Download as PDF, PPTX























![MapReduce
The programmer specifies two functions:
● map(k, v) → <k', v'>*
● reduce(k', v'[ ]) → <k', v'>*
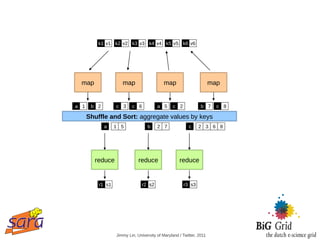
All values associated with the same key are sent to the same reducer
The execution framework handles everything else](https://image.slidesharecdn.com/slides-120531050754-phpapp02/85/Notes-on-data-intensive-processing-with-Hadoop-Mapreduce-28-320.jpg)


![MapReduce
The programmer specifies two functions:
● map(k, v) → <k', v'>*
● reduce(k', v'[ ]) → <k', v'>*
All values associated with the same key are sent to the same reducer
The “execution framework” handles ? everything else ?](https://image.slidesharecdn.com/slides-120531050754-phpapp02/85/Notes-on-data-intensive-processing-with-Hadoop-Mapreduce-32-320.jpg)

![MapReduce
The programmer specifies two functions:
● map (k, v) → <k', v'>*
● reduce (k', v'[ ]) → <k', v'>*
All values associated with the same key are sent to the same reducer
The execution framework handles everything else...
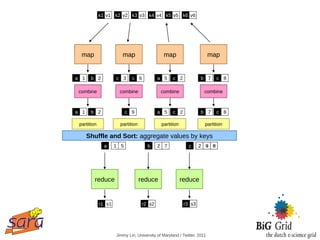
Not quite... usually, programmers also specify:
● partition (k', number of partitions) → partition for k'
● Often a simple hash of the key, e.g., hash(k') mod n
● Divides up key space for parallel reduce operations
● combine (k', v') → <k', v'>*
● Mini-reducers that run in memory after the map phase
● Used as optimization to reduce network traffic](https://image.slidesharecdn.com/slides-120531050754-phpapp02/85/Notes-on-data-intensive-processing-with-Hadoop-Mapreduce-34-320.jpg)



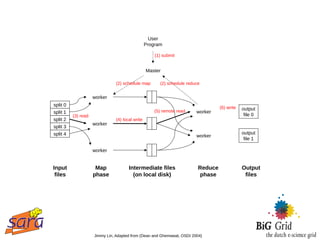
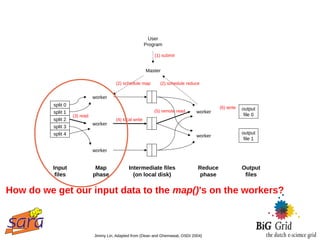





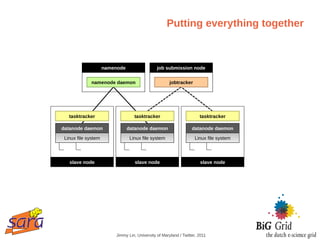


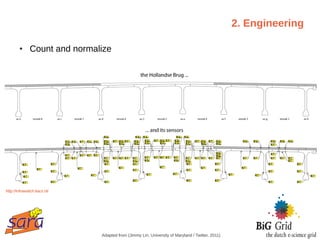
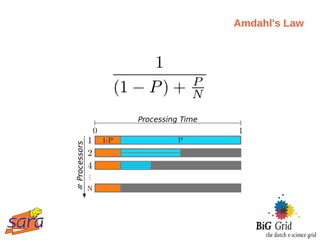
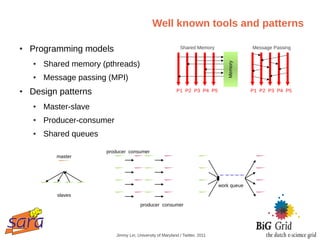
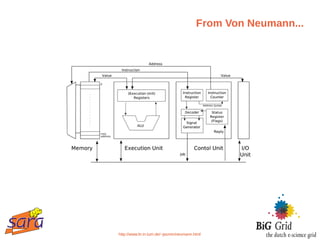
The document outlines a guest lecture on data-intensive processing using Hadoop MapReduce, given by Evert Lammerts at Eindhoven University of Technology. It discusses the significance of 'big data' across various domains such as science, engineering, and commerce, and introduces the MapReduce programming model and its implementations. Key concepts covered include parallel processing challenges, data partitioning, the need for efficient distributed file systems like HDFS, and the functionality of the MapReduce framework in handling large datasets.



































































