Download as ODP, PPTX


















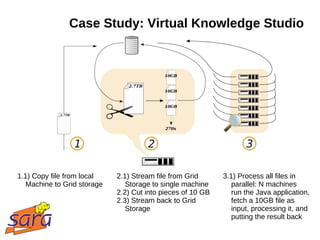
![Case Study: Virtual Knowledge Studio
How do categories in WikiPedia
evolve over time? (And how do
they relate to internal links?)
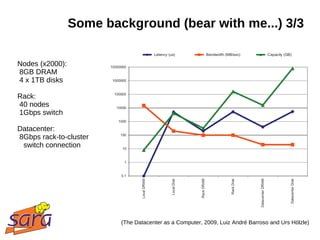
2.7 TB raw text, single file
Java application, searches for
categories in Wiki markup,
like [[Category:NAME]]
Executed on the Grid
http://simshelf2.virtualknowledgestudio.nl/activities/biggrid-wikipedia-experiment](https://image.slidesharecdn.com/presentation-120417062334-phpapp02/85/Hadoop-Sara-BiG-Grid-24-320.jpg)














![And others: NLP & IR
e.g. ClueWeb: a ~13.4 TB webcrawl
e.g. Twitter gardenhose data
e.g. Wikipedia dumps
e.g. del.ico.us & flickr tags
Finding named entities: [person company place] names
Creating inverted indexes
Piloting real-time search
Personalization
Semantic web](https://image.slidesharecdn.com/presentation-120417062334-phpapp02/85/Hadoop-Sara-BiG-Grid-45-320.jpg)







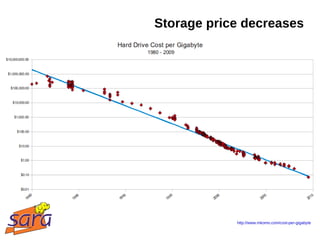
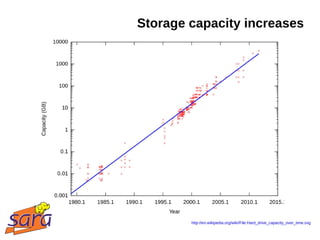
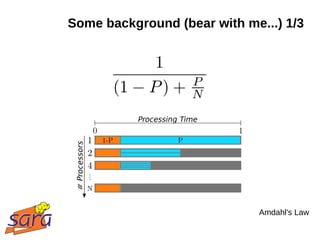
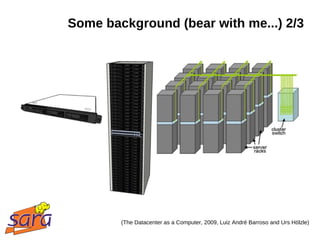
This document discusses large-scale data processing using Apache Hadoop at SARA and BiG Grid. It provides an introduction to Hadoop and MapReduce, noting that data is easier to collect, store, and analyze in large quantities. Examples are given of projects using Hadoop at SARA, including analyzing Wikipedia data and structural health monitoring. The talk outlines the Hadoop ecosystem and timeline of its adoption at SARA. It discusses how scientists are using Hadoop for tasks like information retrieval, machine learning, and bioinformatics.



































































