Download as PDF, PPTX












![Ontologies
Complexity
Types
Labels
Descriptions
Comments
Class
Hierarchies
Relations
Documented
meaning
Basic Logic
Rules
Inferences
Transitivity
Domain
Range
Rules
Description Logic
Reasoning
Class unions
Set semantics
Intersections
Disjointness
[…]
light-weight heavy-weight](https://image.slidesharecdn.com/lancastertalk-200115093054/85/Linked-data-for-knowledge-curation-in-humanities-research-13-320.jpg)










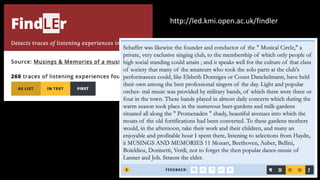
![Finding Listening Experiences (theme: music)
• RECMUS-619, positive: Introduced to the Anacreontic Society, consisting of
amateurs who perform admirably the best orchestral works. The usual supper
followed. After propitiating me with a trio from ’Cosi Fan Tutte’, they drew me to
the piano.
• MASONB-31, positive: In the evening we went to Rev. Baptist Noel’s chapel,
where one is always sure of edification from the sermon if not from the psalms.
• MASONB-88, negative: Flags and pendants were suspended from the windows,
[. . . ] the colors of the German States were waving harmoniously together, and
the banners of the Fine Arts, with appropriate inscriptions, particularly those of
music, poetry and painting, were especially honored, and floated triumphant
amidst the standards of electorates, dukedoms, and kingdoms.](https://image.slidesharecdn.com/lancastertalk-200115093054/85/Linked-data-for-knowledge-curation-in-humanities-research-29-320.jpg)

![Statistical relatedness
0 rontgen[N]
1 play[V]
2 Brahms[N]
3 symphony[N]
4 another[D]
5 musical[J]
6 take[V]
7 always[R]
8 happen[V]
9 specially[R]
10 count[V]
11 something[N]
12 sort[N]](https://image.slidesharecdn.com/lancastertalk-200115093054/85/Linked-data-for-knowledge-curation-in-humanities-research-31-320.jpg)
![Statistical relatedness // Example
RECMUS-619, positive: Introduced to the Anacreontic Society,
consisting of amateurs who perform admirably the best
orchestral works. The usual supper followed. After propitiating me
with a trio from 'Cosi Fan Tutte', they drew me to the piano.
• Anacreontic[n]: 4.13048797627
• amateur[n]: 4.60138704262
• admirably[r]: 3.65226351076
• orchestral[j]: 7.09262661606
• trio[n]: 5.60459207257
• piano[n]: 6.36957273307
Correct](https://image.slidesharecdn.com/lancastertalk-200115093054/85/Linked-data-for-knowledge-curation-in-humanities-research-32-320.jpg)
![Statistical relatedness // Example
MASONB-31, positive: In the evening we went to Rev. Baptist
Noel's chapel, where one is always sure of edification from the
sermon if not from the psalms.
psalm[n]: 4.05596201177
Daga, Enrico, and Enrico Motta. "Capturing themed evidence, a hybrid approach." In Proceedings of the 10th
International Conference on Knowledge Capture, pp. 93-100. 2019.
Wrong](https://image.slidesharecdn.com/lancastertalk-200115093054/85/Linked-data-for-knowledge-curation-in-humanities-research-33-320.jpg)
![Statistical relatedness // Example
MASONB-88, negative: Flags and pendants were suspended from the windows,
[...] the colours of the German States were waving harmoniously together, and
the banners of the Fine Arts, with appropriate inscriptions, particularly those of
music, poetry and painting, were especially honored, and ︎oated triumphant
amidst the standards of electorates, dukedoms, and kingdoms.
harmoniously[r]:4.96754289705
music[n]:1.0
poetry[n]:5.93071678171
painting[n]:4.39244380382
triumphant[j]:3.80869437369
amidst[i]:3.6638322575
Daga, Enrico, and Enrico Motta. "Capturing themed evidence, a hybrid approach." In Proceedings of the 10th
International Conference on Knowledge Capture, pp. 93-100. 2019.
Wrong](https://image.slidesharecdn.com/lancastertalk-200115093054/85/Linked-data-for-knowledge-curation-in-humanities-research-34-320.jpg)


![Hybrid Approach // Example
MASONB-88, negative: Flags and pendants were suspended from the windows, [...]
the colours of the German States were waving harmoniously together, and the
banners of the Fine Arts, with appropriate inscriptions, particularly those of music,
poetry and painting, were especially honored, and ︎oated triumphant amidst the
standards of electorates, dukedoms, and kingdoms.
http://dbpedia.org/resource/Music
Correct](https://image.slidesharecdn.com/lancastertalk-200115093054/85/Linked-data-for-knowledge-curation-in-humanities-research-39-320.jpg)

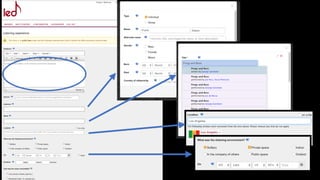







![PhD position open soon
Title: “Distributed Linked Data for Cultural Heritage”
The aim of this project is to research and develop distributed, Linked Data systems
that enable cultural content to be shared between museums and the public. This may
include innovative ways of publishing digital artworks and related resources by
memory institutions as well as enabling the public to share their own experiences of
visiting and engaging with cultural heritage. The PhD will benefit from being closely
connected with the EU funded SPICE project [1] which is developing methods and
tools to allow citizen groups to actively participate with museums internationally.
[1] http://kmi.open.ac.uk/projects/name/spice](https://image.slidesharecdn.com/lancastertalk-200115093054/85/Linked-data-for-knowledge-curation-in-humanities-research-50-320.jpg)


The document discusses the use of linked data in humanities research to facilitate knowledge curation and enhance the discovery of documentary evidence. It outlines how linked data enables the publication of structured information and integrates AI techniques for event retrieval and thematic evidence identification. The text highlights challenges in the curation of complex concepts and the importance of community-oriented initiatives in the field.




















































































