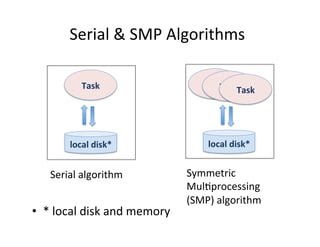
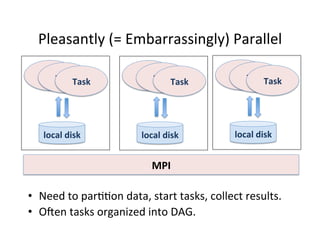
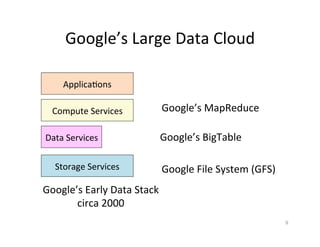
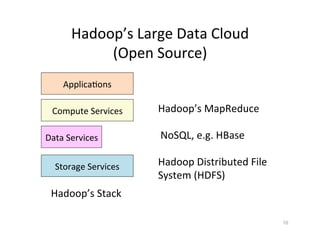
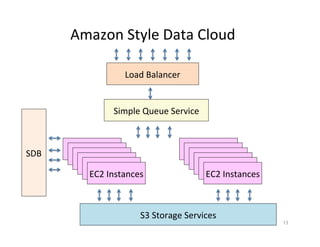
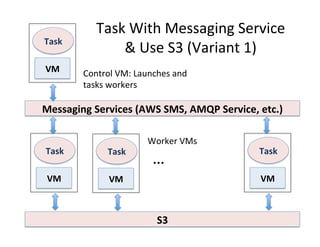
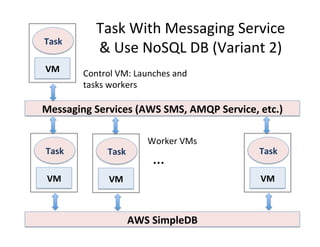
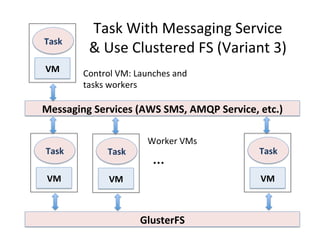
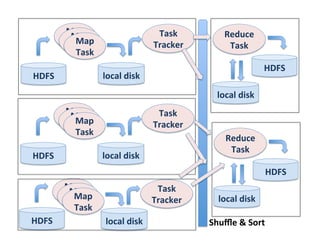
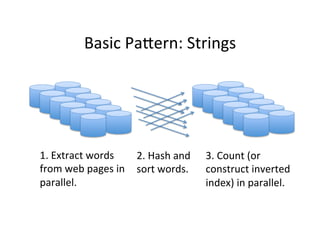
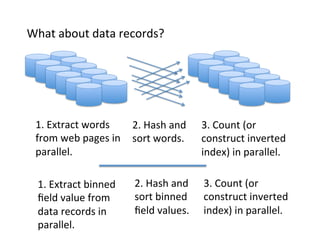
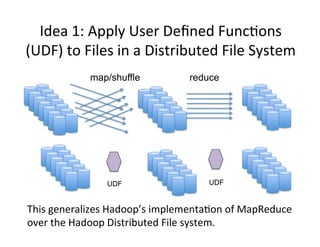
This document presents an introduction to data-intensive computing, covering topics such as managing and processing big data using cloud technologies like Hadoop and Amazon Web Services. It elaborates on key concepts such as MapReduce, user-defined functions, and data processing patterns over distributed file systems. The content includes practical applications, comparisons of programming models, and examples of word count implementations using various programming languages.





































![Word
Count
R
Reducer
trimWhiteSpace <- function(line) gsub("(^ +)|( +$)", "", line)
splitLine <- function(line) {
val <- unlist(strsplit(line, "t"))
list(word = val[1], count = as.integer(val[2]))
}
env <- new.env(hash = TRUE)
con <- file("stdin", open = "r")
while (length(line <- readLines(con, n = 1, warn = FALSE)) >
0) {
line <- trimWhiteSpace(line)
split <- splitLine(line)
word <- split$word
count <- split$count](https://image.slidesharecdn.com/03-processing-big-data-11-v5-170904212945/85/Processing-Big-Data-An-Introduction-to-Data-Intensive-Computing-52-320.jpg)




![Code
Comparison
–
Word
Count
Reducer
Python
def read_mapper_output(file, separator='t'):
for line in file:
yield line.rstrip().split(separator, 1)
def main(sep='t'):
data = read_mapper_output(sys.stdin, sep=sepa)
for word, group in groupby(data, itemgetter(0)):
total_count = sum(int(count) for word, count in group)
print "%s%s%d" % (word, sep, total_count)
R
trimWhiteSpace <- function(line) gsub("(^ +)|( +$)", "", line)
splitLine <- function(line) {
val <- unlist(strsplit(line, "t"))
list(word = val[1], count = as.integer(val[2]))
}
env <- new.env(hash = TRUE)
con <- file("stdin", open = "r")
while (length(line <- readLines(con, n = 1, warn = FALSE)) > 0) {
line <- trimWhiteSpace(line)
split <- splitLine(line)
word <- split$word
count <- split$count
if (exists(word, envir = env, inherits = FALSE)) {
oldcount <- get(word, envir = env)
assign(word, oldcount + count, envir = env)
}
else assign(word, count, envir = env)
}
close(con)
for (w in ls(env, all = TRUE))
cat(w, "t", get(w, envir = env), "n", sep = "”)
Java
public static class Reduce
extends Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values,
Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}](https://image.slidesharecdn.com/03-processing-big-data-11-v5-170904212945/85/Processing-Big-Data-An-Introduction-to-Data-Intensive-Computing-57-320.jpg)


















































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)

















