Variational Autoencoder
2
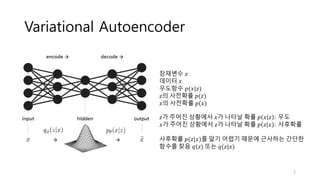
잠재변수 𝑧
데이터𝑥
우도함수 𝑝(𝑥|𝑧)
𝑧의 사전확률 𝑝(𝑧)
𝑥의 사전확률 𝑝 𝑥
𝑧가 주어진 상황에서 𝑥가 나타날 확률 𝑝 𝑥 𝑧 : 우도
𝑥가 주어진 상황에서 𝑧가 나타날 확률 𝑝 𝑧 𝑥 : 사후확률
사후확률 𝑝(𝑧|𝑥)를 알기 어렵기 때문에 근사하는 간단한
함수를 찾음 𝑞(𝑧) 또는 𝑞(𝑧|𝑥)
3.
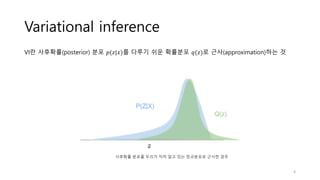
Variational inference
흰색: 잠재변수(z)
회색:관측변수(x)
- 주어진 데이터(𝑥)와 주어지지 않은 잠재변수(𝑧)가 모델에 관여하는 상황.
- 어떤 잠재변수로부터 주어진 데이터를 만들어낼 확률𝑝(𝑥|𝑧)이 가장 높은 모델과, 그때 최적의
잠재변수를 만드는 함수 𝑝(𝑧|𝑥)를 찾아야한다고 생각해보자.
- 이 때, 사후확률 분포 𝑝(𝑧|𝑥) 를 계산하는 것이 불가능에 가까울 정도로 어려운 경우가 많다.
잠재변수간 상호작용 때문에 marginal probability 계산이 힘들다.
Marginal probability: 𝑝(𝑥) = σ 𝑧 𝑝(𝑥, 𝑧)
3
Variational inference
사후확률 𝑝(𝑧|𝑥)에근사한 𝑞(𝑧)를 만들기 위해 두 분포의 차이를 줄여야 함.
→ 두 확률분포의 차이를 계산하는 KL-Divergence 개념 활용
사후확률 분포 𝑝(𝑧|𝑥)와 𝑞(𝑧) 사이의 KLD를 계산하고, KLD가 줄어드는 쪽으로 𝑞(𝑧)를 조금
씩 업데이트하는 과정을 반복하면 사후확률을 잘 근사하는 𝑞∗
(𝑧)를 얻게 될 것
→ 이 과정이 Variational Inference
KLD를 줄어들게 하는데 몇가지 방법이 있음.
5
1. Variational Inferencewith Monte Carlo
Sampling
몬테카를로 방법(Monte Carlo Method): 랜덤 표본을 뽑아 함수의 값을 확률적으로 계산하는 방법.
이를 이용하여 KLD 텀에 대한 근사식을 유도
7
8.
1. Variational Inferencewith Monte Carlo
Sampling
실제 문제에서는 사후확률 분포𝑝(𝑧|𝑥)에 대해 아무런 정보가 없지만 몬테카를로 방법을
이용하면 𝑞(𝑧)를 어떤 분포로든 설정할 수 있다.
Ex) 사후분포에 대한 정보가 없어서 𝑞(𝑧)를 정규분포로 정해 볼 경우
1. 이 정규분포에서 K개의 z들을 뽑으면 KLD의 근사값을 계산 가능.
2. 정규분포의 파라메터(평균, 분산)를 조금씩 바꿔가면서 KLD 근사값을 최소로 하는
파라메터를 구할 수 있을 것.
3. 구해진 정규분포가 바로 VI의 결과.
≈
8
9.
2. Variational Inferencewith SGD
KLD를 줄이는 방향으로 𝑞(𝑧)의 파라메터를 업데이트 하여 VI하는 것도 가능
→ Gradient를 계산하기 위해 KLD가 미분가능 해야함
Ex)
𝑞 𝑧 는 정규분포 𝜃 𝑞 = 𝜇 𝑞, 𝜎 𝑞 , 𝑝 𝑧 는 베타분포 𝛼, 𝛽 라고 두고 𝐾𝐿𝐷 식을 𝜃 𝑞에 대해 미분해 보자.
(적절한 𝜃 𝑞를 추론하려 하는것)
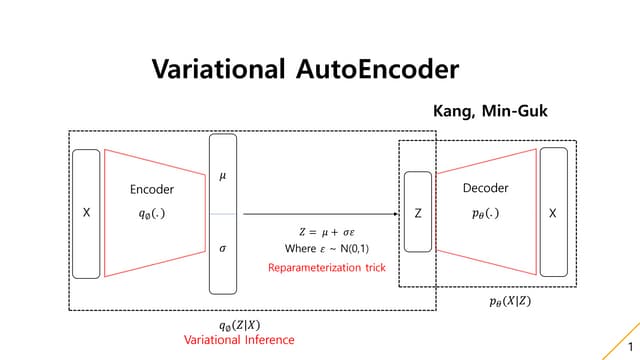
이때, z가 𝜃 𝑞를 파라메터로 갖는 𝑞에 의해 랜덤 샘플링되기 때문에 𝜃 𝑞 에 대한 미분이 불가능
→ z대신 노이즈를 샘플링해서 z를 계산하는 reparameterization trick 사용
9
10.
2. Variational Inferencewith SGD
여기서도 몬테카를로 샘플링을 이용하여 KLD의 gradient 근사값을 계산.
→ Gradient 이용하여 𝜃 𝑞를 수정함으로써 사후확률 분포 𝑝(𝑧|𝑥)에 근사하는 𝑞(𝑧)를 찾을 수 있다.
10
11.
Vatiational EM algorithm
-지금까지는 사전확률함수 𝑝 𝑧 와 우도함수 𝑝 𝑥 𝑧 를 이미 알고 있다는 전제 하에 𝑝 𝑧 𝑥
에근사하는 𝑞 𝑧 를 찾는 𝑉𝐼 과정을 설명하였음.
- 하지만 실제 문제에서는 사전호가률과 우도함수의 파라메터 또한 알고 있지 못하는 경우가 많다.
우도함수를 모르는 상황에서 VI를 하기 위해선?
1. 사전확률 𝑝 𝑧 는 상수로 고정하여도 됨
2. 사후확률 𝑝(𝑧|𝑥)에 근사한 𝑞(𝑧)의 파라메터를 찾는 것과 동시에, 우도함수 𝑝(𝑥|𝑧)의 파라메터 또
한 추정해야 함
3. But, 이 둘을 동시에 찾는 것은 불가능.
→ 한 파라메터를 고정하고 나머지 파라메터를 최적화하는 것을 반복하는 EM algorithm 사용
11
12.
Vatiational EM algorithm
𝑞(𝑧)의파라메터를 𝜃 𝑞, 우도함수𝑝(𝑥|𝑧)의 파라메터를 𝜃𝑙라고 둘 때
EM algorithm은 다음과 같은 과정을 수렴할 때까지 반복함
E-step에서는 KLD를 줄이기 위해 q만을 업데이트하므로 이 과정에서 𝑝(𝑥) 는 변하지 않음.
KLD를 줄이기 위해선 M-step을 통해 𝑝(𝑥)또한 줄여야 한다.
log 𝑝(𝑥)에 대해 정리하면,
- Expectation: 우도함수 𝑝 𝑥 𝑧 의 파라메터 𝜃𝑙을 고정한 상태에서 𝐷 𝐾𝐿(𝑞(𝑧)||𝑝 𝑧 𝑥 )를
줄이는 q의파라메터 𝜃 𝑞를 찾는다.(앞에 소개한 방법 이용)
- Maximization: E-step에서 찾은 𝜃 𝑞를 고정한 상태에서 evidence 𝑝 𝑥 를 최대화하
는 우도함수 𝑝(𝑥|𝑧)의 파라메터 𝜃𝑙를 찾는다.
12
13.
Vatiational EM algorithm
이때, KLD는 항상 양수이므로
우변이 Evidence인 𝑝(𝑥)의 하한을 나타내므로 Evidence Lower Bound(ELBO)라고 부름
양수
M-step 설명중임
13
14.
Vatiational EM algorithm
ELBO두 분포의 차이
(줄이고자 하는것)
ELBO를 최대화 시킨다면?
→ 등호를 만족시키기 위해서 KLD가 최소화 될 것.
𝜃 𝑞가 고정된 상태에서 우도함수𝑝(𝑥|𝑧)의 파라메터 𝜃𝑙
를 KLD가 최소화되는 방향으로 업데이트 하는 것임
이 또한 reparameterization trick을 이용한 SGD를
사용하면 된다.(참고: http://edwardlib.org/tutorials/klqp)
Prior, 상수취급
M-step 설명중임
14






























![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 3장. 분류](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-180724063825-thumbnail.jpg?width=640&height=640&fit=bounds)






![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 4장. 모델 훈련](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-180814064959-thumbnail.jpg?width=640&height=640&fit=bounds)


![[한글] Tutorial: Sparse variational dropout](https://cdn.slidesharecdn.com/ss_thumbnails/tutorialsparsevariationaldropout-190728122300-thumbnail.jpg?width=640&height=640&fit=bounds)












![[Probability for machine learning]](https://cdn.slidesharecdn.com/ss_thumbnails/probabilityformachinelearning-180726131331-thumbnail.jpg?width=640&height=640&fit=bounds)
![[PRML 3.1~3.2] Linear Regression / Bias-Variance Decomposition](https://cdn.slidesharecdn.com/ss_thumbnails/bayesianlinearregressionpart1-170117134816-thumbnail.jpg?width=640&height=640&fit=bounds)























