Download as PDF, PPTX



















![• A Uniform Resource Identifier (URI) is a compact sequence of
characters that identifies an abstract or physical resource.
[RFC3986]
• Syntax
URI = scheme ":" hier-part [ "?" query ] [ "#" fragment ]
• Example
foo://example.com:8042/over/there?name=ferret#nose
_/ _________________/_________/ __________/ __/
| | | | |
scheme authority path query fragment
HTTP URIs](https://image.slidesharecdn.com/ld4dhtutorial-190708152721/85/Ld4-dh-tutorial-26-320.jpg)



![• N-Triples (application/n-triples)
• Turtle (text/turtle)
• RDF/XML (application/rdf+xml)
• N-Quads (application/n-quads)
• TriG (application/trig)
• […]
RDF serializations](https://image.slidesharecdn.com/ld4dhtutorial-190708152721/85/Ld4-dh-tutorial-33-320.jpg)






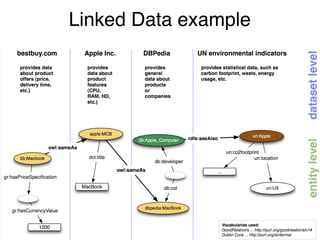







![GET /page/Wolfgang_Amadeus_Mozart HTTP/1.1
Host: dbpedia.org
User-Agent: curl/7.19.7
Accept: */*
HTTP
curl -v http://dbpedia.org/page/Wolfgang_Amadeus_Mozart
HTTP/1.1 200 OK
Date: Wed, 03 Jul 2019 13:41:14 GMT
Content-Type: text/html; charset=UTF-8
Content-Length: 0
Connection: keep-alive
Server: Virtuoso/07.20.3230
Location: http://dbpedia.org/page/Wolfgang_Amadeus_Mozart
[…]
<html> […]](https://image.slidesharecdn.com/ld4dhtutorial-190708152721/85/Ld4-dh-tutorial-48-320.jpg)
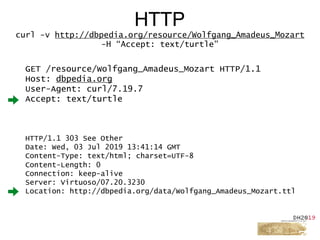
![GET /data/Wolfgang_Amadeus_Mozart.ttl HTTP/1.1
Host: dbpedia.org
User-Agent: curl/7.19.7
Accept: text/turtle
HTTP
curl -v http://dbpedia.org/data/Wolfgang_Amadeus_Mozart.ttl
HTTP/1.1 200 OK
Content-Type: text/turtle; charset=UTF-8
Content-Length: 50708
[…]
@prefix dbo: <http://dbpedia.org/ontology/> .
@prefix dbr: <http://dbpedia.org/resource/> .
dbr:Amadeus_Mozart dbo:wikiPageRedirects dbr:Wolfgang_Ama
dbr:The_Story_of_Mozart dbo:wikiPageRedirects dbr:Wolfga
dbr:Mozartian dbo:wikiPageRedirects dbr:Wolfgang_Amadeus_](https://image.slidesharecdn.com/ld4dhtutorial-190708152721/85/Ld4-dh-tutorial-50-320.jpg)










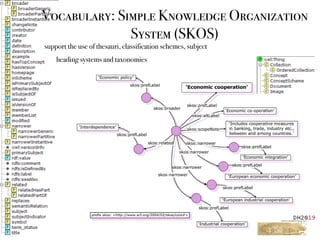
![Ontologies
different levels of detail & complexity
Complexity
Types
Labels
Descriptions
Comments
Class
Hierarchies
Relations
Documented
meaning
Basic Logic
Rules
Inferences
Transitivity
Domain
Range
Rules
Description Logic
Reasoning
Class unions
Sets semantics
Intersections
Disjointness
[…]
light-weight heavy-weight](https://image.slidesharecdn.com/ld4dhtutorial-190708152721/85/Ld4-dh-tutorial-63-320.jpg)











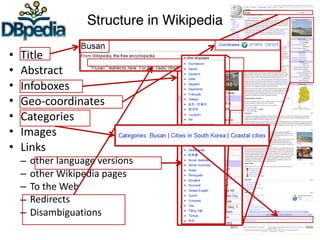
![Infobox templates
{{Infobox Korean settlement
| title = Busan Metropolitan City
| img = Busan.jpg
| imgcaption = A view of the [[Geumjeong]] district in Busan
| hangul = 부산 광역시
...
| area_km2 = 763.46
| pop = 3635389
| popyear = 2006
| mayor = Hur Nam-sik
| divs = 15 wards (Gu), 1 county (Gun)
| region = [[Yeongnam]]
| dialect = [[Gyeongsang]]
}}
http://dbpedia.org/resource/Busan
dbp:Busan dbpp:title ″Busan Metropolitan City″
dbp:Busan dbpp:hangul ″부산 광역시″@Hang
dbp:Busan dbpp:area_km2 ″763.46“^xsd:float
dbp:Busan dbpp:pop ″3635389“^xsd:int
dbp:Busan dbpp:region dbp:Yeongnam
dbp:Busan dbpp:dialect dbp:Gyeongsang
...
Wikitext-Syntax
RDF representation](https://image.slidesharecdn.com/ld4dhtutorial-190708152721/85/Ld4-dh-tutorial-82-320.jpg)





















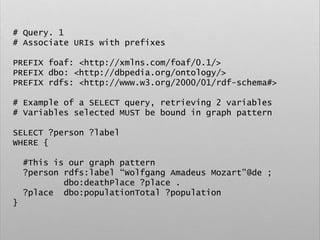




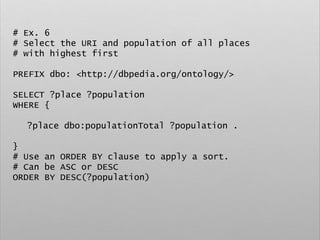
![# Ex. 7
# Select the URI and population of a city
# with highest first
PREFIX dbo: <http://dbpedia.org/ontology/>
PREFIX dbp: <http://dbpedia.org/property/>
SELECT ?place ?population
WHERE {
?place dbo:populationTotal ?population .
FILTER EXISTS {
?place dbp:countryCode []
}
}
# Use an ORDER BY clause to apply a sort.
# Can be ASC or DESC
ORDER BY DESC(?population)](https://image.slidesharecdn.com/ld4dhtutorial-190708152721/85/Ld4-dh-tutorial-120-320.jpg)
![# Ex. 8
# Select the URI and population of the 11-20th most
populated countries
PREFIX dbo: <http://dbpedia.org/ontology/>
PREFIX dbp: <http://dbpedia.org/property/>
SELECT ?place ?population
WHERE {
?place dbo:populationTotal ?population .
FILTER EXISTS {
?place dbp:countryCode []
}
}
# Use an ORDER BY clause to apply a sort.
ORDER BY DESC(?population)
# Limit to first ten results
LIMIT 10
# Apply an offset to get next “page”
OFFSET 10](https://image.slidesharecdn.com/ld4dhtutorial-190708152721/85/Ld4-dh-tutorial-121-320.jpg)

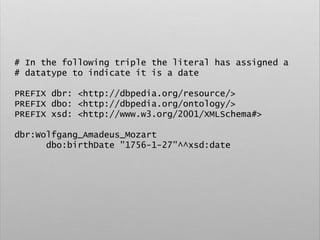
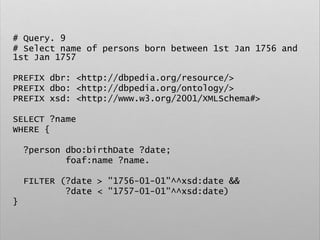
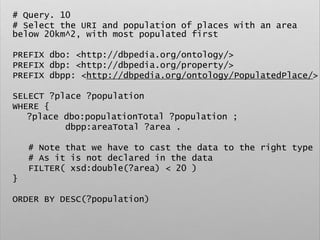
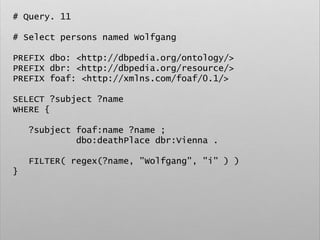


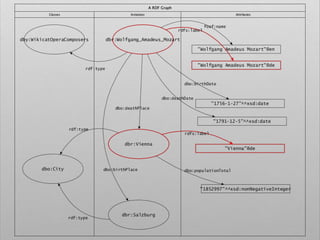
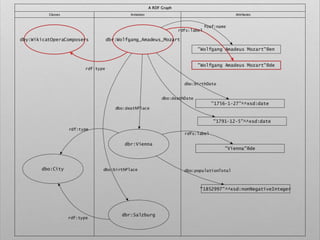
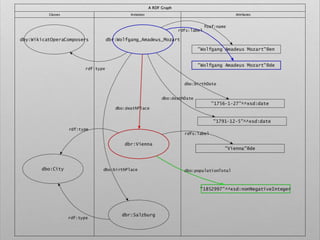
![# Query. 12
# Select list of places that gave birth to german
classical composers
PREFIX space: <http://purl.org/net/schemas/space/>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
SELECT DISTINCT ?place
WHERE {
[] dbo:birthPlace ?place ;
dct:subject dbc:German_classical_composers
}](https://image.slidesharecdn.com/ld4dhtutorial-190708152721/85/Ld4-dh-tutorial-129-320.jpg)


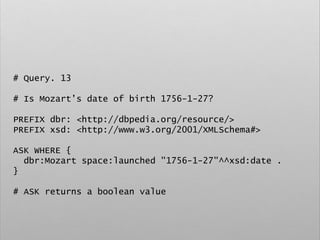

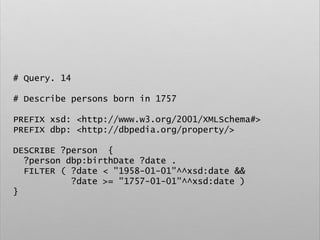

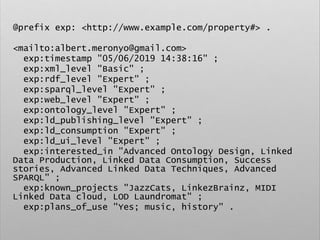
![# Example
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
CONSTRUCT {
?person rdf:type foaf:Person
}
WHERE {
?person ex:timestamp []
}](https://image.slidesharecdn.com/ld4dhtutorial-190708152721/85/Ld4-dh-tutorial-137-320.jpg)
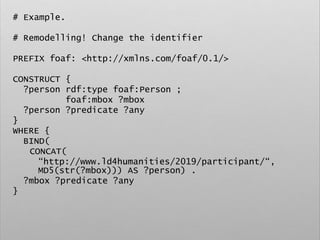

![# Query. 15
# Search in multiple Graphs
SELECT
distinct ?type
FROM <http://data.open.ac.uk/context/youtube>
FROM <http://data.open.ac.uk/context/podcast>
FROM <http://data.open.ac.uk/context/openlearn>
FROM <http://data.open.ac.uk/context/course>
FROM <http://data.open.ac.uk/context/qualification>
WHERE{
[] a ?type
}](https://image.slidesharecdn.com/ld4dhtutorial-190708152721/85/Ld4-dh-tutorial-140-320.jpg)
![# Query. 16
# Search in multiple Graphs
SELECT
distinct ?g ?type
FROM NAMED <http://data.open.ac.uk/context/youtube>
FROM NAMED <http://data.open.ac.uk/context/podcast>
FROM NAMED <http://data.open.ac.uk/context/openlearn>
FROM NAMED <http://data.open.ac.uk/context/course>
FROM NAMED <http://data.open.ac.uk/context/
qualification>
WHERE{
GRAPH ?g { [] a ?type }
}](https://image.slidesharecdn.com/ld4dhtutorial-190708152721/85/Ld4-dh-tutorial-141-320.jpg)


















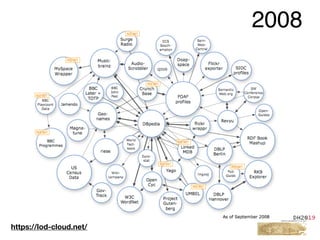
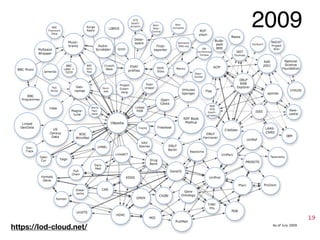
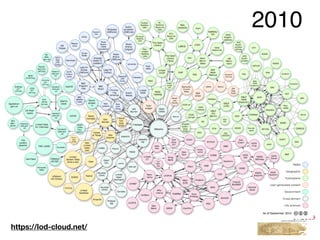
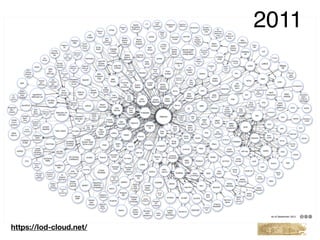
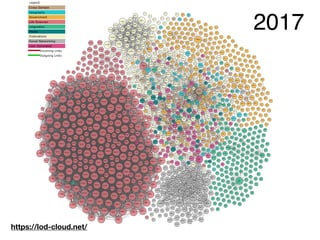
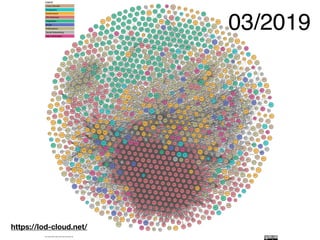
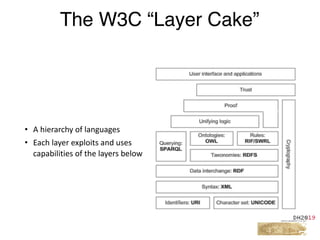
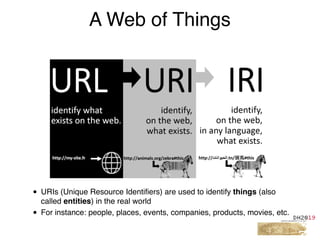
This document provides an overview of a tutorial on Linked Data for the Humanities. The tutorial covers Linked Data basics such as its history and building blocks, including URIs, HTTP, RDF, and SPARQL. It also discusses producing and consuming Linked Data, as well as hybrid methods. The tutorial aims to help participants understand URI resolution, experience graph traversal, and grasp content negotiation through hands-on exercises using tools like cURL.






















































































