Download as PDF, PPTX





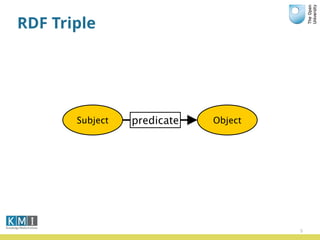
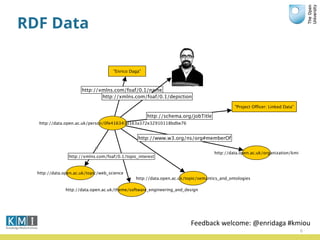


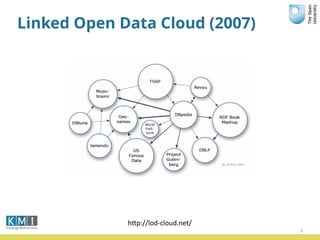
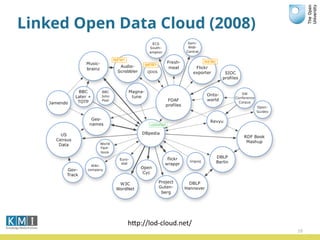

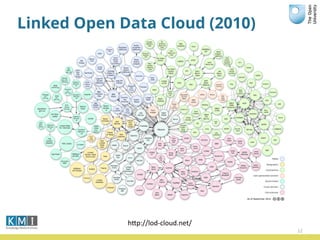







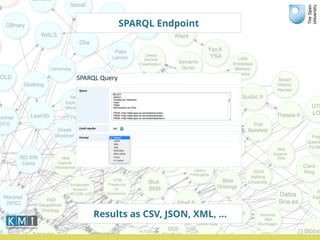


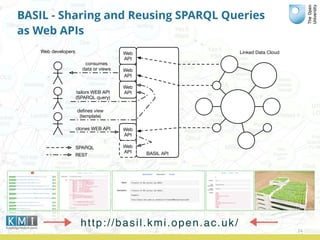







The document discusses the Open University's use of linked open data and their data.open.ac.uk platform. It provides an overview of linked data principles and the data.open.ac.uk platform. Key services of the Open University rely on data.open.ac.uk to support users in various ways such as the student help center and OpenLearn platform. While linked data is useful for centralized data publishing, it does not replace traditional data management and requires developers to integrate it with existing workflows.






















































































