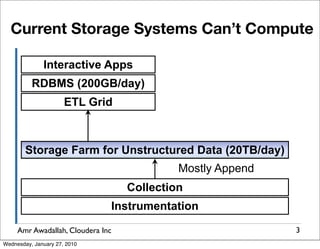
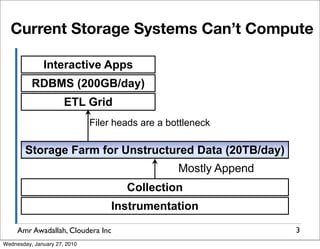
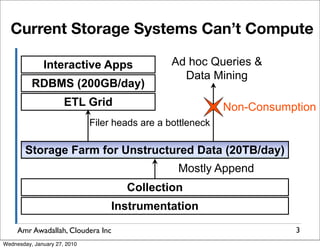
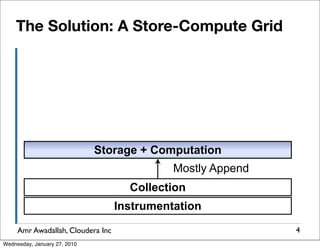
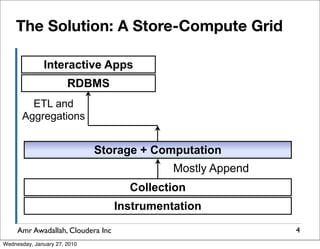
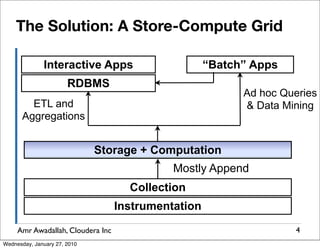
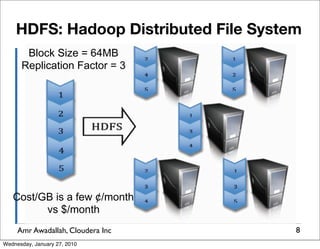
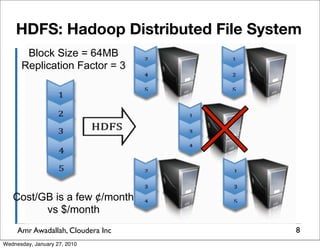
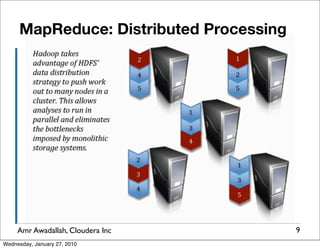
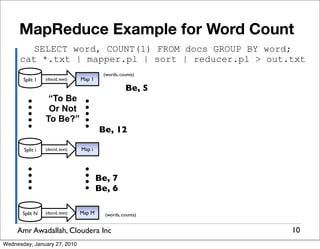
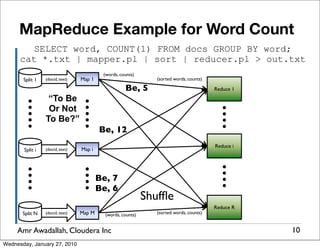
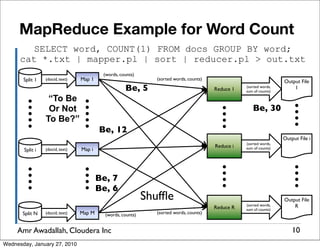
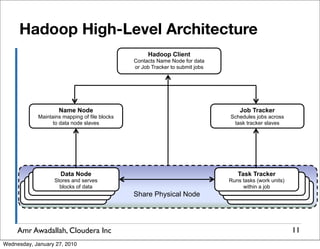
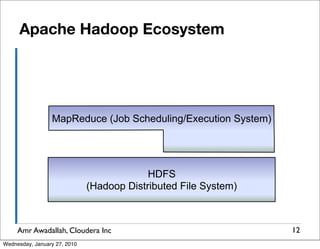
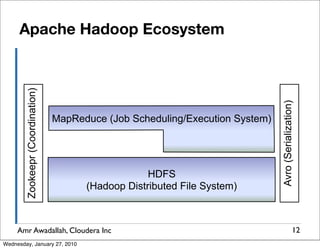
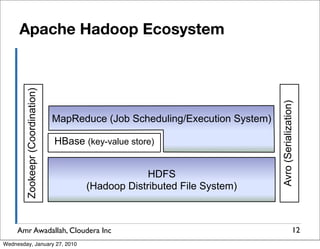
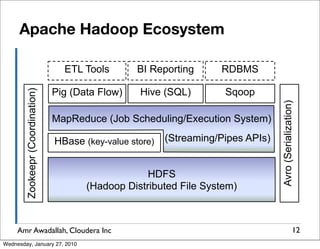
The document summarizes a presentation given by Amr Awadallah of Cloudera on Hadoop. It discusses how current storage systems are unable to perform computation, and how Hadoop addresses this through its marriage of HDFS for scalable storage and MapReduce for distributed processing. It provides an overview of Hadoop's history and design principles such as managing itself, scaling performance linearly, and moving computation to data.