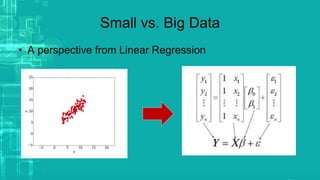
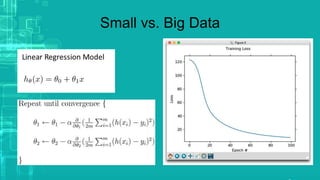
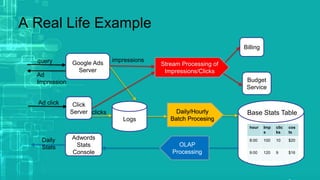
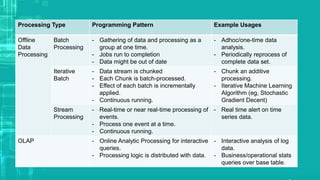
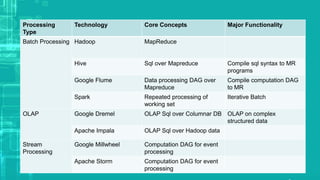
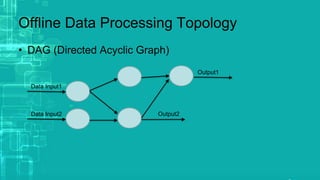
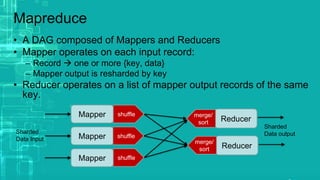
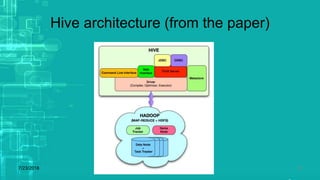
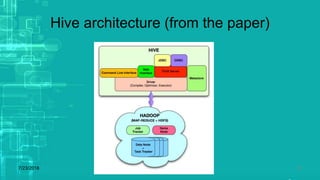
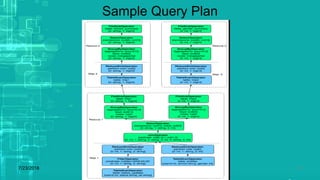
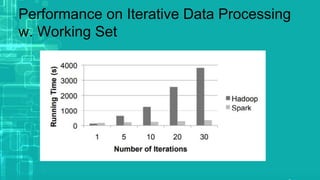
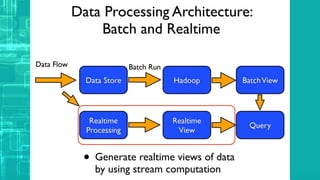
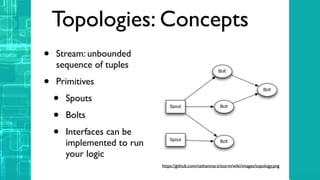
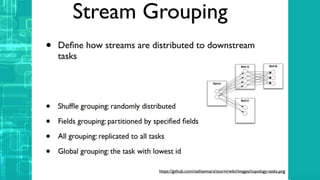
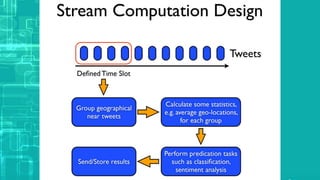
This document provides an overview of big data processing techniques including batch processing using MapReduce and Hive, iterative batch processing using Spark, stream processing using Apache Storm, and OLAP over big data using Dremel and Druid. It discusses techniques such as MapReduce, Hive, Spark RDDs, and Storm tuples for processing large datasets and compares small versus big data approaches. Example usages and technologies for different processing types are also outlined.





















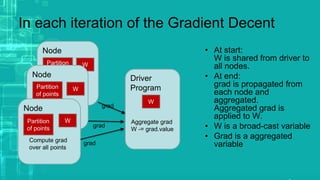
![RDD -- construction
• From a file in a shared file system, such as the Hadoop
Distributed File System (HDFS).
• By “parallelizing” a Scala collection (e.g., an array) in the
driver program, which means dividing it into a number of
slices that will be sent to multiple nodes.
• By transforming an existing RDD.
– A dataset with elements of type A can be transformed into a dataset
with elements of type B using an operation called flatMap, which
passes each element through a user-provided function of type A ⇒
List[B].
– Other transformations can be expressed using flatMap, including
map (pass elements through a function of type A ⇒ B) and filter
(pick elements matching a predicate).](https://image.slidesharecdn.com/data-processing-180723164235/85/Big-Data-Processing-31-320.jpg)




























































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)



![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)
