
Gutenberg-‐1 combine[VBZ] 8.958486374142224E-‐6
…
term_usages_idf
doc_id term term_freq idf
Gutenberg-‐5307 will[MD] 0.01055794688540567 0.09273305662791352
Gutenberg-‐5307 must[MD] 0.0073364195024229134 0.0927780327905548
Gutenberg-‐5307 good[JJ] 0.006226481496521292 0.11554635054423526
…
d
log(48790/d)
…
for
each
term
in
each
doc
…](https://image.slidesharecdn.com/dataworkshop-largetables-public-180612154218/85/CityLABS-Workshop-Working-with-large-tables-21-320.jpg)
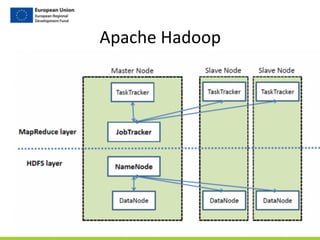
![Step
4/4
Compute
TF/IDF
(IDF)
term_usages_idf
doc_id term term_freq idf
Gutenberg-‐5307 will[MD] 0.01055794688540567 0.09273305662791352
Gutenberg-‐5307 must[MD] 0.0073364195024229134 0.0927780327905548
Gutenberg-‐5307 good[JJ] 0.006226481496521292 0.11554635054423526
…
tfidf
doc_id term tf_idf
Gutenberg-‐5307 will[MD] 0.09273305662791352
Gutenberg-‐5307 must[MD] 0.0927780327905548
Gutenberg-‐5307 good[JJ] 0.11554635054423526
…
…
for
each
term
in
each
doc.
term_freq
*
if](https://image.slidesharecdn.com/dataworkshop-largetables-public-180612154218/85/CityLABS-Workshop-Working-with-large-tables-22-320.jpg)
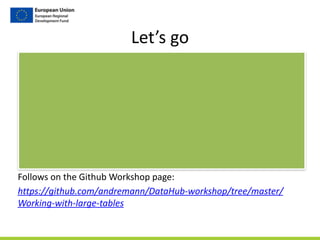


This document discusses working with large tables and big data processing. It introduces distributed computing as an approach to process large datasets by distributing data across multiple nodes and parallelizing operations. The document then outlines using Apache Hadoop and the MK Data Hub cluster to distribute data storage and processing. It demonstrates how to use tools like Hue, Hive, and Pig to analyze tabular data in a distributed manner at scale. Finally, hands-on examples are provided for computing TF-IDF statistics on the large Gutenberg text corpus.





















































































